













十個大型語言模型(LLM)常見面試問題和答案解析

一、哪種技術有助于減輕基于提示的學習中的偏見?
A.微調 Fine-tuning
B.數據增強 Data augmentation
C.提示校準 Prompt calibration
D.梯度裁剪 Gradient clipping
答案:C
提示校準包括調整提示,盡量減少產生的輸出中的偏差。微調修改模型本身,而數據增強擴展訓練數據。梯度裁剪防止在訓練期間爆炸梯度。
二、是否需要為所有基于文本的LLM用例提供矢量存儲?
答案:不需要
向量存儲用于存儲單詞或句子的向量表示。這些向量表示捕獲單詞或句子的語義,并用于各種NLP任務。
并非所有基于文本的LLM用例都需要矢量存儲。有些任務,如情感分析和翻譯,不需要RAG也就不需要矢量存儲。
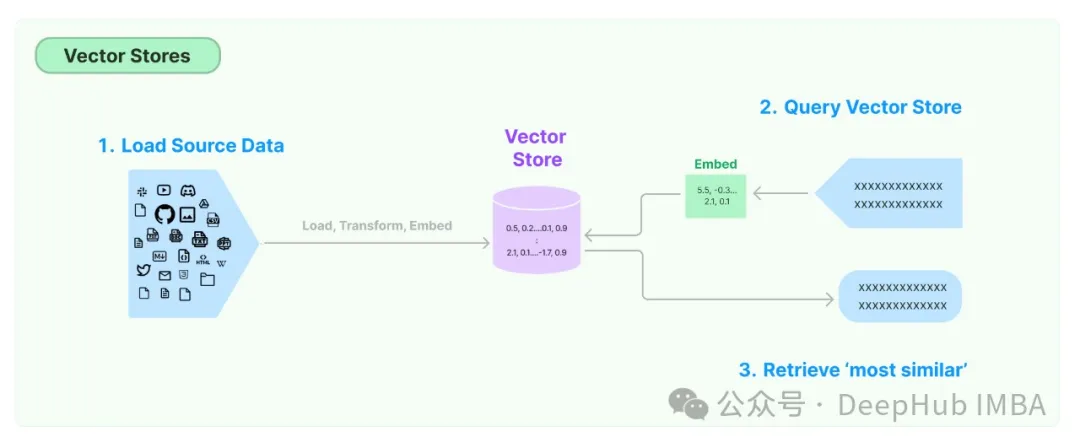
最常見的不需要矢量存儲的:
1、情感分析:這項任務包括確定一段文本中表達的情感(積極、消極、中性)。它通常基于文本本身而不需要額外的上下文。
2、這項任務包括將文本從一種語言翻譯成另一種語言。上下文通常由句子本身和它所屬的更廣泛的文檔提供,而不是單獨的向量存儲。
三、以下哪一項不是專門用于將大型語言模型(llm)與人類價值觀和偏好對齊的技術?
A.RLHF
B.Direct Preference Optimization
C.Data Augmentation
答案:C
數據增強Data Augmentation是一種通用的機器學習技術,它涉及使用現有數據的變化或修改來擴展訓練數據。雖然它可以通過影響模型的學習模式間接影響LLM一致性,但它并不是專門為人類價值一致性而設計的。
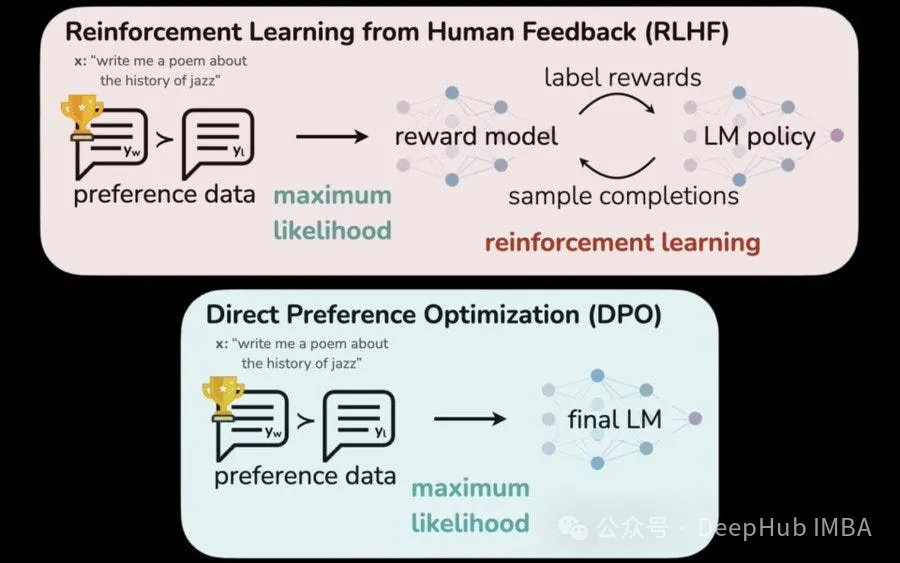
A)從人類反饋中強化學習(RLHF)是一種技術,其中人類反饋用于改進LLM的獎勵函數,引導其產生與人類偏好一致的輸出。
B)直接偏好優化(DPO)是另一種基于人類偏好直接比較不同LLM輸出以指導學習過程的技術。
四、在RLHF中,如何描述“reward hacking”?
A.優化所期望的行為
B.利用獎勵函數漏洞
答案:B
reward hacking是指在RLHF中,agent發現獎勵函數中存在意想不到的漏洞或偏差,從而在沒有實際遵循預期行為的情況下獲得高獎勵的情況,也就是說,在獎勵函數設計不有漏洞的情況下才會出現reward hacking的問題。
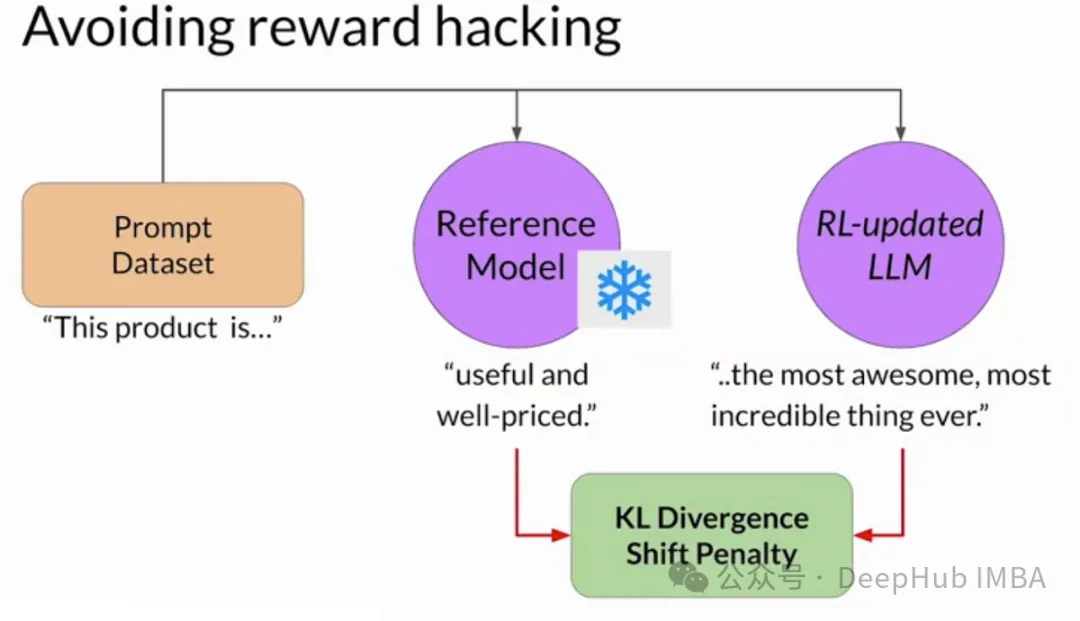
雖然優化期望行為是RLHF的預期結果,但它并不代表reward hacking。選項A描述了一個成功的訓練過程。在reward hacking中,代理偏離期望的行為,找到一種意想不到的方式(或者漏洞)來最大化獎勵。
五、對任務的模型進行微調(創造性寫作),哪個因素顯著影響模型適應目標任務的能力?
A.微調數據集的大小
B.預訓練的模型架構和大小
答案:B
預訓練模型的體系結構作為微調的基礎。像大型模型(例如GPT-3)中使用的復雜而通用的架構允許更大程度地適應不同的任務。微調數據集的大小發揮了作用,但它是次要的。一個架構良好的預訓練模型可以從相對較小的數據集中學習,并有效地推廣到目標任務。
雖然微調數據集的大小可以提高性能,但它并不是最關鍵的因素。即使是龐大的數據集也無法彌補預訓練模型架構的局限性。設計良好的預訓練模型可以從較小的數據集中提取相關模式,并且優于具有較大數據集的不太復雜的模型。
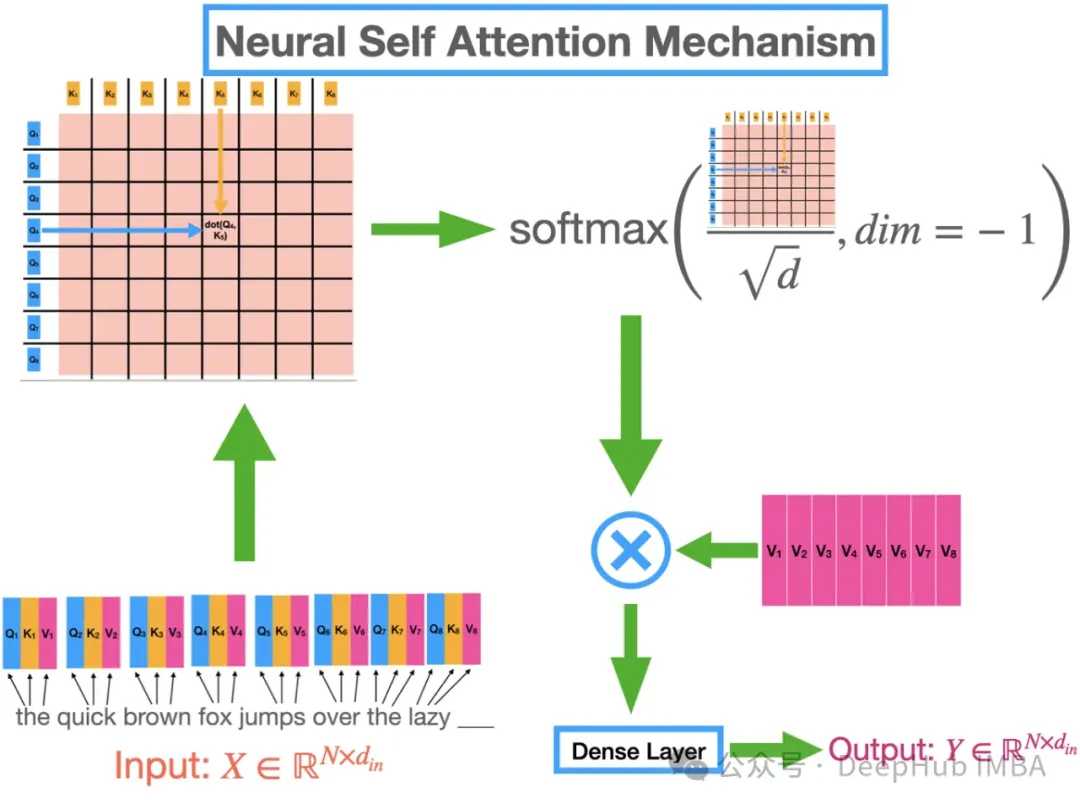
六、transformer 結構中的自注意力機制在模型主要起到了什么作用?
A.衡量單詞的重要性
B.預測下一個單詞
C.自動總結
答案:A
transformer 的自注意力機制會對句子中單詞的相對重要性進行總結。根據當前正在處理的單詞動態調整關注點。相似度得分高的單詞貢獻更顯著,這樣會對單詞重要性和句子結構的理解更豐富。這為各種嚴重依賴上下文感知分析的NLP任務提供了支持。
七、在大型語言模型(llm)中使用子詞算法(如BPE或WordPiece)的優點是什么?
A.限制詞匯量
B.減少訓練數據量
C.提高計算效率
答案:A
llm處理大量的文本,如果考慮每一個單詞,就會導致一個非常大的詞表。像字節對編碼(BPE)和WordPiece這樣的子詞算法將單詞分解成更小的有意義的單位(子詞),然后用作詞匯表。這大大減少了詞匯量,同時仍然捕獲了大多數單詞的含義,使模型更有效地訓練和使用。
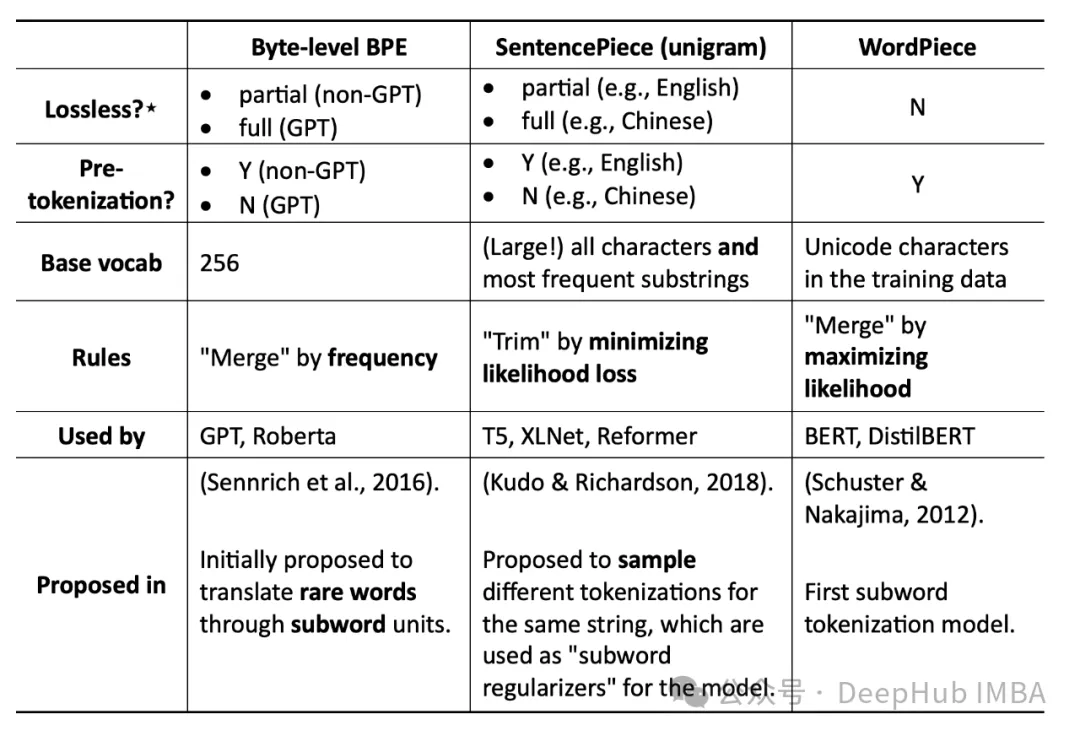
子詞算法不直接減少訓練數據量。數據大小保持不變。雖然限制詞匯表大小可以提高計算效率,但這并不是子詞算法的主要目的。它們的主要優點在于用較小的單位集有效地表示較大的詞匯表。
八、與Softmax相比,Adaptive Softmax如何提高大型語言模型的速度?
A.稀疏單詞表示
B.Zipf定律
C.預訓練嵌入
答案:B
標準Softmax需要對每個單詞進行昂貴的計算,Softmax為詞表中的每個單詞進行大量矩陣計算,導致數十億次操作,而Adaptive Softmax利用Zipf定律(常用詞頻繁,罕見詞不頻繁)按頻率對單詞進行分組。經常出現的單詞在較小的組中得到精確的計算,而罕見的單詞被分組在一起以獲得更有效的計算。這大大降低了訓練大型語言模型的成本。
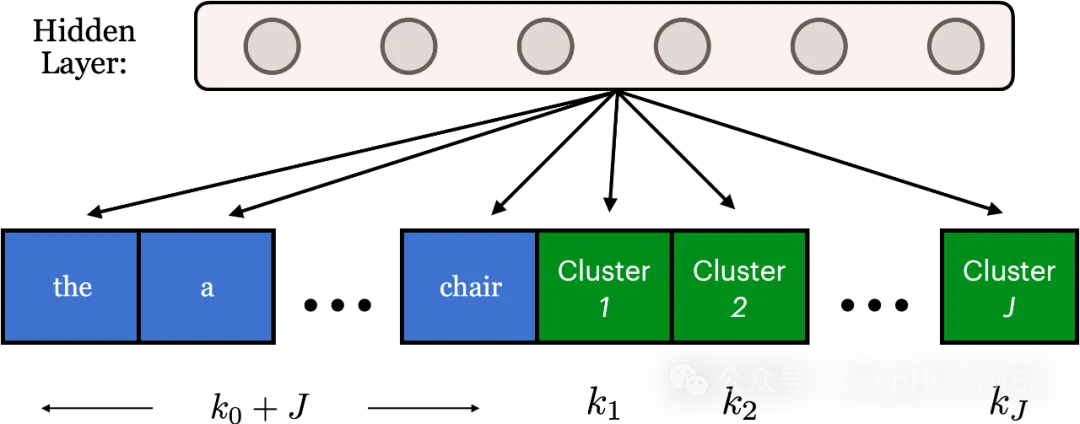
雖然稀疏表示可以改善內存使用,但它們并不能直接解決Softmax在大型詞匯表中的計算瓶頸。預訓練嵌入增強了模型性能,但沒有解決Softmax計算復雜性的核心問題。
九、可以調整哪些推理配置參數來增加或減少模型輸出層中的隨機性?
A.最大新令牌數
B. Top-k
C.Temperature
答案:C
在文本生成過程中,大型語言模型(llm)依賴于softmax層來為潛在的下一個單詞分配概率。溫度Temperature是影響這些概率分布隨機性的關鍵參數。
當溫度設置為低時,softmax層根據當前上下文為具有最高可能性的單個單詞分配顯著更高的概率。更高的溫度“軟化”了概率分布,使其他不太可能出現的單詞更具競爭力。
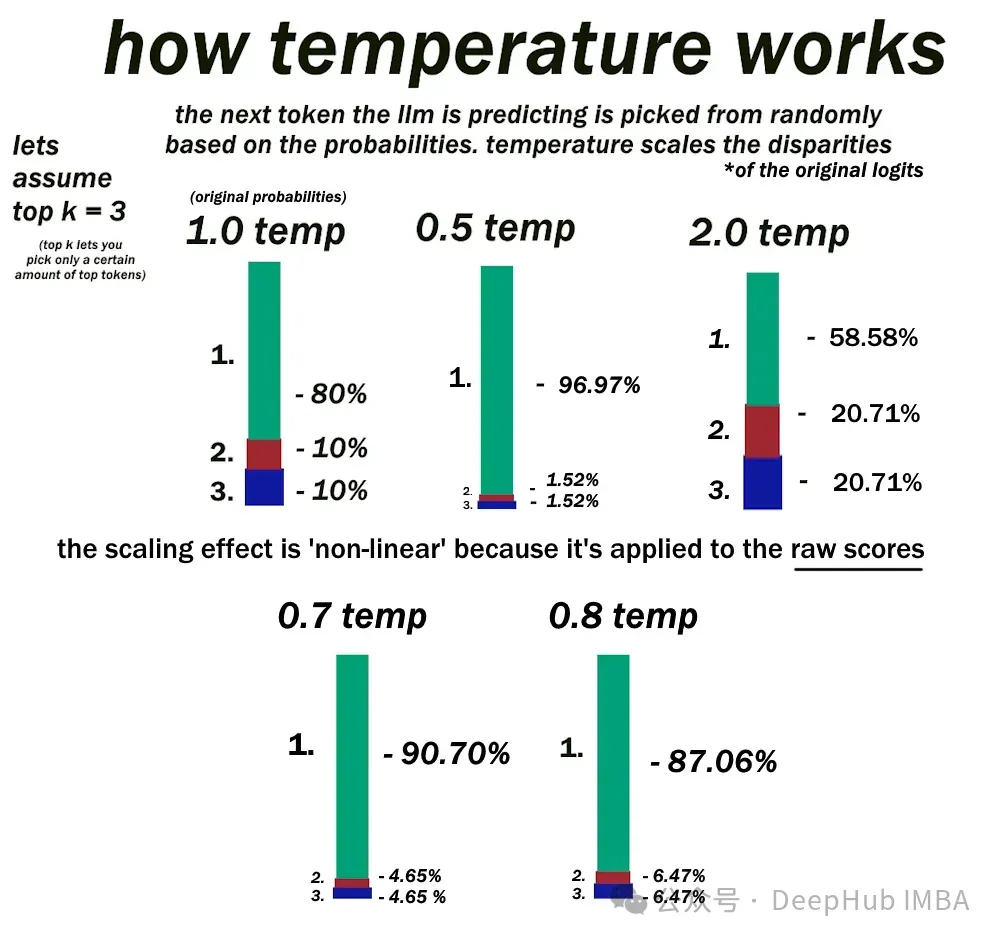
最大新令牌數僅定義LLM在單個序列中可以生成的最大單詞數。top -k采樣限制softmax層只考慮下一個預測最可能的前k個單詞。
十、當模型不能在單個GPU加載時,什么技術可以跨GPU擴展模型訓練?
A. DDP
B. FSDP
答案:B
FSDP(Fully Sharded Data Parallel)是一種技術,當模型太大而無法容納在單個芯片的內存時,它允許跨GPU縮放模型訓練。FSDP可以將模型參數,梯度和優化器進行分片操作,并且將狀態跨gpu傳遞,實現高效的訓練。
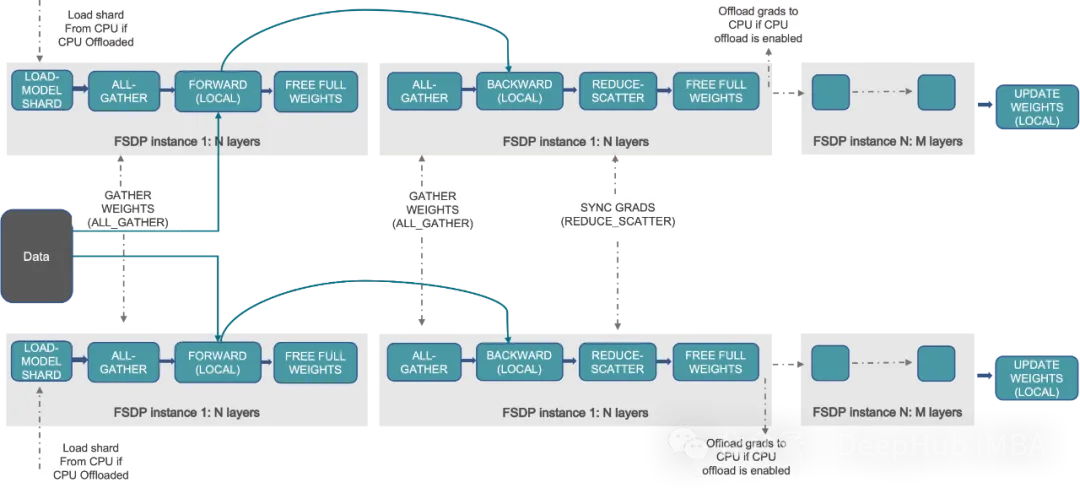
DDP(分布式數據并行)是一種跨多個GPU并行分發數據和處理批量的技術,但它要求模型適合單個GPU,或者更直接的說法是DDP要求單個GPU可以容納下模型的所有參數。

























