Data Fabric 在數(shù)據(jù)集成場景的實踐
一、什么是 Data Fabric 與數(shù)據(jù)虛擬化
1. 集中式數(shù)倉面臨的困境
在正式介紹 Data Fabric 之前,先來看一下現(xiàn)有數(shù)倉體系面臨的問題。提到數(shù)倉,很多做數(shù)據(jù)的同學(xué)都會想到 ETL,以及 Hive、Hadoop、Spark 這些技術(shù)。但很多數(shù)倉使用者,包括數(shù)據(jù)的生產(chǎn)者、消費者、甚至是老板,都對數(shù)倉有著各種不滿。
從數(shù)據(jù)生產(chǎn)者的角度來看,他們每天會面臨大量的分析、取數(shù)需求,從前端提出的需求各種各樣,甚至一個需求還會不斷變化。從數(shù)據(jù)消費者的角度來看,比如分析師、運營同學(xué),他們常常覺得需求難以得到滿足,可能要等候排期,或者是數(shù)據(jù)還沒有等等。
再站在老板的視角,數(shù)倉跟物理世界的倉庫類似,都是用來存放東西的,只不過數(shù)倉存儲的是數(shù)據(jù),數(shù)據(jù)搬進(jìn)去之后,還需要分門別類去維護(hù),以便在要用的時候能快速找到并拿出來。但是它跟物理倉庫有一個很大的差別,那就是物理倉庫是有進(jìn)有出的,而數(shù)據(jù)倉庫卻只進(jìn)不出,隨著業(yè)務(wù)的快速增長,數(shù)據(jù)倉庫也會急劇增長,但數(shù)據(jù)倉庫能解決的問題卻不是成比例增長的,其業(yè)務(wù)價值不但沒有成比例增加,反而由于數(shù)倉規(guī)模的增大導(dǎo)致投入和維護(hù)成本成急劇增加,進(jìn)而導(dǎo)致很多數(shù)倉建設(shè)有一定時間的公司都急需數(shù)據(jù)治理。
其實數(shù)據(jù)治理本質(zhì)就是通過人為手段去解決數(shù)倉業(yè)務(wù)價值不能匹配的問題,因此,站在老板視角來看,數(shù)倉的投入產(chǎn)出比是極低的。所以傳統(tǒng)數(shù)倉有兩個很嚴(yán)重的矛盾:第一個是生產(chǎn)者跟消費者供需的矛盾,第二個是數(shù)倉整體投入產(chǎn)出比的矛盾。
對于用戶來講,可能有些數(shù)據(jù)在數(shù)倉里面,有些數(shù)據(jù)在 MySQL 里面,有些數(shù)據(jù)甚至是一個文件,他會希望拿到這些數(shù)據(jù)就可以直接去分析,而不是還得先把這個數(shù)據(jù)入倉,再轉(zhuǎn)換一下,最后才能用。這就是傳統(tǒng)數(shù)倉與實際需求之間的 GAP。

總結(jié)來講,傳統(tǒng)集中式數(shù)倉面臨著三個方面的挑戰(zhàn):第一個方面是成本;第二個方面是合規(guī),因為大家對數(shù)據(jù)隱私方面的要求越來越高,企業(yè)、政府以及法律法規(guī)上也越來越嚴(yán)格;第三個方面是效率。
2. Data Fabric,新一代數(shù)據(jù)架構(gòu)的思想
接下來看一下 Data Fabric。Gartner 發(fā)布的《2021 年十大數(shù)據(jù)和分析技術(shù)趨勢》中,Data Fabric 被列在首位,它是一項加速變革的技術(shù)。作為一項顛覆性的技術(shù),Data Fabric 的出現(xiàn)是有它的原因的。首先,Data Fabric 認(rèn)為哪怕企業(yè)有成熟的數(shù)倉,甚至有數(shù)據(jù)湖,仍然需要 Data Fabric。因為在現(xiàn)實世界中我們無法把所有的數(shù)據(jù)物理集中到一個地方給用戶使用,過去數(shù)十年無數(shù)企業(yè)和技術(shù)方案都驗證過,這是一條很難實現(xiàn)并只能停留在理想世界中的方案,這是其最基本的理念。

Data Fabric 到底是什么?Data Fabric 中文翻譯成數(shù)據(jù)網(wǎng)格。而數(shù)據(jù)的虛擬化是實現(xiàn)數(shù)據(jù)網(wǎng)格化很關(guān)鍵的一項技術(shù)。當(dāng)然 Data Fabric 還有一些其他的相關(guān)概念,比如 Data Ops、主動元數(shù)據(jù)等等。本文主要介紹數(shù)據(jù)虛擬化這一部分。如果大家對其他 Data Fabric 概念感興趣,可以通過上圖中的二維碼來獲取我們的 Data Fabric 白皮書。
3. 數(shù)據(jù)虛擬化讓數(shù)據(jù)隨手可得、按需計算

我們將數(shù)據(jù)虛擬化定義為三層。第一層是連接層,最主要的作用是為各種各樣的異構(gòu)存儲介質(zhì),不同的物理層定義一個統(tǒng)一的訪問接入模型層,將異構(gòu)數(shù)據(jù)的訪問標(biāo)準(zhǔn)化。第二層是真正做數(shù)據(jù)處理加工的地方,叫合并層。第三層是消費層,將加工后的數(shù)據(jù)提供給消費端使用,接下來會借助案例詳細(xì)展開各層的作用。
二、數(shù)據(jù)虛擬化在數(shù)據(jù)集成場景落地實踐
前文中介紹了 Data Fabric 以及數(shù)據(jù)虛擬化的概念。接下來通過一個真實案例,來介紹如何將數(shù)據(jù)虛擬化技術(shù)應(yīng)用到實際場景中。
1. 在某券商應(yīng)用案例

這是一個券商的案例。在用我們的方案之前,他們是沒有數(shù)倉的,報表是通過寫 Java 程序去實現(xiàn)的。客戶經(jīng)過調(diào)研發(fā)現(xiàn)所有的同行都在使用 Hadoop 這一套大數(shù)據(jù)體系,去構(gòu)建一套完整的數(shù)據(jù)倉庫,但對他們來講這種方案投入成本太多,而且方案也太重了,因此他們急需更加輕量化的數(shù)據(jù)解決方案。
這個券商客戶那邊有很多業(yè)務(wù)庫,并且這些業(yè)務(wù)庫沉淀了很多年,有些放在 MySQL 里面,有些放在 Oracle 里面,也有些在 SQL Server,甚至還有一些網(wǎng)上爬下來的數(shù)據(jù)。他們希望通過這些數(shù)據(jù)匯集在一起來實現(xiàn)企業(yè)的信息化大屏,包括資產(chǎn)管理、數(shù)據(jù)管理月報、數(shù)據(jù)分析等等,為管理層及各個業(yè)務(wù)部門清晰地展示企業(yè)關(guān)鍵業(yè)務(wù)經(jīng)營情況。
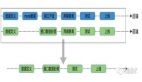
我們提供的解決方案是,首先這些數(shù)據(jù)源通過虛擬化邏輯層連接,這一層映射成最原始的 PDS(Physical Dataset),只邏輯定義,不做物理數(shù)據(jù)的遷移。基于這層邏輯映射的 PDS 之上,再去定義各層,與數(shù)倉的分層架構(gòu)類似,只不過這里的 DWD、DWS、ADS 都是虛擬化的 VDS(Virtual Dataset)。消費端的報告、報表直連到虛擬化引擎,像訪問傳統(tǒng)數(shù)據(jù)庫里面的普通物理表一樣使用任一層里面的 VDS 數(shù)據(jù)。
其中有兩個比較關(guān)鍵的策略。
第一個策略是客戶希望能保留數(shù)倉的功能。首先,保留數(shù)倉數(shù)據(jù)的歷史性,所以我們?yōu)樗麄儤?gòu)建的第一個策略就是在 DWD 明細(xì)這一層,統(tǒng)一按照天去保留歷史快照,與傳統(tǒng)數(shù)倉一樣,只不過是基于虛擬化技術(shù)去做,引擎會在這一層統(tǒng)一構(gòu)建物理作業(yè)。
第二個策略是 DWD 之上的這一層,按需去做物理作業(yè)的構(gòu)建。
有了這兩個策略之后,通過我們的策略引擎去生成真正的作業(yè)。當(dāng)用戶查詢視圖或虛擬表時,虛擬化引擎會根據(jù)用戶的查詢 SQL 路由到真正的物理數(shù)據(jù)上去做查詢(底層會基于不同物理作業(yè)產(chǎn)生的數(shù)據(jù)做關(guān)聯(lián)和合并)。
2. 在某券商應(yīng)用效果

通過上述方案,發(fā)現(xiàn)沒有采用傳統(tǒng)的數(shù)據(jù)體系,也能把常見、典型的用戶場景實現(xiàn)出來。客戶連到邏輯數(shù)據(jù)平臺里面的庫有一百多個,PDS 層虛擬映射的表有兩萬多張。但實際上完成所有關(guān)注的看板、報表,真正用到的表還不到 1%。所以有大量的表對這些經(jīng)營報表是沒有用處的。實際的物理作業(yè)也不多,不超過 100 個,支撐其一百多個核心指標(biāo)。
如果采用傳統(tǒng)數(shù)倉的方案,因為其數(shù)據(jù)散落在各個業(yè)務(wù)庫,如果把兩萬多張表都同步過來,而且是在數(shù)倉里面去寫 ODS 的話,那么成本和代價是完全不一樣的。而我們的方案在以下三個方面帶來了顯著的提升:
- 首先,整個交付效率相對于以前的 Java 開發(fā)提升了至少十倍。即使與傳統(tǒng)數(shù)倉方案對比,也是有明顯優(yōu)勢的。
- 第二,整個研發(fā)鏈路的管理工作量減少了 30%。因為在我們的方案中傳統(tǒng) ETL 中的 E 和 L 層都虛擬化掉了。
- 第三,減少了計算存儲的成本。因為兩萬多張表里面,用到的物理作業(yè)很少。所以整體的成本相對于傳統(tǒng)方案來講,是有巨大節(jié)省的。
3. 數(shù)據(jù)虛擬化應(yīng)用架構(gòu)

上圖中展示了兩種典型的數(shù)據(jù)虛擬化應(yīng)用架構(gòu),適用于不同的場景。
前面的券商案例中,用的是典型的單層虛擬化架構(gòu),通過一個虛擬化層,把公司所有源的數(shù)據(jù)連接在一起。
多層虛擬化架構(gòu),更多用于集團(tuán)性公司,或者分地域的公司。因為各種各樣的原因(比如權(quán)限、安全、合規(guī)、數(shù)據(jù)歸屬和管理權(quán)等等),如果企業(yè)不希望這些數(shù)據(jù)從各個地域或者分公司物理拷貝出來,如果上層還要使用這些數(shù)據(jù),那么多層虛擬化非常適合去解決這類問題。
三、數(shù)據(jù)虛擬化同傳統(tǒng)方案的差異
1. 數(shù)據(jù)虛擬化讓 ETL 專注于 T(Transform)
接下來看一下虛擬化方案與傳統(tǒng)方案的差別。

數(shù)據(jù)虛擬化并不是突然冒出來的一個概念,而是經(jīng)歷了一系列的發(fā)展過程。早期的數(shù)據(jù)倉庫,是 ETL 的模式,隨著各種非結(jié)構(gòu)化數(shù)據(jù)的出現(xiàn),慢慢演變成了數(shù)據(jù)湖的解決方案。數(shù)據(jù)湖中最大的變化是把 transform 這個階段放到了最終使用數(shù)據(jù)的時候去執(zhí)行,也就是變成了 ELT。但是不管是數(shù)據(jù)倉庫還是數(shù)據(jù)湖,都是集中化的物理數(shù)據(jù)存儲方案。而邏輯數(shù)倉是基于虛擬化技術(shù)的數(shù)據(jù)解決方案。在邏輯數(shù)倉里面,更強調(diào)讓用戶只聚焦在 transform,而不需要關(guān)注 E 和 L。

通過上圖中的對比,可以看到邏輯數(shù)倉與傳統(tǒng)數(shù)倉的差別。首先邏輯數(shù)倉完全縮減掉了數(shù)據(jù)抽取過程,它只是一個邏輯映射,相當(dāng)于把所有庫連的元數(shù)據(jù)爬進(jìn)來,數(shù)據(jù)就可用了。第二個差異是在消費端,在邏輯數(shù)倉中不需要把數(shù)據(jù)導(dǎo)到 OLAP 引擎里去,直接就能給 BI、報表或其它工具用。E 和 L 這兩層去掉之后,用戶可以將重心放在中間 transform 這一層,專注于處理數(shù)據(jù)、加工數(shù)據(jù)。
真正做到這個技術(shù)可用,有兩個關(guān)鍵點。第一個是自動化生成 ETL 作業(yè)。其實讓用戶聚焦在 transform 里面,通過虛擬化的技術(shù)去實現(xiàn)他的需求,不代表沒有 ETL 作業(yè),ETL 還是在的,只不過這個過程自動化了。第二個是因為用戶不會感知到物理作業(yè),所以當(dāng)有作業(yè)產(chǎn)生物理數(shù)據(jù)時,這些查詢的改寫、構(gòu)建,都由虛擬化引擎完成了,對用戶是透明的。
2. 數(shù)據(jù)虛擬化=Presto?
大家可能會有兩個疑問,一是這個虛擬化方案與傳統(tǒng)的 Presto 方案有什么差別,二是這里的 ETL job,是不是類似于物化視圖,接下來解答一下這兩個問題。

首先絕大部分用 Presto 的場景都是放在ETL的最末端,當(dāng)然這跟 Presto 的架構(gòu)也有關(guān)系。因為 Presto 就是一個 MPP 引擎,它本身是面向 OLAP 查詢的,只不過支持跨源查詢的能力。如果想延伸到數(shù)據(jù)倉庫這一層的話,就意味著需要支持大規(guī)模數(shù)據(jù)穩(wěn)定且低成本的構(gòu)建能力,而這是 Presto 這類純 OLAP 引擎架構(gòu)所支持不了的,因為 OLAP 引擎的設(shè)計就是追求最大化的利用所有計算和內(nèi)存資源將每個查詢的性能拉到極致。所以數(shù)據(jù)虛擬化不等于 Presto,因為它可以解決一部分類似于虛擬化的問題,但是解決不了傳統(tǒng)數(shù)倉的困境。Aloudata 的數(shù)據(jù)虛擬化是可以解決全場景的。最關(guān)鍵的部分在于 RP 技術(shù)的突破。
RP 與物化視圖的差別在哪里呢?舉個簡單的例子,傳統(tǒng)的物化視圖,是為了加速一些大的 SQL 而誕生的,其實更多的是一種加速緩存,也就意味著數(shù)據(jù)丟掉了是沒關(guān)系的。但是在 RP 這一層,因為 RP 是對標(biāo) ETL 研發(fā)的作業(yè),如果作業(yè)有問題,或者是數(shù)據(jù)有問題,查詢不會繞過它。所以 RP 的定位與物化視圖有著很大的不同,也正因為此,兩者在技術(shù)設(shè)計方案上也存在很大的差別。
首先,RP 會支持多層的構(gòu)建和調(diào)度,與真實的物理上生成的 ETL 作業(yè)沒有差別,也會有強弱依賴,也會有分區(qū)對齊,也會有跨周期依賴等等。只不過這些是自動生成的,而不是人工去配置的。同時,RP 也支持大規(guī)模數(shù)據(jù)量構(gòu)建,也支持自動推導(dǎo)是全量構(gòu)建、增量構(gòu)建,還是分區(qū)構(gòu)建。
另外,在物化視圖中,數(shù)據(jù)一旦構(gòu)建出錯就失效了,數(shù)據(jù)就丟了。但在 RP 里面是不會的,因為數(shù)據(jù)有多個版本,這是很重要的一個能力。
RP 同物化視圖一樣也會基于算子實現(xiàn) SPJG 的查詢改寫能力,但同時它也極大增強了物化改寫能力。在傳統(tǒng)物化改寫中,對于 SQL 的復(fù)雜性是有一定限制的。例如:在 VDS 多層嵌套的場景,多層視圖展開后會生成一個極其龐大的算子樹,傳統(tǒng)物化改寫算法在這類規(guī)模的算子樹上改寫,性能和準(zhǔn)確性都存在極大的限制。
最后,RP 技術(shù)根據(jù)用戶的查詢歷史以及資產(chǎn)的關(guān)系構(gòu)建了智能加速方案。并且能夠自動回收。在數(shù)據(jù)倉庫里面,作業(yè)越來越多,很多沒有用的作業(yè)無人負(fù)責(zé)下線,必然要去人肉治理,以降低計算、存儲成本。在虛擬化之后,因為消費端對作業(yè)是否在用是有感知的,所以能做到自動回收。這也是相對于傳統(tǒng)數(shù)據(jù)治理一個很重要的差別。
3. 傳統(tǒng)數(shù)倉VS邏輯數(shù)倉

邏輯數(shù)倉與傳統(tǒng)數(shù)倉的區(qū)別可以總結(jié)為以下幾個維度:
- 成本方面,邏輯數(shù)倉的實施成本更低,因為只需要部署一套虛擬化引擎,所以也比較輕巧。同時,存算成本也比較低,因為是按需計算的,數(shù)據(jù)隨時可用。另外,自動數(shù)據(jù)治理,可以將重復(fù)資源自動合并、復(fù)用,并基于一定策略自動回收。
- 安全合規(guī)方面,數(shù)據(jù)邏輯集中,可以更好地控制其訪問策略、安全策略等。
- 效率方面,因為它省略掉了很多過程,所以整個研發(fā)效率更高,而且門檻也會比較低。
- 整體技術(shù)方案簡單,一套方案就可以很好地滿足主流數(shù)據(jù)報表和分析場景。
既然邏輯數(shù)倉有這么多優(yōu)點,那么有了邏輯數(shù)倉,傳統(tǒng)數(shù)倉就不再需要了嗎?顯然不是。因為傳統(tǒng)數(shù)倉經(jīng)過多年的發(fā)展,有其自己的理論、技術(shù)體系、人才的沉淀。傳統(tǒng)數(shù)倉最大的問題是無法適應(yīng)非穩(wěn)定的、臨時性的或者創(chuàng)新性的需求,這些業(yè)務(wù)需求有個共同的訴求就是取數(shù)、用數(shù)的敏捷化,這是傳統(tǒng)數(shù)倉架構(gòu)天然無法具備的。所以邏輯數(shù)倉更像是傳統(tǒng)數(shù)倉的補充,通過傳統(tǒng)數(shù)倉加上邏輯數(shù)倉,可以滿足更多的場景。
四、總結(jié)
在本次分享中講到了很多概念,包括 Data Fabric、數(shù)據(jù)虛擬化、邏輯數(shù)倉以及 RP。下圖中展示了它們之間的關(guān)系。

首先 Data Fabric 是一個理念,數(shù)據(jù)虛擬化是 Data Fabric 理念下數(shù)據(jù)網(wǎng)格化能力的具體實現(xiàn)。有了數(shù)據(jù)虛擬化技術(shù),我們?nèi)?gòu)建了一個虛擬化的數(shù)據(jù)倉庫,叫做邏輯數(shù)倉。而真正的突破,是因為有了 RP 這樣的技術(shù),才讓數(shù)據(jù)虛擬化能夠真正去落地,從而實現(xiàn)邏輯數(shù)倉的能力。

本文的兩個主要觀點為:
- 因為數(shù)據(jù)虛擬化的技術(shù),讓數(shù)據(jù)集成不等于數(shù)據(jù)同步。這與傳統(tǒng)的解決方案有很大的差別。因為不等于數(shù)據(jù)同步,反而讓數(shù)據(jù)可以隨時可用。
- 邏輯數(shù)倉讓數(shù)據(jù)的使用更經(jīng)濟(jì)、便捷、高效。
以上就是本次分享的內(nèi)容,謝謝大家。
五、問答環(huán)節(jié)
Q1:怎么保證在查詢時不影響業(yè)務(wù)庫的穩(wěn)定或業(yè)務(wù)系統(tǒng)的正常使用。
A1:這是被問到最多的一個問題。回顧文中的案例,其實在 DWD 這一層做了一個物理作業(yè)的映射,因此對于所有 DWD 上的這些查詢,是不會打到業(yè)務(wù)庫內(nèi)存的。有些訪問如果是直接查詢,比如說繞過了這一層,直接查詢 PDS 這一層,查詢引擎有做一部分的限流控制。根據(jù)不同的業(yè)務(wù)庫的容量,我們可以針對數(shù)據(jù)源做一些容量的限流。
Q2:RP 本身是什么?能否解釋一下?
A2:RP 全稱是關(guān)系投影。以前是 ETL 自己去寫物理作業(yè),寫 SQL,最后把數(shù)據(jù)插到一張物理表中。現(xiàn)在我們把這個過程簡化成了 ETL 同學(xué)去寫真正生成數(shù)據(jù)的邏輯,不用管這個邏輯是不是插到一張物理表中。當(dāng)定義了很多視圖之后,我們發(fā)現(xiàn)比如說它這兩個視圖合在一起去生成一個物理作業(yè)更高效的情況下,就會把它的代碼合在一起去生成真正的物理作業(yè)。所以 RP 與視圖之間的差別就是用戶定義了視圖之后,RP 其實是視圖底層物理作業(yè)的一個映射。
Q3:采集的數(shù)據(jù)時效性如何?
A3:采集的實時性取決于不同的場景。有些場景是有實時采集需求的,而有些場景虛擬化之后,數(shù)據(jù)的時效性能夠得到提升。當(dāng)然這種時效性的提升取決于幾個方面的能力。第一個方面是,如果查詢下推能力足夠強,用戶原始的 SQL,原始的那個庫,能支撐這樣的查詢的話,可能很多地方就不會去采集過來,而是盡量在源端庫進(jìn)行計算,這是一個方案。另外一個是,有些采集,如果源端庫不允許訪問,或者性能很差的情況下,可以在 PDS 層建 RP,也可以在 DWD 層建 RP。進(jìn)入這個 RP 之后,跑的作業(yè)就分兩層,一層是定時去跑,或者說依據(jù)調(diào)度系統(tǒng)的調(diào)度周期去跑,比如說可以調(diào)度到小時級,這是一類。另外一類是如果在 PDS 層建,這種加速作業(yè)的采集是可以更實時化的。比如通過定義 bin log 的方式生成 RP。RP 就是一個訂閱 bin log 的實時采集作業(yè)了。
Q4:Data Fabric 的核心是建立一套映射關(guān)系嗎?
A4:首先,Data Fabric 的基礎(chǔ)是虛擬化。但是 Fabric 不僅僅是這一個概念,其實它上面還有很多,比如主動元數(shù)據(jù),是很關(guān)鍵的一個點。虛擬化數(shù)據(jù)的來源是因為有主動元數(shù)據(jù)的能力,才讓用戶無感知,不用去操心怎樣用他所有的庫。更多的概念,可以參考我們的白皮書。