遵循這些MySQL設計規范,再也沒被組長噴過
故事
會議室里,小貓撓著頭,心里暗暗叫苦著“哎,這代碼都擼完了呀,改起來成本也太大了。”
原來就在剛才,組長找到了小貓,說代碼review過程中發現有些數據表模型設計得不合理,要求小貓改掉。小貓大概是設計了一個配置表,為了省事兒,小貓直接把相關的配置設計成了text類型的存儲形式。
關于這種業務場景下使用text文本類型存儲,組長指出了以下缺點:
- 在內存中處理Text字段時,由于需要處理大量數據,可能會導致內存使用過度,影響數據庫性能。
- Text字段無法創建索引,這會導致數據庫在執行查詢時無法利用索引來加速搜索。雖然可以通過全文索引來改善搜索性能,但是卻會有諸多限制,例如只能用于InnoDB引擎,并且索引只能建立在不超過1000字節的前綴上。
- 目前剛設計的時候就用text類型,后期隨著數據量的增長以及業務需求的變化,可能就意味著要將text類型繼續擴大變成,LongText或MediumText類型,這樣的轉換既費時又可能需要額外的存儲空間。
“組長說的也有道理,但是為什么現在才指出來,當時方案模型評審的時候咋提呢,哎,醉了醉了,現在業務邏輯都按照現有方案開發完了,才提出來.....”
“改?要重寫邏輯,不改?萬一今后真的出現上面組長說的這些問題,不得被噴死......”
彷徨過后,小貓終于下定了決心,改了吧,長痛不如短痛...反正如果不改的話,受罪的還是自己。于是加班是少不了了......
數據庫設計
在需求評審完畢之后,一般就是我們的技術方案的設計,在技術方案設計過程中,數據庫模型設計是一個非常重要的環節。數據庫模型的設計往往會影響后續業務邏輯的拓展或者直接影響著研發實際寫代碼的工作量。甚至會影響幾代研發的維護成本。因此物理數據庫的設計應該是一個非常謹慎以及嚴苛的過程,我們需要步步為營。
那么我們又當如何去進行數據庫的設計呢?接下來,老貓從我們日常開發中用到比較多的mysql數據庫的設計規范說起。如下。
 概要
概要
表設計
關于表設計,咱們從以下幾個方面來看。
1、 表的命名:表命名非常重要,我們要盡量去做到見名知意。
2、 根據實際場景確定引擎,咱們一般業務都會涉及到事務、行級鎖等功能,所以日常開發中包括設計中咱們還是以InnoDB引擎為準。
表設計-命名規范
1、在給相關的表進行命名的時候,表名建議還是以小寫英文字母和0-9數字組成(如果不涉及分表等業務場景,其實很少表名中會帶有數字)以及下劃線組成。雖然mysql在windows下表名不區分大小寫,但是在linux下是區分大小寫的,因此表名最好為小寫。
2、命名需要分類區分對待,當然英文單詞的命名建議使用名詞而不是動詞,另外的話詞義應該要與業務、產品線想關聯。例如我們命名一些配置類表的時候習慣以config打頭,例如config_XXX。當命名臨時表的時候一般tmp打頭,一般為tmp_XXX,當備份表的時候那么就是bak_XXX。
3、 表命名咱們要用英文,而不是拼音或者是拼音和英文混合。記得大學剛出來的時候,那時候老貓也用拼音命名過一些表,例如設計圖書管理系統的時候居然用上了shu_jia(書架)。現在想想好搓。雖然用到英文,上面提到用名詞,那咱們在用名詞的時候其實最好也是使用單數形式而非復數。例如員工表設計的時候,我們設計成employee而不是employees。
4、 上述還提及表名中包含數字,其實很多時候在我們分庫分表的時候會用到。這里提及幾個散表命名方式。首先是hash取模散表,咱們表名后綴使用16進制數,下標從0開始,或者咱們用md5進行散表那么基友user_0,user_ff等等。當然如果用到時間散表,咱們按照年月分表的時候,咱們會命名成user_202404等諸如此類。
表設計-設計規范
1、表設計的時候一般使用Innodb引擎。當然Mysql存在兩種可選引擎還有一種是MyISAM。MyISAM速度快,但是不支持事務、外鍵以及行級鎖。反觀Innodb速度稍遜一籌,但是可以支持事務、外鍵(雖然微服務的場景下,外鍵很少用了)、行級鎖等高級功能。
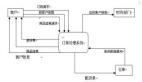
2、必須定義主鍵。說到主鍵,咱一般都是Id自增主鍵。有的時候咱們可能也會用到uuid或者Md5或者hash等字符串作為主鍵,但是這些列并不能保證數據的順序增長。這里還是要和大家聊聊這兩種主鍵的優缺點。方便大家后續在做表設計的時候進行取舍。老貓總結了一下,如下圖:
 主鍵對比
主鍵對比
3、表設計必須包含創建時間以及修改時間,用于記錄創建時間和修改時間。
4、表設計的時候不要使用外鍵,外鍵影響高并發下的性能,另外的目前我們的大型項目中會涉及到分庫分表,如果遇到外鍵的話,咱們的分庫分表將會難以實施。
5、慎用觸發器和存儲過程。當然現在咱們應該很少會用到了,老貓只有當年在學習的時候用到了存儲過程,后面實際工作的時候好像就再也沒有接觸過了。觸發器和存儲過程雖然可以減少開發量,另外封裝性也好,比較安全并且不存在SQL注入問題。但是其本身可移植性是非常差的,另外的話占用服務器的資源也比較多,一旦發生錯誤,咱們排查問題也比較困難。互聯網領域,我們現在更愿意把業務邏輯放到代碼側,變更會容易一些。
6、不要在建表的時候進行預留字段,預留字段命名很難做到見名知意,另外的話及時今后用到,在數據量大的情況下,如果類型不滿足需求,我們去變更類型的時候會導致鎖表。
7、單條記錄的大小不要超過8kb。那么這又是為什么呢?首先,咱們從索引角度來看,innodb的頁塊大小默認為16kb,由于innodb采用聚簇索引(B+樹結構)存放數據,每個頁塊中至少有兩行數據,否則就失去了B+樹的意義(如果每個頁中只有一條數據,整個樹就成了一條雙向鏈表)。由于每個頁塊中至少有兩行數據,可以得出一行數據的大小限制為8kb。其次,從硬盤扇區大小的角度來看,單條記錄的大小一般不應該超過硬盤的扇區大小,目前硬盤的扇區大小多為4kb(只有少數是16kb),如果單條記錄過大的話,查找的時候就會跨越多個扇區,增加尋道時間,可能導致性能下降。
8、單表在設計過程中,咱們最好不要超過50個int字段、20個char字段、2個text字段,另外的話單表列數也要盡量少于50,單表數量咱們也要盡量控制在500w一下,2Gb以內。如果過大的情況下,修改表結構、備份、恢復就有影響,所以當出現太大表的時候,咱們還是盡量要去分庫分表。
字段設計
字段設計主要涵蓋兩個方面,一個是字段的命名,另外一個是字段的數據類型。咱們接下來詳細看一下。
字段設計-命名規范
1、和表設計的時候一樣,咱們在字段命名的過程中也盡量不要使用拼音。
2、在設計字段的時候,咱們要避免數據庫關鍵字,比如name、time、datetime、desc等等。如果真要用到name的時候,咱們最好加上其他元素以及下劃線進行組成,例如user_name、biz_name等等。
3、字段表示枚舉、狀態類型表示是或者否的時候,咱們最好用is打頭,例如is_member,類型用unsigned tinyint(1-是 0-否) default 0。
字段設計-設計規范
1、當我們預知當前字段比較重要,或者之后查詢的時候用到比較多的時候,我們肯定要加上索引,那么這種字段,咱們在進行設計的時候就必須定義成Not null,并且設置default值。例如name為非空的,那么我們的定義可能是name not null default '' comment "命名"。
2、如果字段涉及小數存儲的時候,我們的字段類型最好使用bigdecimal類型,而不是float或者是double,float以及double都會存在精度丟失的問題。當然有較真的小伙伴也會說bigdecimal也是有范圍的,那么如果超過范圍的話,應該怎么辦?那么這個時候,其實我們可以將其分開進行存儲,整數和小數拆開。
3、避免使用text或者blob類型存儲大圖片文件等信息,這種信息建議直接存儲到文件系統,數據庫里面可以直接存儲對應的文件系統鏈接即可。
4、字符串類型的,咱們一般使用varchar類型,如果說存儲的字符串差不多都是等長的,那么我們可以將字段設計成char定長字符串類型。另外的,varhcar類型在進行設計的時候咱們要避免設計過長,因為varchar類型在存儲層面是根據實際長度存儲的,但是內存分配卻是根據指定長度進行的。所以如果字段設計不合理會導致內存不合理占用。
5、進行時間設計的時候,如果確定只要年月日,那么咱們就將字段設計成date類型。如果說要用到時間戳的話,那么我們要用到datetime以及timestamp。但是我們要注意這兩者的區別。關于這兩者的區別,老貓再此不做展開,大家有興趣的可以自己查一下。
6、當多個表中都關聯一個字段的時候,咱們應該要保證這兩個字段的類型一致,以免在寫代碼的時候帶來不必要的轉換麻煩。例如tenant_id這個字段在A表中我們設計成int類型在另外一個地方又設計成了bigint,那么我們對應的代碼中可能一個就是int類型另外一個地方就是Long類型。這樣在實際編碼的過程中就要去轉換。
索引設計
聊到索引相信大家都不陌生,索引一般以索引文件的形式存儲在磁盤上。我們一般所說的索引指的就是B+樹結構組織的索引。
接下來咱們簡單聊一下不同層面的索引的劃分,然后再來聊索引相關的設計規范。
索引的分類
根據存儲類型劃分
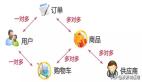
聚集索引:在數據庫表中物理順序和主鍵順序一致,即數據行按照主鍵的順序存儲。只要找到第一個索引值記錄,其余的連續記錄在物理層存儲層面一樣是連續存放。為了使得表記錄和索引的排列順序一致,插入記錄會重新排序,因此修改數據比較慢。
 聚集索引
聚集索引
非聚集索引:表記錄和索引的排列順序不一定一致,非聚集索引的葉子層并不和實際數據頁相重疊,而是采用葉子層包含一個指向表記錄的指針。非聚集索引層次多,不會造成數據重排。

關于數據庫的索引的詳細介紹,老貓在此不做展開。后續會有專門的文章和大家分享。
根據邏輯劃分
這塊大家日常應用的過程中應該還是比較常見的。咱們可以分成以下幾種類型。
- 主鍵索引:特殊的唯一索引,不允許有空值。
- 聯合索引:多個字段上建立的索引,用來提升復合查詢的效率。
- 普通索引:屬于基本索引,沒有其他限制。
- 唯一索引:和普通索引相似,但是值必須唯一,可以用空值,常用來做冪等。
索引命名規范
咱們在給索引命名的時候需要均用英文小寫字母進行命名。
主鍵索引:一般命名用pk_字段名稱(默認一般都是id索引,在創建表的時候一般就已經指定完成了)
普通索引:咱們命名的時候一般用idx_表名_字段名稱或者idx_字段名稱。
唯一索引:一般用uk_表名_字段名稱或者uk_字段名稱。
設計規范
1、不是所有的數據庫字段都適合加索引的。我們在建立索引的時候需要評估字段的區分度。應該盡量避免將索引建立在區分度低的字段上。舉個例子,例如性別:男女。還有日常業務中用到的狀態值、或者status-是否標記等等。
2、應當避免在頻繁更新的字段上建立索引。因為每次變更都會導致B+樹發生變更,頻繁的變更會導致數據庫的性能大大降低。
3、我們需要控制一張表中索引的數量,索引數量并不是越多越好,單表建議控制在5個以內,當然這個也要結合表字段的總數來定并非絕對。索引創建過多會增加CPU以及IO的開銷。雖然索引可以提高查詢效率,但是同樣會降低插入以及更新的效率。
4、創建聯合索引的時候盡量避免冗余。例如(a,b,c)聯合索引即相當于(a)、(a,b)、(a、b、c)。另外這里其實要提到索引的最左匹配原則。當查詢的時候為(a)或者(a,b)或者(a,b,c)的時候才能走到索引。如果查詢是(a,c)那么其實只能走到(a)索引,這個時候其實需要注意(a)的時候返回的數據量,如果過多的話,其實語句設計就是不合理的。如果查詢是(b,c)則不能走索引。(面試官也比較喜歡問這類問題)
5、能使用唯一索引的場景,我們應該盡量去使用唯一索引。
6、如果一個字段的類型是varchar并且此時我們需要去建立相關的索引,我們此時必須要指定相關索引的長度,因為在前文中我們也提到了varchar類型存儲的字符串長度往往是不固定的,如果是固定長度的咱們一般用char。我們完全沒有必要對全字段建立索引,我們只要根據字段文本的區分度來建立索引即可。如下建立索引語句:
ALTER TABLE users ADD INDEX idx_email (email(10));總結
當我們接到產品提的相關需求之后,我們就會開始進行相關的技術分析和設計,其中在設計階段就會涉及基本的業務模型的設計。最終就是進行數據模型的設計。此時就會遇到上述的一些數據庫設計的問題。
通過上述一些注意點,相信很多小伙伴應該知道數據表設計階段的一些注意點了。