













攻陷短視頻后,Sora將需要72萬(wàn)塊H100 GPU
OpenAI 推出的 Sora 模型能夠在各種場(chǎng)景下生成極其逼真的視頻,吸引了全世界的目光。
近日,投資機(jī)構(gòu) factorial funds 發(fā)表了一篇博文,深入探討了 Sora 背后的一些技術(shù)細(xì)節(jié),并對(duì)這些視頻模型可能產(chǎn)生影響進(jìn)行了探討。
最后,文中還討論了對(duì)用于訓(xùn)練 Sora 等模型的算力的看法,并對(duì)訓(xùn)練計(jì)算與推理計(jì)算的算力比較進(jìn)行了預(yù)測(cè),這對(duì)估計(jì)未來(lái) GPU 需求具有重要意義。機(jī)器之心對(duì)此文進(jìn)行了整理。
本報(bào)告的主要調(diào)查結(jié)果總結(jié)如下:
- Sora 是一個(gè)建立在擴(kuò)散 Transformers(DiT)、潛在擴(kuò)散模型之上的擴(kuò)散模型,模型和訓(xùn)練數(shù)據(jù)集似乎都更大更多。
- Sora 證明,擴(kuò)大視頻模型是有效的,與大語(yǔ)言模型(LLM)類(lèi)似,將模型做得更大將是快速改進(jìn)模型的主要驅(qū)動(dòng)力。
- Runway、Genmo 和 Pika 等公司正在圍繞類(lèi) Sora 視頻生成模型構(gòu)建直觀的界面和工作流程。這將決定它們的用途和可用性。
- Sora 需要大量的計(jì)算能力來(lái)訓(xùn)練,至少需要在 4200~10500 塊英偉達(dá) H100 GPU 上訓(xùn)練 1 個(gè)月。
- 推理階段,估計(jì)每個(gè) H100 GPU 每小時(shí)最多可以生成約 5 分鐘的視頻。與 LLM 相比,像 Sora 這樣基于擴(kuò)散的模型推理成本要高幾個(gè)數(shù)量級(jí)。
- 隨著類(lèi) Sora 模型的廣泛部署,推理計(jì)算消耗將多于訓(xùn)練計(jì)算消耗。「平衡點(diǎn)」估計(jì)為 1530 萬(wàn)至 3810 萬(wàn)分鐘的視頻生成,之后在推理上花費(fèi)的計(jì)算會(huì)比原始訓(xùn)練更多。作為參考,TikTok 每天上傳 1700 萬(wàn)分鐘的視頻,YouTube 每天上傳 4300 萬(wàn)分鐘的視頻。
- 假設(shè) TikTok(所有視頻時(shí)長(zhǎng)的 50%)和 YouTube(全部視頻時(shí)長(zhǎng)的 15%)等流行平臺(tái)上大量采用人工智能做視頻生成,考慮到硬件利用率和使用模式,本文估計(jì)推理階段的計(jì)算峰值需求約為 72 萬(wàn)塊 Nvidia H100 GPU。
總之,Sora 在視頻生成的質(zhì)量和能力方面取得了重大進(jìn)展,但也有可能大大增加對(duì) GPU 推理計(jì)算的需求。
Sora 的誕生背景
Sora 是一種擴(kuò)散模型。擴(kuò)散模型是圖像生成領(lǐng)域的熱門(mén)模型,著名的模型有 OpenAI 的 DALL?E 和 Stability AI 的 Stable Diffusion。最近,Runway、Genmo 和 Pika 等公司也在探索視頻生成,很可能也利用了擴(kuò)散模型。
從廣義上講,擴(kuò)散模型是一種生成式機(jī)器學(xué)習(xí)模型,它通過(guò)向數(shù)據(jù)中添加隨機(jī)噪聲來(lái)逐步反向?qū)W習(xí),最終學(xué)會(huì)創(chuàng)建與其所訓(xùn)練的數(shù)據(jù)(如圖像或視頻)相似的數(shù)據(jù)。這些模型從純粹的噪聲模式開(kāi)始,逐步去除噪聲,再完善模型,直至將其轉(zhuǎn)化為連貫而詳細(xì)的輸出。

擴(kuò)散過(guò)程示意圖:噪聲被逐步去除,直至輸出清晰可見(jiàn)詳細(xì)的視頻。圖片摘自 Sora 技術(shù)報(bào)告。
這與大語(yǔ)言模型(LLM)在概念上的工作方式明顯不同:LLM 會(huì)一個(gè)接一個(gè)地反復(fù)生成 token(這被稱(chēng)為自回歸采樣)。Token 一旦產(chǎn)生,就不會(huì)再改變。人們?cè)谑褂?Perplexity 或 ChatGPT 等工具時(shí),可能已經(jīng)見(jiàn)識(shí)過(guò)這種效果:答案會(huì)一個(gè)字一個(gè)字地逐漸出現(xiàn),就像有人在打字一樣。
Sora 的技術(shù)細(xì)節(jié)
OpenAI 在發(fā)布 Sora 的同時(shí),還發(fā)布了一份技術(shù)報(bào)告。遺憾的是,這份報(bào)告的細(xì)節(jié)不多。不過(guò),其設(shè)計(jì)似乎深受《Scalable Diffusion Models with Transformers》這篇研究論文的影響,該論文提出了一種基于 Transformer 的架構(gòu),稱(chēng)為 DiT(Diffusion Transformers 的縮寫(xiě)),用于圖像生成。Sora 似乎將這項(xiàng)工作擴(kuò)展到了視頻生成。因此,結(jié)合 Sora 技術(shù)報(bào)告和 DiT 論文,就可以相當(dāng)準(zhǔn)確地了解 Sora 模型的工作原理。
Sora 有三個(gè)重要部分:1)它不是在像素空間,而是在隱空間中執(zhí)行擴(kuò)散(又稱(chēng)潛在擴(kuò)散);2)它使用 Transformers 架構(gòu);3)它似乎使用了一個(gè)非常大的數(shù)據(jù)集。
潛在擴(kuò)散
要理解第一點(diǎn),即潛在擴(kuò)散,可以考慮生成一幅圖像,并使用擴(kuò)散生成每個(gè)像素。然而,這樣做的效率非常低(例如,一幅 512x512 的圖像有 262,144 個(gè)像素)。取而代之的方法是,首先將像素映射成具有一定壓縮系數(shù)的隱空間表征,在這個(gè)更緊湊的隱空間中執(zhí)行擴(kuò)散,最后再將隱空間表征解碼回像素空間。這種映射大大降低了計(jì)算復(fù)雜度:以 64 位的隱空間為例,只需生成 64x64=4,096 個(gè)表征,而不必在 512x512=262,144 個(gè)像素上運(yùn)行擴(kuò)散過(guò)程。這一想法是《High-Resolution Image Synthesis with Latent Diffusion Models》論文中的關(guān)鍵突破,也是穩(wěn)定擴(kuò)散技術(shù)的基礎(chǔ)。

從像素(左側(cè))到潛在表示(右側(cè)的方框網(wǎng)格)的映射。圖片摘自 Sora 技術(shù)報(bào)告。
DiT 和 Sora 都采用了這種方法。對(duì)于 Sora 來(lái)說(shuō),另一個(gè)考慮因素是視頻具有時(shí)間維度:視頻是圖像的時(shí)間序列,也稱(chēng)為幀。從 Sora 的技術(shù)報(bào)告中可以看出,從像素映射到隱空間的編碼步驟既發(fā)生在空間上(指壓縮每個(gè)幀的寬度和高度),也發(fā)生在時(shí)間上(指跨時(shí)間壓縮)。
Transformers
關(guān)于第二點(diǎn),DiT 和 Sora 都用普通的 Transformer 架構(gòu)取代了常用的 U-Net 架構(gòu)。這很重要,因?yàn)?DiT 論文的作者觀察到,使用 Transformer 能穩(wěn)定地?cái)U(kuò)大模型規(guī)模:隨著訓(xùn)練計(jì)算量的增加(訓(xùn)練模型的時(shí)間延長(zhǎng)或模型增大,或兩者兼而有之),性能也會(huì)隨之提高。Sora 的技術(shù)報(bào)告也指出了同樣的情況也適用于視頻,并提供了一個(gè)說(shuō)明。

關(guān)于模型質(zhì)量如何隨訓(xùn)練計(jì)算量的增加而提高的說(shuō)明:基本計(jì)算量、4 倍計(jì)算量和 32 倍計(jì)算量(從左到右)。視頻摘自 Sora 技術(shù)報(bào)告。
這種縮放自由度可以用所謂的縮放定律(scaling law)來(lái)量化,是一種重要的特性,以前在大語(yǔ)言模型(LLM)和其他模態(tài)的自回歸模型中都對(duì)其進(jìn)行過(guò)研究。應(yīng)用縮放以獲得更好模型的能力是 LLM 快速發(fā)展的主要推動(dòng)力之一。既然圖像和視頻生成也有同樣的特性,我們應(yīng)該期待同樣的縮放方法在這里也能發(fā)揮作用。
數(shù)據(jù)
訓(xùn)練像 Sora 這樣的模型所需的最后一個(gè)關(guān)鍵要素是標(biāo)注數(shù)據(jù),本文認(rèn)為這就是 Sora 的秘訣所在。要訓(xùn)練像 Sora 這樣的文本生成視頻模型,需要成對(duì)的視頻和文本描述。OpenAI 并沒(méi)有詳細(xì)介紹他們的數(shù)據(jù)集,但他們暗示數(shù)據(jù)集非常龐大:「我們從大語(yǔ)言模型中汲取靈感,這些模型通過(guò)在互聯(lián)網(wǎng)級(jí)規(guī)模的數(shù)據(jù)上進(jìn)行訓(xùn)練,獲得了通用能力」。OpenAI 還發(fā)布了一種用詳細(xì)文本標(biāo)簽注釋圖像的方法,該方法曾被用于收集 DALLE?3 數(shù)據(jù)集。其總體思路是在數(shù)據(jù)集的一個(gè)標(biāo)注子集上訓(xùn)練一個(gè)標(biāo)注模型,然后使用該標(biāo)注模型自動(dòng)標(biāo)注其余的數(shù)據(jù)集。Sora 的數(shù)據(jù)集似乎也采用了同樣的技術(shù)。
Sora 的影響分析
本文認(rèn)為 Sora 有幾個(gè)重要的影響,如下所示。
視頻模型開(kāi)始真正有用
Sora 生成的視頻質(zhì)量有一個(gè)明顯的提升,在細(xì)節(jié)和時(shí)間一致性方面都是如此(例如,該模型能夠正確處理物體在暫時(shí)被遮擋時(shí)的持續(xù)性,并能準(zhǔn)確生成水中的倒影)。本文認(rèn)為,現(xiàn)在的視頻質(zhì)量已經(jīng)足以應(yīng)對(duì)某些類(lèi)型的場(chǎng)景,可以在現(xiàn)實(shí)世界中應(yīng)用。Sora 可能很快就會(huì)取代部分視頻素材的使用。
視頻生成領(lǐng)域公司的市場(chǎng)分布圖。
但 Sora 還會(huì)面臨一些挑戰(zhàn):目前還不清楚 Sora 模型的可操控性。編輯生成的視頻既困難又耗時(shí),因?yàn)槟P洼敵龅氖窍袼亍4送猓瑖@這些模型建立直觀的用戶(hù)界面和工作流程也是使其發(fā)揮作用的必要條件。Runway、Genmo 和 Pika 等公司以及更多公司(見(jiàn)上面的市場(chǎng)圖)已經(jīng)在著手解決這些問(wèn)題。
模型縮放對(duì)視頻模型有效,可以期待進(jìn)一步的進(jìn)展
DiT 論文的一個(gè)重要觀點(diǎn)是,如上所述,模型質(zhì)量會(huì)隨著計(jì)算量的增加而直接提高。這與已觀察到的 LLM 的規(guī)律相似。因此,隨著視頻生成模型使用越來(lái)越多的計(jì)算能力進(jìn)行訓(xùn)練,我們應(yīng)該期待這類(lèi)模型的質(zhì)量能快速提高。Sora 清楚地證明了這一方法確實(shí)有效,我們期待 OpenAI 和其他公司在這方面加倍努力。
數(shù)據(jù)生成與數(shù)據(jù)增強(qiáng)
在機(jī)器人和自動(dòng)駕駛汽車(chē)等領(lǐng)域,數(shù)據(jù)本來(lái)就稀缺:網(wǎng)上沒(méi)有機(jī)器人執(zhí)行任務(wù)或汽車(chē)行駛的實(shí)時(shí)數(shù)據(jù)。因此,解決這些問(wèn)題的方法通常是進(jìn)行模擬訓(xùn)練或在現(xiàn)實(shí)世界中大規(guī)模收集數(shù)據(jù)(或兩者結(jié)合)。然而,由于模擬數(shù)據(jù)往往不夠真實(shí),這兩種方法都難以奏效。大規(guī)模收集真實(shí)世界的數(shù)據(jù)成本高昂,而且要為罕見(jiàn)事件收集足夠多的數(shù)據(jù)也具有挑戰(zhàn)性。

通過(guò)修改視頻的某些屬性對(duì)其進(jìn)行增強(qiáng)的示例,在本例中,將原始視頻(左)渲染為郁郁蔥蔥的叢林環(huán)境(右)。圖片摘自 Sora 技術(shù)報(bào)告。
本文認(rèn)為,類(lèi)似 Sora 的模型在這方面會(huì)非常有用。類(lèi)似 Sora 的模型有可能直接用于生成合成數(shù)據(jù)。Sora 還可用于數(shù)據(jù)增強(qiáng),將現(xiàn)有視頻轉(zhuǎn)換成不同的外觀。上圖展示了數(shù)據(jù)增強(qiáng)的效果,Sora 可以將行駛在森林道路上的紅色汽車(chē)視頻轉(zhuǎn)換成郁郁蔥蔥的叢林景色。使用同樣的技術(shù)可以重新渲染白天與夜晚的場(chǎng)景,或者改變天氣條件。
仿真和世界模型
一個(gè)前瞻的研究方向是學(xué)習(xí)所謂的世界模型。如果這些世界模型足夠精確,就可以直接在其中訓(xùn)練機(jī)器人,或者用于規(guī)劃和搜索。
像 Sora 這樣的模型似乎是直接從視頻數(shù)據(jù)中隱式地學(xué)習(xí)真實(shí)世界運(yùn)作的基本模擬。這種「涌現(xiàn)模擬機(jī)制」目前還存在缺陷,但卻令人興奮:它表明,我們或許可以通過(guò)視頻大規(guī)模地訓(xùn)練這些世界模型。此外,Sora 似乎還能模擬非常復(fù)雜的場(chǎng)景,如液體、光的反射、織物和頭發(fā)的運(yùn)動(dòng)。OpenAI 甚至將他們的技術(shù)報(bào)告命名為「作為世界模擬器的視頻生成模型」,這表明他們認(rèn)為這是他們模型最重要的價(jià)值。
最近,DeepMind 公司的 Genie 模型也展示了類(lèi)似的效果: 通過(guò)只在游戲視頻上進(jìn)行訓(xùn)練,該模型學(xué)會(huì)了模擬這些游戲(并制作了新的游戲)。在這種情況下,模型甚至可以在不直接觀察動(dòng)作的情況下學(xué)會(huì)對(duì)動(dòng)作進(jìn)行判斷。同樣,在這些模擬中直接進(jìn)行學(xué)習(xí)也是可以期待的。

谷歌 DeepMind 的「Genie:生成式交互環(huán)境」介紹視頻。
綜合來(lái)看,本文認(rèn)為 Sora 和 Genie 這樣的模型可能會(huì)非常有用,有助于最終在真實(shí)世界的任務(wù)中大規(guī)模地訓(xùn)練具身智能體(例如機(jī)器人)。不過(guò),這些模型也有局限性:由于模型是在像素空間中訓(xùn)練的,因此它們會(huì)對(duì)每一個(gè)細(xì)節(jié)進(jìn)行建模,比如風(fēng)如何吹動(dòng)草葉,即使這與手頭的任務(wù)完全無(wú)關(guān)。雖然隱空間被壓縮了,但由于需要能夠映射回像素,因此隱空間仍需保留大量此類(lèi)信息,因此目前還不清楚能否在隱空間中有效地進(jìn)行規(guī)劃。
Sora 的計(jì)算量估算
Factorial Funds 公司內(nèi)部喜歡評(píng)估模型在訓(xùn)練和推理階段分別使用了多少計(jì)算量。這很有用,因?yàn)檫@樣可以為預(yù)測(cè)未來(lái)需要多少計(jì)算量提供依據(jù)。不過(guò),要估算出這些數(shù)據(jù)也很困難,因?yàn)橛嘘P(guān)用于訓(xùn)練 Sora 的模型大小和數(shù)據(jù)集的詳細(xì)信息非常少。因此,需要注意的是,本節(jié)中的估算結(jié)果具有很大的不確定性,因此應(yīng)謹(jǐn)慎對(duì)待。
根據(jù) DiT 估算 Sora 的訓(xùn)練計(jì)算量
關(guān)于 Sora 的詳細(xì)資料非常少,通過(guò)再次查看 DiT 論文(這篇論文顯然是 Sora 的基礎(chǔ)),也可以根據(jù)其中提供的計(jì)算數(shù)字進(jìn)行推斷。最大的 DiT 模型 DiT-XL 有 675M 個(gè)參數(shù),訓(xùn)練時(shí)的總計(jì)算預(yù)算約為 10^21 FLOPS。這相當(dāng)于約 0.4 臺(tái) Nvidia H100 使用 1 個(gè)月(或一臺(tái) H100 使用 12 天)。
現(xiàn)在,DiT 只是圖像模型,而 Sora 是視頻模型。Sora 可以生成長(zhǎng)達(dá) 1 分鐘的視頻。如果我們假設(shè)視頻是以 24fps 的速度編碼的,那么一段視頻最多由 1,440 幀組成。Sora 的像素到潛在空間映射似乎在空間和時(shí)間上都進(jìn)行了壓縮。如果假定采用 DiT 論文中相同的壓縮率(8 倍),那么在潛空間中將有 180 幀。因此,當(dāng)簡(jiǎn)單地將 DiT 推廣到視頻時(shí),得到的計(jì)算倍率是 DiT 的 180 倍。
本文還認(rèn)為,Sora 的參數(shù)要比 675M 大得多。本文作者估計(jì)至少得有 20B 的參數(shù),所需計(jì)算量是 DiT 的 30 倍。
最后,本文認(rèn)為 Sora 的訓(xùn)練數(shù)據(jù)集比 DiT 大得多。DiT 在 batch 大小為 256 的情況下進(jìn)行了三百萬(wàn)次訓(xùn)練,即在總計(jì) 7.68 億張圖片上進(jìn)行了訓(xùn)練(請(qǐng)注意,由于 ImageNet 僅包含 1,400 萬(wàn)張圖片,因此相同的數(shù)據(jù)被重復(fù)了很多次)。Sora 似乎是在混合圖像和視頻的基礎(chǔ)上進(jìn)行訓(xùn)練的,除此之外,我們對(duì)該數(shù)據(jù)集幾乎一無(wú)所知。因此,本文做了一個(gè)簡(jiǎn)單的假設(shè),即 Sora 的數(shù)據(jù)集 50% 是靜態(tài)圖像,50% 是視頻,而且數(shù)據(jù)集是 DiT 使用的數(shù)據(jù)集的 10 倍到 100 倍。然而,DiT 在相同的數(shù)據(jù)點(diǎn)上反復(fù)訓(xùn)練,如果有更大的數(shù)據(jù)集,可能性能還會(huì)更好。因此,本文認(rèn)為 4-10 倍的計(jì)算倍率的假設(shè)是更合理的。
綜上所述,考慮到額外數(shù)據(jù)集計(jì)算的低倍估算值和高倍估算值,本文得出以下計(jì)算結(jié)果:
- 低倍數(shù)據(jù)集估計(jì)值:10^21 FLOPS × 30 × 4 × (180 / 2) ≈ 1.1x10^25 FLOPS
- 高倍數(shù)據(jù)集估計(jì)值:10^21 FLOPS × 30 × 10 × (180 / 2) ≈ 2.7x10^25 FLOPS
這相當(dāng)于使用 1 個(gè)月的 4,211 - 10,528 臺(tái) Nvidia H100 進(jìn)行訓(xùn)練。
推理與訓(xùn)練計(jì)算的比較
我們往往會(huì)考慮的另一個(gè)重要因素是訓(xùn)練計(jì)算與推理計(jì)算的比較。從概念上講,訓(xùn)練計(jì)算量非常大,但也是一次性成本,只產(chǎn)生一次。相比之下,推理計(jì)算量要小得多,但每次使用都會(huì)產(chǎn)生。因此,推理計(jì)算會(huì)隨著用戶(hù)數(shù)量的增加而增加,并且隨著模型的廣泛使用而變得越來(lái)越重要。
因此,研究「平衡點(diǎn)」是非常有用的,即推理所耗費(fèi)的計(jì)算量大于訓(xùn)練所耗費(fèi)的計(jì)算量。
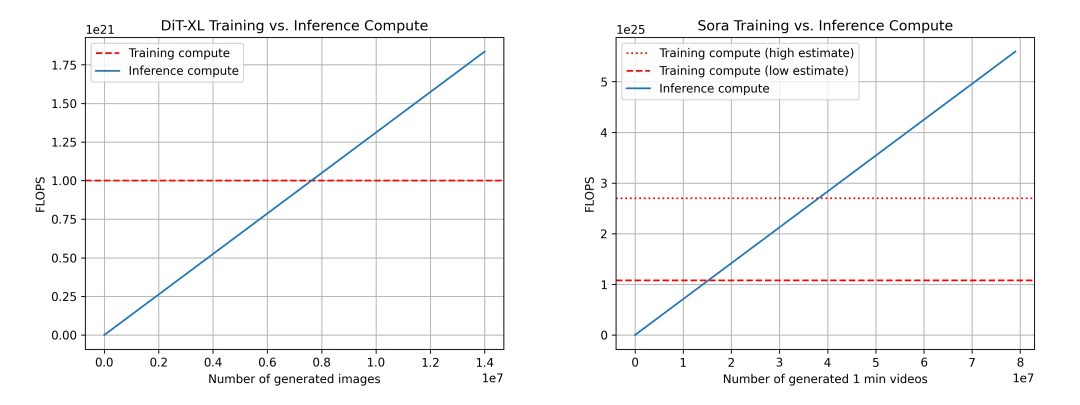
DiT (左)和 Sora (右)的訓(xùn)練與推理計(jì)算結(jié)果對(duì)比。對(duì)于 Sora,本文的數(shù)據(jù)基于上一節(jié)的估計(jì),因此并不完全可靠。這里還顯示了訓(xùn)練計(jì)算的兩種估計(jì)值:一種是低估計(jì)值(假設(shè)數(shù)據(jù)集大小為 4 倍乘數(shù)),另一種是高估計(jì)值(假設(shè)數(shù)據(jù)集大小為 10 倍乘數(shù))。
本文再次使用了 DiT 來(lái)推斷 Sora。對(duì)于 DiT,最大的模型(DiT-XL)每步使用 524×10^9 FLOPS,DiT 使用 250 個(gè)擴(kuò)散步驟生成單幅圖像,總計(jì) 131×10^12 FLOPS。我們可以看到,在生成 760 萬(wàn)張圖像后達(dá)到了平衡點(diǎn),之后推理計(jì)算占據(jù)了主導(dǎo)地位。作為參考,用戶(hù)每天在 Instagram 上傳大約 9500 萬(wàn)張圖片(數(shù)據(jù)來(lái)源)。
對(duì)于 Sora,本文推斷 FLOPS 約為:524×10^9 FLOPS × 30 × 180 ≈ 2.8×10^15 FLOPS.。如果仍然假設(shè)每段視頻經(jīng)歷 250 次擴(kuò)散步驟,那么每段視頻的 FLOPS 總量就是 708×10^15。在生成 1530 萬(wàn)至 3810 萬(wàn)分鐘的視頻后,就會(huì)達(dá)到平衡點(diǎn),此時(shí)所花費(fèi)的推理計(jì)算量將超過(guò)訓(xùn)練計(jì)算量。作為參考,每天約有 4,300 萬(wàn)分鐘的視頻上傳到 YouTube。
需要注意的是,對(duì)于推理而言,F(xiàn)LOPS 并不是唯一重要的因素。例如,內(nèi)存帶寬是另一個(gè)重要因素。此外,關(guān)于如何減少擴(kuò)散步驟的數(shù)量的研究,可能會(huì)大大降低計(jì)算密集度,從而加快推理速度。FLOPS 利用率在訓(xùn)練和推理之間也會(huì)有所不同,在這種情況下,也需要考慮。
不同模型的推理計(jì)算比較
本文還對(duì)不同模型在不同模式下每單位輸出的推理計(jì)算量是如何表現(xiàn)的進(jìn)行了研究。這樣做的目的是為了了解不同類(lèi)別模型的推理計(jì)算密集程度,這對(duì)計(jì)算規(guī)劃和需求有直接影響。需要強(qiáng)調(diào)的是,每個(gè)模型的輸出單位都會(huì)發(fā)生變化,因?yàn)樗鼈兪窃诓煌哪J较逻\(yùn)行的:對(duì)于 Sora,單次輸出是一段 1 分鐘長(zhǎng)的視頻;對(duì)于 DiT,單次輸出是一張 512x512px 的圖片;而對(duì)于 Llama 2 和 GPT-4,單個(gè)輸出被定義為包含 1,000 個(gè) token 的文本的單個(gè)文檔。
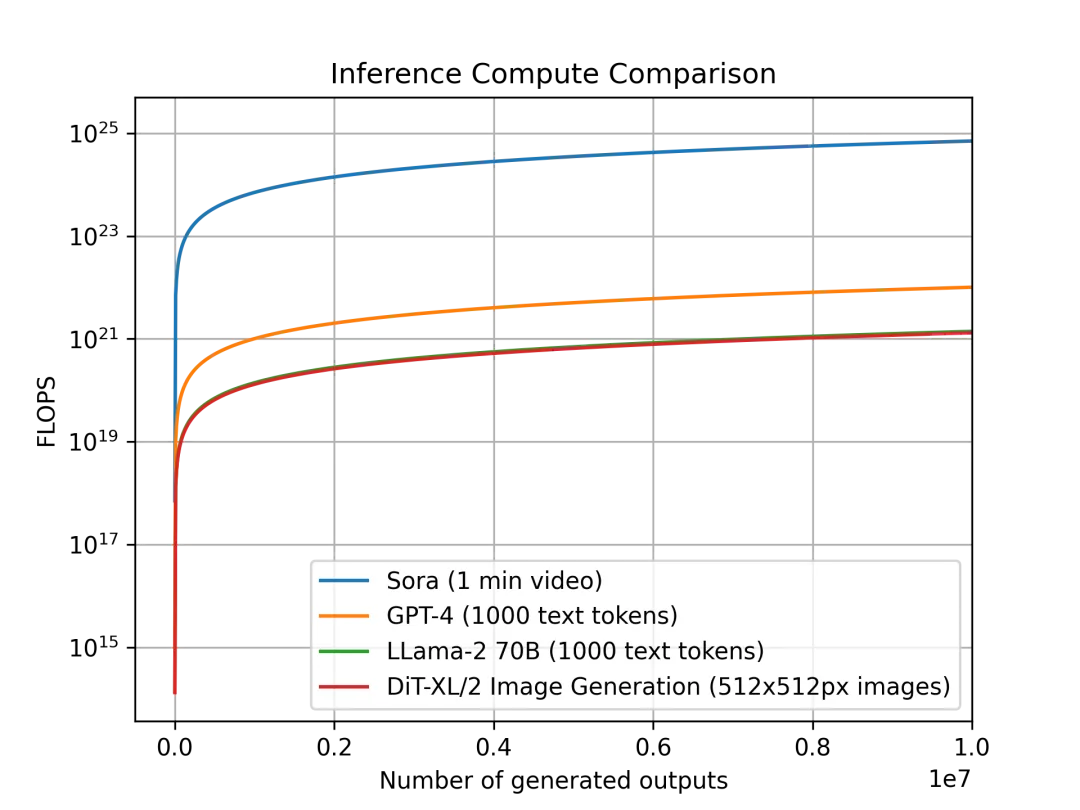
各模型每單位輸出的推理計(jì)算量比較(Sora 為 1 分鐘視頻,GPT-4 和 LLama 為 21000 個(gè)文本 token,DiT 為一張 512x512px 的圖片)。可以看到,本文估計(jì) Sora 的推理計(jì)算成本要高出幾個(gè)數(shù)量級(jí)。
本文比較了 Sora、DiT-XL、LLama 2 70B 和 GPT-4,并繪制了它們之間的對(duì)比圖(使用 FLOPS 的對(duì)數(shù)標(biāo)度)。對(duì)于 Sora 和 DiT,本文使用了上文的推理估計(jì)值。對(duì)于 Llama 2 和 GPT-4,本文使用「FLOPS = 2 × 參數(shù)數(shù)量 × 生成的 token 數(shù)」這一經(jīng)驗(yàn)公式估算 FLOPS 數(shù)。對(duì)于 GPT-4,本文假設(shè)該模型是一個(gè)專(zhuān)家混合(MoE)模型,每個(gè)專(zhuān)家有 220B 個(gè)參數(shù),每個(gè)前向傳遞中有 2 個(gè)專(zhuān)家處于活動(dòng)狀態(tài)。不過(guò)對(duì)于 GPT-4,這些數(shù)字并未得到 OpenAI 的確認(rèn),因此仍需謹(jǐn)慎對(duì)待。
可以看到,像 DiT 和 Sora 這樣基于擴(kuò)散的模型的推理成本要高得多:DiT-XL(一個(gè)擁有 675M 參數(shù)的模型)與 LLama 2(一個(gè)擁有 70B 參數(shù)的模型)消耗的推理計(jì)算量大致相同。我們還可以看到,在推理工作負(fù)載方面,Sora 甚至比 GPT-4 更昂貴。
需要再次指出的是,上述許多數(shù)據(jù)都是估算值,依賴(lài)于簡(jiǎn)化的假設(shè),沒(méi)有考慮到 GPU 的實(shí)際 FLOPS 利用率、內(nèi)存容量和內(nèi)存帶寬的限制以及推測(cè)解碼等高級(jí)技術(shù)。
類(lèi) sora 模型獲得顯著的市場(chǎng)份額之后所需的推理計(jì)算量
本節(jié)根據(jù) Sora 的計(jì)算需求推斷出了需要多少臺(tái) Nvidia H100 才能大規(guī)模運(yùn)行類(lèi)似 Sora 的模型,這意味著人工智能生成的視頻已經(jīng)在 TikTok 和 YouTube 等流行視頻平臺(tái)上實(shí)現(xiàn)顯著的市場(chǎng)滲透。
- 假設(shè)每臺(tái) Nvidia H100 每小時(shí)制作 5 分鐘視頻(詳見(jiàn)上文),換言之每臺(tái) H100 每天制作 120 分鐘視頻。
- TikTok :假設(shè)人工智能的滲透率為 50%,則每天的視頻時(shí)長(zhǎng)為 1700 萬(wàn)分鐘(視頻總數(shù)為 3400 萬(wàn) × 平均時(shí)長(zhǎng)為 30s)
- YouTube :每天 4300 萬(wàn)分鐘視頻,假設(shè)人工智能的滲透率為 15%(大部分為 2 分鐘以下的視頻)
- 人工智能每天制作的視頻總量:850 萬(wàn) + 650 萬(wàn) = 1 070 萬(wàn)分鐘
- 支持 TikTok 和 YouTube 上的創(chuàng)作者社區(qū)所需的 Nvidia H100 總量:1,070 萬(wàn) / 120 ≈ 89000
再基于以下各種因素考慮,這一數(shù)字可能有些保守:
- 假設(shè) FLOPS 的利用率為 100%,并且沒(méi)有考慮內(nèi)存和通信瓶頸。實(shí)際上,50% 的利用率更符合實(shí)際情況,即增加 1 倍。
- 需求在時(shí)間上不是平均分布的,而是突發(fā)的。高峰需求尤其成問(wèn)題,因?yàn)槟阈枰嗟?GPU 才能滿足所有流量的需求。本文認(rèn)為,高峰需求會(huì)使所需 GPU 的最大數(shù)量再增加 1 倍。
- 創(chuàng)作者可能會(huì)生成多個(gè)候選視頻,然后從這些候選視頻中選出最佳視頻。我們做了一個(gè)保守的假設(shè),即平均每個(gè)上傳的視頻會(huì)生成 2 個(gè)候選視頻,這又增加了 1 倍。
- 在峰值時(shí),總共需要大約 720000 塊 Nvidia H100 GPU
這表明,隨著生成式人工智能模型變得越來(lái)越流行且實(shí)用,推理計(jì)算將占主導(dǎo)地位。對(duì)于像 Sora 這樣的基于擴(kuò)散的模型,更是如此。
還需要注意的是,擴(kuò)展模型將進(jìn)一步大大增加推理計(jì)算的需求。另一方面,其中一些問(wèn)題可以通過(guò)更優(yōu)化的推理技術(shù)和跨堆棧的其他優(yōu)化方法來(lái)解決。

視頻內(nèi)容的創(chuàng)意驅(qū)動(dòng)了對(duì) OpenAI 的 Sora 等模型最直接的需求。





























