一文搞懂:AI、機器學習與深度學習的聯系與區別
在當今科技日新月異的浪潮中,人工智能(Artificial Intelligence, AI)、機器學習(Machine Learning, ML)與深度學習(Deep Learning, DL)如同璀璨星辰,引領著信息技術的新浪潮。這三個詞匯頻繁出現在各種前沿討論和實際應用中,但對于許多初涉此領域的探索者來說,它們的具體含義及相互之間的內在聯系可能仍籠罩著一層神秘面紗。
那讓我們先來看看這張圖。

由此可見,深度學習、機器學習、人工智能三者之間有著層層遞進的緊密聯系,「深度學習」是「機器學習」的一個分支,而「機器學習」是「人工智能」的一個分支。
何為人工智能?
人工智能(Artificial Intelligence, AI)是一個籠統且寬泛的概念,它的終極目標即是構建能夠模擬、延伸乃至超越人類智能的計算系統。具體應用在以下領域:
- 圖像識別(Image Recognition)是AI的一個重要分支,致力于研究如何使計算機通過視覺傳感器獲取數據,并基于這些數據進行分析以識別圖像中的物體、場景、行為等信息,模擬人眼和大腦對視覺信號的認知和理解過程。
- 自然語言處理(Natural Language Processing, NLP)則是讓計算機理解和生成人類自然語言的能力,涵蓋了諸如文本分類、語義解析、機器翻譯等多種任務,力圖模擬人類在聽說讀寫等方面的智能行為。
- 計算機視覺(Computer Vision, CV)更廣義地包含了圖像識別,它還涉及到圖像分析、視頻分析、三維重建等多個方面,旨在讓計算機從二維或三維圖像中“看見”并理解世界,這是對人類視覺系統的深層次模仿。
- 知識圖譜(Knowledge Graph, KG)則是一種結構化的、用于存儲和表示實體及其相互間復雜關系的數據模型,它模擬的是人類在認知過程中積累和利用知識的能力,以及基于已有知識進行推理和學習的過程。
這些看似高端的技術確實都是圍繞著“模擬人的智能”這一核心理念展開,只是針對不同的感知維度(如視覺、聽覺、思考邏輯等)進行了專項研究與應用開發,共同推動著人工智能技術的發展和進步。
何為機器學習?
機器學習(Machine Learning, ML)是AI的一個重要分支,它通過讓計算機系統基于一些算法從數據中自動“學習”規律和模式,并據此進行預測或決策,從而模擬、延伸和擴展了人類智能。
例如,在訓練一個貓識別模型時,機器學習處理的過程如下:
- 數據預處理:首先,對收集到的大量貓和非貓圖片進行預處理,包括縮放尺寸、灰度化、歸一化等操作,并將圖片轉換為特征向量表示,這些特征可能來自于手動設計的特征提取技術,比如Haar-like特征、局部二進制模式(LBP)或其他計算機視覺領域常用的特征描述子。
- 特征選擇與降維:根據問題特點選擇關鍵特征,去除冗余和無關信息,有時還會使用PCA、LDA等降維方法進一步減少特征維度,提高算法效率。
- 模型訓練:接著用預處理過的帶有標簽的數據集來訓練選定的機器學習模型,通過調整模型參數優化模型性能,使得模型能夠在給定特征的情況下區分出貓和非貓的圖片。
- 模型評估與驗證:訓練完成后,使用獨立的測試集對模型進行評估,以確保模型具有良好的泛化能力,能夠準確地應用于未見過的新樣本。
常用的10大機器學習算法有:決策樹、隨機森林、邏輯回歸、SVM、樸素貝葉斯、K最近鄰算法、K均值算法、Adaboost算法、神經網絡、馬爾科夫等。
何為深度學習?
深度學習(Deep Learning, DL)則又是機器學習的一種特殊形式,它主要依賴于深層神經網絡結構來模擬人腦處理信息的方式,并自動從數據中提取復雜的特征表示。
例如,在訓練一個貓識別模型時,深度學習處理的過程如下:
(1) 數據預處理與準備:
- 收集大量的包含貓和非貓圖像的數據集,并對其進行清洗、標注,確保每張圖片都有對應的標簽(如“貓”或“非貓”)。
- 圖像預處理:將所有圖像調整為統一大小,進行歸一化處理、數據增強等操作。
(2) 模型設計與搭建:
- 選擇深度學習架構,對于圖像識別任務,通常使用卷積神經網絡(Convolutional Neural Network, CNN)。CNN能有效提取圖像的局部特征,并通過多層結構進行抽象表示。
- 構建模型層次,包括卷積層(用于特征提取)、池化層(減少計算量和防止過擬合)、全連接層(對特征進行整合分類)以及可能的批量歸一化層、激活函數(如ReLU、sigmoid等)。
(3) 初始化參數與設置超參數:
- 初始化模型中各層權重和偏置,可以采用隨機初始化或者特定初始化策略。
- 設置學習率、優化器(如SGD、Adam等)、批次大小、訓練周期(epoch)等超參數。
(4) 前向傳播:
- 將經過預處理的圖像輸入到模型中,通過各層的卷積、池化、線性變換等操作,最終得到輸出層的預測概率分布,即模型判斷輸入圖片是貓的概率。
(5) 損失函數與反向傳播:
- 使用交叉熵損失函數或者其他適合的損失函數來衡量模型預測結果與真實標簽之間的差異。
- 計算損失后,執行反向傳播算法,計算損失關于模型參數的梯度,以便于更新參數。
(6) 優化與參數更新:
- 利用梯度下降或其他優化算法根據梯度信息調整模型參數,目的是使損失函數最小化。
- 在每個訓練迭代過程中,模型會不斷學習和調整參數,逐步提高對貓圖像的識別能力。
(7) 驗證與評估:
- 定期在驗證集上評估模型性能,監測準確率、精確率、召回率等指標的變化情況,以此指導模型訓練過程中的超參數調整和早停策略。
(8) 訓練完成與測試:
- 當模型在驗證集上的表現趨于穩定或達到預先設定的停止條件時,停止訓練。
- 最后,在獨立的測試集上評估模型的泛化能力,確保模型能夠有效地對未見過的新樣本進行貓的識別。
深度學習和機器學習的區別
深度學習和機器學習的區別在于:
1.解決問題的方法
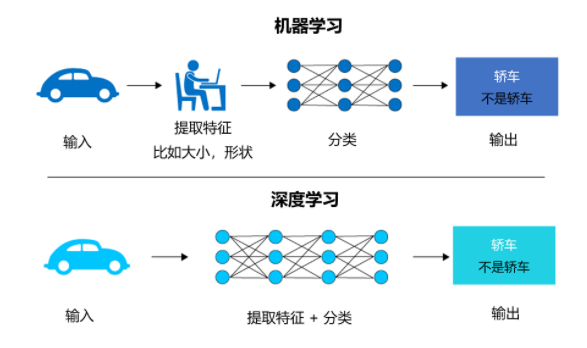
機器學習算法通常依賴于人為設計的特征工程,即根據問題背景知識預先抽取關鍵特征,然后基于這些特征構建模型并進行優化求解。
深度學習則采取了端到端的學習方式,通過多層非線性變換自動生成高級抽象特征,并且這些特征是在整個訓練過程中不斷優化得到的,無需手動選擇和構造特征,更接近于人類大腦的認知處理方式。
舉個例子,如果你要寫一個軟件讓它去識別一輛轎車,如果使用機器學習,你需要人為提取汽車的特征,比如大小和形狀等;而如果你使用深度學習,那么人工智能神經網絡會自行提取這些特征,不過它需要大量的標識為轎車的圖片來進行學習。
2.應用場景
機器學習在指紋識別、特征物體檢測等領域的應用基本達到了商業化的要求。
深度學習主要應用于文字識別、人臉技術、語義分析、智能監控等領域。目前在智能硬件、教育、醫療等行業也在快速布局。
3.所需數據量
機器學習算法在小樣本情況下也能展現出較好的性能,對于一些簡單任務或者特征易于提取的問題,較少的數據即可達到滿意效果。
深度學習通常需要大量的標注數據來訓練深層神經網絡,其優勢在于能從原始數據中直接學習復雜的模式和表示,尤其當數據規模增大時,深度學習模型的性能提升更為顯著。
4.執行時間
訓練階段,由于深度學習模型的層次更多、參數數量龐大,故訓練過程往往較為耗時,需要高性能計算資源的支持,如GPU集群。
相較之下,機器學習算法(尤其是那些輕量級的模型)在訓練時間和計算資源需求上通常較小,更適合于快速迭代和實驗驗證。