













微軟、國科大開啟1Bit時代:大模型轉三進制,速度快4倍能耗降至1/41
把大模型的權重統統改成三元表示,速度和效率的提升讓人害怕。
今天凌晨,由微軟、國科大等機構提交的一篇論文在 AI 圈里被人們爭相轉閱。該研究提出了一種 1-bit 大模型,實現效果讓人只想說兩個字:震驚。

如果該論文的方法可以廣泛使用,這可能是生成式 AI 的新時代。
對此,已經有人在暢想 1-bit 大模型的適用場景,看起來很適合物聯網,這在以前是不可想象的。

人們還發現,這個提升速度不是線性的 —— 而是,模型越大,這么做帶來的提升就越大。

還有這種好事?看起來英偉達要掂量掂量了。
近年來,大語言模型(LLM)的參數規模和能力快速增長,既在廣泛的自然語言處理任務中表現出了卓越的性能,也為部署帶來了挑戰,并引發人們擔憂高能耗會對環境和經濟造成影響。
因此,使用后訓練(post-training)量化技術來創建低 bit 推理模型成為上述問題的解決方案。這類技術可以降低權重和激活函數的精度,顯著降低 LLM 的內存和計算需求。目前的發展趨勢是從 16 bits 轉向更低的 bit,比如 4 bits。然而,雖然這類量化技術在 LLM 中廣泛使用,但并不是最優的。
最近的工作提出了 1-bit 模型架構,比如 2023 年 10 月微軟研究院、國科大和清華大學的研究者推出了 BitNet,在降低 LLM 成本的同時為保持模型性能提供了一個很有希望的技術方向。
BitNet 是第一個支持訓練 1-bit 大語言模型的新型網絡結構,具有強大的可擴展性和穩定性,能夠顯著減少大語言模型的訓練和推理成本。與最先進的 8-bit 量化方法和全精度 Transformer 基線相比,BitNet 在大幅降低內存占用和計算能耗的同時,表現出了極具競爭力的性能。
此外,BitNet 擁有與全精度 Transformer 相似的擴展法則(Scaling Law),在保持效率和性能優勢的同時,還可以更加高效地將其能力擴展到更大的語言模型上, 從而讓 1 比特大語言模型(1-bit LLM)成為可能。
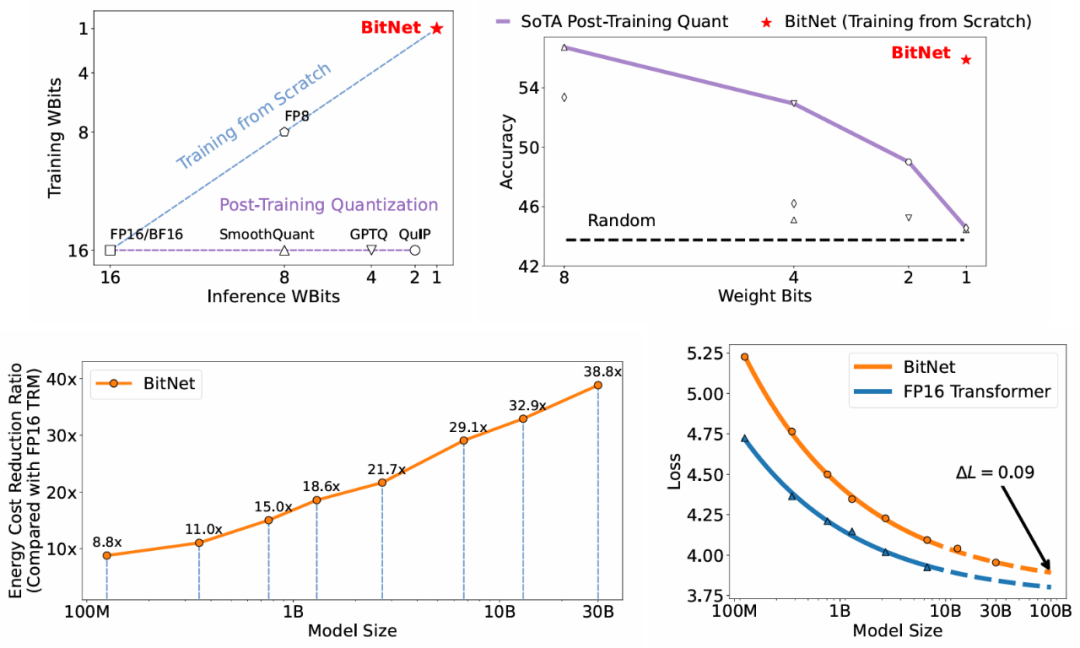
BitNet 從頭訓練的 1-bit Transformers 在能效方面取得了有競爭力的結果。來源:https://arxiv.org/pdf/2310.11453.pdf
如今,微軟研究院、國科大同一團隊(作者部分變化)的研究者推出了 BitNet 的重要 1-bit 變體,即 BitNet b1.58,其中每個參數都是三元并取值為 {-1, 0, 1}。他們在原來的 1-bit 上添加了一個附加值 0,得到二進制系統中的 1.58 bits。
BitNet b1.58 繼承了原始 1-bit BitNet 的所有優點,包括新的計算范式,使得矩陣乘法幾乎不需要乘法運算,并可以進行高度優化。同時,BitNet b1.58 具有與原始 1-bit BitNet 相同的能耗,相較于 FP16 LLM 基線在內存消耗、吞吐量和延遲方面更加高效。

- 論文地址:https://arxiv.org/pdf/2402.17764.pdf
- 論文標題:The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
此外,BitNet b1.58 還具有兩個額外優勢。其一是建模能力更強,這是由于它明確支持了特征過濾,在模型權重中包含了 0 值,顯著提升了 1-bit LLM 的性能。其二實驗結果表明,當使用相同配置(比如模型大小、訓練 token 數)時,從 3B 參數規模開始, BitNet b1.58 在困惑度和最終任務的性能方面媲美全精度(FP16)基線方法。
如下圖 1 所示,BitNet b1.58 為降低 LLM 推理成本(延遲、吞吐量和能耗)并保持模型性能提供了一個帕累托(Pareto)解決方案。

BitNet b1.58 介紹
BitNet b1.58 基于 BitNet 架構,并且用 BitLinear 替代 nn.Linear 的 Transformer。BitNet b1.58 是從頭開始訓練的,具有 1.58 bit 權重和 8 bit 激活。與原始 BitNet 架構相比,它引入了一些修改,總結為如下:

用于激活的量化函數與 BitNet 中的實現相同,只是該研究沒有將非線性函數之前的激活縮放到 [0, Q_b] 范圍。相反,每個 token 的激活范圍為 [?Q_b, Q_b],從而消除零點量化。這樣做對于實現和系統級優化更加方便和簡單,同時對實驗中的性能產生的影響可以忽略不計。
與 LLaMA 類似的組件。LLaMA 架構已成為開源大語言模型的基本標準。為了擁抱開源社區,該研究設計的 BitNet b1.58 采用了類似 LLaMA 的組件。具體來說,它使用了 RMSNorm、SwiGLU、旋轉嵌入,并且移除了所有偏置。通過這種方式,BitNet b1.58 可以很容易的集成到流行的開源軟件中(例如,Huggingface、vLLM 和 llama.cpp2)。
實驗及結果
該研究將 BitNet b1.58 與此前該研究重現的各種大小的 FP16 LLaMA LLM 進行了比較,并評估了模型在一系列語言任務上的零樣本性能。除此之外,實驗還比較了 LLaMA LLM 和 BitNet b1.58 運行時的 GPU 內存消耗和延遲。
表 1 總結了 BitNet b1.58 和 LLaMA LLM 的困惑度和成本:在困惑度方面,當模型大小為 3B 時,BitNet b1.58 開始與全精度 LLaMA LLM 匹配,同時速度提高了 2.71 倍,使用的 GPU 內存減少了 3.55 倍。特別是,當模型大小為 3.9B 時,BitNet b1.58 的速度是 LLaMA LLM 3B 的 2.4 倍,消耗的內存減少了 3.32 倍,但性能顯著優于 LLaMA LLM 3B。

表 2 結果表明,隨著模型尺寸的增加,BitNet b1.58 和 LLaMA LLM 之間的性能差距縮小。更重要的是,BitNet b1.58 可以匹配從 3B 大小開始的全精度基線的性能。與困惑度觀察類似,最終任務( end-task)結果表明 BitNet b1.58 3.9B 優于 LLaMA LLM 3B,具有更低的內存和延遲成本。
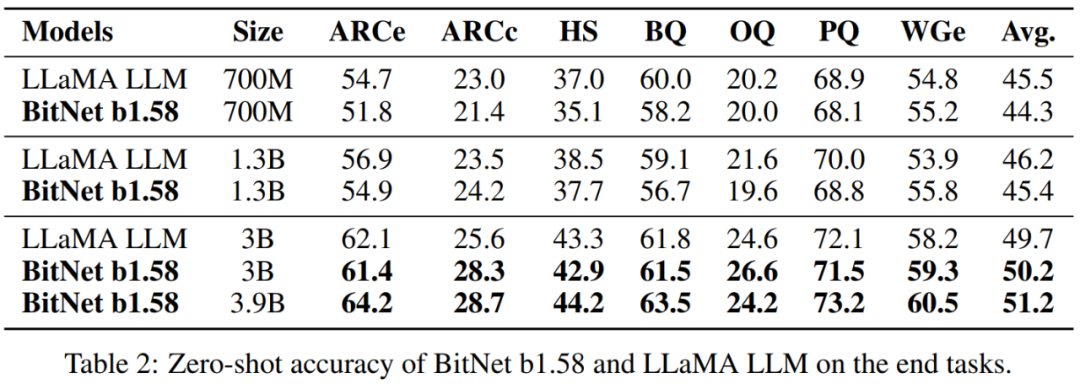
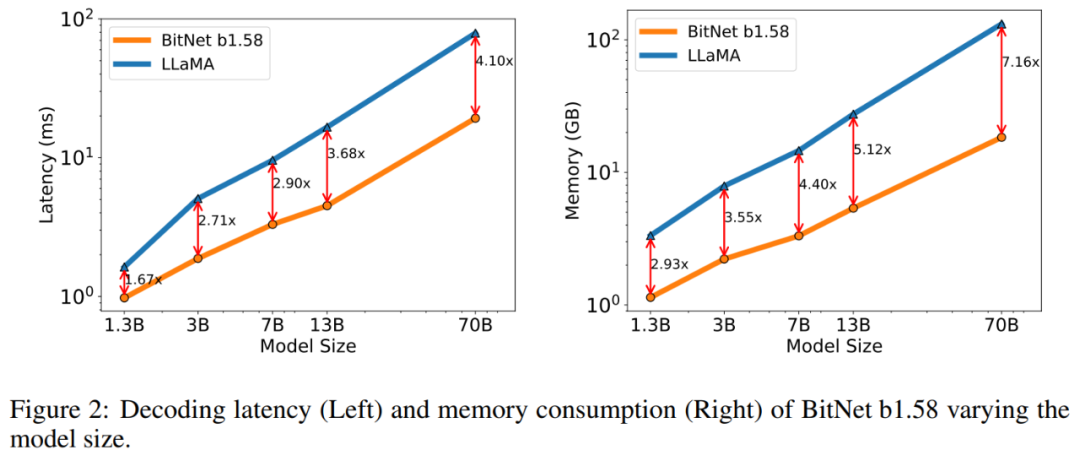
內存和延遲:該研究進一步將模型大小擴展到 7B、13B 和 70B 并評估成本。圖 2 顯示了延遲和內存的趨勢,隨著模型大小的增加,增長速度(speed-up)也在增加。特別是,BitNet b1.58 70B 比 LLaMA LLM 基線快 4.1 倍。這是因為 nn.Linear 的時間成本隨著模型大小的增加而增加,內存消耗同樣遵循類似的趨勢。延遲和內存都是用 2 位核測量的,因此仍有優化空間以進一步降低成本。
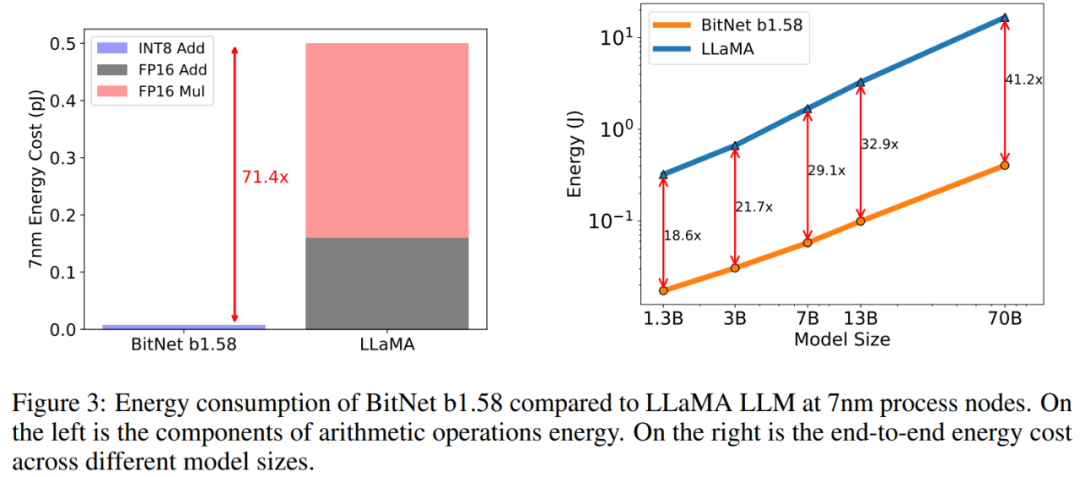
能耗。該研究還對 BitNet b1.58 和 LLaMA LLM 的算術運算能耗進行了評估,主要關注矩陣乘法。圖 3 說明了能耗成本的構成。BitNet b1.58 的大部分是 INT8 加法計算,而 LLaMA LLM 則由 FP16 加法和 FP16 乘法組成。根據 [Hor14,ZZL22] 中的能量模型,BitNet b1.58 在 7nm 芯片上的矩陣乘法運算能耗節省了 71.4 倍。
該研究進一步報告了能夠處理 512 個 token 模型的端到端能耗成本。結果表明,隨著模型規模的擴大,與 FP16 LLaMA LLM 基線相比,BitNet b1.58 在能耗方面變得越來越高效。這是因為 nn.Linear 的百分比隨著模型大小的增加而增長,而對于較大的模型,其他組件的成本較小。
吞吐量。該研究比較了 BitNet b1.58 和 LLaMA LLM 在 70B 參數體量上在兩個 80GB A100 卡上的吞吐量,使用 pipeline 并行性 [HCB+19],以便 LLaMA LLM 70B 可以在設備上運行。實驗增加了 batch size,直到達到 GPU 內存限制,序列長度為 512。表 3 顯示 BitNet b1.58 70B 最多可以支持 LLaMA LLM batch size 的 11 倍,從而將吞吐量提高 8.9 倍。

更多技術細節請查看原論文。





















