解析大數據:從流數據攝取到交互式可視化的完整生態系統
大數據處理涉及處理和分析大型復雜數據集的技術和技術。“大數據”通常指的是傳統數據庫和處理工具無法處理的數據集。 例如:應用程序日志、用戶交互日志:這些大數據用于分析用戶互動、偏好和行為,以改進內容推薦算法并提升用戶參與度。 各種組件共同工作以處理、存儲和分析這些大型數據集。這些組件共同形成一個大數據處理生態系統。

大數據處理的關鍵組件:
1. 數據攝取和傳輸(Kafka、Logstash(ELK))
批處理和流處理:數據可以分批攝取,也可以以實時流模式處理。 批處理涉及按預定義的塊收集和處理數據,而流攝取處理連續生成并以準實時方式處理的數據。
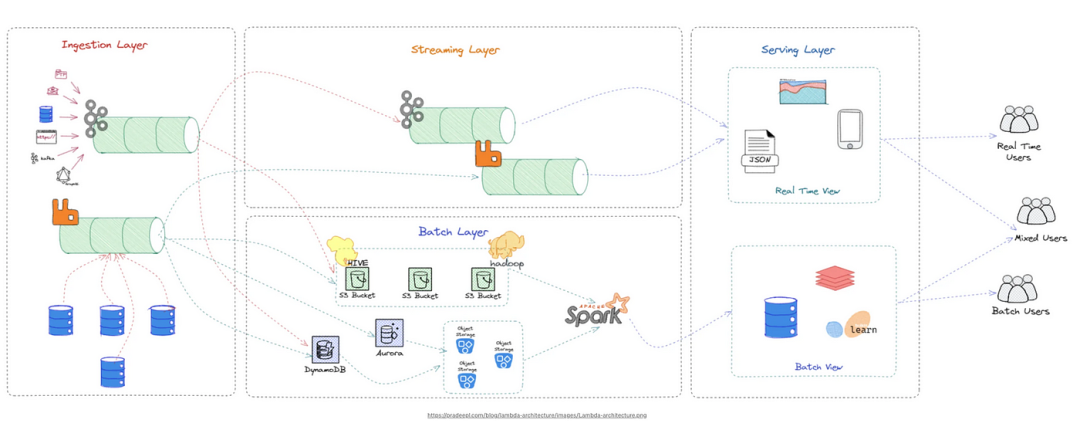
Apache Kafka:
用于構建實時數據管道和流應用的廣泛使用平臺。 為什么選擇Kafka?
- 可以處理每秒數百萬個事件。
- 可靠性:即使發生故障,數據也不會丟失:所有消息都寫入磁盤并復制到多個代理,以確保它們不會丟失。
- 默認情況下,它保證至少一次傳遞。
- 回放數據:如果需要,可以重新播放數據。
- 高度可擴展:可以添加更多代理來處理不斷增加的負載。分區器確保消息均勻分布在分區上:
- 強大的API和集成:用于與其他系統進行數據攝取的Kafka Connect。用于構建實時流應用程序的Kafka Streams。
- 安全功能,例如身份驗證和加密,可用于保護數據在傳輸和靜息時。 ??
- 可定制和靈活:還允許設置消息的保留期。支持各種數據格式,包括文本、JSON、Avro和Protobuf。
- 支持多種模式和協議。
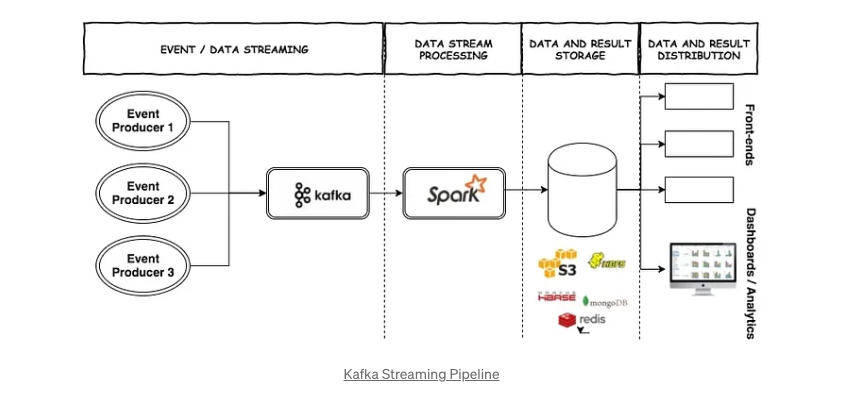
2. 原始存儲(HDFS、S3)
這些系統將大數據分布在多臺機器上,以提高可伸縮性和容錯性。
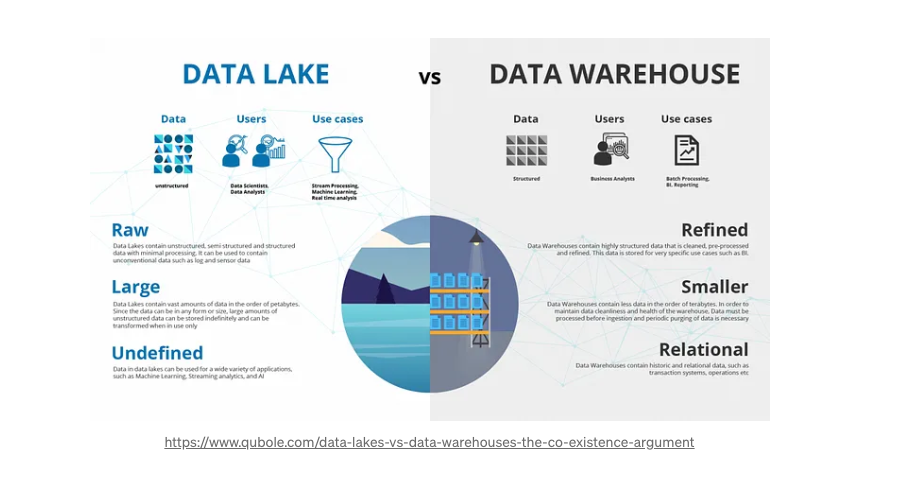
數據湖: 組織用來管理其PB級數據的大數據存儲系統。 什么是數據湖?(AWS S3、Azure Data、Apache Hadoop/HDFS)
- 存儲原始數據:它是大型、集中的非結構化和結構化數據倉庫。
- 允許以其原始格式存儲數據,無需先進行轉換。
- 存儲各種類型的數據:存儲來自各種源頭的大量數據,包括結構化、半結構化和非結構化數據。
用例:
- 想要支持組織中的多種用例,如分析、數據科學和臨時分析。
- 想要以原始和未處理的格式存儲大量數據,以便進行未來分析。
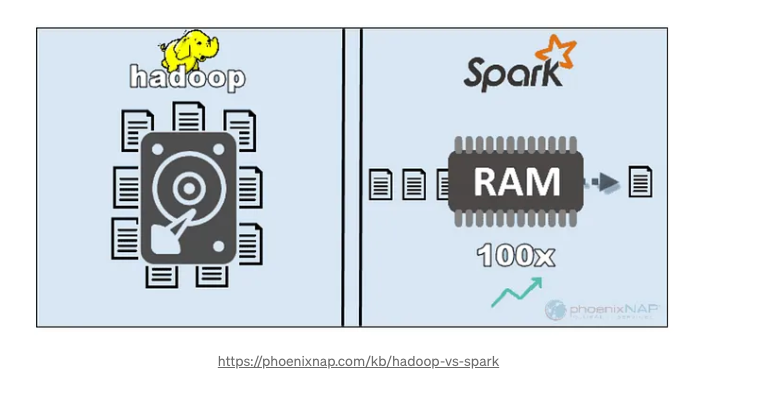
3. 處理(Hadoop、Spark)
(1) Hadoop是什么? Apache Hadoop是一個用于分布式存儲和處理大型數據集的開源框架。
Hadoop的核心概念:
- HDFS: Hadoop分布式文件系統(HDFS)是Apache Hadoop框架的存儲組件,旨在在分布式集群上存儲和管理大量數據。
- 分布式存儲:它將數據分割成塊并在集群中的多個節點上復制,確保數據的可用性和韌性。
- 成本效益存儲:HDFS利用常規硬件進行存儲,使其成為存儲大量數據的經濟有效解決方案。
(2) MapReduce: 用于并行處理大型數據集的編程模型。
并行處理模型:它將任務分解成可以在集群中的節點上并行執行的小子任務。
(3) Hadoop的優勢:
- 批處理工作負載
- 可接受較高的延遲
- 想要成本效益
(4) Hadoop的替代方案?
Apache Spark: 它是一個為大數據處理提供快速集群計算框架的開源分布式計算系統。
它是為解決MapReduce編程模型的局限性而開發的。
(5) Spark的亮點:
- 流處理:Spark支持批處理和流處理。
- 速度和性能:Spark執行內存處理,相比于依賴磁盤存儲中間數據的Hadoop,性能顯著提高。
(6) 轉換和索引(Pig、Elasticsearch)
索引是什么?
索引是有關日志的附加元數據,旨在實現對整個日志體積的更快查詢。
大數據中的索引是指創建允許從大型數據集中高效快速檢索信息的數據結構的過程。在數據量龐大的情況下,索引對于優化查詢性能和加速數據訪問至關重要 。
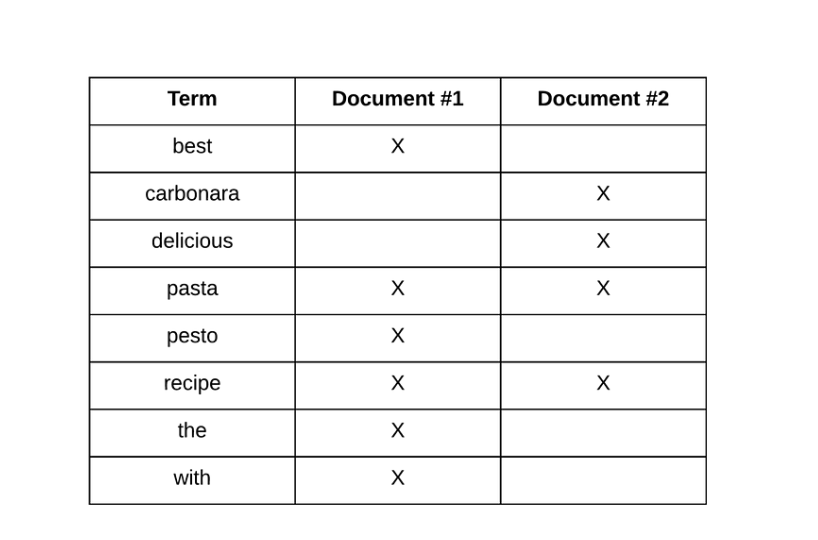
倒排索引 工具:
Apache Pig腳本:Pig Latin是一種具有簡單可讀語法的數據流腳本語言。它由一系列語句組成,定義要應用于數據集的數據轉換。
4. 數據庫
NoSQL數據庫: 專為處理大量非結構化和半結構化數據而設計。示例包括MongoDB、Cassandra和Apache HBase。
數據倉庫: 針對大型數據集上的分析查詢進行優化的專業數據庫。 什么是數據倉庫?(例如:Amazon Redshift、Snowflake)
- 為分析進行優化的存儲:它是經過優化以進行報告和分析的結構化數據的集中存儲庫。
- 預定義的關系數據庫架構
- 促進復雜查詢和分析。
用例:
- 當要存儲已經過處理、清理和轉換以進行分析和報告的結構化數據時。
- 想要支持業務智能、報告和數據分析。
示例: Hive是構建在Hadoop之上的數據倉庫基礎設施。
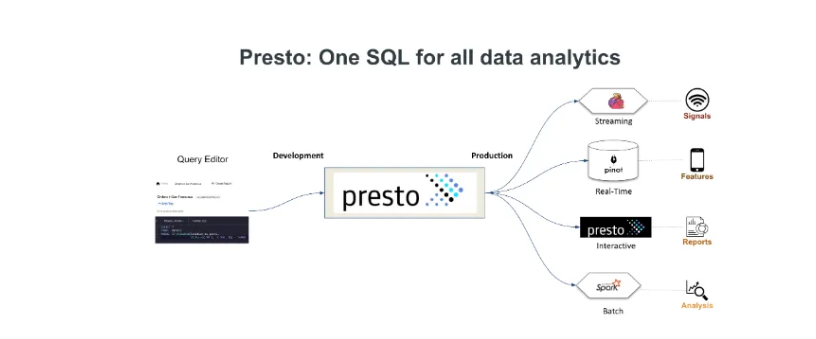
5. 分析(Presto、Spark SQL)
Presto是由Facebook創建的面向大數據的開源分布式SQL查詢引擎。它專為在大型數據集上進行快速分析查詢而開發。
SQL查詢引擎 → 可以使用SQL語法!
主要特點:
- 多功能:它可以查詢來自多個來源的數據,包括Hadoop、關系數據庫(如MySQL、PostgreSQL)和其他數據存儲。它提供了一個統一的界面,用于查詢不同的數據集。
- SQL兼容性:它支持SQL語法,使其對習慣于關系數據庫的用戶來說更加熟悉。
- 高性能:它經過優化,可用于低延遲的交互式查詢,適用于臨時數據分析和業務智能。
- 復雜查詢、連接、子查詢:它支持復雜查詢、連接、子查詢和聚合,適用于各種分析任務。
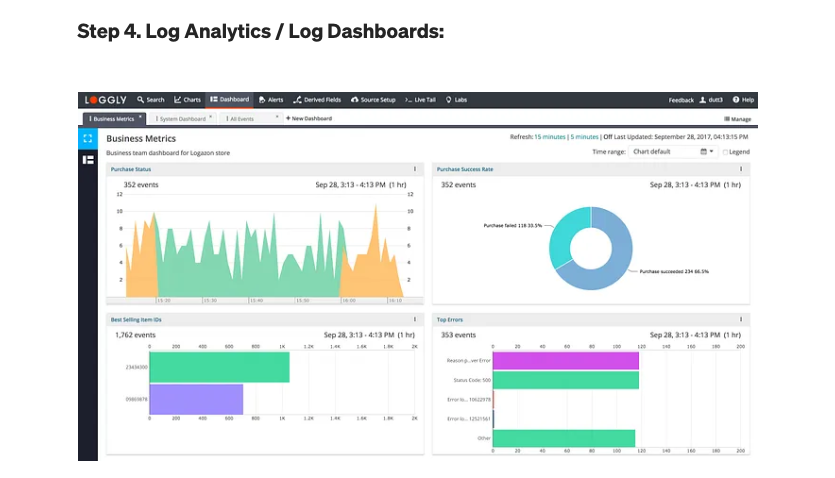
6. 可視化:(Kibana、Tableau)
- Tableau、Power BI、AWS QuickSight:用于創建交互式和可視化儀表板,以探索和傳達來自大數據的見解的流行工具。
- Jupyter Notebooks:一種開源的Web應用程序,允許用戶創建和共享包含實時代碼、可視化和敘述文本的文檔。