













關于C++遍歷中文字符串的問題
今天來介紹一個C++中的基礎問題:中文字符串的遍歷問題。可就是這么的一個基礎問題,也坑了我不少時間,真是應了那句話基礎不牢,地動山搖。

小試牛刀
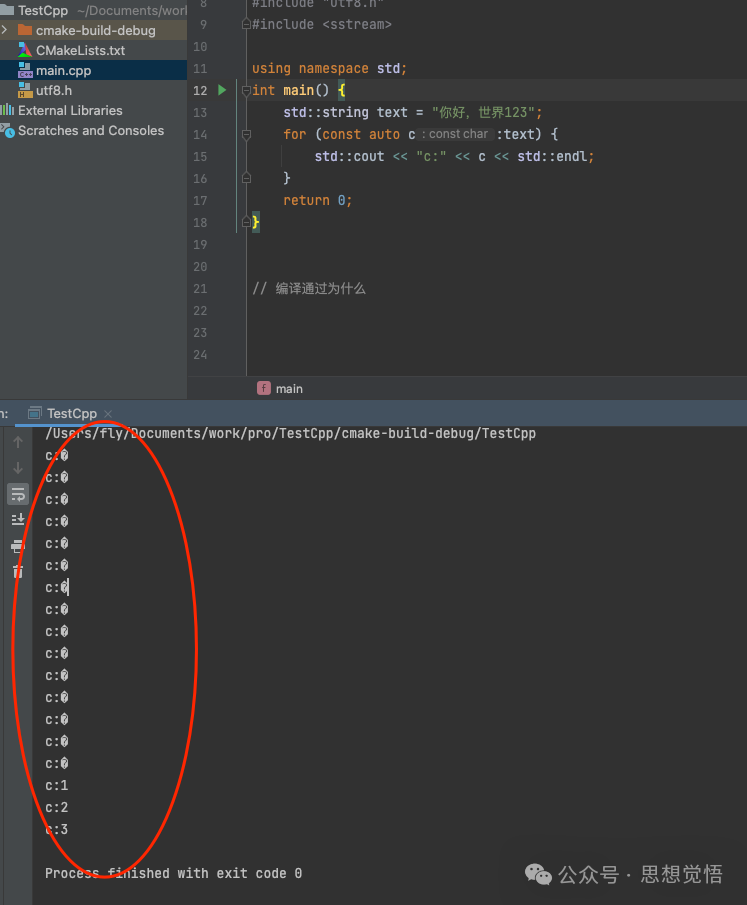
首先我們來一個demo,假如要使用std::string遍歷"你好,世界123"這個字符串,你會怎么寫?
當時筆者是這么想的:

于是大手一揮,Ctrl C + Ctrl V寫下了一下代碼:
using namespace std;
int main() {
std::string text = "你好,世界123";
for (const auto c:text) {
std::cout << "c:" << c << std::endl;
}
return 0;
}運行起來一看,我都懵逼了,居然是亂碼...
一看到亂碼,筆者首先想到的可能編碼不是utf-8的,于是我改了一行代碼:
std::string text = u8"你好,世界123";結果還是于事無補,還是亂碼的,我開始有點慌了...

在這里說明一下當在C++中使用字符串字面值時,可以使用前綴u8來表示使用UTF-8編碼。這意味著該字符串會以UTF-8編碼的格式存儲在內存中。
面對這些亂碼,我不得不拿出CV工程師的殺手锏,趕緊上stackoverflow求助...
不負眾望,果然被我找到了答案。。。
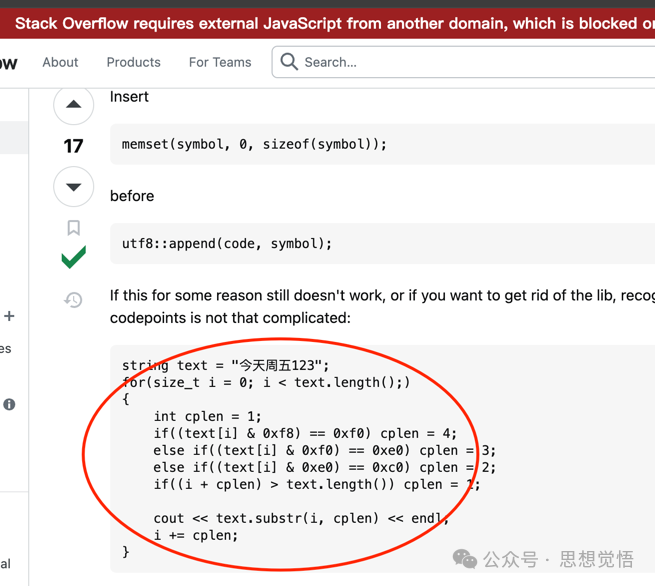
馬上復制粘貼來驗證一波...
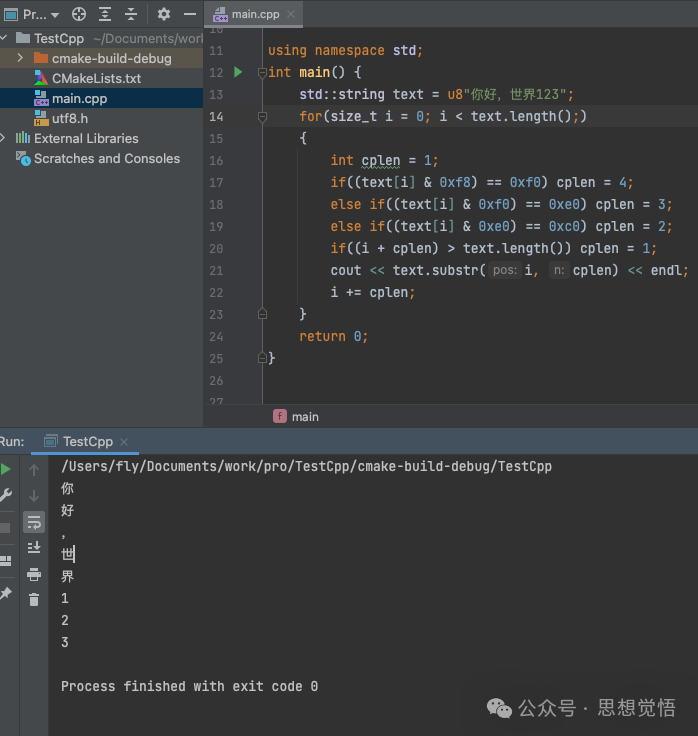
using namespace std;
int main() {
std::string text = u8"你好,世界123";
for(size_t i = 0; i < text.length();)
{
int cplen = 1;
if((text[i] & 0xf8) == 0xf0) cplen = 4;
else if((text[i] & 0xf0) == 0xe0) cplen = 3;
else if((text[i] & 0xe0) == 0xc0) cplen = 2;
if((i + cplen) > text.length()) cplen = 1;
cout << text.substr(i, cplen) << endl;
i += cplen;
}
return 0;
}運行起來,果然是想要的結果。666,憑實力攻克了一個技術難題,帶領公司往前跨了一大步,這回升級加薪穩了吧!!!
尋根問底
本著舉一反三的學習態度,我想知道為什么中文字符串的遍歷要特殊處理,我找到了這個:https://en.wikipedia.org/wiki/UTF-8#Description
原來一個中文字符不一定是和英文一樣占用一個字符,它們可能會占用幾個字符,但它們的長度其實可以從字符的頭中讀取出來的。
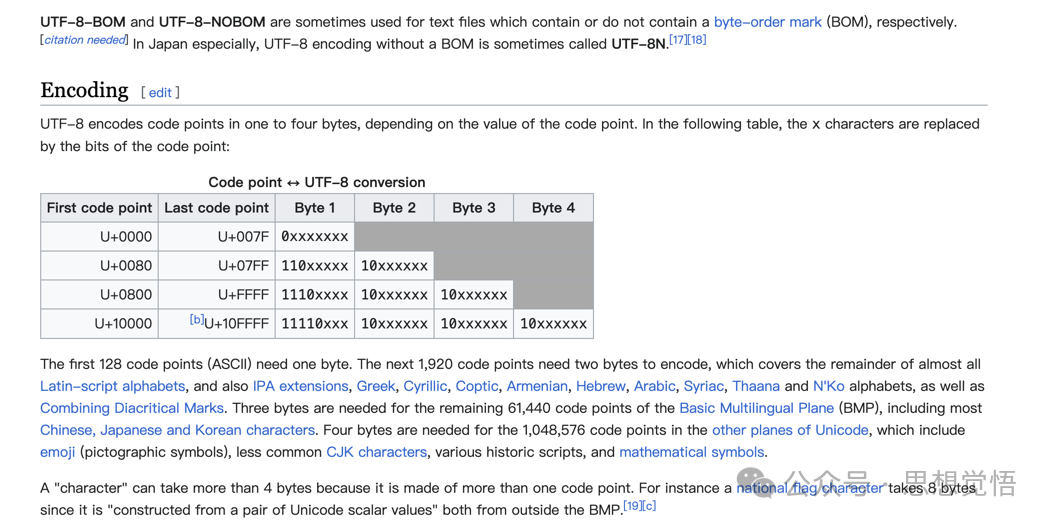
我簡單地用瀏覽器翻譯了一下,大家將就這看一下大概意思

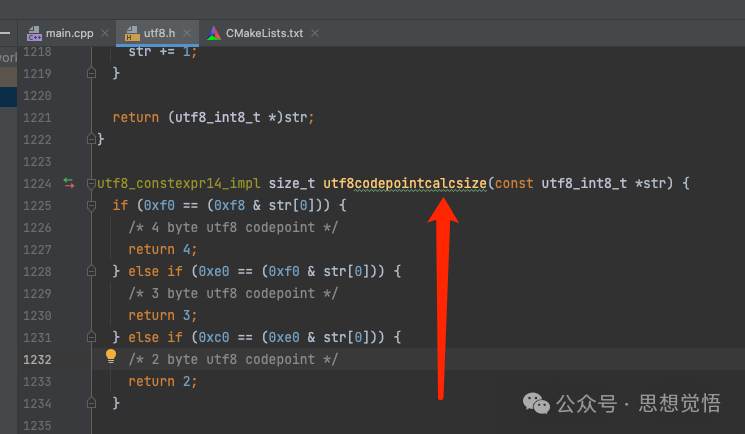
當然如果你不想自己寫獲取中文字符長度的邏輯代碼,也可以用別人寫好的開源庫。這里給大家推薦一個輕量級的,只有一個utf8.h文件的開源庫:https://github.com/sheredom/utf8.h
那么我們的代碼就變成了這樣:
int main() {
std::string text = u8"你好,世界123";
for (size_t i = 0; i < text.size();)
{
auto cplen = utf8codepointcalcsize(&text[i]);
std::cout << text.substr(i, cplen) << std::endl;
i += cplen;
}
return 0;
}其實我們查看下utf8.h這個庫的utf8codepointcalcsize函數內部實現,和我們上面說的是一樣的。
這么一個簡單的坑,以前怎么沒發現這個問題?一個是沒遇到過這樣的需求,二是就算用到了也不是用C++實現的,例如在QT上直接使用QString就沒有這些問題。












