還在YOLO-World?DetCLIPv3出手!性能大幅度超出一眾SOTA!
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。

現(xiàn)有的開詞匯目標(biāo)檢測器通常需要用戶預(yù)設(shè)一組類別,這大大限制了它們的應(yīng)用場景。在本文中,作者介紹了DetCLIPv3,這是一種高性能檢測器,不僅在開詞匯目標(biāo)檢測方面表現(xiàn)出色,同時還能為檢測到的目標(biāo)生成分層標(biāo)簽。
DetCLIPv3的特點(diǎn)有三個核心設(shè)計(jì):
- 多功能的模型架構(gòu):作者導(dǎo)出一個健壯的開集檢測框架,并通過集成字幕 Head 進(jìn)一步賦予其生成能力。
- 高信息密度數(shù)據(jù):作者開發(fā)了一個自動標(biāo)注 Pipeline ,利用視覺大型語言模型來細(xì)化大規(guī)模圖像-文本對中的字幕,為訓(xùn)練提供豐富、多粒度的目標(biāo)標(biāo)簽以增強(qiáng)訓(xùn)練。
- 高效的訓(xùn)練策略:作者采用了一個預(yù)訓(xùn)練階段,使用低分辨率輸入,使目標(biāo)字幕生成器能夠從廣泛的圖像-文本配對數(shù)據(jù)中高效學(xué)習(xí)廣泛的視覺概念。
在預(yù)訓(xùn)練之后是一個微調(diào)階段,利用少量高分辨率樣本進(jìn)一步提高檢測性能。借助這些有效的設(shè)計(jì),DetCLIPv3展示了卓越的開詞匯檢測性能,例如,作者的Swin-T Backbone 模型在LVIS minival基準(zhǔn)上取得了顯著的47.0零樣本固定AP,分別優(yōu)于GLIPv2、GroundingDINO和DetCLIPv2 18.0/19.6/6.6 AP。DetCLIPv3在VG數(shù)據(jù)集上的密集字幕任務(wù)也取得了先進(jìn)的19.7 AP,展示了其強(qiáng)大的生成能力。
1 Introduction
在開放詞匯目標(biāo)檢測(OVD)領(lǐng)域的近期進(jìn)展已經(jīng)實(shí)現(xiàn)了識別和定位多種不同目標(biāo)的能力。然而,這些模型在推理過程中依賴于預(yù)定義的目標(biāo)類別列表,這限制了它們在實(shí)際場景中的應(yīng)用。
與目前僅基于類別名稱識別物體的開放詞匯目標(biāo)檢測(OVD)方法相比,人類認(rèn)知展現(xiàn)出了更多的靈活性。如圖2所示,人類能夠以層次化的方式,從不同的粒度理解物體。這種多級識別能力展示了人類豐富的視覺理解能力,這是現(xiàn)代OVD系統(tǒng)尚未達(dá)到的。
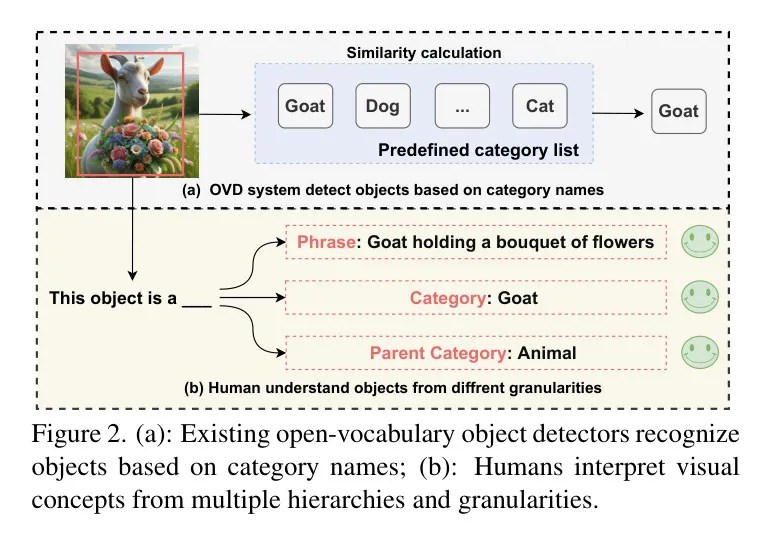
為了解決上述限制,作者引入了DetCLIPv3,這是一種新型的目標(biāo)檢測器,它擴(kuò)展了開放詞匯目標(biāo)檢測的范圍。DetCLIPv3不僅能夠根據(jù)提供的類別名稱識別物體,還能夠?yàn)槊總€檢測到的物體生成層次化的標(biāo)簽。這一特性具有兩個優(yōu)點(diǎn):1) 由于其卓越的生成能力,即使在沒有適當(dāng)?shù)妮斎胛矬w類別的情況下,檢測器仍然適用;2) 模型能夠提供關(guān)于物體的全面且分層的描述,而不僅僅是基于給定類別進(jìn)行識別。具體來說,DetCLIPv3具有三個核心設(shè)計(jì)特點(diǎn):
多功能的模型架構(gòu): DetCLIPv3基于一個健壯的開詞匯(OV)檢測器,并且進(jìn)一步通過一個物體描述器增強(qiáng)了其生成能力。具體來說,物體描述器利用OV檢測器提供的foreground proposals(前景 Proposal ),并通過語言建模訓(xùn)練目標(biāo)來訓(xùn)練生成每個檢測到的物體的分層標(biāo)簽。這種設(shè)計(jì)不僅允許精確的定位,還能提供視覺概念的詳細(xì)描述,從而為視覺內(nèi)容提供更豐富的解釋。
高信息密度數(shù)據(jù): 發(fā)展強(qiáng)大的生成能力需要豐富的訓(xùn)練數(shù)據(jù),這些數(shù)據(jù)需充實(shí)了詳細(xì)的物體 Level 描述。這樣全面的數(shù)據(jù)庫稀缺(例如,Visual Genome [25])成為了訓(xùn)練有效物體描述生成器的重大障礙。另一方面,盡管大規(guī)模的圖像-文本配對數(shù)據(jù)很豐富,但它們?nèi)狈γ總€物體的細(xì)粒度標(biāo)注。為了利用這些數(shù)據(jù),作者設(shè)計(jì)了一個自動標(biāo)注管線,利用最先進(jìn)的視覺大型語言模型[7, 35],該模型能夠提供包含豐富層次化物體標(biāo)簽的精細(xì)圖像描述。通過這個管線,作者得到了一個大規(guī)模的數(shù)據(jù)集(稱為GranuCap50M),以增強(qiáng)DetCLIPv3在檢測和生成方面的能力。
高效的多階段訓(xùn)練: 與高分辨率輸入相關(guān)的目標(biāo)檢測訓(xùn)練成本高昂,這對從大量的圖像-文本對中學(xué)習(xí)構(gòu)成了重大障礙。為了解決這個問題,作者提出了一種高效的多階段對齊訓(xùn)練策略。這種方法首先利用大規(guī)模、低分辨率的圖像-文本數(shù)據(jù)集的知識,然后在高質(zhì)量、細(xì)粒度、高分辨率的 數(shù)據(jù)上進(jìn)行微調(diào)。這種方法確保了全面的視覺概念學(xué)習(xí),同時保持了可管理的訓(xùn)練需求。
通過有效的設(shè)計(jì),DetCLIPv3在檢測和目標(biāo) Level 的生成能力上表現(xiàn)出色,例如,采用Swin-T Backbone 網(wǎng)絡(luò),在LVIS minival基準(zhǔn)測試中取得了顯著的47.0零樣本固定AP[9],明顯優(yōu)于先前的模型如GLIPv2[65],DetCLIPv2[60]和GroundingDINO[36]。此外,它在密集字幕任務(wù)上達(dá)到18.4 mAP,比先前的SOTA方法GRiT[56]高出2.9 mAP。廣泛的實(shí)驗(yàn)進(jìn)一步證明了DetCLIPv3在領(lǐng)域泛化及下游遷移能力方面的優(yōu)越性。
2 Related works
開放詞匯目標(biāo)檢測。 近期在開放詞匯目標(biāo)檢測(OVD)方面的進(jìn)展使得可以識別無限范圍類別的目標(biāo),如文獻(xiàn)[16, 17, 57, 63, 69]所示。這些方法通過將預(yù)訓(xùn)練的視覺-語言模型,例如CLIP [46],整合到檢測器中來實(shí)現(xiàn)OVD。另外,擴(kuò)大檢測訓(xùn)練數(shù)據(jù)集也顯示出潛力[24, 29, 31, 36, 58, 60, 65, 70],這些方法結(jié)合了來自各種任務(wù)(如分類和視覺定位)的數(shù)據(jù)集。此外,偽標(biāo)簽已經(jīng)作為增強(qiáng)訓(xùn)練數(shù)據(jù)集的另一種有效策略出現(xiàn),如文獻(xiàn)[15, 29, 43, 58, 68, 69]所示。然而,先前的OVD方法仍然需要一個預(yù)定義的目標(biāo)類別進(jìn)行檢測,這限制了它們在多樣化場景中的適用性。相比之下,作者的DetCLIPv3即使在沒有類別名稱的情況下也能夠生成豐富的分層目標(biāo)標(biāo)簽。
密集字幕生成。 密集字幕生成旨在為特定圖像區(qū)域生成描述[23, 28, 30, 51, 61]。最近,CapDet [38] 和 GRiT [56] 都通過引入一個字幕生成器,為目標(biāo)檢測器配備了生成能力。然而,由于訓(xùn)練數(shù)據(jù)稀缺,例如 Visual Genome [25] 中包含的數(shù)據(jù),它們只能為有限的視覺概念生成描述。相比之下,作者利用大規(guī)模圖像-文本對中的豐富知識,使模型能夠?yàn)楦鼜V泛的概念譜生成分層標(biāo)簽信息。
圖像-文本對的重新描述。 近期研究 [5, 26, 44, 62] 強(qiáng)調(diào)了當(dāng)前圖像-文本對數(shù)據(jù)中存在的問題,并已表明重新描述的高質(zhì)量圖像-文本對可以顯著提高各種視覺任務(wù)的學(xué)習(xí)效率,例如文本到圖像生成 [5, 44],圖像-文本檢索 [26, 27] 和圖像標(biāo)注 [26, 62]。作者將這一想法擴(kuò)展到開放詞匯目標(biāo)檢測,并探索如何有效地利用圖像-文本對中包含的目標(biāo)實(shí)體信息。
3 Method
在本節(jié)中,作者介紹了DetCLIPv3的核心設(shè)計(jì),包括:(1)模型架構(gòu)(第3.1節(jié))—闡述作者的模型如何實(shí)現(xiàn)開詞匯目標(biāo)檢測及生成目標(biāo)描述;(2)自動標(biāo)注數(shù)據(jù)流程(第3.2節(jié))—詳細(xì)說明作者策劃大規(guī)模、高質(zhì)量的圖像-文本對的方法,涵蓋不同粒度層面的目標(biāo)信息;(3)訓(xùn)練策略(第3.3節(jié))—概述作者如何有效地利用大規(guī)模圖像-文本數(shù)據(jù)集來促進(jìn)目標(biāo)概念的生成,進(jìn)而提升開詞匯檢測的能力。
Model Design
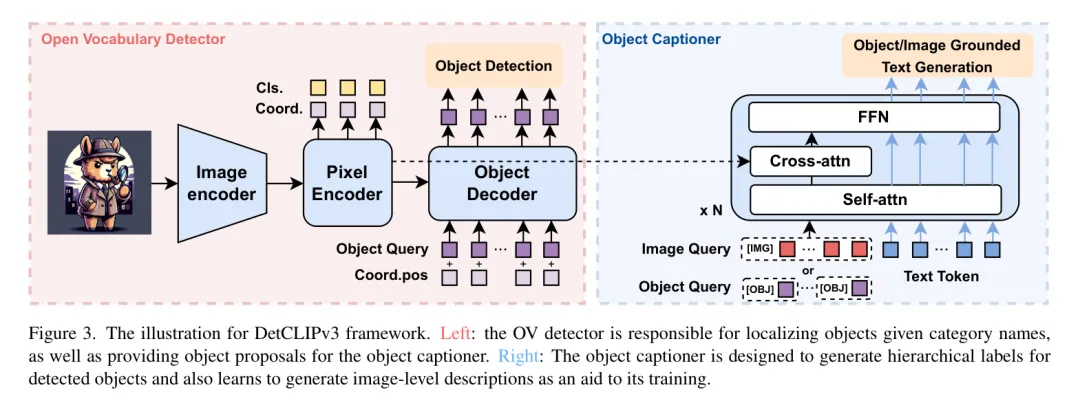
圖3展示了DetCLIPv3的整體框架。本質(zhì)上,該模型基于一個強(qiáng)大的開放詞匯目標(biāo)檢測器,并配備了一個專門用于生成分層和描述性目標(biāo)概念的目標(biāo)標(biāo)題生成器。該模型能夠在兩種模式下運(yùn)行:1) 當(dāng)提供一個預(yù)定義的類別詞匯表時,DetCLIPv3預(yù)測列表中提到的物體的定位;2) 在沒有詞匯表的情況下,DetCLIPv3能夠定位物體并為每一個物體生成分層描述。
數(shù)據(jù)制定。 DetCLIPv3的訓(xùn)練利用了來自多個來源的數(shù)據(jù)集,包括檢測[50, 55]、定位[24]以及圖像-文本對[4, 48, 52, 53],并帶有邊界框偽標(biāo)簽(具體見第3.2節(jié))。與DetCLIPv1/v2[58, 60]一樣,作者采用一種_平行制定_方法將來自不同數(shù)據(jù)源的文本輸入統(tǒng)一為一種標(biāo)準(zhǔn)格式。具體來說,每個輸入樣本結(jié)構(gòu)化為一個三元組,,其中是輸入圖像,表示一組邊界框,而則表示一組概念文本,包括正負(fù)概念。
對于檢測數(shù)據(jù), 包括類別名稱及其定義(如 [58, 60] 中所述),適用于訓(xùn)練和測試階段。負(fù)概念是從數(shù)據(jù)集中的類別中抽取的。對于接地(grounding)和圖像-文本對數(shù)據(jù),正概念是目標(biāo)描述,而負(fù)概念則從大規(guī)模名詞語料庫中抽取(具體見第3.2節(jié))。在訓(xùn)練期間,為了增加負(fù)概念的數(shù)量,作者從所有訓(xùn)練節(jié)點(diǎn)收集它們,并執(zhí)行去重處理。
開放詞匯檢測器。 作者提出了一種緊湊但功能強(qiáng)大的檢測器架構(gòu),用于DetCLIPv3,如圖3中紅色框所示。具體來說,它是一個雙路徑模型,包括一個視覺目標(biāo)檢測器 和一個文本編碼器 。視覺目標(biāo)檢測器采用基于 Transformer 的檢測架構(gòu)[3, 66, 71],由一個 Backbone 網(wǎng)絡(luò)、一個像素編碼器和一個目標(biāo)解碼器組成。Backbone 網(wǎng)絡(luò)和像素編碼器負(fù)責(zé)提取視覺特征,進(jìn)行細(xì)粒度特征融合,并為解碼器提出候選目標(biāo) Query 。類似于GroundingDINO [36],作者利用文本特征根據(jù)相似性選擇前k個像素特征,并后來使用它們的坐標(biāo)預(yù)測來初始化解碼器目標(biāo) Query 的位置部分。然而,與眾不同的是,作者放棄了在[36]中設(shè)計(jì)的計(jì)算密集型跨模態(tài)融合模塊。遵循先前的DETR-like檢測器[3, 66, 71],作者的訓(xùn)練損失由三個組成部分構(gòu)成:,其中 是區(qū)域視覺特征與文本概念之間的對比焦損失[34],而 和 分別是L1損失和GIOU[47]損失。為了提升性能,在解碼器的每一層以及編碼器的輸出上采用了輔助損失。
目標(biāo)描述器。 目標(biāo)描述器使DetCLIPV3能夠?yàn)槲矬w生成詳細(xì)和分層的標(biāo)簽。為了獲取圖像-文本對中包含的豐富知識,作者在訓(xùn)練過程中進(jìn)一步結(jié)合了圖像級字幕目標(biāo)以增強(qiáng)生成能力。如圖3中藍(lán)色框所示,目標(biāo)描述器的設(shè)計(jì)受到Qformer [27]的啟發(fā)。具體來說,它采用了一種基于多模態(tài)Transformer的架構(gòu),其交叉注意力層被替換為為密集預(yù)測任務(wù)定制的可變形注意力[71]。描述器的輸入包括視覺(物體或圖像) Query 和文本標(biāo)記。視覺 Query 通過交叉注意力與像素編碼器的特征交互,而自注意力層和FFN層在不同模態(tài)之間共享。此外,采用了多模態(tài)因果自注意力 Mask [11, 27]來控制視覺 Query 與文本標(biāo)記之間的交互。描述器的訓(xùn)練由傳統(tǒng)的語言建模損失 指導(dǎo),對于物體級和圖像級生成具有不同的輸入格式:
目標(biāo)級生成。目標(biāo) Query 以及可變形交叉注意力所需的參考點(diǎn),都來源于目標(biāo)解碼器最終層的輸出。輸入結(jié)構(gòu)為:$,其中\texttt{[OBJ]}$是一個特殊的任務(wù) Token ,表示目標(biāo)生成任務(wù)。在訓(xùn)練期間,作者使用與 GT 情況相匹配的正 Query 來計(jì)算損失。在推理過程中,為了獲得前景 Proposal ,作者根據(jù)它們與作者精選名詞語料庫(第3.2節(jié))中最頻繁的15K名詞概念的相似性,選擇前k個候選目標(biāo) Query 。在為這些目標(biāo)生成分層標(biāo)簽后,作者使用OV檢測器重新校準(zhǔn)它們的目標(biāo)性得分,計(jì)算目標(biāo) Query 與它們生成的'短語'和'類別'字段之間的相似性。這2個相似性中較高的一個被采納作為目標(biāo)性得分。
圖像級生成。受到Qformer [27]的啟發(fā),作者初始化了32個可學(xué)習(xí)的圖像 Query ,并使用一組固定的參考點(diǎn)。具體來說,作者從像素編碼器的參考點(diǎn)等間隔地采樣了32個位置。與目標(biāo)級生成類似,輸入結(jié)構(gòu)為 $</imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text></imagequery,$$\texttt{[img]},text>,其中\texttt{[IMG]}$ 是一個特殊的任務(wù)標(biāo)記,表示圖像生成。圖像級生成的推理過程與訓(xùn)練是一致的。</imagequery,$$\texttt{[img]},text>
Dataset Construction
自動標(biāo)注數(shù)據(jù) Pipeline 。利用大量成本效益高的圖像-文本對進(jìn)行視覺概念學(xué)習(xí),對于提高開放詞匯目標(biāo)檢測器的一般化能力至關(guān)重要。然而,現(xiàn)有的圖像-文本對數(shù)據(jù)集存在重大缺陷,這些缺陷阻礙了它們在OVD中的實(shí)用性,如圖4所示:(1) 錯位:互聯(lián)網(wǎng)來源的圖像-文本對數(shù)據(jù)經(jīng)常包含大量噪聲。即使使用CLIP [46]基于分?jǐn)?shù)的過濾[48, 49],許多文本仍然無法準(zhǔn)確描述圖像的內(nèi)容,如圖4的第二和第三張圖像所示。(2) 部分標(biāo)注:大部分文本只描述圖像中的主要目標(biāo),導(dǎo)致目標(biāo)信息稀疏,因此,損害了OVD系統(tǒng)的學(xué)習(xí)效率,如圖1所示。(3) 實(shí)體提取挑戰(zhàn):先前的工作[24, 32, 43, 60]主要使用傳統(tǒng)的NLP解析器,如NLTK [1, 42]或SpaCy [21],從圖像-文本對中提取名詞概念。它們的有限能力可能導(dǎo)致名詞與圖像內(nèi)容對齊不良,如圖4的第二行所示。這種不匹配為后續(xù)的學(xué)習(xí)過程或偽標(biāo)簽工作流程帶來了進(jìn)一步的復(fù)雜性。


一個理想的圖像-文本對數(shù)據(jù)集對于視覺描述(OVD)應(yīng)當(dāng)包含對圖像的準(zhǔn)確和全面的描述,提供從詳細(xì)到粗略不同粒度 Level 的圖像中目標(biāo)的信息。基于這種啟發(fā),作者 Proposal 使用視覺大型語言模型(VLLM)[7, 35]來開發(fā)一個自動標(biāo)注流水線,以提高數(shù)據(jù)質(zhì)量。VLLM具有感知圖像內(nèi)容的能力,以及強(qiáng)大的語言技能,使它們能夠生成精確和詳細(xì)的標(biāo)題以及目標(biāo)描述。
使用VLLM重制標(biāo)題:作者從常用的數(shù)據(jù)集[4, 52, 53]中抽取了24萬張圖像-文本對,并使用InstructBLIP [7]模型進(jìn)行了重制標(biāo)題。為了利用原始標(biāo)題中的信息,作者將其融入作者的提示設(shè)計(jì)中,結(jié)構(gòu)如下:_"給定圖像的一個含噪聲的標(biāo)題:{原始標(biāo)題},撰寫一幅圖像的詳細(xì)清晰描述。"_。這種方法有效地提升了標(biāo)題文本的質(zhì)量,同時保持了原始標(biāo)題中名詞概念的多樣性。
使用GPT-4的實(shí)體提取:作者利用GPT-4[45]卓越的語言能力來處理精致標(biāo)題中的實(shí)體信息。具體來說,首先用它過濾掉VLLM生成的標(biāo)題中非實(shí)體的描述,比如對圖像的氛圍或藝術(shù)性解讀。隨后,它負(fù)責(zé)從標(biāo)題中提取出現(xiàn)的物體實(shí)體。每個實(shí)體都被格式化為一個三元組:{短語,類別,父類別},分別表示物體描述在三個不同粒度 Level 上。
對VLLM進(jìn)行大規(guī)模標(biāo)注的指令調(diào)整:考慮到GPT-4 API的高昂成本,將其用于大規(guī)模數(shù)據(jù)集生成是不切實(shí)際的。作為一種解決方案,作者在LLaVA [35]模型上執(zhí)行進(jìn)一步的指令調(diào)整階段,利用之前步驟獲得的改進(jìn)的標(biāo)題和目標(biāo)實(shí)體。然后,這個微調(diào)后的模型被用來為包含200M圖像-文本對的大型數(shù)據(jù)集生成標(biāo)題和實(shí)體信息,這些樣本取自CC15M [4, 52],YFCC[53] 和 LAION [48]。
邊界框自動標(biāo)記:為了自動推導(dǎo)出圖像-文本配對數(shù)據(jù)中的邊界框標(biāo)注,作者應(yīng)用一個預(yù)訓(xùn)練的開詞匯目標(biāo)檢測器(第3.3節(jié))來分配偽邊界框標(biāo)簽,給定從前一步驟中得出的目標(biāo)實(shí)體。當(dāng)提供來自VLLM的準(zhǔn)確候選目標(biāo)實(shí)體時,檢測器的準(zhǔn)確性可以大大提高。具體來說,作者將 '短語' 和 '類別' 字段作為檢測器的文本輸入,并使用預(yù)定義的分?jǐn)?shù)閾值來過濾結(jié)果邊界框。如果這兩個字段中的任何一個匹配,作者會為該目標(biāo)分配整個實(shí)體 {短語, 類別, 父類別}。在使用預(yù)定義的置信度閾值過濾后,大約有5000萬個數(shù)據(jù)被采樣用于后續(xù)訓(xùn)練,作者將其稱為 GranuCap50M。在訓(xùn)練檢測器時,作者使用 '短語' 和 '類別' 字段作為文本標(biāo)簽;而在訓(xùn)練目標(biāo)描述器時,作者將三個字段 - '短語' 類別' 父類別'
無概念語料庫。 與DetCLIP [58]相似,作者利用提取的目標(biāo)實(shí)體的信息開發(fā)了一個名詞概念語料庫。這個語料庫主要旨在為GT和圖像-文本對數(shù)據(jù)(第3.1節(jié))提供負(fù)概念。具體來說,作者從20億個重新配文的數(shù)據(jù)中收集實(shí)體的_'category'_字段。在頻率分析之后,總頻率低于10的概念被省略。DetCLIPv3的名詞概念語料庫由792k名詞概念組成,幾乎是DetCLIP中構(gòu)建的14k概念的57倍擴(kuò)展。
Multi-stage Training Scheme
學(xué)習(xí)生成多樣化的物體描述需要在大型數(shù)據(jù)集上進(jìn)行廣泛的訓(xùn)練。然而,像目標(biāo)檢測這樣的密集預(yù)測任務(wù)需要高分辨率輸入才能有效處理不同物體之間的尺度變化。這大大提高了計(jì)算成本,給擴(kuò)大訓(xùn)練規(guī)模帶來了挑戰(zhàn)。為了緩解這個問題,作者開發(fā)了一個基于“預(yù)訓(xùn)練+微調(diào)”范式的訓(xùn)練策略來優(yōu)化訓(xùn)練成本,具體來說,它包括以下3個步驟:
訓(xùn)練OV檢測器(第一階段):在初始階段,作者用標(biāo)注的數(shù)據(jù)集來訓(xùn)練OV檢測器,即Objects365 [50],V3Det[55]和GoldG [24]。為了使模型在后續(xù)訓(xùn)練階段能夠從低分辨率輸入中學(xué)習(xí),作者對訓(xùn)練數(shù)據(jù)應(yīng)用了大規(guī)模抖動增強(qiáng)。此外,在這一階段開發(fā)的具有Swin-L Backbone 網(wǎng)絡(luò)的模型被用來為圖像-文本對生成偽邊界框,具體如第3.2節(jié)所述。
預(yù)訓(xùn)練目標(biāo)描述生成器(階段2):為了使目標(biāo)描述生成器能夠生成多樣化的目標(biāo)描述,作者使用GranuCap50M對其進(jìn)行預(yù)訓(xùn)練。為了提高這個訓(xùn)練階段的效率,作者凍結(jié)了OV檢測器所有的參數(shù),包括 Backbone 網(wǎng)絡(luò)、像素編碼器和目標(biāo)解碼器,并采用了較低的輸入分辨率320×320。這種策略使得描述生成器能夠從大規(guī)模的圖像-文本對中有效地獲取視覺概念知識。
整體微調(diào)(階段3):這一階段旨在使字幕生成器適應(yīng)高分辨率輸入,同時提高 OV 檢測器的性能。具體來說,作者從 GranuCap50M 中均勻抽取了60萬個樣本。這些樣本以及檢測和定位數(shù)據(jù)集一起用來進(jìn)一步微調(diào)模型。在此階段,釋放所有參數(shù)以最大化有效性,訓(xùn)練目標(biāo)設(shè)置為檢測和字幕生成損失的組合,即 。字幕生成器的監(jiān)督僅來自使用作者的自動標(biāo)注 Pipeline 構(gòu)建的數(shù)據(jù)集,而所有數(shù)據(jù)都用于 OV 檢測器的訓(xùn)練。由于檢測器和字幕生成器都已進(jìn)行預(yù)訓(xùn)練,因此模型可以在幾個周期內(nèi)有效適應(yīng)。
4 Experiments
訓(xùn)練細(xì)節(jié)。 作者使用Swin-T和Swin-L [37] 主干網(wǎng)絡(luò)訓(xùn)練了2個模型。目標(biāo)檢測器的訓(xùn)練設(shè)置主要遵循DetCLIPv2 [60]。作者分別使用32/64塊V100 GPU來訓(xùn)練基于swin-T/L的模型。三個階段的訓(xùn)練周期分別為12、3和5。對于使用Swin-T主干網(wǎng)絡(luò)的模型,這些階段的相應(yīng)訓(xùn)練時間總計(jì)為54、56和35小時。有關(guān)其他訓(xùn)練細(xì)節(jié),請參閱附錄。
Zero-Shot Open-Vocabulary Object Detection
遵循之前的工作[29, 43, 58, 60, 65],作者用1203類LVIS[18]數(shù)據(jù)集上的零樣本性能來評估作者模型的開放詞匯能力。作者報(bào)告了在val(LVIS)和mini-val[24](LVIS)分割上的固定AP[9]性能。在這個實(shí)驗(yàn)中,作者僅使用了模型的OV檢測器組件,并將數(shù)據(jù)集的類別名稱作為輸入。
表1展示了作者的方法與現(xiàn)有方法的比較。DetCLIPv3顯著優(yōu)于其他方法,展現(xiàn)了卓越的開詞匯目標(biāo)檢測能力。例如,在LVIS小型驗(yàn)證集上,采用Swin-T(第8行)和Swin-L(第15行) Backbone 網(wǎng)絡(luò)的作者的模型分別達(dá)到47.0和48.8的AP,分別比之前的最先進(jìn)方法DetCLIPv2提高了6.6(第7行)和4.1 AP(第14行)。值得注意的是,作者的Swin-L模型在稀有類別上的性能(49.9 AP)甚至超過了在基礎(chǔ)類別上的性能(頻繁類別中為47.8 AP,普通類別中為49.7 AP)。這表明,使用高質(zhì)量圖像-文本對的全面預(yù)訓(xùn)練大大增強(qiáng)了模型識別各種視覺概念的能力,導(dǎo)致在長尾分布數(shù)據(jù)上的檢測能力顯著提升。

Evaluation of Object Captioner
作者采用了2個任務(wù)來評估作者的物體描述生成器,即零樣本生成式目標(biāo)檢測和密集標(biāo)注。
零樣本生成目標(biāo)檢測。 作者在COCO [33] 數(shù)據(jù)集上進(jìn)行了零樣本目標(biāo)級標(biāo)簽生成,使用的推理過程是第3.1節(jié)中描述的,并評估了其檢測性能。然而,這種評估由于兩個關(guān)鍵因素而具有重大挑戰(zhàn):(1) 缺乏預(yù)定義的類別用于前景選擇,導(dǎo)致檢測器提出的前景區(qū)域與數(shù)據(jù)集的目標(biāo)模式之間存在不一致。(2) 生成結(jié)果可以是任何任意的詞匯,這可能與數(shù)據(jù)集中指定的類別名稱不匹配。為了緩解這些問題,作者引入了多種后處理技術(shù)。具體來說,作者使用生成的標(biāo)簽中的“類別”字段作為目標(biāo)的類別。為了解決第(2)個問題,在評估過程中,作者使用評估模型的文本編碼器計(jì)算生成類別與COCO類別名稱之間的相似性,并用最佳匹配的COCO類別替換生成的目標(biāo)類別。為了解決第(1)個問題,作者進(jìn)一步過濾掉相似度得分低于預(yù)定義閾值0.7的目標(biāo)。
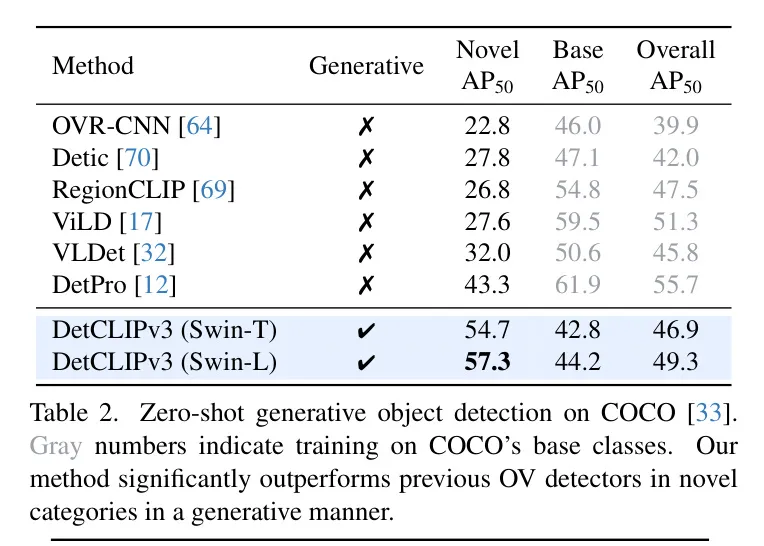
為了與現(xiàn)有方法進(jìn)行比較,作者采用了在OVR-CNN [64]中提出的OV COCO設(shè)置,其中從COCO中選擇了48個類別作為基礎(chǔ)類別,17個作為新穎類別。所使用的評估指標(biāo)是在IoU為0.5時的mAP。與先前方法相反,_作者在所有設(shè)置中執(zhí)行零樣本生成OV檢測,而無需對基礎(chǔ)類別進(jìn)行訓(xùn)練_。表2展示了評估結(jié)果。作者的生成方法可以在新穎類別性能上顯著優(yōu)于先前的判別方法。而且,在沒有對基礎(chǔ)類別進(jìn)行訓(xùn)練的情況下,作者的總體AP達(dá)到了與先前方法相當(dāng)?shù)乃健_@些結(jié)果證明了基于生成的OV檢測作為一個有前景的范式的潛力。
密集字幕生成。 利用從大量的圖像-文本對中獲得的視覺概念知識,DetCLIPv3可以輕松地被適配以生成詳細(xì)的物體描述。遵循[23, 51]的研究,作者在VG V1.2 [25]和VG-COCO [51]數(shù)據(jù)集上評估了密集字幕生成的性能。為了確保公平比較,作者在訓(xùn)練數(shù)據(jù)集上對作者的模型進(jìn)行微調(diào)。類似于CapDet [38],在微調(diào)期間,作者將作者的OV檢測器轉(zhuǎn)換為一個類無關(guān)的前景提取器,這是通過將所有前景物體的文本標(biāo)簽分配給概念'object'來實(shí)現(xiàn)的。表3將作者的方法與現(xiàn)有方法進(jìn)行了比較。DetCLIPv3顯著優(yōu)于現(xiàn)有方法。_例如_,在VG上,作者使用Swin-T(第7行)和Swin-L(第8行)作為 Backbone 網(wǎng)絡(luò)的模型,分別超過了之前最佳的方法GRiT [56](第6行),提高了2.9 AP和4.2 AP。

Robustness to Distribution Shift
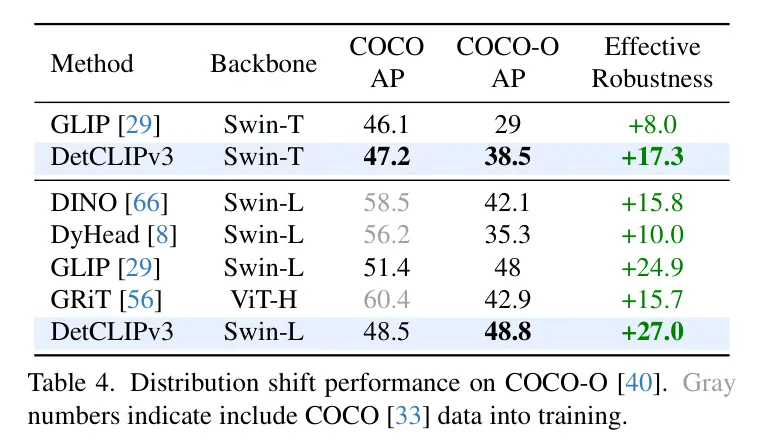
一個健壯的OV目標(biāo)檢測器應(yīng)該能夠在各個領(lǐng)域識別廣泛的視覺概念。最近的視覺-語言模型CLIP [46] 通過學(xué)習(xí)大量的圖像-文本對,在ImageNet變體[19, 20, 54]的域遷移中展示了卓越的泛化能力。同樣,作者期望在OV檢測中觀察到類似的現(xiàn)象。為此,作者使用COCO-O [40] 來研究作者模型對分布變化的魯棒性。表4將作者的方法與幾種領(lǐng)先的閉集檢測器以及開集檢測器GLIP在COCO和COCO-O上進(jìn)行了比較。由于COCO沒有包含在作者的訓(xùn)練中,DetCLIPv3的性能落后于那些專門在它上面訓(xùn)練的檢測器。然而,作者的模型在COCO-O上顯著超過了這些檢測器。例如,作者的Swin-L模型在COCO-O上達(dá)到48.8 AP,甚至超過了它在COCO上的性能(48.5 AP),并獲得了最佳的有效魯棒性分?jǐn)?shù)+27.0。更多定性可視化結(jié)果請參考附錄。
Transfer Results with Fine-tuning
表5探討了通過在下游數(shù)據(jù)集上對DetCLIPv3進(jìn)行微調(diào)來轉(zhuǎn)移其能力,即LVIS minival [24]和ODinW [29]。對于LVIS,考慮了兩種設(shè)置:(1) LVIS:僅使用基礎(chǔ)(常見和頻繁)類別進(jìn)行訓(xùn)練,如[43]中所做;以及(2) LVIS:涉及使用所有類別進(jìn)行訓(xùn)練。
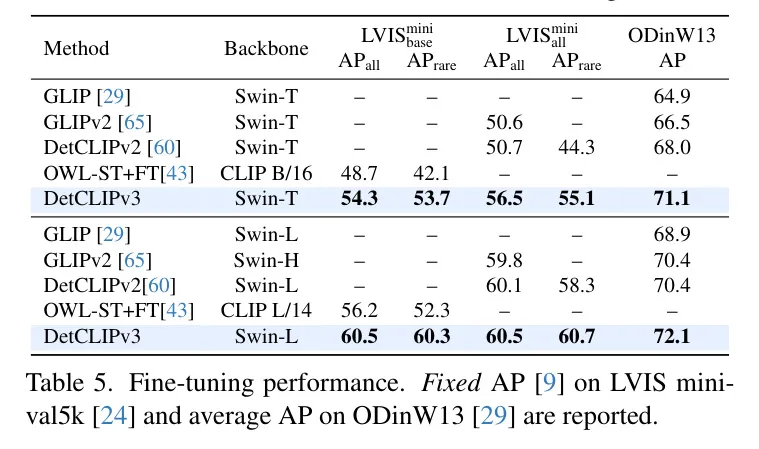
DetCLIPv3在所有設(shè)定中一致地優(yōu)于其同類產(chǎn)品。在ODinW13上,基于Swin-T的DetCLIPv3(71.1 AP)甚至超過了基于Swin-L的DetCLIPv2(70.4 AP)。在LVIS上,DetCLIPv3展示了出色的性能,例如,基于Swin-L的模型在LVIS和LVIS上均達(dá)到了60.5 AP,超過了預(yù)先用20億偽標(biāo)簽數(shù)據(jù)訓(xùn)練的OWL-ST+FT [43](在LVIS上56.2 AP)一大截。這表明作者自動標(biāo)注 Pipeline 構(gòu)建的高質(zhì)量圖像-文本對有效地提升了學(xué)習(xí)效率。此外,作者觀察到與[43]中類似的結(jié)論:在強(qiáng)大的預(yù)訓(xùn)練支持下,即使僅在基礎(chǔ)類別上進(jìn)行微調(diào)也能顯著增強(qiáng)稀有類別的性能。這體現(xiàn)在Swin-L模型從表1第15行的49.8 AP提升到表5的60.3 AP上。
Ablation Study
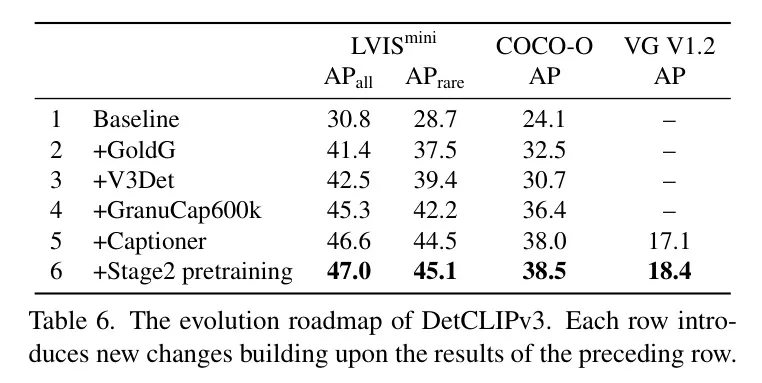
DetCLIPv3的演變路線圖。 表6探討了DetCLIPv3的發(fā)展路線圖,從 Baseline 模型到最終版本。作者的實(shí)驗(yàn)采用了一個帶有Swin-T Backbone 網(wǎng)絡(luò)的模型。對于OV檢測器,作者在LVIS minival(第4.1節(jié))和COCO-O(第4.3節(jié))上評估了AP,對于字幕生成器,作者在VG(第4.2節(jié))上報(bào)告了微調(diào)后的性能。作者的 Baseline (第1行)模型是去除了物體字幕生成器的OV檢測器(如第3.1節(jié)所述),僅在Objects365 [50]上訓(xùn)練。這個模型能力有限,在LVIS上僅取得了30.8 AP的適中成績。隨后,作者引入了一系列有效設(shè)計(jì):(1)融入更多的人工標(biāo)注數(shù)據(jù)(第2行和第3行),即GoldG [24]和V3Det [55],將LVIS AP顯著提升到42.5。(2)引入圖像-文本對數(shù)據(jù),即來自GranuCap50M的60萬樣本(也是作者第3階段訓(xùn)練使用的訓(xùn)練數(shù)據(jù),見第3.3節(jié)),有效將LVIS AP進(jìn)一步改進(jìn)為45.3。更重要的是,它顯著提升了模型的領(lǐng)域泛化能力,將COCO-O的AP從第3行的30.7提升到第4行的36.4。(3) 第5行進(jìn)一步整合了物體字幕生成器,但沒有了第2階段的預(yù)訓(xùn)練。盡管沒有引入新數(shù)據(jù),它還是將LVIS AP提升到46.6。這種改進(jìn)揭示了學(xué)習(xí)字幕生成器對OV檢測的好處——學(xué)習(xí)為物體生成多樣化標(biāo)簽鼓勵了物體解碼器提取更具判別性的物體特征。(4)整合第2階段字幕生成器預(yù)訓(xùn)練高效地從GranuCap50M的大量圖像-文本對中獲取廣泛的視覺概念知識。這種設(shè)計(jì)顯著增強(qiáng)了字幕生成器的生成能力,將VG的AP從第5行的17.1提升到第6行的18.4。此外,它還將OV檢測性能從在LVIS上的46.6 AP適度提升到47.0 AP。
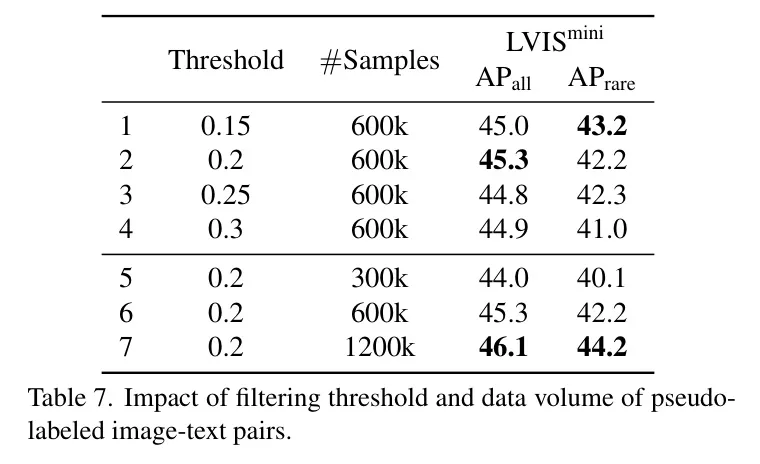
圖像-文本對的偽標(biāo)記。 表7探討了在利用偽標(biāo)記的圖像-文本對時兩個關(guān)鍵因素:過濾閾值和數(shù)據(jù)量。作者在第一階段訓(xùn)練中使用了Swin-T模型,并整合了偽標(biāo)記數(shù)據(jù)。0.2的過濾閾值取得了最佳效果,而數(shù)據(jù)的不斷增加也持續(xù)提高了OV檢測的性能。盡管使用1200k數(shù)據(jù)獲得了更好的結(jié)果,但考慮到效率,作者選擇在第三階段訓(xùn)練中使用600k數(shù)據(jù)。值得注意的是,在生成性任務(wù)中輔助字幕器的學(xué)習(xí)時,600k數(shù)據(jù)樣本的有效性(表6第5行,46.6 AP)超過了沒有字幕器輔助的1200k樣本的結(jié)果(46.1 AP)。
Visualization
圖1展示了DetCLIPv3在OV檢測和目標(biāo)標(biāo)簽生成方面的可視化結(jié)果。作者的模型展現(xiàn)出卓越的視覺理解能力,能夠檢測或生成廣泛的視覺概念。更多可視化結(jié)果請參閱附錄。
5 Limitation and Conclusion
限制。 對DetCLIPv3生成能力的評估尚不完整,因?yàn)楝F(xiàn)有的基準(zhǔn)測試在有效評估生成檢測結(jié)果方面存在不足。此外,DetCLIPv3當(dāng)前的檢測過程不支持通過指令進(jìn)行控制。未來,重要的研究方向?qū)⑹情_發(fā)用于評估生成式開放詞匯檢測器的全面指標(biāo),并將大型語言模型(LLMs)整合到指令控制的開放詞匯檢測中。
結(jié)論。在本文中,作者提出了DetCLIPv3,這是一種創(chuàng)新的OV檢測器,它能夠基于類別名稱定位目標(biāo),并生成具有層次性和多粒度的目標(biāo)標(biāo)簽。這種增強(qiáng)的視覺能力使得更全面的細(xì)粒度視覺理解成為可能,從而擴(kuò)展了OVD模型的應(yīng)用場景。作者希望作者的方法為未來視覺認(rèn)知系統(tǒng)的發(fā)展提供啟發(fā)。
訓(xùn)練。 DetCLIPv3的訓(xùn)練涉及來自各種來源的數(shù)據(jù)。表8匯總了在不同訓(xùn)練階段中使用的數(shù)據(jù)詳細(xì)信息。由于不同數(shù)據(jù)類型的訓(xùn)練過程各不相同(例如,目標(biāo)字幕器只接受圖像-文本對數(shù)據(jù)作為輸入),作者設(shè)計(jì)每個迭代的全局批次僅包含一種類型的數(shù)據(jù)。
對于開放詞匯檢測器的訓(xùn)練,遵循先前的DetCLIP工作[58, 60],作者使用FILIP[59]語言模型的參數(shù)初始化文本編碼器,并在訓(xùn)練過程中將學(xué)習(xí)率降低0.1,以保留通過FILIP預(yù)訓(xùn)練獲得的知識。為了提高訓(xùn)練效率,作者將文本編碼器的最大文本標(biāo)記長度設(shè)置為16。
在訓(xùn)練目標(biāo)描述器時,作者使用Qformer [27]的預(yù)訓(xùn)練權(quán)重來初始化描述器,而可變形[71]交叉注意力層則是隨機(jī)初始化的。為了保留在Qformer [27]預(yù)訓(xùn)練期間獲得的知識,目標(biāo)描述器使用與BERT [10]相同的分詞器來處理文本輸入,這與采用CLIP [46]分詞器的文本編碼器不同。目標(biāo)描述器的最大文本標(biāo)記長度設(shè)置為32。
在每一個訓(xùn)練階段,為了節(jié)省GPU內(nèi)存,采用了自動混合精度[41]和梯度預(yù)訓(xùn)練權(quán)重[6]。表9總結(jié)了每個訓(xùn)練階段的詳細(xì)訓(xùn)練設(shè)置。
推理過程。 DetCLIPv3的OV檢測器的推理過程遵循DINO [66],其中每張圖像的結(jié)果來自于300個具有最高置信度分?jǐn)?shù)的目標(biāo) Query 的預(yù)測。對于在LVIS [18]數(shù)據(jù)集上的固定AP [9]評估,要求整個驗(yàn)證集中的每個類別至少有10,000個預(yù)測。為了確保每張圖像有足夠的預(yù)測數(shù)量,作者采用了類似于GLIP [29]的推理過程。具體來說,在為每個數(shù)據(jù)樣本進(jìn)行推理時,1203個類別被分成31個塊,每個塊的大小為40個類別。作者分別為每個塊進(jìn)行推理,并基于它們的置信度分?jǐn)?shù)保留前300個預(yù)測。
在DetCLIPv3目標(biāo)描述器的推理過程中,正如主論文中所描述的,對于每張圖像,作者使用作者開發(fā)的名詞概念語料庫中最頻繁的15k個概念作為文本 Query ,提取相似度最高的前100個前景區(qū)域。在目標(biāo)描述器為這些區(qū)域生成描述性標(biāo)簽后,使用OV檢測器對其置信度分?jǐn)?shù)進(jìn)行重新校準(zhǔn)。然后對那些重新校準(zhǔn)后分?jǐn)?shù)高于0.05的區(qū)域執(zhí)行一個類無關(guān)的非最大值抑制(NMS)操作,其結(jié)果作為預(yù)測輸出。作者對目標(biāo)描述器的推理設(shè)置了等于1的束搜索(beam search)大小。
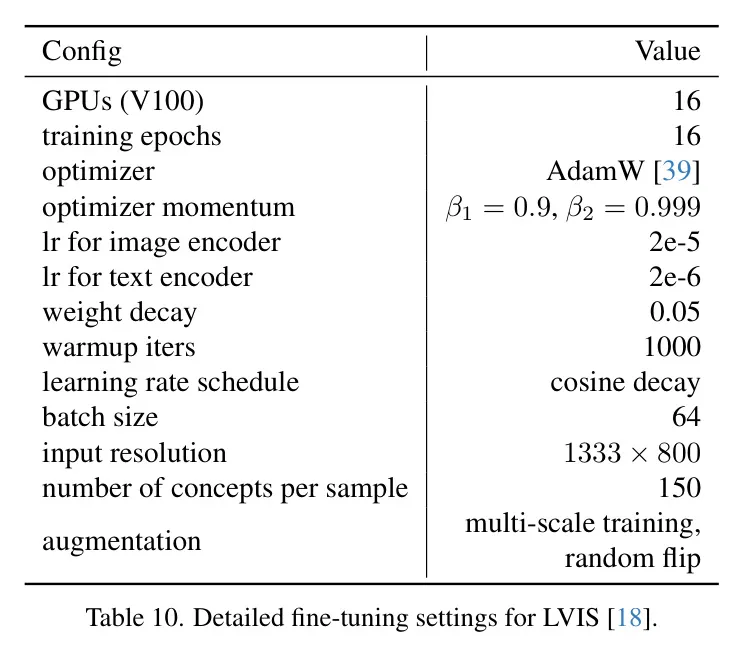
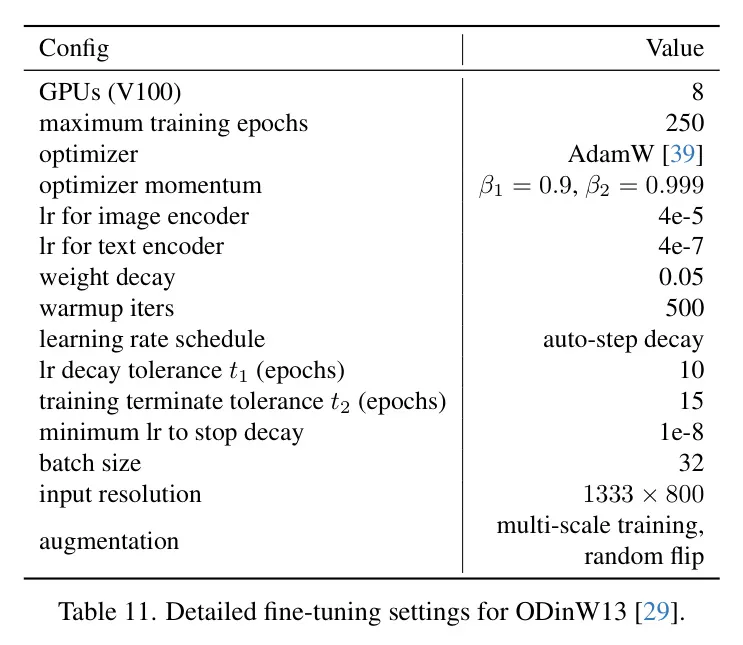
微調(diào)。 作者在兩個數(shù)據(jù)集上對DetCLIPv3進(jìn)行微調(diào),即LVIS [18] 和 ODinW13 [29]。表10和11分別總結(jié)了LVIS和ODinW13的詳細(xì)微調(diào)設(shè)置。對于LVIS,當(dāng)用基礎(chǔ)類別進(jìn)行微調(diào)時,在采樣負(fù)概念時會排除新類別。對于ODinW13,類似于DetCLIPv2[60],作者采用自動衰減的學(xué)習(xí)率計(jì)劃。具體來說,當(dāng)性能達(dá)到平臺期并在容忍期內(nèi)持續(xù)時,作者將學(xué)習(xí)率降低0.1倍。如果在容忍期內(nèi)性能沒有提升,作者則終止訓(xùn)練過程。
Appendix B Additional Data Pipeline Details
圖5展示了DetCLIPv3自動標(biāo)注數(shù)據(jù)流程的概覽。

提示。 在這里,作者提供了每個步驟中使用的提示,包括用于VLLMs以及GPT-4的提示。
使用VLLM重制標(biāo)題:作者采用Instruct-BLIP [7]對240K圖像-文本對進(jìn)行重新配文。為了利用原始標(biāo)題文本中的信息,作者使用以下提示: “給定圖像的噪聲標(biāo)題: {原始標(biāo)題}, _編寫圖像的詳細(xì)清晰描述”。
使用GPT-4進(jìn)行實(shí)體提取:在這一步驟中,作者首先利用GPT-4從VLLM生成的標(biāo)題中過濾掉非實(shí)體描述。使用的提示是:_“這是一張圖片的標(biāo)題:{caption}。提取與圖像中可直接觀察到的事實(shí)描述相關(guān)的部分,同時過濾掉提及推理內(nèi)容、氣氛/外觀/風(fēng)格描述以及歷史/文化/品牌介紹等部分。只返回結(jié)果,不包含其他內(nèi)容。如果你認(rèn)為沒有事實(shí)描述,只需返回'None'。” 隨后,作者使用以下提示從過濾后的標(biāo)題中提取關(guān)于目標(biāo)實(shí)體的信息:_“你是一個AI,負(fù)責(zé)從大量圖像標(biāo)題中開發(fā)一個開集目標(biāo)檢測數(shù)據(jù)集,無法訪問實(shí)際的圖像。你的任務(wù)是按照以下原則準(zhǔn)確地識別和提取這些標(biāo)題中的'目標(biāo)':
- '物體'在物理上是可觸摸的:它們必須是可以在圖像中視覺表示的具體實(shí)體。它們不包括以下內(nèi)容:
- 抽象概念(例如“歷史”、“文化”)或情感(例如“悲傷”、“快樂”)
- 對圖像本身(例如“圖像”、“圖片”、“照片”)或相機(jī)(例如某物正對著“相機(jī)”)的元引用,除非它們專門指圖像中的物理元素。
- 任何描述詞(如“外觀”、“氣氛”、“顏色”)
- 事件/活動及過程(如“游戲”、“演講”、“表演”)和特定事件類型(如“鄉(xiāng)村風(fēng)格婚禮”、“電影節(jié)”)
- 構(gòu)圖方面(如“透視”、“焦點(diǎn)”、“構(gòu)圖”)或視角/看法(如“鳥瞰圖”)。
- 物體在視覺上是獨(dú)特的:它們是獨(dú)立的實(shí)體,可以從其環(huán)境中視覺上隔離開來。它們不包括環(huán)境特征(如“多彩環(huán)境”)和一般的位置/場景描述符(例如,“室內(nèi)場景”,“鄉(xiāng)村設(shè)置”,“晴天”,“黑白插圖”)。在提取過程中遵循以下指南:
- 合并重復(fù)項(xiàng):如果提取的多個“物體”指代字幕中的同一實(shí)體,將它們合并為一個,同時保留概念多樣性。
- 對描述性變體進(jìn)行分類:對于用形容詞描述的“物體”,提供帶形容詞和不帶形容詞的兩個版本。
- 識別更廣泛的類別:為每個“物體”分配一個“父類別”。以下是你結(jié)果的編號列表格式:id. “帶形容詞的物體”, “不帶形容詞的物體”, “父類別”。你的回復(fù)應(yīng)僅包含結(jié)果,不含多余內(nèi)容。以下是字幕:{字幕}。
- 針對大規(guī)模標(biāo)注的VLLM指令調(diào)整:在這個階段,作者使用上面得到的字幕文本和物體實(shí)體信息來微調(diào)LLaVA [35] 模型。在這里,作者將前述信息組合成一個新的簡潔提示,并構(gòu)建如下問題-答案對:_問題:“從圖像的噪聲字幕:{原始字幕},生成一個精煉的圖像描述,并識別所有可見的‘物體’——圖像中任何視覺和物理可識別的實(shí)體。記住以下指南:
- 從字幕中合并相似的‘物體’,保留概念多樣性。
- 對于用形容詞描述的‘物體’,提供帶形容詞和不帶形容詞的兩個版本。
- 為每個‘物體’分配一個‘父類別’。以如下格式呈現(xiàn)結(jié)果:字幕:{字幕} 物體:{id. ‘帶形容詞的物體’,‘不帶形容詞的物體’,‘父類別’}。<圖像標(biāo)記>” 答案:字幕:{精煉的字幕} 物體:{實(shí)體信息} 在這里,VLLM接收圖像標(biāo)記<圖像標(biāo)記>和它們的原始字幕{原始字幕}作為輸入,并學(xué)習(xí)生成精煉的字幕以及提取關(guān)于物體實(shí)體的信息。
可視化。 圖2-a和2-b展示了通過作者提出的數(shù)據(jù)處理流程獲得的細(xì)化標(biāo)題和提取的實(shí)體信息。此外,圖3顯示了在第一階段訓(xùn)練后,作者基于Swin-L的模型生成的邊界框偽標(biāo)簽。
Appendix C More Qualitative Results
圖4-a、4-b和4-c展示了DetCLIPv3的目標(biāo)字幕生成器產(chǎn)生的多粒度目標(biāo)標(biāo)簽的附加定性結(jié)果。在沒有候選類別的情況下,DetCLIPv3的目標(biāo)字幕生成器能夠生成密集、細(xì)粒度、多粒度的目標(biāo)標(biāo)簽,從而促進(jìn)了對圖像的更全面理解。
Appendix D More Experimental Results
表10:針對LVIS [18] 的詳細(xì)微調(diào)設(shè)置。
表11:ODinW13 [29]的詳細(xì)微調(diào)設(shè)置。
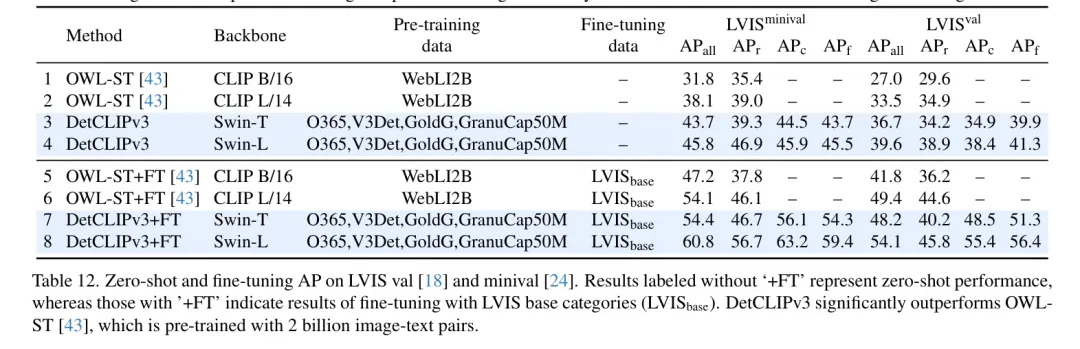
關(guān)于LVIS的更多結(jié)果。 為了全面評估DetCLIPv3的性能,表12提供了在LVIS上的標(biāo)準(zhǔn)平均精度(Average Precision, AP),并將其與在20億圖像-文本對上預(yù)訓(xùn)練的最新方法OWL-ST [43] 進(jìn)行比較。具體來說,作者在LVIS minival [24] 和驗(yàn)證 [18] 數(shù)據(jù)集上評估了兩種設(shè)置:零樣本性能和經(jīng)過在LVIS基礎(chǔ)類別上微調(diào)后的性能。
3 擴(kuò)展實(shí)體
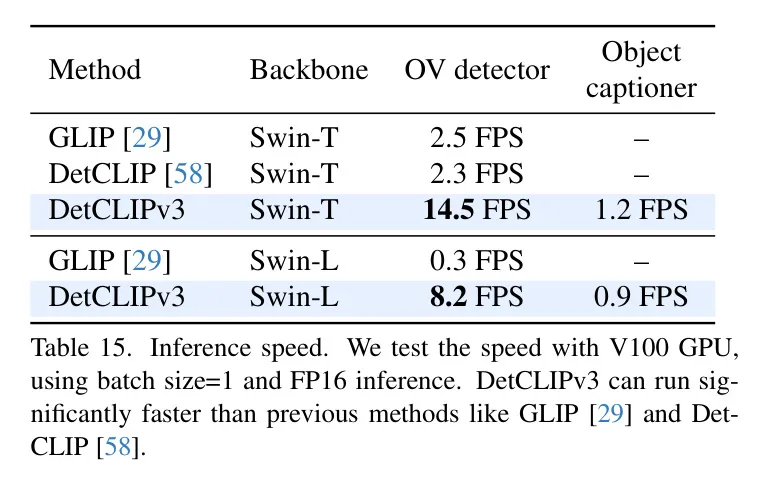
推理速度。 表15報(bào)告了DetCLIPv3的推理速度以及與先前方法的比較。