Kubernetes的垂直和水平擴縮容的性能評估
可擴展的應用可能會采用水平或垂直擴縮容來動態調整云端資源。為了幫助選擇最佳策略,本文主要對比了kubernetes中的水平和垂直擴縮容。通過對 Web 應用程序進行綜合負載測量實驗,結果表明水平擴縮容的效率更高,對負載變化的響應更快,且對應用程序響應時間的影響更小。
簡介
云服務的負載可能會隨時間變動,為了實現可擴展,需要依據特定的指標(如CPU)來采取自動擴容策略,以此來擴大應用的處理能力。為此,我們需要均衡應用的QoS和云基礎設施的開銷,即量入為出。
當前有兩種擴縮容類型:水平,即服務的數目會視負載的情況增加或減少;垂直,即服務的資源(CPU或內存)會視負載的情況增加或減少。但即使有了這兩種方法,也沒有明確定義的標準來決定使用哪種方法。此外,在性能和成本效益方面,還缺乏與垂直自動擴縮容相關的分析,以及如何與水平自動擴縮容進行比較。
因此,為了評估這兩種方法的性能,我們使用kubernetes做了一個測量實驗,并借助了一個壓測工具,該工具可以以一種受控的方式向一個"busy-wait"應用發送請求,并根據負載發生變化后自動擴縮容決策的時間、每個決策上請求的 CPU 的容量以及應用響應時間的影響來對這些機制進行評估。
Kubernetes的自動擴縮容策略
k8s是一個基于Borg的開源項目,聚焦容器編排,并允許在集群中運行容器應用,同時簡化了不同環境(生產、開發等)的配置。總之,k8s提供了一組物理和虛擬機(節點),其中,master負責控制和給worker節點分配任務。在k8s中,pod是節點上最小的可分配單元,一個pod可以打包一個或多個容器,并定義執行規則。需要注意的是,要確保節點能夠有足夠的資源去運行對應的pod。
為了在k8s中創建一個對象,需要創建一個包含所需規格的配置文件。K8s的對象可以用于不同的目的,如監控、網絡配置、擴縮容等。因此,需要根據不同的目的來選擇不同的類型。此處使用的類型是:
- horizontal pod autoscaler
- vertical pod autoscaler
Horizontal Pod Autoscaler
水平自動擴縮容的目的是降低或增加集群中的Pods數目,以便有效地利用資源并滿足應用的需求。這種擴縮容方式圍繞某些指標,如CPU、內存、自定義指標或外部指標(基于Kubernetes外部的應用負載)。[2] [3]
為了使用水平擴縮容,需要創建一個HorizontalPodAutoscaler配置文件,并定義一個CPU百分比使用限制,如果Pod的利用率達到該限制,則會創建出更多的副本。HPA每15s(可變)會校驗是否需要創建新的Pods。
HPA 背后的算法基于 HPA 所watch的所有Pods的當前利用率的平均值(U?),期望利用率(U),以及當前副本數量(U?),因此可以根據如下格式進行計算:
Nd=Na?(Ua/Ud)Nd=Na?(Ua/Ud)
為了更好地理解上述格式,我們假設如下場景:
- 一個集群中有5個副本(N? = 5),平均利用率為限制100 milicores或0.1 CPU-core(U = 100)。
- 在一個負載峰值之后,所有pods的平均利用率上升到200m(U = 200)。
- 應用公式,得到N = 5 * (200 / 100) = 10,其中N = 10,就是在保證平均利用率為100m且兼顧到閾值的理想Pods數。
通過以上例子,可以看到HPA會將副本數翻倍,而不是每次僅創建一個副本,這種方式使得HPA非常精準。
HPA有一個默認的延遲(5分鐘),在負載降低時進行縮容。該時間僅在利用率低于定義的利用率限制時才會開始計算。
Vertical Pod Autoscaler
垂直擴縮容的目的是增加或降低現有Pods分配的資源(CPU或內存)。在Kubernetes中,它會修改Pod請求的資源容量。[4]
為了使用這種方式,需要創建一個VerticalPodAutoscaler類型的對象,并指定需要自動擴縮容的deployment。這種方式包含3個主要的組件:
- Updater:充當哨兵,校驗Pods是否有做夠的資源,否則會使用期望的資源來重啟這些Pods。
- Admission controller:和updater配合,定義合適的pod request資源容量。
- Recommender:watch資源,基于過去或當前利用率,提供建議來擴大或縮小內存或CPU。
當前VPA提供了3種類型的Recommender:
- Target:推薦理想的內存和CPU容量
- Upper bound:推薦request資源的上限值,如果request大于此限值,考慮到置信因子,將會縮小Pod的規模
- Lower bound:推薦request資源的下限值,如果request低于此限制,考慮到置信因子,將會擴大Pod的規模
置信因子是一種使VPA 在自動擴縮容決策上更加保守的一種方法。這種方式會用到如下變量:當前Pod request CPU(R?),下限(B?)及其置信因子 (a?),和上限 (B?)及其置信因子(a?)。
當R? > (B? * a?)時,VPA會減少資源規模,其中置信因子a?會隨著 Pod 啟動時間的增加而增加,并緩慢收斂到1。上限的置信因子的計算式為a? = (1 + 1/Δ?),其中Δ?是Pod創建以來的天數。
另一方面,當R? < (B? * a?)時VPA會增加資源規模,其中置信因子a?會隨著 Pod 啟動時間的增加而增加,并緩慢收斂到1。下限的置信因子的計算式為a? = (1 + 0.001/Δ?)^-2。這樣,通過置信因子,VPA可以快速做出決策。
為了更好地理解,假設一個pod當前的request CPU為R? = 100,當前下限為B? = 150,啟動以來的時間為5分鐘,將其轉換為天,得到Δ? = 5 /60/24 = 0.003472。下限的置信因子為a? = (1 + 0.001/0.00347)^-2 = 0.6,因此,可以看到100 < 150 * 0.6 ? 100 < 90,結論為false,此時不會增加Pod的容量。為了重新創建Pod,置信因子最少應該為a? = 0.67,換句話說,大約需要7分鐘才會重建。
驗證環境
為了生成并分析實驗結果,需要創建一個測試環境,并定義某種方式來生成資源利用率來觸發自動擴縮容策略,所有實驗都實現了自動化,并保存和組織實驗數據。環境的架構和組件如下圖所示:
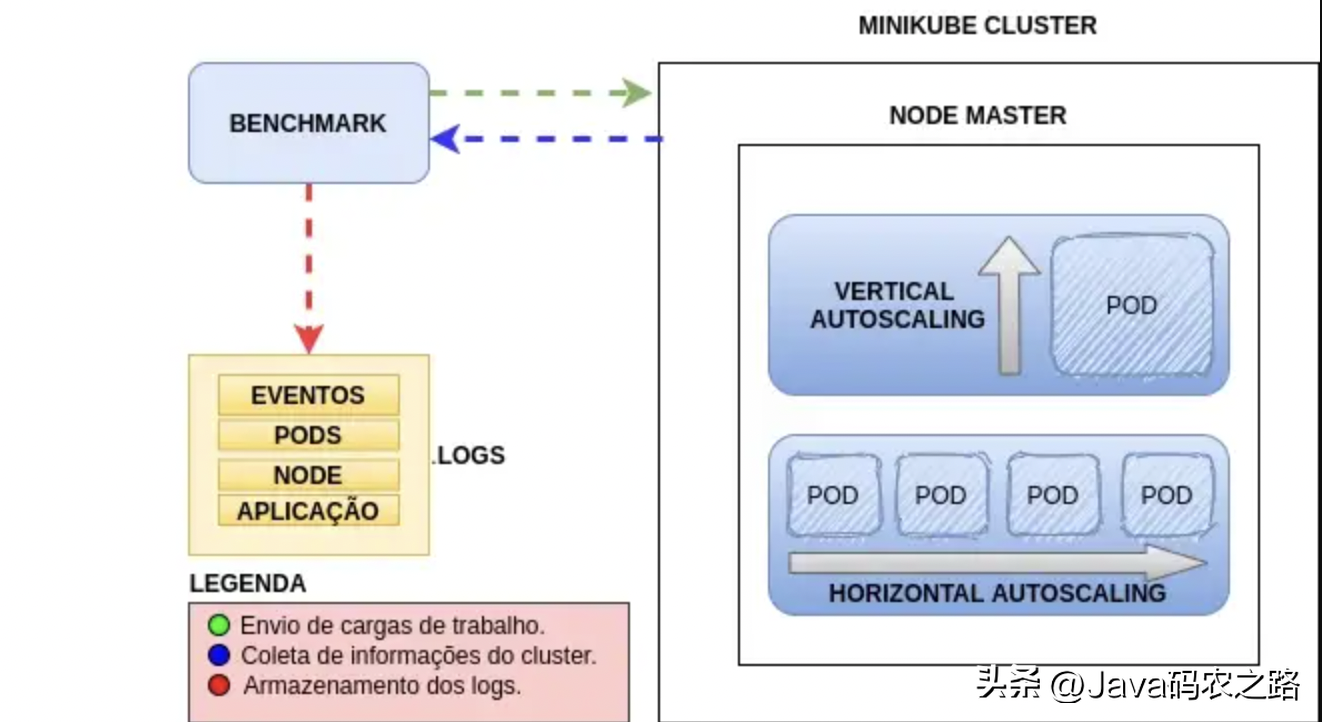
- Eventos: 事件
- Aplica??o: 應用
- Legenda: 副標題
- Green: 分配負載
- Blue: 采集集群信息
- Red: 日志存儲
容器編排環境使用的是Minikube,生成負載采用的工具是Hey Benchmark Tool,它是使用Go編寫的壓測工具,能夠并發大量請求,此外,它還包含所有所需的參數:
- 定義了請求執行的時長
- 定義了并行的workers數目
- 定義了worker發送的請求速率
為了在Minikube中生成負載,我們開發了一個node.js web應用,該應用會暴露一個REST,其會調用一個busy-wait 函數,使服務在一定毫秒時間段內的CPU-core的利用率達到100%,從下圖中可以看出,該函數接收一個服務時間,并在時間結束前讓CPU保持繁忙。

評估場景
考慮到垂直擴縮容至少需要一個監控的Pod,因此為了保持配置相似,需要為每個擴縮容策略配置2個初始Pods。此外,每個Pod初始request的CPU為0.15 CPU-cores,限制為1.5CPU-cores。
在所有評估的場景中,服務時間(endpoint處理一個請求的時間)為常數S = 0.175 秒。負載強度受發送的請求速率(λ)以及并發的客戶端(每秒發送一個請求)控制。實驗的每個場景分為9個階段,每個階段包含不同的負載,每個階段的執行時間為2分鐘,每種場景的總執行時間為18分鐘。
為了讓每個階段達到期望的CPU利用率,根據隊列理論的運算規律定義了請求速率。根據利用率規律,流量強度定義為ρ = λ ? S。例如,達到2 cores利用率(ρ = 2)的服務時間為S = 0.1, 此時每秒請求速率為λ = ρ / S = 2 / 0.1 = 20。但如果該請求速率超過40,那么等式不再平衡,因為此時的負載的確需要4個cores。[5]
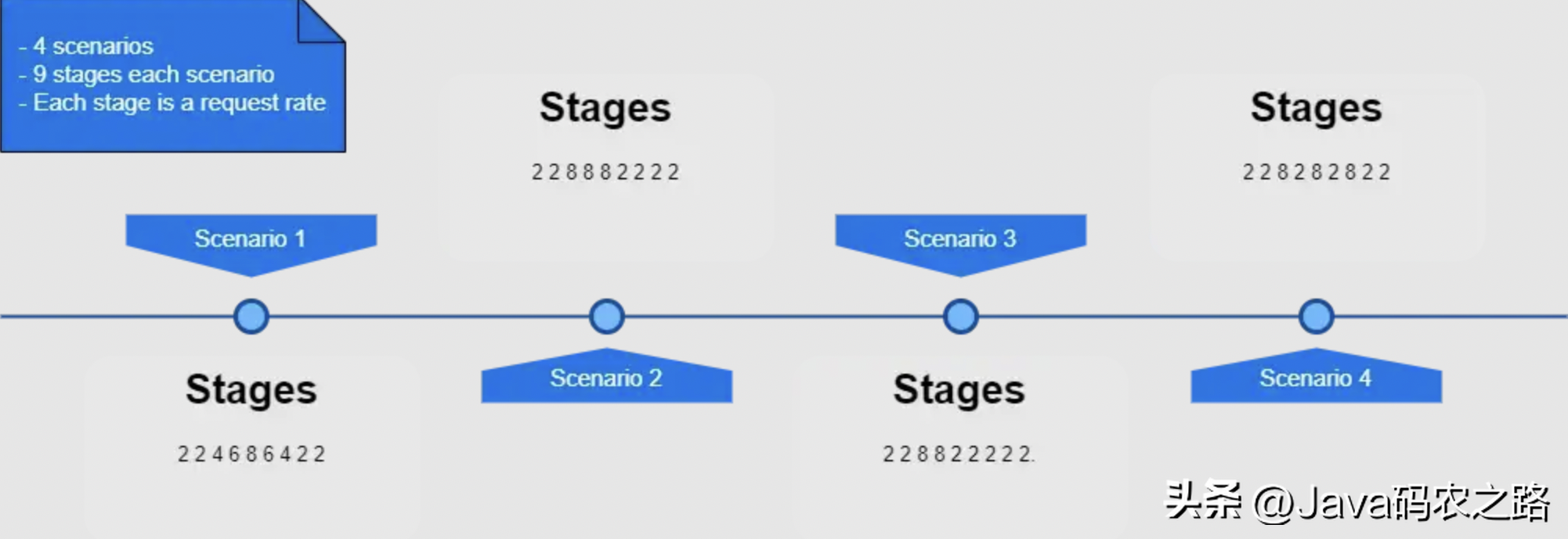
實驗的階段流程
如上圖所示,請求速率為λ = 2(需要ρ = 0.35 CPU-cores);λ = 4 (需要 ρ = 0.7 CPU-cores); λ = 6 (需要 ρ = 1.05 CPU-cores); 和 λ = 8 (需要 ρ = 1.4 CPU-cores),因此,這些情景假設綜合了以下幾點:
- 第一種場景中λ = [2, 2, 4, 6, 8, 6, 4, 2, 2],以一種非激進的方式逐步增加或減少負載
- 第二種場景中λ = [2, 2, 8, 8, 8, 2, 2, 2, 2],突然增加負載,并保持3個階段,然后在剩余的階段中降低降到最低值
- 第三種場景中λ = [2, 2, 8, 8, 2, 2, 2, 2, 2],與第二種類似,但高負載持續時間更少
- 第四種場景中λ = [2, 2, 8, 2, 8, 2, 8, 2, 2],使用多個峰值負載
當定義好這些場景之后,就可以使用腳本自動化執行。
在實驗執行過程中,Kubernetes API會提供評估所需的關鍵數據:1)CPU使用情況;2)autoscaler推薦值;3)Pod Request的CPU數。每10秒對這些數據進行一次檢索,并保存到日志文件中。因此,使用這些信息,可以判斷每個Pod request的CPU隨時間的變化情況。
同時,每次執行腳本生成負載(使用Hey工具)時,也會將應用的指標保存到日志文件中,為測試提供應用的行為數據。
結論
每種自動擴縮容策略下都會執行者四種實驗場景。每種方式的初始Pods數為2,每個Pod的CPU-core為0.15,并會隨時間被擴縮容器所修改。圖1和圖2展示了實驗過程中每個Pod的request CPU。虛線表示在負載的每個階段達到100% 利用率所需的 CPU 容量。
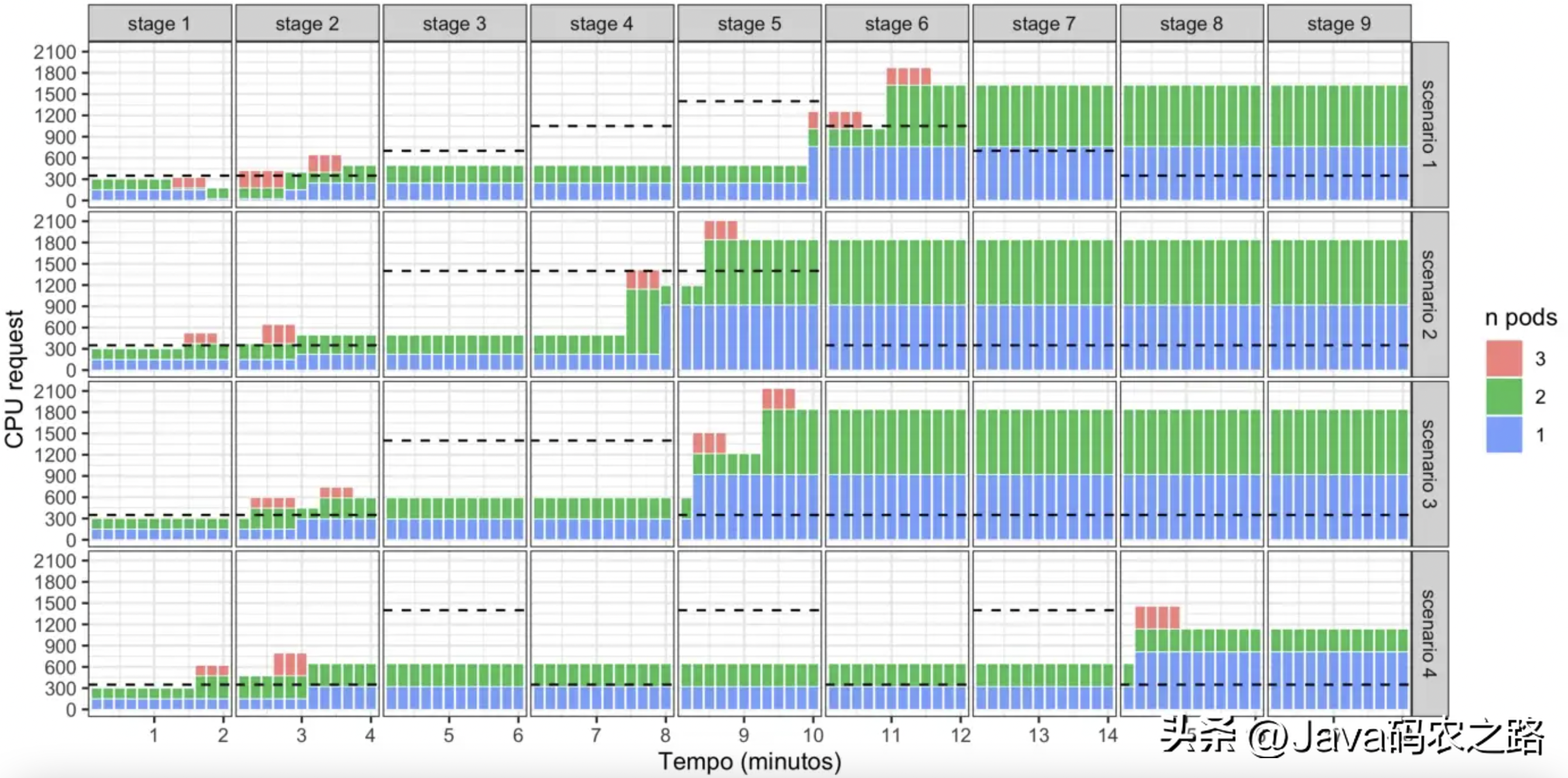
圖1:垂直擴縮容中每個Pod request的CPU
可以看到,在VPA中,重新分配資源是有延遲的,大部分時間停留在 CPU 容量低于所需的情況下(虛線下面的彩色條)。場景1的負載是逐步增加的,其自動擴縮容決策的延遲相對要大,而場景2、3的負載變化比較突然,其延遲也相對較低。場景4的負載峰值較短,只有在階段8才出現了資源的申請,此外還可以看到,在進行擴容時,VPA request的CPU要大于所需的CPU,在縮容時,VPA也更加保守。
此外,即使在最后5個低強度的負載的階段中,VPA也沒有進行縮容,此時申請的資源要大于所需的資源。這種延遲背后的原因是出于該機制的置信因子,它需要更多的時間來提升推薦的可信度。此外,在某些時候出現3個Pod的原因是,在調整Pod時,VPA會使用期望的資源容量來創建一個新的Pod,并在新的Pod就緒之后結束掉老的Pod。因此,置信因子可以多次減少重建 Pods 帶來的開銷。
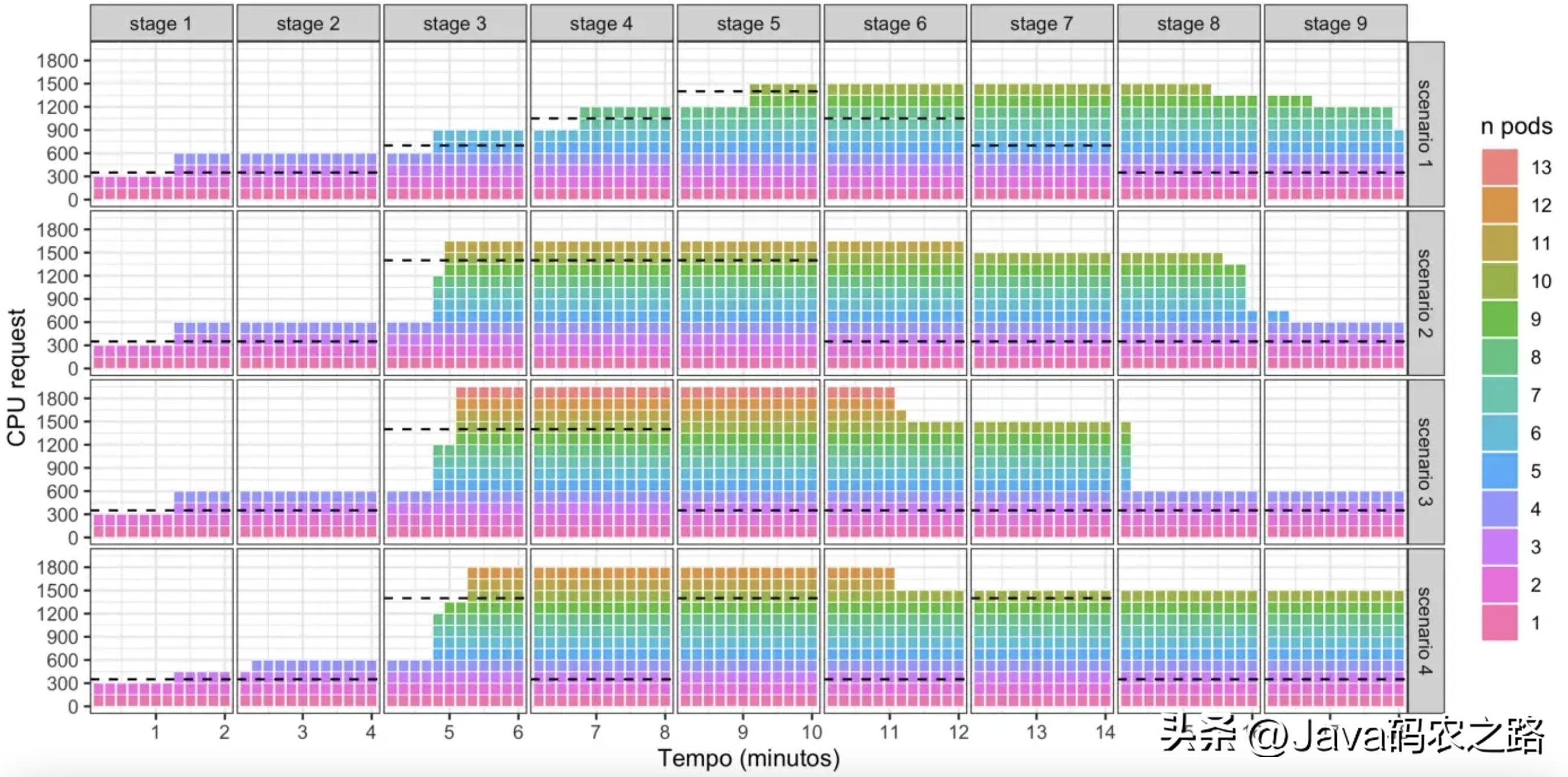
圖2:水平擴縮容中每個Pod request的CPU
大部分情況下,HPA都能對工作負載的變化作出有效的反應(盡管請求的 CPU 略高于所需的 CPU)。當負載上升時,其平均擴容決策時間為40秒。
只有在所有場景的第3階段,以及在場景1的第4和第5階段中,CPU停留在所需值以下的時間持續了大約1分鐘。
HPA能夠在5分鐘的延遲后進行縮容,而VPA則不會縮容。在場景4中,HPA超量request 了CPU資源,這對于處理短時間的峰值來說這是正向的,但長遠來看,有可能會給基礎設施成本帶來一定影響。
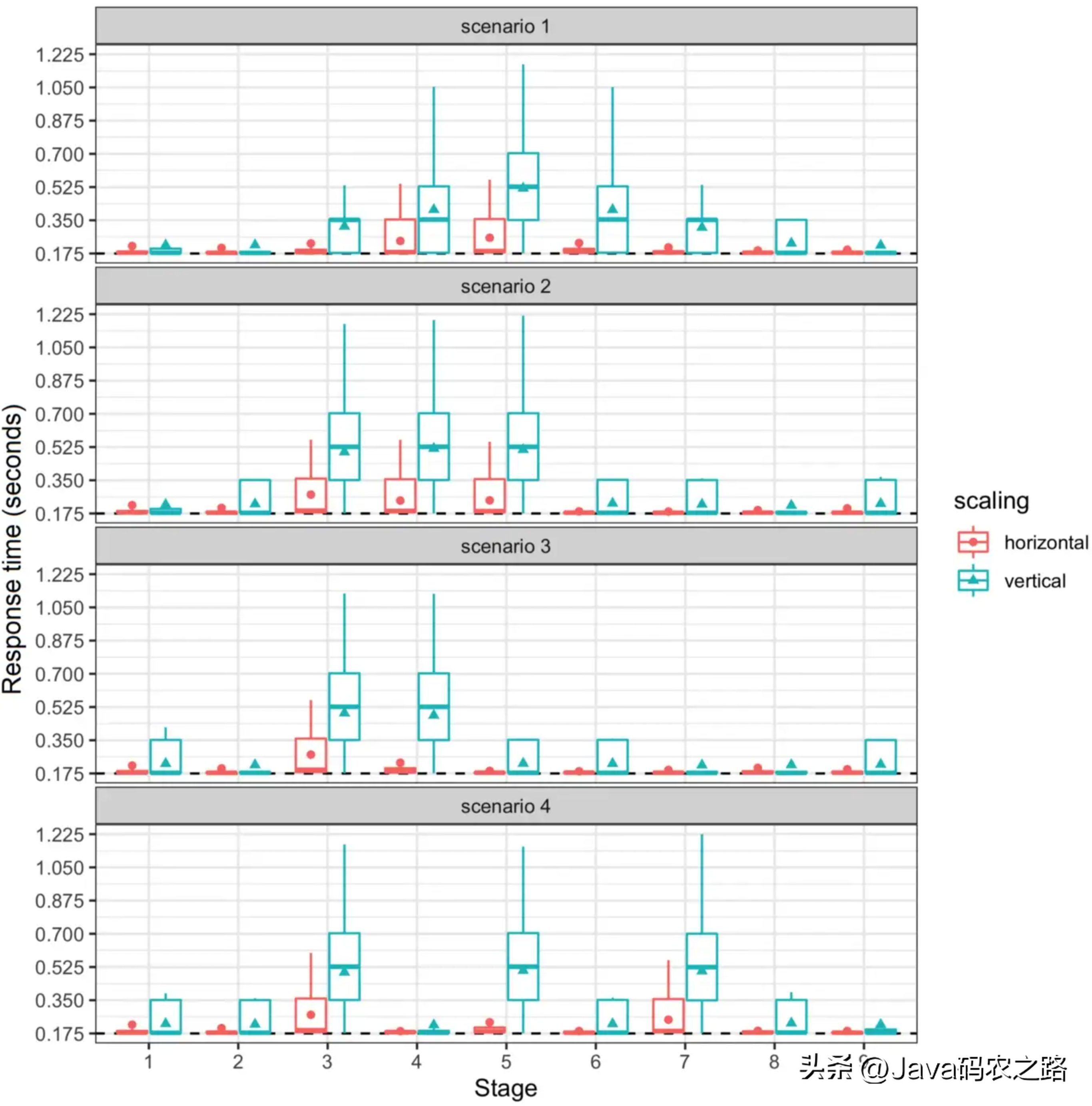
圖3:垂直和水平擴縮容下的應用響應時間
圖3展示比較了每個場景下的負載階段對 Web 應用程序所做請求的響應時間。每個框的中間線代表中間值,而點和三角形是每個階段響應時間的平均值。
在所有場景下下,水平自動擴縮容展示的響應時間非常接近于服務時間(0.175秒),在負載量增加的幾個階段中,只有平均值和第三四分位數略大。另一方面,在各種階段中,由于調整Pod存在延遲,垂直自動擴縮容展示的響應時間要遠大于服務時間(無論平均值和四分位數)。
可以這么說,在使用默認配置對這兩種自動擴縮容策略進行評估的過程中表明,HPA是更有效的,它可以更快響應負載的變化,并且有足夠數量的 Pods 來處理請求,而 VPA 受到了調整 Pods延遲的負面影響。
總結
本次工作通過測量實驗分析了Kubernetes中水平和垂直自動擴縮容的性能。為此,需要某種方式來生成負載并使用壓測工具控制負載,以及創建多個場景來分析自動擴縮容方式的行為,主要關注響應時間、Pods的CPU request指標,以及自動擴容時間時間的時間。
從本次的實驗中可以看到,水平自動擴縮容相對不保守,但對資源的調整也相對更高效。需要注意的是,這種精度是由水平pod自動擴縮容器算法的客觀性決定的,該算法將請求的資源保持在已定義的資源使用限制的平均值內。
相比之下,垂直自動擴縮容在資源申請決策上則更加保守,因為它依賴于隨時間增加置信因子的對數。可以得出,在較長時間的實驗中,可以生成更多的pod執行的歷史數據,垂直自動擴縮容將更有效地執行自動擴縮容決策。
在本次的實驗參數和場景下,水平自動擴縮容展現了更高的效率,其決策的精確性提供了資源的靈活性,以及更快的 Web 應用響應時間。需要注意的是,在本次時間結束之時,垂直自動擴縮容還處理beta階段,仍然會接受日常更新,因此未來有可能會在效率上有所提升。此外,本次實驗使用了Kubernetes的默認配置,因此修改參數可能會產生不同的結果。