為業務系統賦能,攜程機票最終行程系統架構演進之路
作者簡介
Stephen,攜程資深后端開發工程師,專注新技術挖掘,持續推動業務創新
Scott ,攜程資深研發經理,負責訂單系統架構升級和優化
一、背景
攜程機票訂單系統是由多個業務子系統組成,包括出票、改簽、航變等等,獲取訂單行程信息復雜度較高。
例如:用戶預訂了一個包含了2個乘客的機票訂單,該訂單發生了航變,其中用戶A選擇了退票,用戶B選擇了改簽。
業務系統需要獲得該訂單最新的行程信息以及行程變化軌跡,以進行展示和進一步處理。

上述例子用戶的最新行程信息為:
- 乘客1:航班號9C888,SHA-PEK,已退票
- 乘客2:航班號9C999,SHA-PEK,已改簽
歷史的系統設計需要通過API對各業務子系統的數據進行實時的聚合和計算,如果要獲取上述例子的最終行程與軌跡,需要至少調用訂單、出票、改期、航變系統等,流程復雜且耗時高,并且針對一些復雜的業務場景還可能導致錯匹配、漏匹配等問題。

總結下來有如下幾個問題:
- 數據私有(分散),數據模型不統一
- 按照時間線進行聚合的難度大,需要動態計算,耗時長
- 數據存儲周期不一致,完整性不高
- 數據分析困難,報表邏輯復雜
二、目標
總的來說,我們需要設計一個用戶行程系統來滿足以下要求:
- 完整準確的行程信息
信息豐富完整,并保證更新及時、準確 - 使用便利
一站式獲取,使用方效率提升,方便使用方快速接入 - 性能可靠
系統性能良好,可靠性高 - 提升業務系統自動化率
提升自動化率,上線靈活 - 快速實現復雜業務流程
對于大量動態數據的分析與過濾需要快速實現并上線
三、實施方案
3.1 設計思路
Q1:系統需要提供什么樣的能力?
1)提供準確的用戶最新行程信息
用戶和相關的業務系統需要及時和方便的獲取到完整、準確行程信息
2)輸出歷史行程變化軌跡
對于退票等場景,需要了解用戶完整的行程變化軌跡,以便于自動化處理相關數據
3)通過行程信息進行模糊匹配
對于航變場景,航司通知某個具體航班發生了變化,系統需要通過這些信息匹配到對應的訂單并進行后續的處理
Q2:如何確保信息的豐富和準確?
1)在豐富性方面,可以接入大量的數據源并提供便捷的接入方式,及時有效的采集數據,提升系統數據的完整性
2)在準確性方面,可以采用主動 + 被動等方式,多維度的對數據進行校驗、修復,提升數據的準確性
Q3:如何提升系統的穩定性和可擴展性?
1)通過分布式緩存、結構化并發等技術提升系統的性能與穩定性
2)通過數據庫的sharding、數據倉庫的賦能等方式提供在線和離線的數據處理能力,進一步擴充數據的應用場景
3.2 系統架構圖
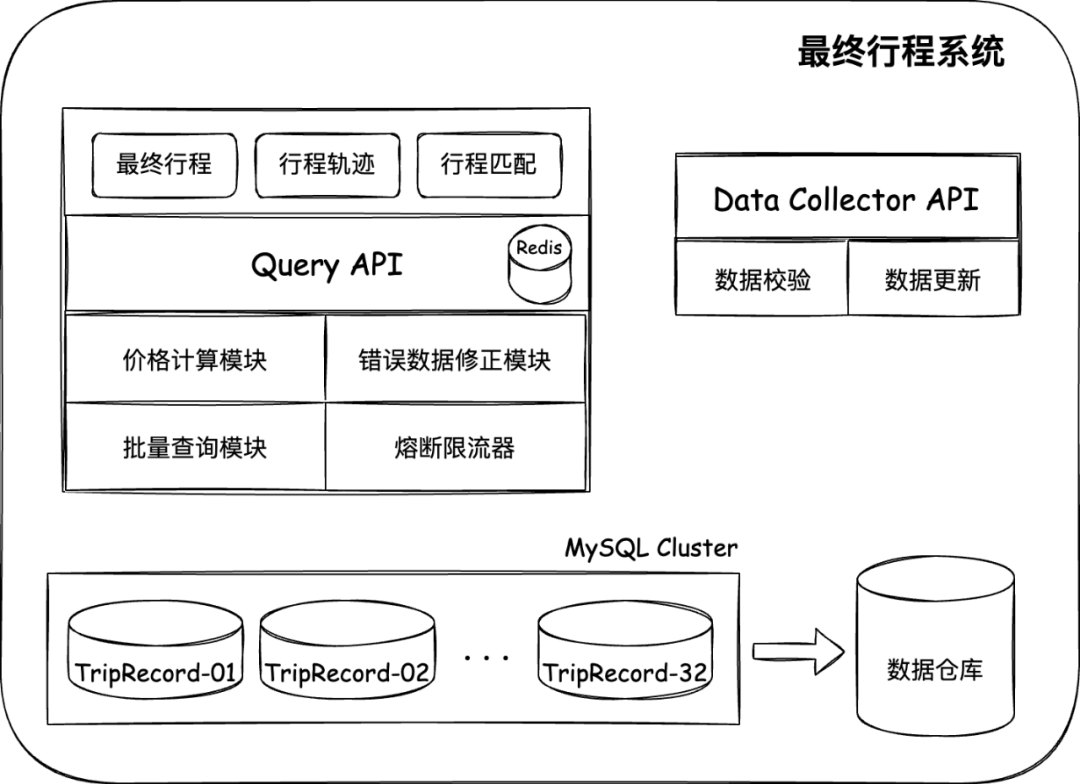
最終行程系統主要有以下幾個方面組成:
1)最終行程數據通知與更新系統
即上圖中的Data Collector API,通過收集各種來源,如訂單庫、出票系統、改簽系統等的數據,更新或者落地在最終行程系統數據庫中。同時在落地的時候也會進行被動 + 主動相結合的數據校驗機制,保證數據的準確性。
2)最終行程查詢系統,即上圖中的Query API,其中包含三大功能與若干個模塊
- 最終行程查詢,對外輸出該訂單的最終行程信息,該接口流量最高,包含有緩存組件、熔斷器、限流器等,保障其性能的穩定;
- 行程溯源軌跡查詢,對外輸出該訂單下所有行程變化的歷史軌跡,使用方可以通過該接口拿到這個訂單的行程關系圖,感知所有變化軌跡;并且整合了價格計算模塊、錯誤數據修正模塊;
- 行程匹配查詢,通過給定的行程要素條件,匹配能夠對應上的最終行程記錄,并支持批量查詢;
3)數據存儲架構,通過分庫提升數據庫的水平擴展能力,并且結合數據倉庫為業務賦能
3.3 信息豐富性
支持多種更新機制,方便接入多種類型的通知方,提升信息的豐富度,目前已經接入了出、退、改、航變、票號中心等22個數據源。
策略1: 系統主動通知,適用于對于數據新鮮度要求較高的場景,查詢性能較好
策略2: 消息通知消費,適用于數據新鮮度要求不太高的場景,通過反查保證數據最終一致,方便系統解耦
策略3: 實時查詢,適用于數據變化非常頻繁,新鮮度要求高的場景;減少了數據冗余,但是在查詢和使用上存在依賴
策略4: 動態數據的過濾通知,適用于存在規則變更,但變化維度和訂單維度不同,需要掃描海量數據來獲取更新記錄的場景
3.4 便利度增加和業務提升
3.4.1 降低溯源接口接入復雜度
溯源軌跡接口對于行程關系圖的輸出形式,對于使用方的便利度影響非常大,比如如下的行程關系圖。

歷史的輸出形式為一種無限層級的樹形結構,這樣的結構雖然能對向下的溯源查詢以及對一變多的行程變化關系提供支持,但是對于向上的溯源查詢、多變一、多變多的行程變化關系不友好,許多使用方都需要使用DFS等算法來解析數據,不夠簡潔易用,容易出錯;并且樹形結構已經不能直觀的反映出類似二變一(中轉變直飛)的行程變化場景,而且這樣的結構還會出現數據的冗余,如下圖所示:

基于以上的情況,新溯源接口選擇了類似圖的鄰接矩陣來表述行程溯源變化關系,通過TripInfo節點來表示頂點數組,平鋪出行程溯源關系圖中各個節點的行程信息;通過ChangeInfo節點來表示邊數組,主要描述行程變化關系。這樣的描述更加通用、結構清晰并且對使用方更友好。

3.4.2 支持大量動態數據的掃描與過濾
在實際的業務場景中需要維護這樣一部分數據,它會發生變化,但引起變化的規則維度與訂單維度不一致,所以需要掃描海量數據來獲取需要被更新的記錄。同時,掃描依賴的數據可能還需要跨庫才能拿到,按照現有的數據庫結構實現起來非常復雜。通過調研,最終采用數倉并結合業務SDK過濾的動態數據主動更新機制,實現了業務場景主動更新與通知的功能,該流程有如下幾個特點:

- 輕松整合所有依賴數據項,通過數據倉庫的大數據分析能力,可以輕松整合所有依賴的數據項
- 對數據進行篩選,在數據倉庫處理的流程中,添加了業務SDK的過濾機制進行數據的初篩,將海量數據進行過濾,并結合Double Check機制進行進一步的篩選,得到真正受影響的記錄
- 觸發消息的聚合機制,同時考慮到了業務誤操作后又修改一次的情況,所以增加了消息聚合機制,聚合一段時間的消息后再真正觸發數倉進行處理
該流程具有很強的通用性,通過簡單替換不同的SQL語句,切換不同的SDK,就可以輕松將該流程移植到其他業務項目中,實現了功能的快速上線。
3.5 性能優化
3.5.1 提升數據庫的水平擴展能力
最終行程系統在之前使用的是單庫存儲,但是隨著數據量的不斷增加,當業務信息擴充時,新增數據字段在數據庫層面上變的難以操作;并且如果按照業務期望的存儲時間,硬盤使用率會過高,造成了存儲瓶頸。
經過調研,決定對最終行程數據庫做 Sharding 處理,將數據平均分配到多個分片就可以滿足存儲要求并兼顧性能指標。
1)數據切分,基于最終行程數據特性,即訂單號訪問占比較高,同時在訂單號分布均勻的前提下,最終采用了訂單號對數據庫總分片數取模的方式,以保證數據分布的均勻性。
2)數據兼容,對于sharding庫和非sharding庫雙寫新數據的操作,并考慮數據庫存在異常的情況,需要增加異常補償處理機制;并且對于歷史存量數據,也進行了分批次的數據遷移以及補償功能,同時為了保證數據一致性,在遷移完成后也進行了多批次的數據對比與接口對比工作,保證 Sharding 數據的準確性和可靠性。
3)查詢性能,多分庫的查詢性能是分庫存在的典型問題,對于最終行程來說,采用非訂單號查詢操作,分庫后就涉及到多個分片的 All Shard 查詢,極大地增加了數據庫壓力和影響查詢性能。經過數據統計,分析得到特定的業務字段查詢其實就涵蓋了非訂單號查詢的大多數,從而增加其二級索引表就可以有效解決 All Shard 查詢性能的問題。
3.5.2 接入Redis緩存提升系統性能
總體上采用先操作數據庫,后刪除緩存;先查詢緩存,查詢不到緩存則查詢數據庫,并回填緩存的方式進行處理。
1)提升新鮮度,在行程更新流程時、接收BinLog消息時、接收業務變更消息時都會將緩存刪除。
2)采用分級儲存查詢的模式,查詢時根據調用方所需的數據級別進行獲取,縮小Redis獲取數據的大小,減少網絡開銷。
3)異步回填,啟用專用的線程對緩存數據進行異步回填,這樣可以不拖累查詢請求本身的耗時。
4)優化緩存容量,對Json序列化器定制規則,不輸出值為null的字段;將序列化對象中的字段通過@JsonProperty注解取一個簡短的別名,來簡化Json字符串Key的大小;使用Zstd壓縮算法對序列化后的數據進行壓縮;通過前期調研命中率和生存時間的關系,得出達到預期命中率的最小緩存生存時間,從而進一步減少Redis的容量。
3.5.3 結構化并發在匹單接口中的探索
最終行程匹單接口允許使用方傳入多組條件進行匹配,接口內部對于這多組條件采用的是for循環的方式順序執行的,存在并發改造的空間;且匹單接口操作數據庫存在多shard查詢的情況,對于多shard查詢,Dal底層會使用線程池并發調用,對線程的開銷較大。綜合上述問題,并結合近期發布的新的長期支持版本JDK21,發現了其預覽功能中的結構化并發比較適用于匹單場景的優化。
1)簡化多線程編程,增強可觀察性。
一般而言,如果我們想要實現并發操作,需要使用異步編程的方式來實現,但是使用這樣的方式對于代碼閱讀性和調試來說都比較差。在目前的多線程開發中,常用的方式是使用CompletableFuture的級聯方式編寫。與單線程的代碼相比,這樣的寫法并不直觀,并且“任務終止不干凈”和“等待超過必要時間”的問題仍然存在,如果要解決這些問題還需要自己實現一系列模版代碼,費力度大大增加。
而結構化并發的一大特點就是讓開發人員以類似單線程的方式來編寫多線程代碼,他引出了一個結構化任務作用域(Scope)的概念,在這個作用域中創建并執行任務,這些任務的生命周期都由作用域來負責管理,開發人員可以不用關系細節問題。對于作用域的任務使用try-with-resources塊,如果在執行中出現錯誤,會自動調用StructuredTaskScope的shutdown方法來終止執行,調用shutdown方法會阻止新任務的執行,同時取消正在運行中的任務。

2)使用虛擬線程解決阻塞問題。
StructuredTaskScope底層默認采用了虛擬線程進行實現,在我們原來的認知中,線程的使用都是昂貴的,而虛擬線程是JVM中Thread類的實現,它是輕量級的,當使用虛擬線程進行代碼執行時,如果遇到阻塞操作,便會釋放掉載體線程;并當該阻塞操作可用時,虛擬線程又將被安排在載體線程上去繼續處理執行。即在虛擬線程中,阻塞不是問題,因為阻塞時底層的載體線程已經被釋放了
虛擬線程和結構化并發的組合將非常強大,虛擬線程使阻塞不再是一個問題,而結構化并發為我們提供了更簡單的多線程編寫方案,以更直觀的方式處理異步編程。
3.6 優化前后數據支撐
- 數據庫QPS降低30%
- 數據庫CPU平均利用率下降20%
- 平均響應時間降低40%,P95降低30%
- 減少機器線程數41%,CPU利用率降低25%,顯著減少機器壓力
- 快速支持了業務功能,人力成本節約至少50%以上
四、后續規劃
1)易用性優化
增加行程變化訂閱通知機制,進一步提升易用性。
2)可靠性與性能提升
- 細化熔斷和降級的策略
- 和框架團隊協作,積極推廣新技術在生產系統上的規范化落地
- 探索新的數據庫結構與數據庫選型,提升關系鏈路的存儲能力
3)可視化
實現整體客人行程的可視化界面,依托最終行程數據的力量,幫助業務/產品開發更快了解到訂單全貌,幫助提升問題解決效率。