













老黃祭出全新RTX 500 GPU,AIGC性能狂飆14倍!AI應用的門檻徹底被打下來了
在巴塞羅那舉行的世界移動大會(MWC 2024)上,英偉達發布了最新款的入門級移動版工作站GPU,RTX 500 Ada和RTX 1000 Ada。
這兩款入門級移動工作站GPU與之前發布的RTX 2000、3000、3500、4000和5000一起,構成了英偉達移動工作站GPU的整個產品線。
按照英偉達官方的說法,配備了入門級GPU的筆記本電腦,相較于使用CPU來處理AI任務的設備,效率能暴增14倍!
這兩款新的GPU,將會在今年第一季度搭載在OEM的合作伙伴推出的筆記本電腦中上市。
入門級工作站移動GPU,補全產品線的最后一塊拼圖
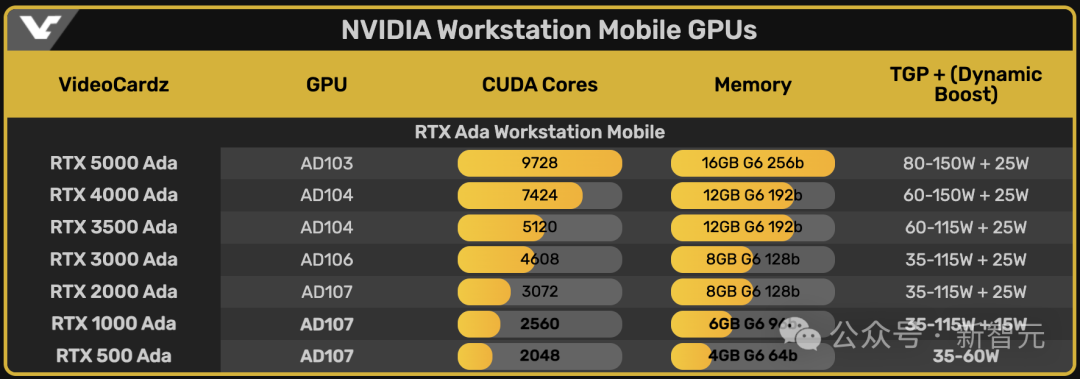
從功耗上我們就能看出來,這兩款入門級的產品基本上是針對輕薄本推出的產品。
雖然配備的核心數,內存數遠遠低于產品線中的其他信號,但是Ada構架所支持的特性卻是一點沒有縮水。

- 第三代RT核心:
光線追蹤性能是前代的兩倍,實現了高度真實感的渲染效果。

- 第四代Tensor核心:
處理速度是上一代的兩倍,加快了深度學習訓練、推理過程和AI驅動的創意任務。

- Ada構架的CUDA核心:
相比前代,單精度浮點(FP32)處理能力提高了30%,在圖形處理和計算任務上大幅提升了性能。

- 專用GPU內存:
RTX 500搭載了4GB內存,而RTX 1000則配備了6GB內存,足以應對復雜的3D和AI應用,處理大型項目和數據集,以及多應用并行工作流程。
- DLSS 3:
這一AI圖形技術的突破性進展,通過產生更多高質量畫面顯著提高了性能。

- AV1編碼器:
第八代編碼器(NVENC)支持AV1編碼,比H.264編碼高效40%,為視頻直播、流媒體和視頻通話提供了更多可能。

基于Ampere構架的上一代產品,RTX A500和RTX A1000的的核心數都只有2048。
這一代更新后的RTX 500 Ada,保留2024個核心數不變,但是RTX 1000 Ada的核心數就提升了1/4,達到2560個,內存直接標配6GB。

而且對比上一代產品,英偉達這兩個型號的GPU功率都有了不小的提升。
RTX 500從20-60W提升到了35-60W,RTX 1000從35-95W提升到了35-140W,而且RTX 1000還支持了Dynamic Boost,功耗可以再額外提升15W。
AI應用進入日常生活,入門級GPU大有可為
英偉達稱,與單純依賴CPU的配置相比,新款RTX 500 GPU能夠在執行像Stable Diffusion這類模型時,提供高達14倍的AI性能。
此外,AI照片編輯速度提升3倍,3D渲染的圖形性能提升了10倍,將為各種工作流程帶來了巨大的生產力飛躍。
隨著生成式AI和混合式工作環境日益成為常態,從內容創作者到研究人員,再到工程師,幾乎所有專業人士都需要一款功能強大的、支持AI加速的筆記本電腦,以便在任何地點都能有效應對行業挑戰(加班)。
隨著各大硬件廠商都在布局AI PC和AI手機,可以預料在不遠的將來,除了專業的開發者和內容創作者之外,普通老百姓也會在日常生活中接觸到大量的AI應用。

老黃在MWC如此重要的場合,拋出的卻是兩款最入門的移動GPU。
這似乎就是在對外宣稱,在算力巨頭眼里,普通的消費者也同樣能夠享受到技術普及帶來的紅利。
而傳統的CPU廠家,也在今年初推出了自己帶有AI能力的產品,希望從產品形態上和英偉達形成差異化競爭。

AMD第一代基于XDNA架構的神經處理單元(NPU)去年上市,作為其「Phoenix」Ryzen 7040移動處理器系列的組成部分。
其中,XDNA通過一系列特殊設計的 AI Engine 處理單元組成的網絡來實現空間數據流處理。
每個AI Engine單元都配備了一個向量處理器和一個標量處理器,還有用于存儲程序和數據的本地內存。
這種設計避免了傳統架構中頻繁從緩存中讀取數據所帶來的能量消耗,通過使用板載上內存和專門設計的數據流,AI Engine能夠AI和信號處理任務中實現高效和低功耗的計算。
幾個月后,英特爾推出了同樣配備NPU的Core Ultra「Meteor Lake」構架。

英特爾的 Meteor Lake SoC將CPU,NPU,GPU結合在一起,來應對未來可能出現的不同AI應用。
Meteor Lake擁有三個功能齊全的AI引擎,Arc Xe-LPG顯卡保證了AI需求的算力上限。
相比之下,NPU及其兩個神經計算引擎用來承擔持續的人工智能工作負載,以進一步提高能效。
CPU本身以及Redwood Cove(P)和Crestmont(E)內核的組合可以以更低的延遲處理AI工作負載,從而提高精度。
最近有消息稱,微軟最新推出的Windows 11 DirectML預覽版將為Core Ultra NPU提供初步支持。
隨著微軟在操作系統層面對于AI的全面更新和支持,英特爾和AMD在CPU中加入了應對AI負載的NPU,入門級AI應用的硬件競爭必將越演越烈。

本地化運行自己的大模型,英偉達誓要將AI應用的門檻打下來
除了不斷更新自己的硬件收割科技大廠,英偉達在前段時間也上線了自己第一款支持本地運行的大模型系統——Chat with RTX。

它可以讓用戶利用手上的消費級GPU本地化地運行開源LLM,利用用戶自己的數據和知識庫,定制一款專屬于自己的聊天機器人。
這是英偉達推出的第一款面向普通消費者的AI應用。
簡單來說,它就是英偉達自己推出的開源大模型啟動器,目的是讓沒有技術背景的消費者能夠真的在自己的設備上運行大模型。
用戶想要運行Chat with RTX的要求也非常簡單,只要是使用英偉達消費級的30/40系的顯卡,或者Ampere/Ada GPU,擁有16G的內存,100G的空余硬盤空間,就能使用。

安裝模型的時候,會自動根據顯存提供支持的模型。

安裝完成后,通過瀏覽器界面就能直接使用聊天機器人了。
而現階段,只支持開源的Mistral 7B和 Llama2 13B。
但因為顯存的關系,剛剛發布的RTX 500和1000 Ada似乎還不能運行這個系統。
但主要是因為兩款支持的開源模型尺寸對于消費級GPU來說還是比較大。
如果未來英偉達能讓Chat with RTX支持更多的開源模型,比如說微軟前段時間推出的Phi-2 2.7B,那么即便是4G顯存的RTX 500Ada也將可以本地化地跑大模型了。



























