達(dá)觀數(shù)據(jù):一文詳解高斯混合模型原理
本文用生動(dòng)的案例對(duì)高斯混合模型原理進(jìn)行了通俗易懂的講解,并分析了高斯混合模型與另一種常見聚類算法K-means的關(guān)系。
什么是高斯混合模型(Gaussian Mixture Model)
高斯混合模型(Gaussian Mixture Model)通常簡(jiǎn)稱GMM是一種業(yè)界廣泛使用的聚類算法,該方法使用了高斯分布作為參數(shù)模型,并使用了期望***(Expectation Maximization,簡(jiǎn)稱EM)算法進(jìn)行訓(xùn)練。本文對(duì)該方法的原理進(jìn)行了通俗易懂的講解,期望對(duì)讀者更直觀的理解方法原理有幫助。文本的***還分析了高斯混合模型了另一種常見聚類算法K-means的關(guān)系,實(shí)際上在特定約束條件下,K-means算法可以被看作是高斯混合模型(GMM)的一種特殊形式。
1. 什么是高斯分布?
高斯分布(Gaussian distribution)有時(shí)也被稱為正態(tài)分布(normal distribution),是一種在自然界大量存在的、最為常見的分布形式,在提供精確數(shù)學(xué)定義前,先用一個(gè)簡(jiǎn)單的例子來(lái)說(shuō)明。
如果我們對(duì)大量的人口進(jìn)行身高數(shù)據(jù)的隨機(jī)采樣,并且將采得的身高數(shù)據(jù)畫成柱狀圖,將會(huì)得到如下圖1所示的圖形。這張圖模擬展示了334個(gè)成人的統(tǒng)計(jì)數(shù)據(jù),可以看出圖中最多出現(xiàn)的身高在180cm左右2.5cm的區(qū)間里。
人的身高數(shù)據(jù)構(gòu)成的正態(tài)分布直方圖")
圖1:由334個(gè)人的身高數(shù)據(jù)構(gòu)成的正態(tài)分布直方圖
這個(gè)圖形非常直觀的展示了高斯分布的形態(tài)。接下來(lái)看下嚴(yán)格的高斯公式定義,高斯分布的概率密度函數(shù)公式如下:
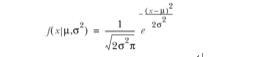
公式中包含兩個(gè)參數(shù),參數(shù)μ表示均值,參數(shù)σ表示標(biāo)準(zhǔn)差,均值對(duì)應(yīng)正態(tài)分布的中間位置,在本例中我們可以推測(cè)均值在180cm附近。標(biāo)準(zhǔn)差衡量了數(shù)據(jù)圍繞均值分散的程度。
學(xué)過(guò)大學(xué)高數(shù)的同學(xué)應(yīng)該還記得,正態(tài)分布的一個(gè)背景知識(shí)點(diǎn)是,95%的數(shù)據(jù)分布在均值周圍2個(gè)標(biāo)準(zhǔn)差的范圍內(nèi)。本例中大約20到30左右是標(biāo)準(zhǔn)差參數(shù)的取值,因?yàn)榇蠖鄶?shù)數(shù)據(jù)都分布在120cm到240cm之間。
上面的公式是概率密度函數(shù),也就是在已知參數(shù)的情況下,輸入變量指x,可以獲得相對(duì)應(yīng)的概率密度。還要注意一件事,就是在實(shí)際使用前,概率分布要先進(jìn)行歸一化,也就是說(shuō)曲線下面的面積之和需要為1,這樣才能確保返回的概率密度在允許的取值范圍內(nèi)。
如果需要計(jì)算指定區(qū)間內(nèi)的分布概率,則可以計(jì)算在區(qū)間首尾兩個(gè)取值之間的面積的大小。另外除了直接計(jì)算面積,還可以用更簡(jiǎn)便的方法來(lái)獲得同樣的結(jié)果,就是減去區(qū)間x對(duì)應(yīng)的累積密度函數(shù)(cumulative density function,CDF)。因?yàn)镃DF表示的是數(shù)值小于等于x的分布概率。
現(xiàn)在我們回到之前的例子來(lái)評(píng)估下參數(shù)和對(duì)應(yīng)的實(shí)際數(shù)據(jù)。假設(shè)我們用柱狀線來(lái)表示分布概率,每個(gè)柱狀線指相應(yīng)身高值在334個(gè)人中的分布概率,用每個(gè)身高值對(duì)應(yīng)的人數(shù)除以總數(shù)(334)就可以得到對(duì)應(yīng)概率值,圖2用左側(cè)的紅色線(Sample Probability)來(lái)表示。
如果我們?cè)O(shè)置參數(shù)μ=180,σ=28,使用累積密度函數(shù)來(lái)計(jì)算對(duì)應(yīng)的概率值——右側(cè)綠色線(Model Probability),可以肉眼觀察到模型擬合的精度。
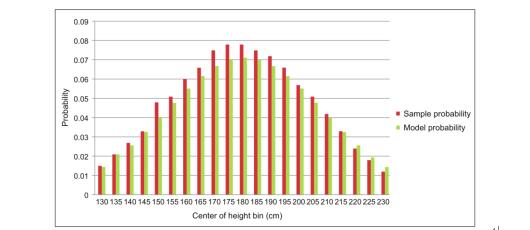
圖2
圖2:對(duì)給定用戶,身高分布的采樣概率用紅色柱狀圖表示,高斯模型在參數(shù)μ=180,σ=28時(shí)計(jì)算出的概率用綠色柱狀圖表示
觀察圖2可以看出,剛才咱們猜測(cè)的均值參數(shù)180和標(biāo)準(zhǔn)差參數(shù)28擬合的效果很不錯(cuò),雖然可能稍微偏小了一點(diǎn)點(diǎn)。當(dāng)然我們可以不斷調(diào)校參數(shù)來(lái)擬合的更好些,但是更準(zhǔn)確的辦法是通過(guò)算法來(lái)生成它們,這個(gè)過(guò)程就被稱為模型訓(xùn)練(model training)。最常用的方法是期望***(EM)算法,待會(huì)給大家詳細(xì)講解。
順便說(shuō)一句,采樣的數(shù)據(jù)和全體數(shù)據(jù)的分布情況總是存在一定差異的。這里首先假設(shè)了采集的334個(gè)用戶的數(shù)據(jù)能代表全體人口的身高分布。另外我們還假定了隱含的數(shù)據(jù)分布是高斯分布,并以此來(lái)繪制分布曲線,并以此為前提預(yù)估潛在的分布情況。如果采集越來(lái)越多的數(shù)據(jù),通常身高的分布越來(lái)越趨近于高斯(盡管仍然有其他不確定因素),模型訓(xùn)練的目的就是在這些假設(shè)前提下盡可能降低不確定性。
2. 期望***與高斯模型訓(xùn)練
模型的EM訓(xùn)練過(guò)程,直觀的來(lái)講是這樣:我們通過(guò)觀察采樣的概率值和模型概率值的接近程度,來(lái)判斷一個(gè)模型是否擬合良好。然后通過(guò)調(diào)整模型以讓新模型更適配采樣的概率值。反復(fù)迭代這個(gè)過(guò)程很多次,直到兩個(gè)概率值非常接近時(shí),我們停止更新并完成模型訓(xùn)練。
現(xiàn)在我們要將這個(gè)過(guò)程用算法來(lái)實(shí)現(xiàn),所使用的方法是模型生成的數(shù)據(jù)來(lái)決定似然值,即通過(guò)模型來(lái)計(jì)算數(shù)據(jù)的期望值。通過(guò)更新參數(shù)μ和σ來(lái)讓期望值***化。這個(gè)過(guò)程可以不斷迭代直到兩次迭代中生成的參數(shù)變化非常小為止。該過(guò)程和k-means的算法訓(xùn)練過(guò)程很相似(k-means不斷更新類中心來(lái)讓結(jié)果***化),只不過(guò)在這里的高斯模型中,我們需要同時(shí)更新兩個(gè)參數(shù):分布的均值和標(biāo)準(zhǔn)差
3. 高斯混合模型(GMM)
高斯混合模型是對(duì)高斯模型進(jìn)行簡(jiǎn)單的擴(kuò)展,GMM使用多個(gè)高斯分布的組合來(lái)刻畫數(shù)據(jù)分布。
舉個(gè)具體例子來(lái)給大家說(shuō)明:想象下現(xiàn)在咱們不再考察全部用戶的身高,而是要在模型中同時(shí)考慮男性和女性的身高。假定之前的樣本里男女都有,那么之前所畫的高斯分布其實(shí)是兩個(gè)高斯分布的疊加的結(jié)果。相比只使用一個(gè)高斯來(lái)建模,現(xiàn)在我們可以用兩個(gè)(或多個(gè))高斯分布:

該公式和之前的公式非常相似,細(xì)節(jié)上有幾點(diǎn)差異。首先分布概率是K個(gè)高斯分布的和,每個(gè)高斯分布有屬于自己的μ和σ參數(shù),以及對(duì)應(yīng)的權(quán)重參數(shù) ,權(quán)重值必須為正數(shù),所有權(quán)重的和必須等于1,以確保公式給出數(shù)值是合理的概率密度值。換句話說(shuō),如果我們把該公式對(duì)應(yīng)的輸入空間合并起來(lái),結(jié)果將等于1。
回到之前的例子,女性在身高分布上通常要比男性矮,如圖3所示:

圖3:男性和女性身高的概率分布圖
圖3的y-軸所示的概率值,是在已知每個(gè)用戶性別的前提下計(jì)算出來(lái)的。但通常情況下我們并不能掌握這個(gè)信息(也許在采集數(shù)據(jù)時(shí)沒記錄),因此不僅要學(xué)出每種分布的參數(shù),還需要生成性別的劃分情況( )。當(dāng)決定期望值時(shí),需要將權(quán)重值分別生成男性和女性的相應(yīng)身高概率值并相加。
注意雖然現(xiàn)在模型更復(fù)雜了,但仍然可使用與之前相同的技術(shù)進(jìn)行模型訓(xùn)練。在計(jì)算期望值時(shí)(很可能通過(guò)已被混合的數(shù)據(jù)生成),只需要一個(gè)更新參數(shù)的***化期望策略。
4. 高斯混合模型的學(xué)習(xí)實(shí)例
前面的簡(jiǎn)單例子里使用了一維高斯模型:即只有一個(gè)特征(身高)。但高斯不僅局限于一維,很容易將均值擴(kuò)展為向量,標(biāo)準(zhǔn)差擴(kuò)展為協(xié)方差矩陣,用n-維高斯分布來(lái)描述多維特征。接下來(lái)的程序清單里展示了通過(guò)scikit-learn的高斯混合模型運(yùn)行聚類并對(duì)結(jié)果進(jìn)行可視化展示。
在初始化GMM算法時(shí),傳入了以下參數(shù):
- -n_components ——用戶混合的高斯分布的數(shù)量。之前的例子里是2個(gè)。
- -covariance_type ——約定協(xié)方差矩陣的屬性,即高斯分布的形狀。參考下面文檔來(lái)具體了解:http://scikit-learn.org/stable/modules/mixture.html
- -n_iter —— EM的迭代運(yùn)行次數(shù)。
計(jì)算結(jié)果如下圖(Iris數(shù)據(jù)集):
- 有關(guān)make_ellipses ——make_ellipses來(lái)源于plot_gmm_classifier方法,作者為scikit-learn的Ron Weiss和Gael Varoquaz。根據(jù)協(xié)方差矩陣?yán)L制的二維圖形,可以找出方差***和其次大的坐標(biāo)方向,以及相對(duì)應(yīng)的量級(jí)。然后使用這些坐標(biāo)軸將相應(yīng)的高斯分布的橢圓圖形繪制出來(lái)。這些軸方向和量級(jí)分別被稱為特征向量(eigenvectors)和特征值(eigenvalues)。
據(jù)集的4-D高斯聚類結(jié)果在二維空間上的映射圖")
圖4:展示了Iris數(shù)據(jù)集的4-D高斯聚類結(jié)果在二維空間上的映射圖
make_ellipses方法在概念上很簡(jiǎn)單,它將gmm對(duì)象(訓(xùn)練模型)、坐標(biāo)軸、以及x和y坐標(biāo)索引作為參數(shù),運(yùn)行后基于指定的坐標(biāo)軸繪制出相應(yīng)的橢圓圖形。
5. k-means和GMM的關(guān)系
在特定條件下,k-means和GMM方法可以互相用對(duì)方的思想來(lái)表達(dá)。在k-means中,根據(jù)距離每個(gè)點(diǎn)最接近的類中心來(lái)標(biāo)記該點(diǎn)的類別,這里存在的假設(shè)是每個(gè)類簇的尺度接近且特征的分布不存在不均勻性。這也解釋了為什么在使用k-means前對(duì)數(shù)據(jù)進(jìn)行歸一會(huì)有效果。高斯混合模型則不會(huì)受到這個(gè)約束,因?yàn)樗鼘?duì)每個(gè)類簇分別考察特征的協(xié)方差模型。
K-means算法可以被視為高斯混合模型(GMM)的一種特殊形式。整體上看,高斯混合模型能提供更強(qiáng)的描述能力,因?yàn)榫垲悤r(shí)數(shù)據(jù)點(diǎn)的從屬關(guān)系不僅與近鄰相關(guān),還會(huì)依賴于類簇的形狀。n維高斯分布的形狀由每個(gè)類簇的協(xié)方差來(lái)決定。在協(xié)方差矩陣上添加特定的約束條件后,可能會(huì)通過(guò)GMM和k-means得到相同的結(jié)果。
實(shí)踐中如果每個(gè)類簇的協(xié)方差矩陣綁定在一起(就是說(shuō)它們完全相同),并且矩陣對(duì)角線上的協(xié)方差數(shù)值保持相同,其他數(shù)值則全部為0,這樣能夠生成具有相同尺寸且形狀為圓形類簇。在此條件下,每個(gè)點(diǎn)都始終屬于最近的中間點(diǎn)對(duì)應(yīng)的類。
在k-means方法中,使用EM來(lái)訓(xùn)練高斯混合模型時(shí)對(duì)初始值的設(shè)置非常敏感。而對(duì)比k-means,GMM方法有更多的初始條件要設(shè)置。實(shí)踐中不僅初始類中心要指定,而且協(xié)方差矩陣和混合權(quán)重也要設(shè)置。這里可以運(yùn)行k-means來(lái)生成類中心,并以此作為高斯混合模型的初始條件。由此可見兩個(gè)算法有相似的處理過(guò)程,主要區(qū)別在于模型的復(fù)雜度不同。
整體來(lái)看,所有無(wú)監(jiān)督機(jī)器學(xué)習(xí)算法都遵循一條簡(jiǎn)單的模式:給定一系列數(shù)據(jù),訓(xùn)練出一個(gè)能描述這些數(shù)據(jù)規(guī)律的模型(并期望潛在過(guò)程能生成數(shù)據(jù))。訓(xùn)練過(guò)程通常要反復(fù)迭代,直到無(wú)法再優(yōu)化參數(shù)獲得更貼合數(shù)據(jù)的模型為止。
【本文為51CTO專欄作者“達(dá)觀數(shù)據(jù)”的原創(chuàng)稿件,轉(zhuǎn)載可通過(guò)51CTO專欄獲取聯(lián)系】