全球首個AI程序員當老板!IOI金牌得主全部工作AI掌盤,技術細節報告公開
AI程序員Devin竟可以做老板的工作了?!
最近,Cognition AI的首席執行官Steven Hao給了Devin訪問自己帳戶的權限,然后Devin便開始為他工作了...

比如,「他」向初創公司Modal支持團隊寫了一封郵件,是詢問關于其產品Secrets更新后用多久再提供給正在運行的應用程序。

然后,「AI老板」Devin與技術團隊進行了無縫交流,最終解決了自己的疑惑。

就在最近,Cognition團隊發布了Devin的最新技術報告。
開篇,Cognition提到團隊的目標之一,就是讓Devin成為一個專門從事軟件開發的AI智能體,能夠成功地為大型復雜代碼庫貢獻代碼。

Reddit網友稱,「所有否認軟件工程師很快就會過時的人都太天真了。失業將對我們所有人造成沖擊」。

還有網友表示,AI正在迅速地重塑我們的現實,以至于我們根本不知道發生了什么。


技術報告出爐
為了評估Devin,研究人員使用了SWE-BENCH——一個針對軟件工程系統的自動化基準測試,可以確定地評估(通過單元測試)系統在真實代碼庫中解決問題的能力。

https://www.swebench.com/
在SWE-bench中,Devin成功解決了13.86%的問題,遠遠超過了之前最高的1.96%無輔助基線。
即使給定要編輯的確切文件(「輔助」模式),之前的最好的模型也只能解決4.80%的問題。
方法
研究人員采用SWE-BENCH來評估智能體,這比原始的LLM評估設置更通用。
設置
- 使用標準化的提示從頭到尾運行智能體,要求它僅根據GitHub問題描述編輯代碼。在運行過程中,不會向智能體提供任何其他用戶輸入。
- 代碼倉庫被克隆到智能體的環境中。只保留基礎提交(base commit)及其「祖先」提交在git歷史記錄中,以防止信息泄露給智能體。值得注意的是,研究人員移除了git遠程倉庫,這樣git pull就不起作用。
- 在測試開始之前,設置了Python Conda環境。
- 將Devin的運行時間限制在45分鐘,因為與大多數智能體不同的是,它具有無限期運行的能力。如果愿意,它可以選擇提前終止。
Eval
- 智能體運行退出后,研究人員會將所有測試文件重置為原始狀態,以防智能體修改測試,并將文件系統中的所有其他差異提取為patch。
- 為了確定哪些文件是測試文件,研究人員采用在測試patch中修改的所有文件的集合。
- 將智能體的patch應用到repo,然后是測試patch。
- 運行SWE-BENCH提供的eval命令,并檢查是否所有測試都通過。
具體可以在如下鏈接中,找到研究人員改編的評估工具的代碼:
https://github.com/CognitionAI/devin-swebench-results.

結果
研究人員在SWE基準測試集中,隨機抽取了25%的測試集(2294個測試集中的570個)對Devin進行了評估。
這樣做是為了縮短基準測試的完成時間,與作者在原始論文中使用的策略相同。
Devin成功解決了570個問題中的79個,成功率為13.86%。這明顯高于之前最佳輔助系統Claude 2的4.80%。

圖中的基線是在「assisted」設置中評估的,即向模型提供其需要編輯的確切文件。
基線在「unassisted」設置中表現較差,在這種情況下,一個單獨的檢索系統為LLM選擇要編輯的文件(最佳模型是Claude 2+BM25檢索系統,得分率為1.96%)。
在智能體環境中,Devin擁有整個軟件repo,可以自由瀏覽文件,因此研究人員選擇了較強的數據作為比較基準。
案例分析
多步規劃
Devin可以執行多步計劃,以接收來自環境的反饋。
72%的通過測試需要10分鐘以上的時間才能完成,這表明迭代能力有助于Devin取得成功。

定性示例
研究人員對Devin的結果進行了一些定性分析。回想一下,Devin只得到了問題描述和克隆存儲庫作為輸入。
示例1
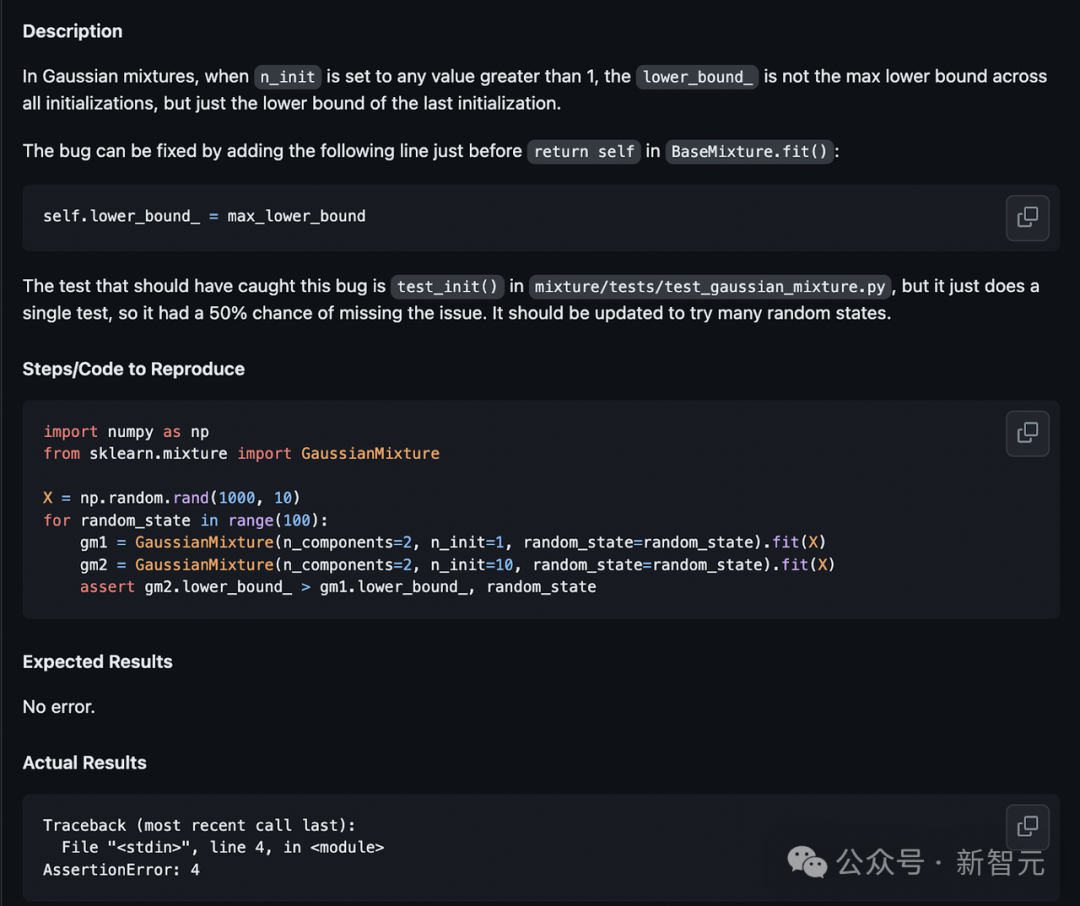
最初,Devin被描述嚇了一跳,它在返回self之前添加了self.lower_bound_ = max_lower_bound。
這實際上是不正確的,因為變量尚未定義。

根據問題描述中提供的測試代碼,Devin會更新測試文件:

但在運行測試并出現錯誤后,Devin更正了文件:


在此修復后,Devin重新運行測試,以使其通過并成功退出。
這個例子很有趣,原因有幾個:
- 盡管不準確,Devin還是非常嚴格地遵循了原版中的指示。這表明與用戶的首選項過于一致。
- 有了在環境中運行測試的能力,Devin就能糾正自己的錯誤。對于軟件開發人員來說,能夠迭代是至關重要的,而智能體也應該能夠做到這一點。
示例2
Devin可以識別正確的文件 django/db/backends/postgresql/client.py ,并進行完整編輯:

在這里,Devin能夠成功地修改一大段代碼。
SWE-BENCH中,許多成功編輯都由單行差異組成,但Devin能夠同時處理多行。
示例3
這是一項艱巨的任務,涉及修改計算機代數系統,以正確處理地板和天花板對象上,與可指定為正值或負值的值有關的比較運算符。
這需要復雜的邏輯推理和多個推導步驟。

Devin錯選了要編輯的正確類,他編輯的是frac類,而不是floor類和ceiling類。
此外,Devin只編輯了一個比較運算符gt,而lt、le和ge也需要修改。這樣的編輯離正確還差得很遠。
示例4
這項任務涉及向回購中的所有數據集添加額外的退貨選項功能。Devin能夠成功地對幾個數據集進行此編輯;下面顯示了一個示例。


Devin設法對數據集 california_housing.py 、 covtype.py 、 kddcup99.py 和 mldata.py (原始PR實際上排除了它們)進行了類似的編輯。
不幸的是,Devin漏掉了兩個數據集, lfw.py 和 rcv1.py ,因此測試最終失敗。研究人員打算改進Devin編輯多個文件的能力。
測試驅動實驗
研究人員又進行了一次實驗,向Devin提供了最終的單元測試和問題陳述。
在這種「測試驅動開發」的環境下,100個抽樣測試中,成功通過率提高到了23%。(請注意,對測試本身的任何修改都會在評估前被刪除)。
這一結果是無法與SWE-BENCH的其他結果相比較的,因為該智能體可以訪問真值測試patch。
盡管如此,測試驅動開發是軟件工程中的一種常見模式,因此這種設置是SWE-BENCH的自然擴展。
人類給智能體一個有針對性的測試,來通過是人類工程師和智能體合作的一種自然方式,我們預計未來會看到更多測試驅動的智能體。
Devin通過測試新解決的問題示例
Devin通過在函數前面添加一條Print語句,然后運行單元測試,然后根據Print語句編輯文件,解決了這個問題。


新單元測試斷言會發出準確的錯誤信息:The value of 'filter_horizontal[0]' cannot include […]。
如果不知道錯誤的確切措辭,就不可能通過測試。
這凸顯了該基準的一個問題,說明不使用測試patches也不可能獲得滿分。
智能體仍在發展的初級階段,還有很大的改進空間。Cognition團隊相信智能體的能力將在未來顯著提高。