一文詳解Spark內存模型原理,面試輕松搞定
1.引言
Spark 是一個基于內存處理的計算引擎,其中任務執行的所有計算都發生在內存中。因此,了解 Spark 內存管理非常重要。這將有助于我們開發 Spark 應用程序并執行性能調優。我們在使用spark-submit去提交spark任務的時候可以使用--executor-memory和--driver-memory這兩個參數去指定任務提交時的內存分配,如果提交時內存分配過大,會占用資源。如果內存分配太小,則很容易出現內存溢出和滿GC問題。
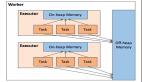
Efficient memory use is critical for good performance, but the reverse is also true: inefficient memory use leads to bad performance.Spark 的整體架構圖如下:
 圖片
圖片
Spark 應用程序包括兩個 JVM 進程:driver進程和executor進程。其中:
- driver進程是主控制進程,負責創建 SparkSession/SparkContext、提交作業、將作業轉換為任務以及協調執行器之間的任務執行。
- executor進程主要負責執行特定的計算任務并將結果返回給驅動程序。driver的進程的內存管理相對簡單,Spark并沒有對此制定具體內存管理計劃。
因此在這篇文章中,我們將會詳細深入分析executor的內存管理。
2.Excutor內存模型
executor充當在工作節點上啟動的 JVM 進程。因此,了解 JVM 內存管理非常重要。我們知道JVM 內存管理分為兩種類型:
- 堆內存管理(In-Heap Memory):對象在 JVM 堆上分配并由 GC 綁定。
- 堆外內存管理(外部內存):對象通過序列化在JVM外部的內存中分配,由應用程序管理,不受GC約束。
整體的JVM結構如下所示:
 圖片
圖片
通常,對象的讀寫速度為:on-heap > off-heap > disk
2.1 內存管理
Spark 內存管理分為兩種類型:靜態內存管理器(Static Memory Management,SMM),以及統一內存管理器(Unified Memory Management,UMM)。
 圖片
圖片
在Spark1.6.0之前只有一種內存管理方案,即Static Memory Management,但是從 Spark 1.6.0 開始,引入Unified Memory Manager 內存管理方案,并被設置為 Spark 的默認內存管理器,從代碼中開始發現(以下代碼是基于spark 2.4.8)。
// Determine whether to use the old memory management mode
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
// The old version uses static memory management
new StaticMemoryManager(conf, numUsableCores)
} else {
// The new version uses unified memory management
UnifiedMemoryManager(conf, numUsableCores)
}而在最新的Spark 3.x開始, Static Memory Management由于缺乏靈活性而已棄用,在源碼中已經看到關于Static Memory Management的所有代碼,自然也就看不到控制內存管理方案選擇的spark.memory.useLegacyMode這個參數。
2.2 靜態內存管理器(SMM)
雖然在spark 3.x版本開始SMM已經被淘汰了,但是目前很多企業使用的spark的版本還有很多是3.x之前的,因此我覺得為了整個學習的連貫性,還是有必要說一下的靜態內存管理器 (SMM) 是用于內存管理的傳統模型和簡單方案,該方案實現上簡單粗暴,將整個內存區間分成了:存儲內存(storage memory,)、執行內存(execution memory)和其他內存(other memory)的大小在應用程序處理過程中是固定的,但用戶可以在應用程序啟動之前進行配置。這三部分內存的作用及占比如下:storage memory:主要用于緩存數據塊以提高性能,同時也用于連續不斷地廣播或發送大的任務結果。通過spark.storage.memoryFraction進行配置,默認為0.6。
/**
* Return the total amount of memory available for the storage region, in bytes.
*/
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}其中又可以分成兩部分:預留區域:這部分主要是為了防止OOM,大概占了存儲區域中的10%,由參數spark.storage.safetyFraction控制;可用的存儲區域:該區域主要是為了緩存RDD的數據和Broadcast數據,大概占了存儲區域的90%。另外該區域中并不是所有的內存都用于以上作用,還單獨拎出來一部分區域用于緩存iterator形式的block數據,我們稱之為Unroll區域,由參數spark.storage.unrollFraction控制,大概占了可用的存儲區域的20%,如下:
private val maxUnrollMemory: Long = {
(maxOnHeapStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}execution memory:在執行shuffle、join、sort和aggregation時,用于緩存中間數據。通過spark.shuffle.memoryFraction進行配置,默認為0.2。
private def getMaxExecutionMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
if (systemMaxMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}從代碼中我們可以看到,可執行內存也分成了兩個部分:預留部分和可用部分,類似存儲內存學習,這里不在贅述。other memory:除了以上兩部分的內存,剩下的就是用于其他用作的內存,默認為0.2。這部分內存用于存儲運行Spark系統本身需要加載的代碼與元數據。因此,關于SMM的整體分配圖如下:
 圖片
圖片
基于此就會產生不可逾越的缺點:即使存儲內存有可用空間,我們也無法使用它,并且由于執行程序內存已滿,因此存在磁盤溢出。(反之亦然)。另外一個最大的問題就是:SMM只支持堆內內存(On-Heap),不支持對外內存(Off-Heap)
補充知識1:在Spark的存儲體系中,數據的讀寫是以塊(Block)為單位,也就是說Block是Spark存儲的基本單位,這里的Block和Hdfs的Block是不一樣的,HDFS中是對大文件進行分Block進行存儲,Block大小是由dfs.blocksize決定的;而Spark中的Block是用戶的操作單位,一個Block對應一塊有組織的內存,一個完整的文件或文件的區間端,并沒有固定每個Block大小的做法。每個塊都有唯一的標識,Spark把這個標識抽象為BlockId。BlockId本質上是一個字符串,但是在Spark中將它保證為"一組"case類,這些類的不同本質是BlockID這個命名字符串的不同,從而可以通過BlockID這個字符串來區別BlockId
補充知識2:內存池是Spark內存的抽象,它記錄了總內存大小,已使用內存大小,剩余內存大小,提供給MemoryManager進行分配/回收內存。它包括兩個實現類:ExecutionMemoryPool和StorageMemoryPool,分別對應execution memory和storage memory。當需要新的內存時,spark通過memoryPool來判斷內存是否充足。需要注意的是memoryPool以及子類方法只是用來標記內存使用情況,而不實際分配/回收內存。
2.3 統一內存管理器(UMM)
從 Spark 1.6.0 開始,采用了新的內存管理器來取代靜態內存管理器,并為 Spark 提供動態內存分配。它將內存區域分配為由存儲和執行共享的統一內存容器。當未使用執行內存時,存儲內存可以獲取所有可用內存,反之亦然。如果任何存儲或執行內存需要更多空間,則會調用acquireMemory方法將擴展其中一個內存池并收縮另一個內存池。因此,UMM相比SMM的內存管理優勢明顯:存儲內存和執行內存之間的邊界不是靜態的,在內存壓力的情況下,邊界會移動,即一個區域會通過從另一個區域借用空間來增長。當應用程序沒有緩存并且正在進行時,執行會使用所有內存以避免不必要的磁盤溢出。當應用程序有緩存時,它將保留最小存儲內存,以便數據塊不受影響。此內存管理可為各種工作負載提供合理的開箱即用性能,而無需用戶了解內存內部劃分方式的專業知識。
2.3.1 堆內存
默認情況下,Spark 僅使用堆內存。Spark 應用程序啟動時,堆內存的大小由 --executor-memory 或 spark.executor.memory 參數配置。在UMM下,spark的堆內存結構圖如下:
 圖片
圖片
我們發現大體上和SMM沒有太大的區別,包括每個區域的功能,只是UMM在Storage和Execution可以彈性的變化(這一點也是spark rdd中“彈性”的體現之一)。
備注:在 Spark 1.6 中,spark.memory.fraction 值為 0.75,spark.memory.storageFraction 值為 0.5。從spark 2.x開始spark.memory.fraction 值為 0.6。
2.3.1.1 System Reserved:系統預留
預留內存是為系統預留的內存,用于存儲Spark的內部對象。從 Spark 1.6 開始,該值為 300MB。這意味著 300MB 的 RAM 不參與 Spark 內存區域大小計算。預留內存的大小是硬編碼的,如果不重新編譯 Spark 或設置 spark.testing.reservedMemory,則無法以任何方式更改其大小,一般在實際的生產環境中不建議修改此值。
private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}從源碼中我們可以看出,如果執行程序內存小于保留內存的 1.5 倍(1.5 * 保留內存 = 450MB),則 Spark 作業將失敗,并顯示以下異常消息:
24/03/20 13:55:51 ERROR repl.Main: Failed to initialize Spark session.
java.lang.IllegalArgumentException: Executor memory 314572800 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:225)
at org.apache.spark.memory.UnifiedMemoryManager$.apply(UnifiedMemoryManager.scala:199)2.3.1.2 其他內存(或稱用戶內存)
其他內存是用于存儲用戶定義的數據結構、Spark 內部元數據、用戶創建的任何 UDF 以及 RDD 轉換操作所需的數據(如 RDD 依賴信息等)的內存。例如,我們可以通過使用 mapPartitions 轉換來重寫 Spark 聚合,以維護一個哈希表以運行此聚合,這將消耗所謂的其他內存。此內存段不受 Spark 管理,計算公式為:(Java Heap - Reserved Memory) * (1.0 - spark.memory.fraction)。
2.3.1.3 Spark內存(或稱統一內存)
Spark Memory 是由 Apache Spark 管理的內存池。Spark Memory 負責在執行任務(如聯接)或存儲廣播變量時存儲中間狀態。計算公式為:(Java Heap - Reserved Memory) * spark.memory.fraction。
Spark 任務在兩個主要內存區域中運行:
- Executor Memory:用于隨機播放、聯接、排序和聚合。
- Storage Memory:用于緩存數據分區。
它們之間的邊界由 spark.memory.storageFraction 參數設置,默認為 0.5 或 50%。
1)StorageMemory: 存儲內存
存儲內存用于存儲所有緩存數據、廣播變量、unroll數據等,“unroll”本質上是反序列化序列化數據的過程。任何包含內存的持久性選項都會將該數據存儲在此段中。Spark 通過刪除基于最近最少使用 (LRU) 機制的舊緩存對象來為新緩存請求清除空間。緩存的數據從存儲中取出后,將寫入磁盤或根據配置重新計算。廣播變量存儲在緩存中,具有MEMORY_AND_DISK持久性級別。這就是我們存儲緩存數據的地方,這些數據是長期存在的。
計算公式:
(Java Heap - Reserved Memory) * spark.memory.fraction * spark.memory.storageFraction2)Execution Memory:執行內存
執行內存用于存儲 Spark 任務執行過程中所需的對象。例如,它用于將映射端的shuffle中間緩沖區存儲在內存中。此外,它還用于存儲hash聚合步驟的hash table。如果沒有足夠的可用內存,執行內存池還支持溢出磁盤,但是其他線程(任務)無法強制逐出此池中的block。執行內存往往比存儲內存壽命更短。每次操作后都會立即將其逐出,為下一次操作騰出空間。
計算公式:
(Java Heap - Reserved Memory) * spark.memory.fraction * (1.0 - spark.memory.storageFraction)由于執行內存的性質,無法從此池中強制逐出塊;否則,執行將中斷,因為找不到它引用的塊。但是,當涉及到存儲內存時,可以根據需要從內存中逐出block并寫入磁盤或重新計算(如果持久性級別為MEMORY_ONLY)。
存儲和執行池借用規則:
- 只有當執行內存中有未使用的塊時,存儲內存才能從執行內存中借用空間。
- 如果塊未在存儲內存中使用,則執行內存也可以從存儲內存中借用空間。
- 如果存儲內存使用執行內存中的塊,并且執行需要更多內存,則可以強制逐出存儲內存占用的多余塊
- 如果存儲內存中的塊被執行內存使用,而存儲需要更多的內存,則無法強行逐出執行內存占用的多余塊;它將具有更少的內存區域。它將等到 Spark 釋放存儲在執行內存中的多余塊,然后占用它們。
案例:計算 5 GB 執行程序內存的內存
為了計算預留內存、用戶內存、spark內存、存儲內存和執行內存,我們將使用以下參數:
spark.executor.memory=5g
spark.memory.fractinotallow=0.6
spark.memory.storageFractinotallow=0.5那么會得到如下結論:
Java Heap Memory = 5 GB
= 5 * 1024 MB
= 5120 MB
Reserved Memory = 300 MB
Usable Memory = (Java Heap Memory - Reserved Memory)
= 5120 MB - 300 MB
= 4820 MB
User Memory = Usable Memory * (1.0 * spark.memory.fraction)
= 4820 MB * (1.0 - 0.6)
= 4820 MB * 0.4
= 1928 MB
Spark Memory = Usable Memory * spark.memory.fraction
= 4820 MB * 0.6
= 2892 MB
Spark Storage Memory = Spark Memory * Spark.memory.storageFraction
= 2892 MB * 0.5
= 1446 MB
Spark Execution Memory = Spark Memory * (1.0 - spark.memory.storageFraction)
= 2892 MB * ( 1 - 0.5)
= 2892 MB * 0.5
= 1446 MB2.3.2 堆外內存
堆外內存是指將內存對象(序列化為字節數組)分配給 JVM堆之外的內存,該堆由操作系統(而不是JVM)直接管理,但存儲在進程堆之外的本機內存中(因此,它們不會被垃圾回收器處理)。這樣做的結果是保留較小的堆,以減少垃圾回收對應用程序的影響。訪問此數據比訪問堆存儲稍慢,但仍比從磁盤讀取/寫入快。缺點是用戶必須手動處理管理分配的內存。此模型不適用于 JVM 內存,而是將 malloc() 中不安全相關語言(如 C)的 Java API 直接調用操作系統以獲取內存。由于此方法不是對 JVM 內存進行管理,因此請避免頻繁 GC。此應用程序的缺點是內存必須寫入自己的邏輯和內存應用程序版本。Spark 1.6+ 開始引入堆外內存,可以選擇使用堆外內存來分配 Unified Memory Manager。
默認情況下,堆外內存是禁用的,但我們可以通過 spark.memory.offHeap.enabled(默認為 false)參數啟用它,并通過 spark.memory.offHeap.size(默認為 0)參數設置內存大小。如:
spark-shell \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=5g堆外內存支持OFF_HEAP持久性級別。與堆上內存相比,堆外內存的模型相對簡單,僅包括存儲內存和執行內存。
如果啟用了堆外內存,Executor 中的 Execution Memory 是堆內的 Execution 內存和堆外的 Execution 內存之和。存儲內存也是如此。
總之,Spark內存管理的核心目標是在有限的內存資源下,實現數據緩存的最大化利用和執行計算的高效進行,同時盡量減少由于內存不足導致的數據重算或內存溢出等問題,是整個spark允許可以穩定運行的基礎保障。