在 Kubernetes 環境下如何優雅擴縮容 Pulsar
背景
在整個大環境的降本增效的熏陶下,我們也不得不做好應對方案。
根據對線上流量、存儲以及系統資源的占用,發現我們的 Pulsar 集群有許多的冗余,所以考慮進行縮容從而減少資源浪費,最終也能省一些費用。
不過在縮容之前很有必要先聊聊擴容,Pulsar 一開始就是存算分離的架構(更多關于 Pulsar 架構的內容本文不做過多介紹,感興趣的可以自行搜索),天然就非常適合 kubernetes 環境,也可以利用 kubernetes 的能力進行快速擴容。
擴容
Pulsar 的擴容相對比較簡單,在 kubernetes 環境下只需要修改副本即可。
Broker
當我們的 broker 層出現瓶頸時(比如 CPU、內存負載較高、GC 頻繁時)可以考慮擴容。
計算層都擴容了,也需要根據流量計算下存儲層是否夠用。
如果我們使用的是 helm 安裝的 Pulsar 集群,那只需要修改對于的副本數即可。
broker:
configuration
component: broker
replicaCount: 3->5當我們將副本數從 3 增加到 5 之后 kubernetes 會自動拉起新增的兩個 Pod,之后我們啥也不需要做了。
Pulsar 的負載均衡器會自動感知到新增兩個 broker 的加入,從而幫我們將一些負載高的節點的流量遷移到新增的節點中。
Bookkeeper
在介紹 bookkeeper 擴容前先簡單介紹些 Bookkeeper 的一些基本概念。
- Ensemble size (E):當前 Bookkeeper 集群的節點數量
- Write quorum size (QW):一條消息需要寫入到幾個 Bookkeeper 節點中
- ACK quorum size (QA):有多少個 Bookkeeper 節點 ACK 之后表示寫入成功
對應到我們在 broker.conf 中的配置如下:
managedLedgerDefaultEnsembleSize: "2"
managedLedgerDefaultWriteQuorum: "2"
managedLedgerDefaultAckQuorum: "2"這個三個參數表示一條消息需要同時寫入兩個 Bookkeeper 節點,同時都返回 ACK 之后才能表示當前消息寫入成功。
從這個配置也可以看出,Bookkeeper 是多副本寫入模型,適當的降低 QW 和 QA 的數量可以提高寫入吞吐率。
大部分場景下 Bookkeeper 有三個節點然后 E/QW/QA 都配置為 2 就可以滿足消息多副本寫入了。
多副本可以保證當某個節點宕機后,這個節點的消息在其他節點依然有存放,消息讀取不會出現問題。
那什么情況下需要擴容 Bookkeeper 了,當然如果單個 Bookkeeper 的負載較高也是可以擴容的。
但我們當時擴容 Bookkeeper 的場景是想利用 Pulsar 的資源隔離功能。
因為有部分業務的消息量明顯比高于其他的 topic,這樣會導致某個 Broker 的負載較高,同時也可能影響到其他正常的 topic。
最好的方式就將這部分數據用單獨的 broker 和 Bookkeeper 來承載,從而實現硬件資源的隔離。
這樣的需求如果使用其他消息隊列往往不太好實現,到后來可能就會部署多個集群來實現隔離,但這樣也會增加運維的復雜度。
好在 Pulsar 天然就支持資源隔離,只需要一個集群就可以實現不同 namespace 的流量隔離。
此時就可以額外擴容幾個 Bookkeeper 節點用于特定的 namespace 使用。
 圖片
圖片
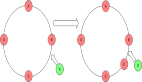
從上圖可以看到:我們可以將 broker 和 Bookkeeper 分別進行分組,然后再配置對應的 namespace,這樣就能實現資源隔離了。
更多關于資源隔離的細節本文就不過多贅述了。
鋪墊了這么多,其實 Bookkeeper 的擴容也蠻簡單的:
bookkeeper:
component: bookie
metadata:
resources:
# requests:
# memory: 4Gi
# cpu: 2
replicaCount: 3->5和 broker 擴容類似,提高副本數量后,Pulsar 的元數據中心會感知到新的 Bookkeeper 節點加入,從而更新 broker 中的節點數據,這樣就會根據我們配置的隔離策略分配流量。
縮容
其實本文的重點在于縮容,特別是 Bookkeeper 的縮容,這部分內容我在互聯網上很少看到有人提及。
Broker
Broker 的縮容相對簡單,因為存算分離的特點:broker 作為計算層是無狀態的,并不承載任何的數據。
其實是承載數據的,只是 Pulsar 會自動遷移數據,從而體感上覺得是無狀態的。
只是當一個 broker 下線后,它上面所綁定的 topic 會自動轉移到其他在線的 broker 中。
這個過程會導致連接了這個 broker 的 client 觸發重連,從而短暫的影響業務。
正因為 broker 的下線會導致 topic 的歸屬發生轉移,所以在下線前最好是先通過監控面板觀察需要下線的 broker topic 是否過多,如果過多則可以先手動 unload 一些數據,盡量避免一次性大批量的數據轉移。
 圖片
圖片
觀察各個broker 的 topic 數量
Bookkeeper
而 Bookkeeper 的縮容則沒那么容易了,由于它是作為存儲層,本身是有狀態的,下線后節點上存儲的數據是需要遷移到其他的 Bookkeeper 節點中的。
不然就無法滿足之前提到的 Write quorum size (QW) 要求;因此縮容還有一個潛在條件需要滿足:
縮容后的 Bookkeeper 節點數量需要大于broker 中的配置:
managedLedgerDefaultEnsembleSize: "2"
managedLedgerDefaultWriteQuorum: "2"
managedLedgerDefaultAckQuorum: "2"不然寫入會失敗,整個集群將變得不可用。
Pulsar 提供了兩種 Bookkeeper 的下線方案:
不需要遷移數據
其實兩種方案主要區別在于是否需要遷移數據,第一種比較簡單,就是不遷移數據的方案。
首先需要將 Bookkeeper 設置為 read-only 狀態,此時該節點將不會接受寫請求,直到這個 Bookkeeper 上的數據全部過期被回收后,我們就可以手動下線該節點。
使用 forceReadOnlyBookie=true 可以強制將 Bookkeeper 設置為只讀。
但這個方案存在幾個問題:
- 下線時間不確定,如果該 Bookkeeper 上存儲的數據生命周期較長,則無法預估什么時候可以下線該節點。
- 該配置修改后需要重啟才能生效,在 kubernetes 環境中這些配置都是寫在了 configmap 中,一旦刷新后所有節點都會讀取到該配置,無法針對某一個節點生效;所以可能會出現將不該下線的節點設置為了只讀狀態。
但該方案的好處是不需要遷移數據,人工介入的流程少,同樣也就減少了出錯的可能。
比較適合于用虛擬機部署的集群。
遷移數據
第二種就是需要遷移數據的方案,更適用于 kubernetes 環境。
遷移原理
先來看看遷移的原理:
- 當 bookkeeper 停機后,AutoRecovery Auditor 會檢測到 zookeeper 節點/ledger/available 發生變化,將下線節點的 ledger 信息寫入到 zookeeper 的 /ledgers/underreplicated 節點中。
- AutoRecovery ReplicationWorker 會檢測 /ledgers/underreplicated節點信息,然后輪訓這些 ledger 信息從其他在線的 BK 中復制數據到沒有該數據的節點,保證 QW 數量不變。
每復制一條數據后都會刪除 /ledgers/underreplicated 節點信息。
所有 /ledgers/underreplicated 被刪除后說明遷移任務完成。
- 執行 bin/bookkeeper shell decommissionbookie 下線命令:
- 會等待 /ledgers/underreplicated 全部刪除
- 然后刪除 zookeeper 中的元數據
- 元數據刪除后 bookkeeper 才是真正下線成功,此時 broker 才會感知到 Bookkeeper 下線。
AutoRecovery 是 Bookkeeper 提供的一個自動恢復程序,他會在后臺檢測是否有數據需要遷移。
簡單來說就是當某個Bookkeeper 停機后,它上面所存儲的 ledgerID 會被寫入到元數據中心,此時會有一個單獨的線程來掃描這些需要遷移的數據,最終將這些數據寫入到其他在線的 Bookkeeper 節點。
Bookkeeper 中的一些關鍵代碼:
 圖片
圖片
 圖片
圖片
下線步驟
下面來看具體的下線流程:
- 副本數-1
bin/bookkeeper shell listunderreplicated 檢測有多少 ledger 需要被遷移
- 執行遠程下線元數據
- nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &
- 這個命令會一直后臺運行等待數據遷移完成,比較耗時
- 查看下線節點是否已被剔除
- bin/bookkeeper shell listbookies -a
- 循環第一步
第一步是檢測一些現在有多少數據需要遷移:bin/bookkeeper shell listunderreplicated 命令查看需要被遷移的 ledger 數據也是來自于 /ledgers/underreplicated節點
 圖片
圖片
正常情況下是 0
第二步的命令會等待數據遷移完成后從 zookeeper 中刪除節點信息,這個進程退出后表示下線成功。
 圖片
圖片
這個命令最好是后臺執行,并輸出日志到專門的文件,因為周期較長,很有可能終端會話已經超時了。
我們登錄 zookeeper 可以看到需要遷移的 ledger 數據:
bin/pulsar zookeeper-shell -server pulsar-zookeeper:2181
get /ledgers/underreplication/ledgers/0000/0000/0000/0002/urL0000000002
replica: "pulsar-test-2-bookie-0.pulsar-test-2-bookie.pulsar-test-2.svc.cluster.local:3181"
ctime: 1708507296519underreplication 的節點路徑中存放了 ledgerId,通過 ledgerId 計算路徑:
 圖片
圖片
 圖片
圖片
注意事項
下線過程中我們可以查看 nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &這個命令寫入的日志來確認遷移的進度,日志中會打印當前還有多少數量的 ledger 沒有遷移。
同時需要觀察 zookeeper、Bookkeeper 的資源占用情況。
因為遷移過程中寫入大量數據到 zookeeper 節點,同時遷移數時也會有大量流量寫入 Bookkeeper。
不要讓遷移過程影響到了正常的業務使用。
根據我的遷移經驗來看,通常 2w 的ledger 數據需要 2~3 小時不等的時間,具體情況還得根據你的集群來確認。
回滾方案
當然萬一遷移比較耗時,或者影響了業務使用,所以還是要有一個回滾方案:
這里有一個大的前提:只要 BK 節點元數據、PVC(也就是磁盤中的數據) 沒有被刪除就可以進行回滾。
所以只要上述的 decommissionbookie 命令沒有完全執行完畢,我們就可以手動 kill 該進程,然后恢復副本數據。
這樣恢復的 Bookkeeper 節點依然可以提供服務,同時數據也還存在;只是浪費了一些 autorecovery 的資源。
最后當 bookkeeper 成功下線后,我們需要刪除 PVC,不然如果今后需要擴容的時候是無法啟動 bookkeeper 的,因為在啟動過程中會判斷掛載的磁盤是否有數據。
總結
總的來說 Pulsar 的擴縮容還是非常簡單的,只是對于有狀態節點的數據遷移稍微復雜一些,但只要跟著流程走就不會有什么問題。
參考鏈接: