













大型語言模型如何教會自己遵循人類指令?
譯文譯者 | 李睿
審校 | 重樓
如今,人們對能夠使大型語言模型(LLM)在很少或沒有人為干預的情況下改進功能的技術越來越感興趣。大型語言模型(LLM)自我改進的領域之一是指令微調(IFT),也就是讓大型語言模型教會自己遵循人類指令。

指令微調(IFT)是ChatGPT和Claude等大型語言模型(LLM)獲得成功的一個主要原因。然而,指令微調(IFT)是一個復雜的過程,需要耗費大量的時間和人力。Meta公司和紐約大學的研究人員在共同發表的一篇論文中介紹了一種名為“自我獎勵語言模型”的新技術,這種技術提供了一種方法,使預訓練的語言模型能夠創建和評估示例,從而教會自己進行微調。
這種方法的優點是,當多次應用時,它會繼續改進語言模型。自我獎勵語言模型不僅提高了它們的指令遵循能力,而且在獎勵建模方面也做得更好。
自我獎勵的語言模型
對大型語言模型(LLM)進行微調以適應指令遵循的常用方法是基于人類反饋強化學習(RLHF)。
在人類反饋強化學習(RLHF)中,語言模型根據從獎勵模型收到的反饋來學習優化其反應。獎勵模型是根據人類注釋者的反饋進行訓練的,這有助于使語言模型的響應與人類的偏好保持一致。人類反饋強化學習(RLHF)包括三個階段:預訓練大型語言模型(LLM),創建基于人類排名輸出的獎勵模型,以及強化學習循環,其中大型語言模型(LLM)根據獎勵模型的分數進行微調,以生成與人類判斷一致的高質量文本。
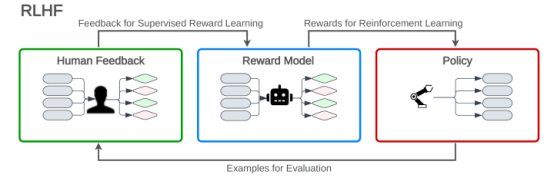 圖1人類反饋強化學習(RLHF)
圖1人類反饋強化學習(RLHF)
另一種方法是直接偏好優化(DPO),在這種方法中,語言模型可以生成多個答案,并從人類那里接收直接反饋得知哪一個答案更可取。在直接偏好優化(DPO)中,不需要創建單獨的獎勵模型。
雖然這些技術已被證明是有效的,但它們都受到人類偏好數據的大小和質量的限制。人類反饋強化學習(RLHF)具有額外的限制,即一旦訓練完成,獎勵模型就會被凍結,其質量在大型語言模型(LLM)的整個微調過程中都不會改變。
自我獎勵語言模型(SRLM)的思想是創建一種克服這些限制的訓練算法。研究人員在論文中寫道:“這種方法的關鍵是開發一個擁有訓練過程中所需的所有能力的代理,而不是將它們分成不同的模型,例如獎勵模型和語言模型。”
自我獎勵語言模型(SRLM)有兩個主要功能:首先,它可以對用戶的指令提供有益且無害的響應。其次,它可以創建和評估指令和候選響應的示例。
這使得它能夠在人工智能反饋(AIF)上迭代訓練自己,并通過創建和訓練自己的數據來逐步改進。
在每次迭代中,大型語言模型(LLM)在遵循指令方面變得更好。因此,它在為下一輪訓練創建示例方面也有所改進。
自我獎勵語言模型(SRLM)的工作原理
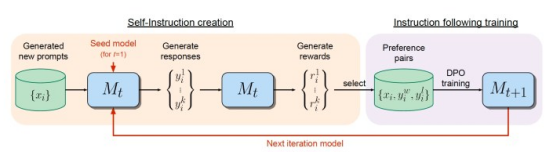 圖2自我獎勵語言模型(SRLM)創建自己的訓練示例并對其進行評估
圖2自我獎勵語言模型(SRLM)創建自己的訓練示例并對其進行評估
自我獎勵的語言模型從在大量文本語料庫上訓練的一個基礎大型語言模型(LLM)開始。然后,該模型在一小部分人類注釋的示例上進行微調。其種子數據包括指令微調(IFT)示例,其中包括成對的指令和響應對。
為了改進結果,種子數據還可以包括評估微調(EFT)示例。在評估微調(EFT)中,為大型語言模型(LLM)提供一條指令和一組響應。它必須根據響應與輸入提示的相關性對響應進行排序。評估結果由推理描述和最終分數組成,這些例子使大型語言模型(LLM)能夠發揮獎勵模型的作用。
一旦在初始數據集上進行了訓練,該模型就可以為下一次訓練迭代生成數據。在這個階段,模型從原始的指令微調(IFT)數據集中采樣示例,并生成一個新的指令提示符。然后,它為新創建的提示生成幾個候選響應。
最后,該模型采用LLM-as-a-Judge對響應進行評估。LLM-as-a-Judge需要一個特殊的提示,包括原始請求、候選人回復和評估回復的說明。
 圖3 LLM-as-a-judge提示
圖3 LLM-as-a-judge提示
一旦模型創建了指令示例并對響應進行了排序,自我獎勵語言模型(SRLM)就會使用它們來創建人工智能反饋訓練(AIFT)數據集,也可以使用這些說明以及回答和排名分數來創建偏好數據集。有兩種方法可以組裝訓練數據集。一個是該數據集可以與直接偏好優化(DPO)一起使用,以教會語言模型區分好響應和壞響應。另一個是可以創建一個僅包含最高排名響應的監督微調(SFT)數據集。研究人員發現,加入排名數據可以提高訓練模型的性能。
一旦新創建的示例被添加到原始數據集中,就可以再次訓練模型。這個過程將重復多次,每次循環都會創建一個模型,該模型既能更好地遵循指示又能更好地評估響應。
研究人員寫道:“重要的是,由于該模型既可以提高其生成能力,又可以通過相同的生成機制作為自己的獎勵模型,這意味著獎勵模型本身可以通過這些迭代得到改進。我們相信,這可以提高這些學習模式未來自我完善的潛力上限,消除了制約瓶頸。”
實驗自我獎勵語言模型(SRLM)
研究人員以Llama-2-70B為基礎模型測試了自我獎勵語言模型。作為指令微調的種子數據,他們使用了包含數千個指令微調示例的Open Assistant數據集。Open Assistant還提供了具有多個排序響應的指令示例,這些指令可用于評估微調(EFT)。
他們的實驗表明,自我獎勵語言建模的每一次迭代都提高了大型語言模型(LLM)遵循指令的能力。此外,大型語言模型(LLM)在獎勵建模方面變得更好,這反過來又使它能夠為下一次迭代創建更好的訓練示例。他們在AlpacaEval基準測試上的測試表明,三次迭代自我獎勵語言模型(SRLM)的Llama-2表現優于Claude 2、Gemini Pro和GPT-4.0613。
但是,這種方法也有局限性。像其他允許大型語言模型(LLM)自我改進的技術一樣自我獎勵語言模型(SRLM)可能導致模型陷入“獎勵黑客”陷阱,在這個陷阱中,它開始優化響應以獲得所需的輸出,但其原因是錯誤的。獎勵黑客攻擊可能導致不穩定的語言模型在現實世界的應用程序和不同于其訓練示例的情況下表現不佳。也不清楚這個過程可以在多大程度上根據模型大小和迭代次數進行縮放。
但是自我獎勵語言模型(SRLM)具有明顯的優勢,可以為訓練數據提供更多信息。如果已經有一個帶注釋的訓練示例的數據集,那么可以使用自我獎勵語言模型(SRLM)來提高大型語言模型(LLM)的能力,而無需向數據集添加更多示例。
研究人員寫道:“我們相信這是一個令人興奮的研究方向,因為這意味著該模型能夠在未來的迭代中更好地為改進指令遵循分配獎勵——這是一種良性循環。雖然這種改進在現實情況下可能會飽和,但它仍然允許持續改進的可能性,而人類的偏好通常用于建立獎勵模型和指令遵循模型。”
原文標題:How language models can teach themselves to follow instructions,作者:Ben Dickson




























