3D版Sora來了?UMass、MIT等提出3D世界模型,具身智能機器人實現新里程碑
在最近的研究中,視覺-語言-動作(VLA,vision-language-action)模型的輸入基本都是2D數據,沒有集成更通用的3D物理世界。
此外,現有的模型通過學習「感知到動作的直接映射」來進行動作預測,忽略了世界的動態性,以及動作和動態之間的關系。
相比之下,人類在思考時會引入世界模型,可以描繪除對未來情景的想象,從而對下一步的行動進行規劃。
為此,來自馬薩諸塞州大學阿默斯特分校、MIT等機構的研究人員提出了3D-VLA模型,通過引入一類全新的具身基礎模型(embodied foundation models),可以根據生成的世界模型無縫連接3D感知、推理和行動。
項目主頁:https://vis-www.cs.umass.edu/3dvla/
論文地址:https://arxiv.org/abs/2403.09631
具體而言,3D-VLA構建在基于3D的大型語言模型(LLM)之上,并引入一組交互token來參與具身環境中。
為了將生成能力注入模型,淦創團隊訓練了一系列具身擴散模型,并將其對齊到LLM中以預測目標圖像和點云。
為了對3D-VLA模型進行訓練,通過從現有的機器人數據集中提取大量的3D相關信息來構建出一個大規模的3D具身指令數據集。
實驗結果表明,3D-VLA顯著提高了在具身環境中推理、多模態生成和規劃的能力,展示出其在現實世界中的應用潛力。
三維具身指令調整數據集(3D Embodied Instruction Tuning Dataset)
得益于互聯網上數十億規模的數據集,VLM在各種任務中表現出了非凡的性能,百萬級的視頻動作數據集也為機器人控制的具身VLM奠定了基礎。
但當前的數據集大多不能在機器人操作中提供深度或3D標注和精確控制,需要包含3D空間推理和交互:如果沒有3D信息,機器人很難理解和執行需要3D空間推理的命令,比如「把最遠的杯子放在中間的抽屜里」。

為了彌補這一差距,研究人員構建了一個大規模的3D指令調優數據集,該數據集提供了足夠的「3D相關信息」以及「相應的文本指令」以訓練模型。
研究人員設計了一個pipeline從現有的具身數據集中提取3D語言動作對,獲得點云、深度圖、3D邊界框、機器人的7D動作和文本描述的標注。
3D-VLA基礎模型
3D-VLA是一個用于在具身環境(embodied environment)中進行三維推理、目標生成和決策的世界模型。
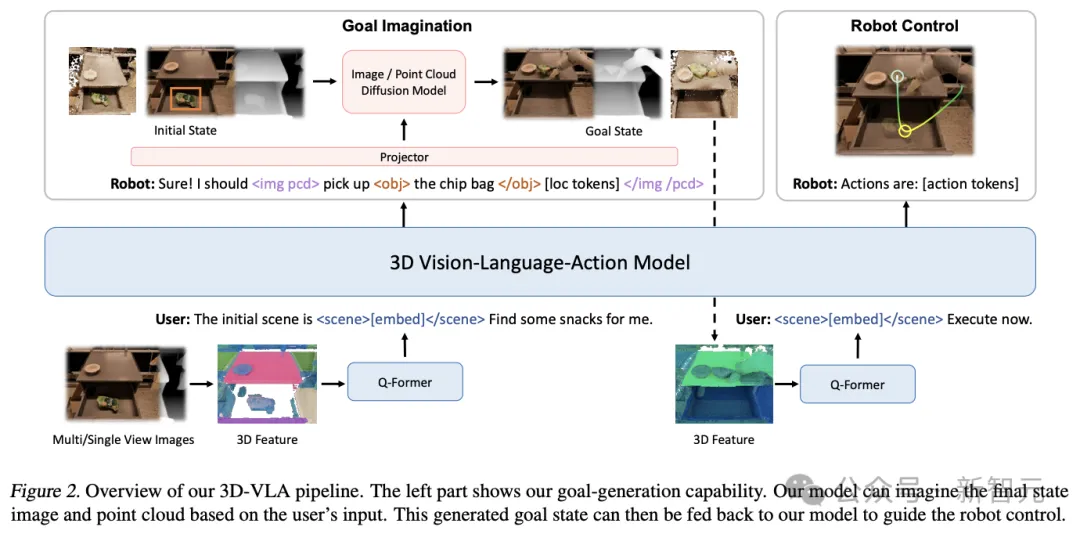
首先在3D-LLM之上構建主干網絡,并通過添加一系列交互token來進一步增強模型與3D世界交互的能力;再通過預訓練擴散模型并使用投影來對齊LLM和擴散模型,將目標生成能力注入3D-VLA
骨干網絡
在第一階段,研究人員按照3D-LLM的方法開發3D-VLA基礎模型:由于收集到的數據集沒有達到從頭開始訓練多模態LLM所需的十億級規模,因此需要利用多視圖特征生成3D場景特征,使得視覺特征能夠無縫集成到預訓練VLM中,不需要自適應。
同時,3D-LLM的訓練數據集主要包括對象(objects)和室內場景,與具體設置不直接一致,所以研究人員選擇使用BLIP2-PlanT5XL作為預訓練模型。
在訓練過程中,解凍token的輸入和輸出嵌入,以及Q-Former的權重。
交互tokens
為了增強模型對3D場景的理解與環境中的交互,研究人員引入了一組全新的交互tokens
首先,輸入中加入了object tokens,包含解析句子中的對象名詞(如<obj> a chocolate bar </obj> [loc tokens] on the table),這樣模型就能更好地捕捉到被操作或提及的對象。
其次,為了更好地用語言表達空間信息,研究人員設計了一組位置token <loc0-255>,用 AABB 形式的六個標記來表示三維邊界框。
第三,為了更好地進行動態編碼,框架中引入了<scene></scene>來包含靜態場景的嵌入:通過對場景token進行組合,3D-VLA 可以理解動態場景,并管理交錯三維場景和文本的輸入。
通過擴展代表機器人動作的專用標記集,進一步增強了該架構。機器人的動作有 7 個自由度,用 <aloc0-255>、<arot0-255> 和 <gripper0/1> 等離散token來表示手臂的預定絕對位置、旋轉和抓手張開度,每個action由 <ACT SEP> token進行分隔。
注入目標生成能力
人類能夠對場景的最終狀態進行預先可視化(pre-visualize),以提升動作預測或決策的準確性,也是構建世界模型的關鍵方面;在初步實驗中,研究人員還發現提供真實的最終狀態可以增強模型的推理和規劃能力。
但訓練MLLM來生成圖像、深度和點云并不簡單:
首先,視頻擴散模型并不是為具身場景量身定制的,比如Runway在生成「打開抽屜」的未來幀時,場景中會發生視圖變化、對象變形、怪異的紋理替換以及布局失真等問題。
并且,如何將各種模態的擴散模型整合到一個單一的基礎模型中仍然是一個難題。
所以研究人員提出的新框架,首先根據圖像、深度和點云等不同形式對具體的擴散模型進行預訓練,然后在對齊階段將擴散模型的解碼器對齊到3D-VLA的嵌入空間。

實驗結果
3D-VLA是一個多功能的、基于3D的生成式世界模型,可以在3D世界中執行推理和定位、想象多模態目標內容,并為機器人操作生成動作,研究人員主要從三個方面對3D-VLA進行了評估:3D推理和定位、多模態目標生成和具身行動規劃。
3D推理和定位
3D-VLA在語言推理任務上優于所有2D VLM方法,研究人員將其歸因于3D信息的杠桿作用,3D信息為推理提供了更準確的空間信息。
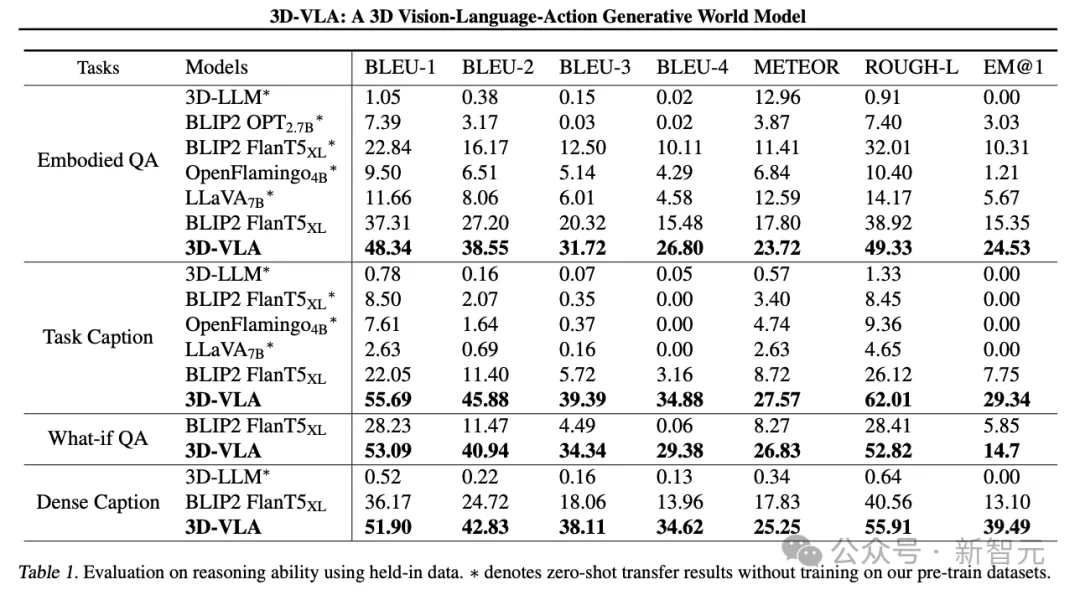
此外,由于數據集中包含一組3D定位標注,3D-VLA學習定位相關對象,有助于模型更專注于關鍵對象進行推理。
研究人員發現3D-LLM在這些機器人推理任務中表現不佳,證明了在機器人相關的3D數據集上收集和訓練的必要性。

并且3D-VLA在定位性能方面表現出明顯優于2D基線方法,這一發現也為標注過程的有效性提供了令人信服的證據,有助于模型獲得強大的3D定位能力。
多模態目標生成
與現有的零樣本遷移到機器人領域的生成方法相比,3D-VLA在大多數指標方面實現了更好的性能,證實了使用「專門為機器人應用設計的數據集」來訓練世界模型的重要性。
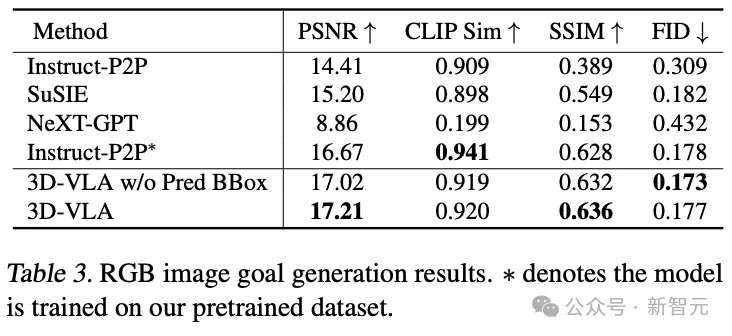
即使在與Instruct-P2P*的直接比較中,3D-VLA也始終性能更優,結果表明,將大型語言模型集成到3D-VLA中可以更全面、更深刻地理解機器人操作指令,從而提高目標圖像生成性能。
此外,當從輸入提示符中排除預測的邊界框時,可以觀察到性能略有下降,證實了使用中間預測邊界框的有效性,可以幫助模型理解整個場景,允許模型將更多的注意力分配到給定指令中提到的特定對象,最終增強其想象最終目標圖像的能力。
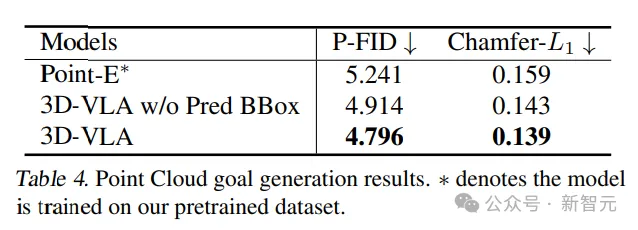
點云生成的結果對比中,具有中間預測邊界框的3D-VLA性能最好,證實了在理解指令和場景的背景下結合大型語言模型和精確對象定位的重要性。
具身行動規劃
3D-VLA在RLBench動作預測中的大多數任務中超過了基線模型的性能,顯示了其具有規劃能力。
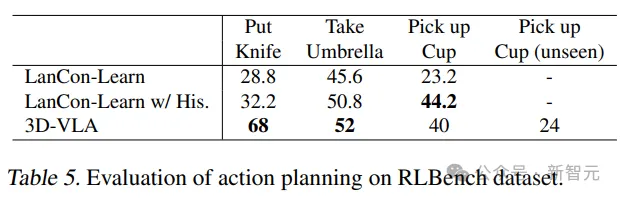
值得注意的是,基線模型需要用到歷史觀察、對象狀態和當前狀態信息,而3D-VLA模型只通過開環控制執行。
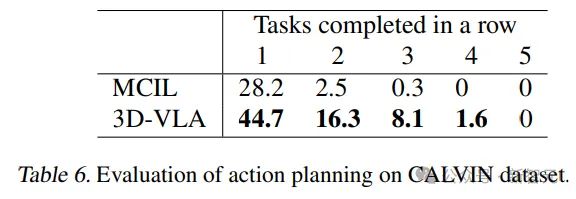
此外,模型的泛化能力在撿杯(pick-up-cup)任務中得到了證明,3D-VLA在CALVIN中也取得了較好的結果,研究人員將這種優勢歸因于定位感興趣的對象和想象目標狀態的能力,為推斷動作提供了豐富的信息。