如何教會AI像人類一樣進行規劃?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
人類的規劃是分層級的。無論是做晚餐這種簡單的事,還是如出國旅行這種稍微復雜的事,我們通常都會先在腦海中勾勒出想要實現的目標,接著進一步把目標逐步細化為一系列詳細的下級目標、下下級目標等,最終實際的行動順序會比最開始的計劃復雜得多。
高效規劃需要了解構成分層規劃的實質的抽象高級概念。至今,人類習得這種抽象的概念的過程仍然未知。
人類能自發構建這種高級概念,可以根據所處環境的任務、回報和結構,做出高效的規劃。同時,由于這種行為與底層計算的形式化模型是一致的,這些發現因此得以建立在既定的計算原則上,并和以前分層規劃的相關研究聯系起來。
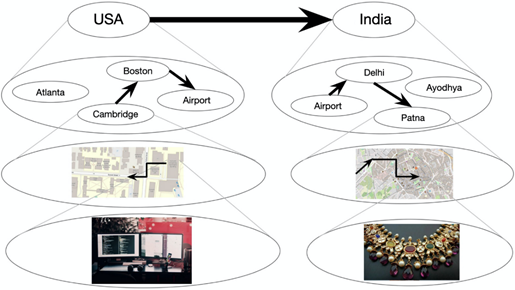
分層規劃示例
上圖描述了一個分層規劃的例子,即一個人是如何規劃離開在劍橋的辦公室,之后前往印度的Patna購買一件夢想的婚紗裝飾。圓表示狀態,箭頭表示狀態之間的轉換。每個狀態代表了一組較低級別的狀態。加粗的箭頭表示的是通常最先在腦海中閃現的高級狀態之間的轉換。
貝葉斯視角
當應用于計算式智能體時,分層規劃使模型具備更高級的規劃本領。通過假設一個在特定環境結構下的生成過程,可以從貝葉斯視角對分層代表進行建模。有關這一問題的現有工作包括開發一個計算框架,以便在一系列簡化過的關于層級結構的假設下獲取分層代表,即模擬人們如何在無獎勵環境的心理表征下,創建方便規劃的狀態集群。
在為了預測聚類的形成,并將該模型與人類的數據進行比較,我們創建了一個結合聚類和獎勵的層次化發現的貝葉斯認知模型。
我們分析了靜態和動態兩種獎勵機制下的情況,發現人類將獎勵信息泛化到高層集群中,并利用獎勵的信息來創建集群,說明模型可以預測獎勵泛化和基于獎勵的集群形成。
理論背景
心理學和神經科學交叉的關鍵領域即是形式上理解人類行為與指定行為的關系。我們想知道:完成某個任務后,人工智能接著會采用什么樣的計劃和方法?人類是如何發現有用的抽象概念?
這個問題很有趣,人類和動物擁有適應新環境的獨特能力,以前關于動物學習的文獻表明,這種靈活性源于目標的分層代表,這使復雜的任務分解成可延伸至各種環境的低級子程序。
分組
分組發生在動作被組合成可以實現更遠目標的延時的動作序列,它通常出現在學習從目標導向系統轉移到以刻板的方式執行動作的習慣系統之后。
從計算的角度來看,由于這種分層代表,智能體能夠在開環中快速執行操作;可以在遇到已知的問題時重復利用熟悉的操作序列;甚至能夠調整已建立的動作序列來解決以前遇到過的問題,從而更加快速地學習并延長時間范圍內的計劃。
智能體不需要考慮與目標相關的細枝末節,例如,去商店的目標被分解為離開房間、步行和進入商店,而不是起床、左腳前移到右腳前移等。
分層強化學習
智能體如何做出能得到獎勵的決定是強化學習的主題。分層強化學習(HRL)已成為描述分層學習和規劃的主流框架,在對HRL建模的研究中,已經存在圍繞構建模型的潛在方法的觀點。
筆者關注到人們自發地將環境規劃為制約規劃的狀態集群。在時間和記憶方面,這種分層規劃比平面規劃更為有效,后者包括低級別的行動,并有賴于人們有限的工作記憶容量。
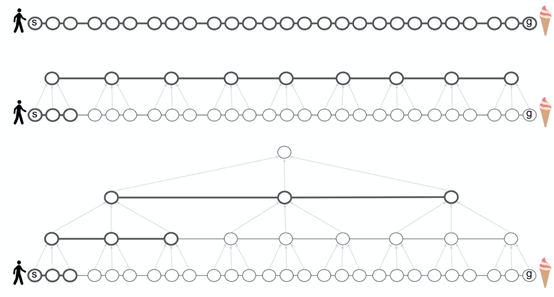
在下圖中,粗節點和粗邊表示必須在短期記憶范圍內考慮和維護它們,以便計算規劃,灰色箭頭表示集群成員。低級別圖G中,從狀態s到狀態g的規劃所需步驟至少是與實際執行計劃的步驟相同(頂部),引入高級圖H緩解了這一問題,降低了計算成本(中間)。同時,進一步擴展遞歸層次減少了規劃(底部)所涉及的時間和內存。
Solway等人提供了一個最優分層的正式定義,但他們沒有明確大腦可能如何發現它。筆者假設了一個最優分層取決于環境結構,包括圖結構和環境可觀察特征的分布,特別是獎勵。
模型
假設智能體將其環境視作一個圖,其中節點是在環境中的狀態,邊是狀態之間的轉變。這些狀態和轉變可以是抽象的,同樣,它也可以如地鐵站及其中的行駛的列車路線一樣是具體的。
結構
將可觀測環境表示為圖G=(V,E),潛分層表示為H。G和H都是無權無向的,H由集群組成,其間G中的每個低級節點恰好屬于一個集群,以及連接這些集群的橋或高級邊。集群k和k′之間的橋只有在某些v,v′∈V之間存在一條邊使v∈k和v′∈k'的情況下才會存在,即H中的每一條高級邊在G中都有一條對應的低級邊。
在下圖中,顏色表示集群分配。規劃時規劃者會考慮黑色邊緣,但忽略灰色邊緣,粗邊對應于集群之間的轉變,集群w和z之間的轉變是通過一個橋來完成的。

高級圖(頂部)和低級圖(底部)的例子
在添加獎勵之前,學習算法在發現最優分層的時候會受以下制約:
- 小集群
- 集群內的緊密連接
- 集群間的稀疏連接
然而,我們不希望集群太小——在極端情況下,每個節點都是自己的集群,這讓層次結構毫無用處。此外,雖然跨集群的稀疏連接是我們所期望的,但我們也希望集群之間的橋梁仍存,借以保留底層圖片的屬性。
我們使用了離散時間隨機的中餐館過程(CRP)作為聚類的先驗。分層發現在倒置生成模型以獲得分層H后驗概率的過程中實現。在中正式出現的生成模型生成了該分層。
獎勵
在圖G的語境中,獎勵可以解釋為頂點的可視特征。由于人們通常基于可視的特征進行聚類,因此由獎勵誘導的聚類模型是合理的。此外,我們設定了每個狀態都提供一個隨機確定的獎勵,而智能體的目標是最大化總獎勵。
因為我們假設集群會誘導獎勵,所以建立的每個集群具有均等回報。該集群中的每個節點都有一個從均等獎勵集群為中心的分布中提取的均等獎勵。最后,每個可視獎勵都是從以該節點的均等獎勵為中心的分布中提取的。
為了簡化推論,首先假設報酬是恒定的、靜態的。某些在固定概率的觀測值之間變化的獎勵被標記為動態的。
我們用了兩個實驗來驗證關于人類行為的假設,以及了解模型的預測能力。特別的是,我們研究了集群在多大程度上推動了對獎勵的推導,以及在多大程度上獎勵驅動了集群的形成。對于每個實驗,我們都收集人類數據并將其與模型的預測進行比較。
集群誘導獎勵
第一個實驗的目標是了解獎勵在狀態集群中普及的方式。我們測試了圖形結構是否驅動了集群的形成,以及人們是否將在一個節點上觀察到的獎勵推廣到該節點所屬的集群。
建立
讓32名受試者按照下面的場景,選擇下一個要訪問的節點。下面的圖表或是它的翻轉版本會被隨機地呈現在參與者面前,以確保沒有人為偏差或未介紹的圖形結構。我們預測參與者選擇的節點會靠近位于更大集群處的標記節點,第一種情況下,灰色節點位于藍色節點左側,灰色節點位于藍色節點右側。
以下任務和相關圖表會展示給參與者:
你在一個由多個獨立礦山和隧道組成的大型金礦中工作。礦井布局如下圖所示(每個圓圈代表一個礦井,每條線代表一個隧道)。你每天都有報酬,此外當天發現的每克黃金都有10美元的報酬。你每天只挖一個礦,并記錄下當天的黃金產量(以克為單位)。在過去的幾個月里,你發現平均來說,每個礦每天產出約15克黃金。昨天,你在下圖中挖了一個藍色的礦,得到了30克黃金。你今天要在兩個礦井(陰影部分)中挖哪一個?請圈出你選擇的礦。
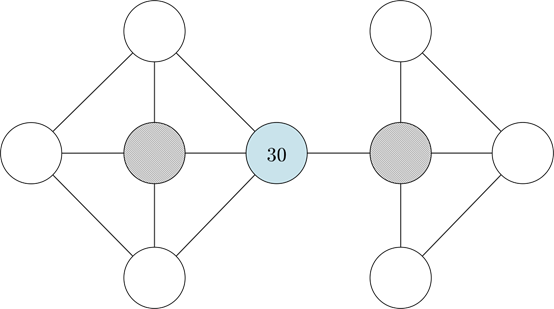
展示給參與者的礦井圖紙
我們希望大多數參與者能夠自動識別以下用桃色和薰衣草色的節點來表示的不同集群,并根據這些集群決定選哪一個集群。假設參與者會選擇桃色而非薰衣草色的的節點,因為標簽為30的節點(比平均值大得多)位于桃色集群中。
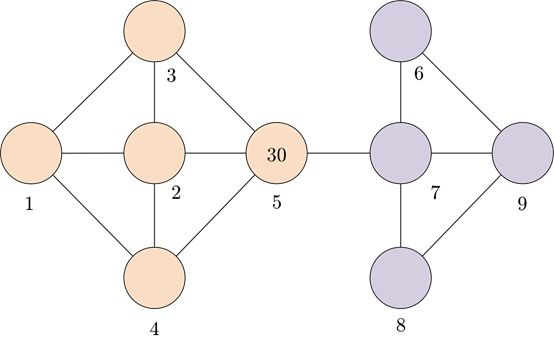
展示給參與者的和集群類似的礦井圖紙
推論
我們使用了Metropolis-within-Gibbs抽樣,對H近似套用了貝葉斯推導。這組樣本通過H的后續取樣來更新H的每個分量,在一個Metropolis-Hastings步驟中對所有其他分量進行條件調節。使用高斯隨機游走作為連續分量的建議分布,并使用有前提的CRP先驗作為分組分配的建議分布。該方法可以被解釋為隨機爬山算法后續定義了一個效用函數。
結果
在真人組和模擬組中各有32名參與者。模型輸出的前三個集群如下所示(左側區域)。所有前三名的結果都是一樣的,這表明該模型以很高的可信度識別了有色分組。
參與者和靜態獎勵模型的結果顯示在下面的條形圖(右面區域)中,展示了選擇下一訪問節點2的人類和模擬受試者的比例。實心黑線表示平均值,黑色虛線表示2.5%和97.5%。
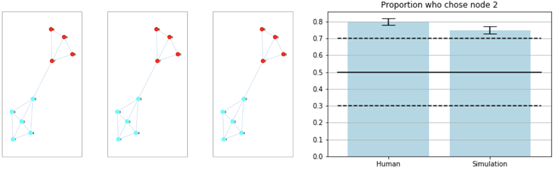
聚類實驗中獎賞泛化的結果
下表中的p-value是通過右尾二項檢定計算的,其中空值假設為二項分布,而非選擇左、右灰色節點。顯著性水平取0.05,人體實驗結果和模型結果均具有統計學意義。
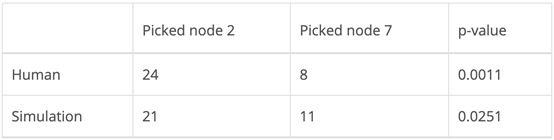
人類行為與靜態獎勵模型
獎勵誘導集群
第二個實驗的目標是確定獎勵是否會誘發集群。我們預測,即使圖的結構本身不會誘導聚類,但相鄰位置相同獎賞的節點也會聚集在一起。
Solway等人的研究表明人們更喜歡跨越最少分層邊界的路徑。因此,在兩條完全相同的路徑之間,選擇其中一條路徑的唯一原因是它跨越了更少的分層邊界。對此可能的反駁是,人們會選擇的是獎勵更高的路徑。
然而,在下面詳述的建立中,只在目標狀態下會提供獎勵,而不是沿著所選的路徑漸次累積。此外,獎勵的大小在不同的試驗中是不同的。因此,人們不太可能因該路徑的節點有更高的獎勵而喜歡上一條路徑。
建立
這個實驗是在網絡上使用亞馬遜Mechanical-Turk(MTurk)。參與者會獲得以下任務背景:
假設你是一名礦工,在由隧道連接的金礦網絡中工作。每個礦每天產出一定數量的黃金(以“點數”指代)。在每一天,你的工作是從一個起始礦井導航到一個目標礦井,并在目標礦井收集點數。在某些日子里,你可以自由選擇任何你喜歡的礦井。此時,你應該試著選一個所得點數最高的礦。而在其他日子里,只有一個礦是可用的。該礦的點呈綠色,其他礦點呈灰色不可選。此時你只能導航到可用礦井。每個礦井的點數都會在上面寫明。當前礦井將用粗邊界突出顯示。你可以使用箭頭鍵(上、下、左、右)在礦井之間導航。一旦你到達目標礦井,按空格鍵收集點數并開始第二天的工作。實驗將有100天(試驗)。
下面的圖表(左邊)呈現給參與者。為了控制潛在的左右不對稱性,與之前的實驗一樣,參與者被隨機分配到圖中所示的布局或其水平翻轉版本。預期的誘導集群也被描述,并編號了節點以供參考(右邊)。
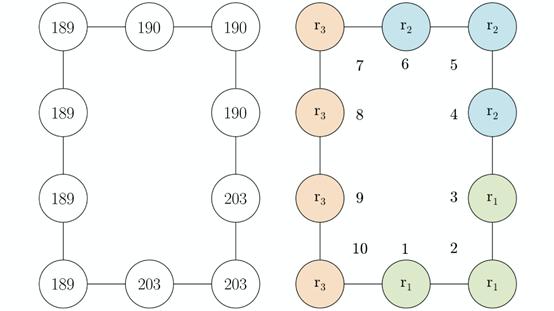
向MTurk參與者展示的礦井圖(左),以及可能的集群(右)
我們將第一種情況稱為參與者選擇自由式導航到任何礦井,第二種情況是參與者固定選擇式導航到指定礦井。參加者在每次試驗中都會獲得金錢獎勵,以阻止隨機響應。
在每次試驗中,獎勵值的變化概率為0.2。新的獎勵從區間[0,300]中隨機抽取。然而在試驗之間,獎勵的分組保持不變:節點1、2和3始終共有一個獎勵值,節點4、5和6共有另一種的獎勵值,節點7、8、9和10具有第三種獎勵值。
前99次試驗允許參與者建立一個集群的分層結構。實驗的最終試驗要求參與者從節點6導航到節點1。假設獎勵誘導了上面所示的集群,我們預測更多的參與者將選擇通過節點5的路徑,該節點只跨越了一個集群邊界,而通過節點7的路徑跨越兩個集群邊界。
推論
我們建立了固定選擇案例的模型,假設所有100個試驗中的任務都與提交給參與者的第100個試驗相同。首先假定靜態獎勵,在所有的測試中,該獎勵保持不變。接下來,假設動態獎勵,即每次試驗的獎勵都會發生變化。
與之前模型預測參與者選擇的節點的實驗不同,本實驗關注的是參與者選擇的從起始節點到目標節點的完整路徑中的第二個節點。因此,為了將模型與人為數據進行比較,使用廣度優先搜索的一種變體(以下稱為分層BFS)來預測從起始節點(節點6)到目標節點(節點1)的路徑。
靜態獎勵。對于每個受試者,使用Metropolis-within-Gibbs抽樣,從后驗樣本中取樣,并選擇最有可能的分層,即具有最高后驗概率的分層。然后,使用層次化的BFS,首先在集群間找路徑,然后在集群內的節點間找路徑。
動態獎勵。對于動態獎勵,我們使用在線推斷。對于每個模擬的參與者,每個試驗的取樣只進行10步,然后保存分層并添加有關修改后獎勵的信息。接下來從保存的分層開始再次采樣。在人為試驗中,盡管在群體中獎勵總是相等的,但是每個試驗開始時獎勵被重新隨機分配新值的概率為0.2。
這種推理方法模擬了人類參與者在許多的試驗過程中累積學習的方式。為了達到實驗目的,假設人們一次只記住一個分層,而不會同時更新多個分層。對數后驗被修改以判罰未連接集群,因為在這類推論下,此類集群更加普遍。
結果
人類組和兩個模擬組都有95名參與者。相等數量的參與者選擇通過節點5和通過節點7的路徑為零假設代表,因為在沒有任何其他信息的情況下,假設兩條路徑的長度相等,參與者選擇其中一條的可能性相等。
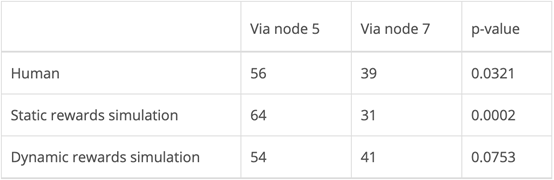
人類行為與靜態和動態獎勵模型
如上表所示,人類試驗和靜態獎勵建模的結果在α=0.05時具有統計學意義。此外,如下所示,人類試驗的結果位于正態分布的第90個百分位數,以0.5為中心,給出零假設時的預期比例。
在該圖中,我們包括由靜態獎勵模型(第一行),具有在斷開的組成部分之間形成簇的靜態獎勵模型(第二行)和動態獎勵模型(第三行)標識的聚類。
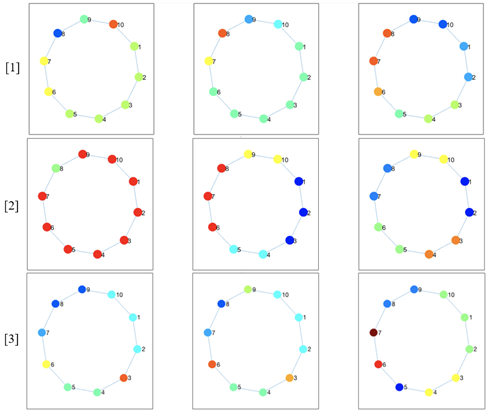
模擬識別的集群
靜態獎勵。我們使用了1000次Metropolis-in-Gibbs采樣來生成每個樣本,每個樣本的老化和滯后均為1。靜態獎勵下的模擬肯定會有利于通過節點5的路徑達到統計上有意義的水平。此外,由于其目的是對人類行為進行建模,因此鑒于人類數據也具有統計學意義(0.0321<α= 0.05),那么該結果是有意義的。
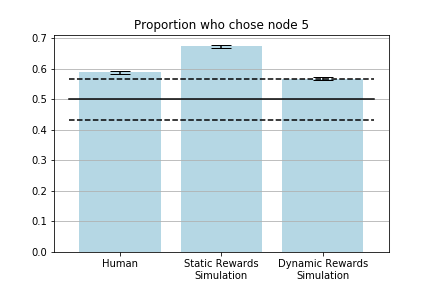
人類和模擬受試者的選擇
動態獎勵。為了模擬人類試驗,我們進行了100次試驗,每次試驗進行了10次Metropolis-within-Gibbs迭代,以便后方取樣。burnin和lag再次設置為1。
盡管比起靜態獎勵模型下的模擬組,動態獎勵模型下的模擬者組離假設更遠,但比起靜態獎勵,在線推理方法似乎更適合創建人類數據的模型。在動態獎勵模型下,56名人類參與者和54名模擬參與者選擇了節點5(3.4%的差異),而靜態獎勵模型下的64名模擬參與者(18.5%的差異)。
上面的柱狀圖顯示了選擇路徑的第二個節點是節點5的人類和模擬者的比例。實心黑線表示在給出零假設的情況下的預期比例,黑色虛線表示第10和第90個百分位。
人類似乎會自發地將環境組織成支持分層規劃的狀態集群,從而通過將問題分解為不同抽象級別的子問題,來解決具有挑戰性的問題。人們總是依賴這種等級分明的陳述來完成大大小小的任務,而他們往往第一次嘗試就成功了。
我們證明了一個最優分層不僅取決于圖的結構,而且還取決于環境的可視特征,即獎勵的分布。我們建立了分層貝葉斯模型,以了解聚類如何誘發靜態獎勵,以及靜態和動態獎勵如何誘發聚類,并發現就我們的模型捕獲人類行為的緊密程度而言,大多數結果在統計層面上都是顯著的。