













終于有人調查了小模型過擬合:三分之二都有數據污染,微軟Phi-3、Mixtral 8x22B被點名
當前最火的大模型,竟然三分之二都存在過擬合問題?
剛剛出爐的一項研究,讓領域內的許多研究者有點意外。

提高大型語言模型的推理能力是當前研究的最重要方向之一,而在這類任務中,近期發布的很多小模型看起來表現不錯,比如微軟 Phi-3、Mistral 8x22B 等等。
但隨后,研究者們指出當前大模型研究領域存在一個關鍵問題:很多研究未能正確地對現有 LLM 的能力進行基準測試。


這是因為目前的大多數研究都采用 GSM8k、MATH、MBPP、HumanEval、SWEBench 等測試集作為基準。由于模型是基于從互聯網抓取的大量數據集進行訓練的,訓練數據集可能無意中包含了與基準測試中的問題高度相似的樣本。
這種污染可能導致模型的推理能力被錯誤評估 —— 它們可能僅僅是在訓練過程中蒙到題了,正好背出了正確答案。
剛剛,Scale AI 的一篇論文對當前最熱門的大模型進行了深度調查,包括 OpenAI 的 GPT-4、Gemini、Claude、Mistral、Llama、Phi、Abdin 等系列下參數量不同的模型。
測試結果證實了一個廣泛的疑慮:許多模型受到了基準數據的污染。

- 論文標題:A Careful Examination of Large Language Model Performance on Grade School Arithmetic
- 論文鏈接:https://arxiv.org/pdf/2405.00332
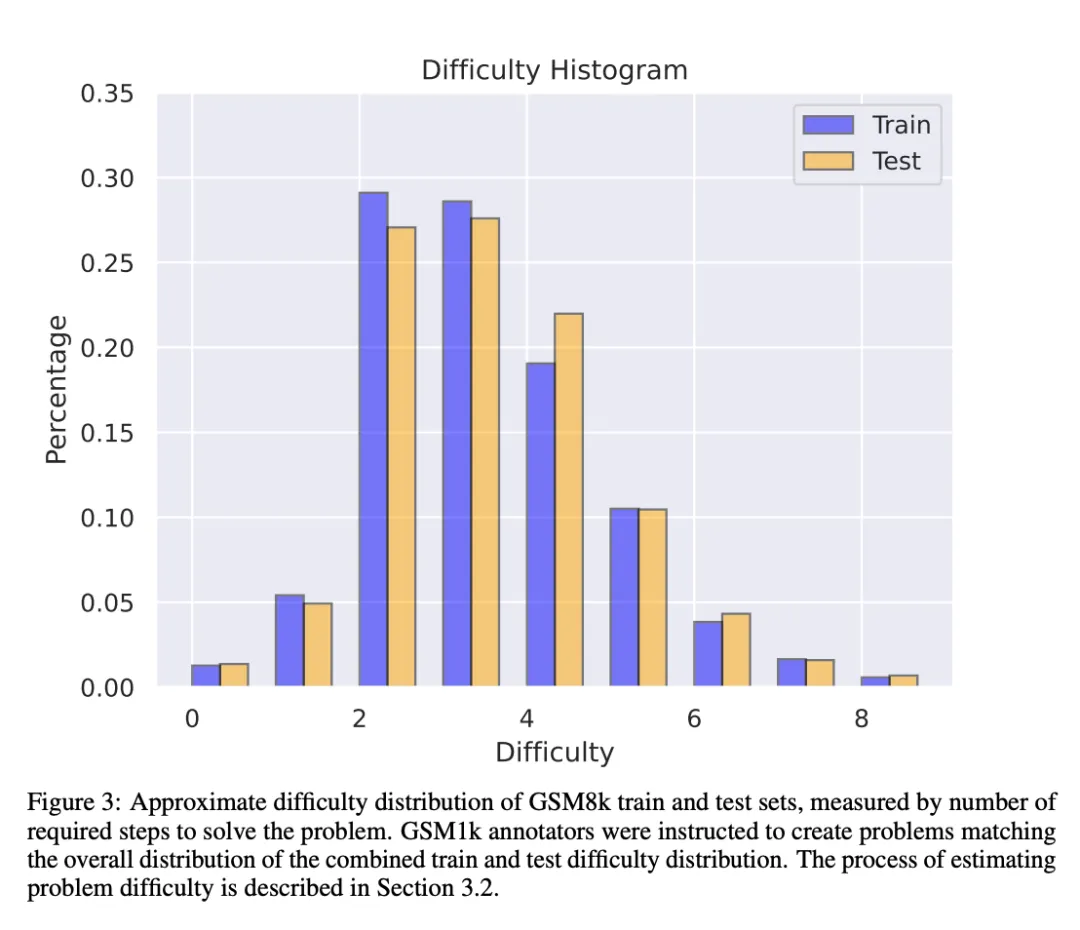
為了避免數據污染問題,來自 Scale AI 的研究者們未使用任何 LLM 或其他合成數據來源,完全依靠人工注釋創建了 GSM1k 數據集。與 GSM8k 相似,GSM1k 內含有 1250 道小學級數學題。為了保證基準測試公平,研究者們盡力確保了 GSM1k 在難度分布上與 GSM8k 是相似的。在 GSM1k 上,研究者對一系列領先的開源和閉源大型語言模型進行了基準測試,結果發現表現最差的模型在 GSM1k 上的性能比在 GSM8k 上低 13%。
尤其是以量小質優聞名的 Mistral 和 Phi 模型系列,根據 GSM1k 的測試結果顯示,幾乎其中的所有版本都顯示出了過擬合的一致證據。

通過進一步分析發現,模型生成 GSM8k 樣本的概率與其在 GSM8k 和 GSM1k 之間的表現差距之間存在正相關關系(相關系數 r^2 = 0.32)。這強烈表明,過擬合的主要原因是模型部分背出了 GSM8k 中的樣本。不過,Gemini、GPT、Claude 以及 Llama2 系列過顯示出的擬合跡象非常少。此外,包括最過擬合的模型在內,所有模型仍能夠成功地泛化到新的小學數學問題,雖然有時的成功率低于其基準數據所示。

Scale AI 目前不打算公開發布 GSM1k,以防未來發生類似的數據污染問題。他們計劃定期對所有主要的開源和閉源 LLM 持續進行評估,還將開源評估代碼,以便后續研究復現論文中的結果。
GSM1k 數據集
GSM1k 內包含 1250 道小學數學題。這些問題只需基本的數學推理即可解決。Scale AI 向每位人工注釋者展示 3 個 GSM8k 的樣本問題,并要求他們提出難度相似的新問題,得到了 GSM1k 數據集。研究者們要求人工注釋者們不使用任何高級數學概念,只能使用基本算術(加法、減法、乘法和除法)來出題。與 GSM8k 一樣,所有題的解都是正整數。在構建 GSM1k 數據集的過程中,也沒有使用任何語言模型。
為了避免 GSM1k 數據集的數據污染問題,Scale AI 目前不會公開發布該數據集,但將開源 GSM1k 評估框架,該框架基于 EleutherAI 的 LM Evaluation Harness。
但 Scale AI 承諾,在以下兩個條件中先達成某一項后,將在 MIT 許可證下發布完整的 GSM1k 數據集:(1) 有三個基于不同預訓練基礎模型譜系的開源模型在 GSM1k 上達到 95% 的準確率;(2) 至 2025 年底。屆時,小學數學很可能不再足以作為評估 LLM 性能的有效基準。
為了評估專有模型,研究者將通過 API 的方式發布數據集。之所以采取這種發布方式,是論文作者們認為,LLM 供應商通常不會使用 API 數據點來訓練模型模型。盡管如此,如果 GSM1k 數據通過 API 泄露了,論文作者還保留了未出現在最終 GSM1k 數據集中的數據點,這些備用數據點將在以上條件達成時隨 GSM1k 一并發布。
他們希望未來的基準測試發布時也能遵循類似的模式 —— 先不公開發布,預先承諾在未來某個日期或滿足某個條件時發布,以防被操縱。
此外,盡管 Scale AI 盡力確保了 GSM8k 和 GSM1k 之間在最大程度上一致。但 GSM8k 的測試集已經公開發布并廣泛地用于模型測試,因此 GSM1k 和 GSM8k 僅是在理想情況下的近似。以下評估結果是 GSM8k 和 GSM1k 的分布并非完全相同的情況下得出的。
評估結果
為了對模型進行評估,研究者使用了 EleutherAI 的 LM Evaluation Harness 分支,并使用了默認設置。GSM8k 和 GSM1k 問題的運行 prompt 相同,都是從 GSM8k 訓練集中隨機抽取 5 個樣本,這也是該領域的標準配置(完整的 prompt 信息見附錄 B)。
所有開源模型都在溫度為 0 時進行評估,以保證可重復性。LM 評估工具包提取響應中的最后一個數字答案,并將其與正確答案進行比較。因此,以與樣本不符的格式生成「正確」答案的模型響應將被標記為不正確。
對于開源模型,如果模型與庫兼容,會使用 vLLM 來加速模型推斷,否則默認使用標準 HuggingFace 庫進行推理。閉源模型通過 LiteLLM 庫進行查詢,該庫統一了所有已評估專有模型的 API 調用格式。所有 API 模型結果均來自 2024 年 4 月 16 日至 4 月 28 日期間的查詢,并使用默認設置。
在評估的模型方面,研究者是根據受歡迎程度選擇的,此外還評估了幾個在 OpenLLMLeaderboard 上排名靠前但鮮為人知的模型。
有趣的是,研究者在這個過程中發現了古德哈特定律(Goodhart's law)的證據:許多模型在 GSM1k 上的表現比 GSM8k 差很多,這表明它們主要是在迎合 GSM8k 基準,而不是在真正提高模型推理能力。所有模型的性能見下圖附錄 D。
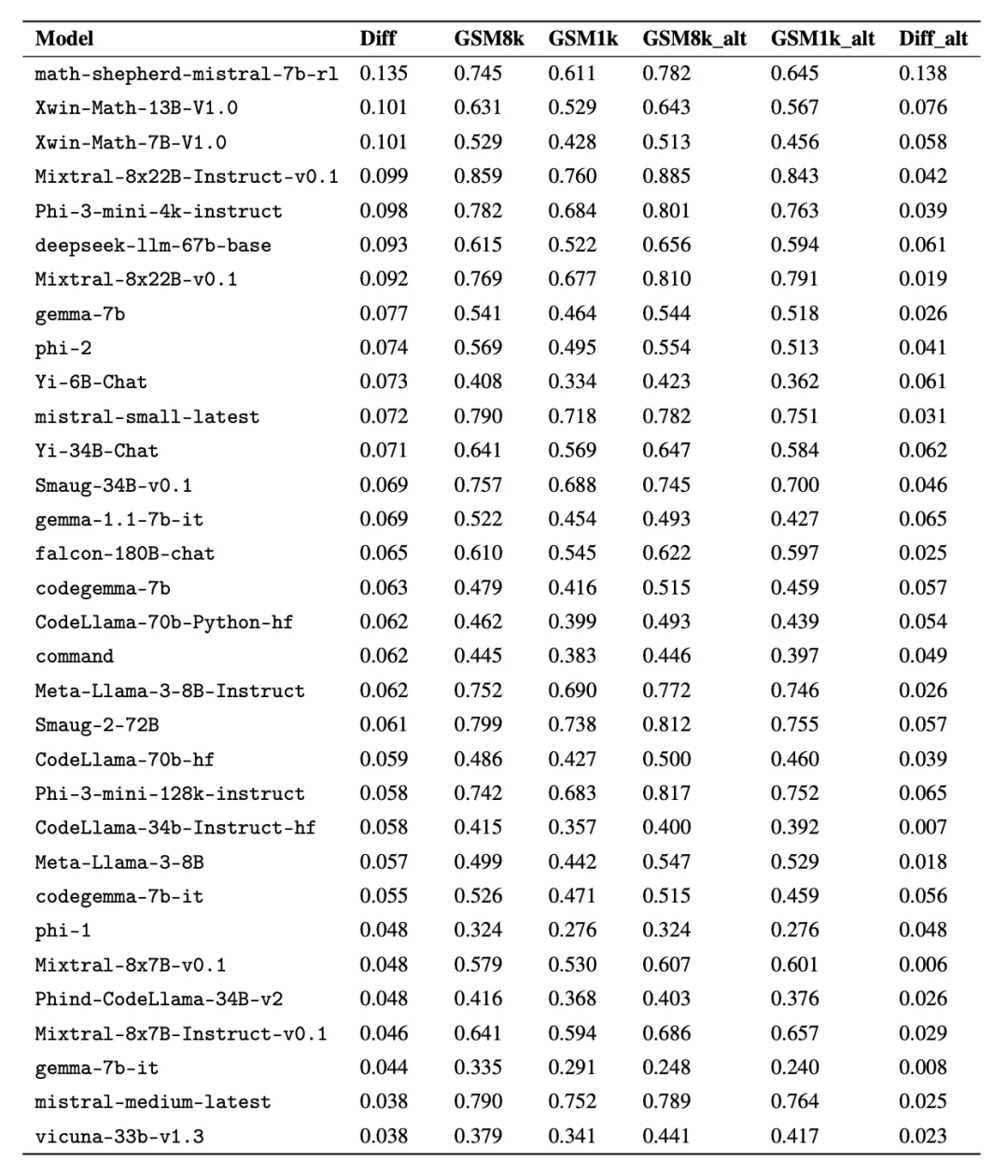
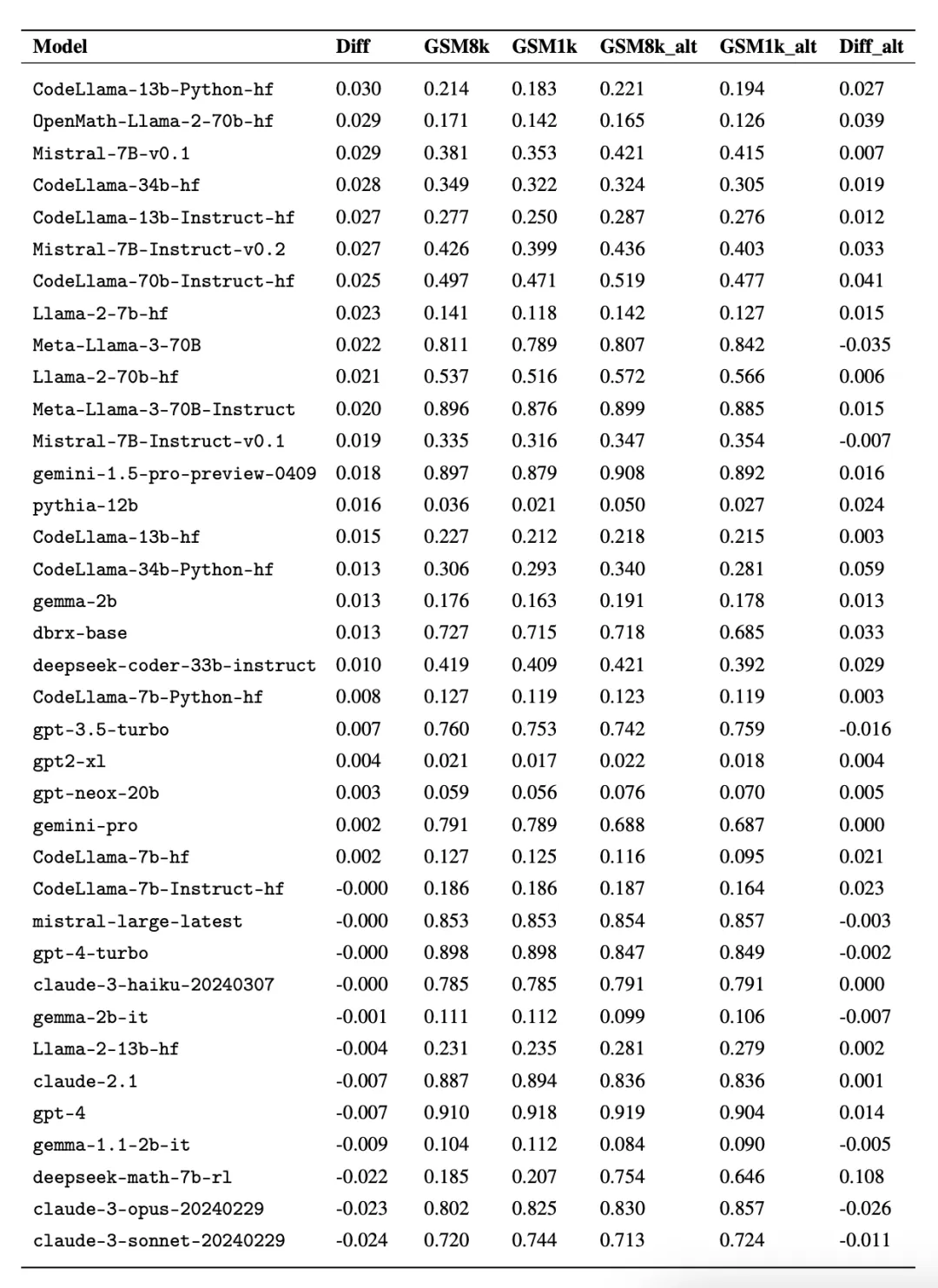
為了進行公平對比,研究者按照模型在 GSM8k 上的表現對它們進行了劃分,并與其他表現類似的模型進行了對比(圖 5、圖 6、圖 7)。

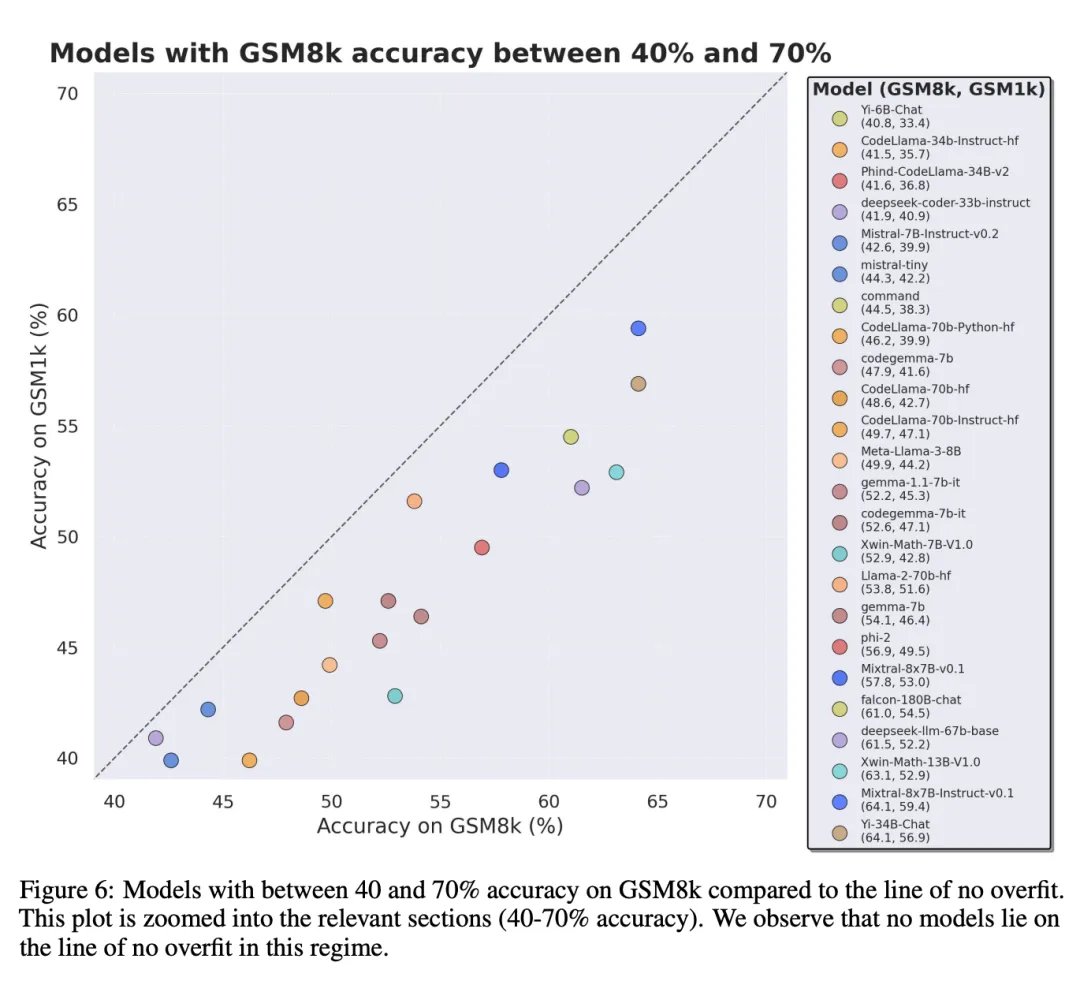

得出了哪些結論?
盡管研究者提供了多個模型的客觀評估結果,但同時表示,解釋評估結果就像對夢境的解釋一樣,往往是一項非常主觀的工作。在論文的最后一部分,他們以更主觀的方式闡述了上述評估的四個啟示:
結論 1: 一些模型系列是系統性過擬合
雖然通常很難從單一數據點或模型版本中得出結論,但檢查模型系列并觀察過擬合模式,可以做出更明確的陳述。一些模型系列,包括 Phi 和 Mistral,幾乎每一個模型版本和規模都顯示出在 GSM8k 上比 GSM1k 表現更強的系統趨勢。還有其他模型系列,如 Yi、Xwin、Gemma 和 CodeLlama 也在較小程度上顯示出這種模式。
結論 2: 其他模型,尤其是前沿模型,沒有表現出過擬合的跡象
許多模型在所有性能區域都顯示出很小的過擬合跡象,特別是包括專有 Mistral Large 在內的所有前沿或接近前沿的模型,在 GSM8k 和 GSM1k 上的表現似乎相似。對此,研究者提出了兩個可能的假設:1)前沿模型具有足夠先進的推理能力,因此即使它們的訓練集中已經出現過 GSM8k 問題,它們也能泛化到新的問題上;2)前沿模型的構建者可能對數據污染更為謹慎。
雖然不能查看每個模型的訓練集,也無法確定這些假設,但支持前者的一個證據是,Mistral Large 是 Mistral 系列中唯一沒有過擬合跡象的模型。Mistral 只確保其最大模型不受數據污染的假設似乎不太可能,因此研究者傾向于足夠強大的 LLM 也會在訓練過程中學習基本的推理能力。如果一個模型學會了足夠強的推理能力來解決給定難度的問題,那么即使 GSM8k 出現在其訓練集中,它也能夠泛化到新的問題上。
結論 3: 過擬合的模型仍然具有推理能力
很多研究者對模型過擬合的一種擔心是,模型無法進行推理,而只是記憶訓練數據中的答案,但本論文的結果并不支持這一假設。模型過擬合的事實并不意味著它的推理能力很差,而僅僅意味著它沒有基準所顯示的那么好。事實上,研究者發現許多過擬合模型仍然能夠推理和解決新問題。例如,Phi-3 在 GSM8k 和 GSM1k 之間的準確率幾乎下降了 10%,但它仍能正確解決 68% 以上的 GSM1k 問題 —— 這些問題肯定沒有出現在它的訓練分布中。這一表現與 dbrx-instruct 等更大型的模型相似,而后者包含的參數數量幾乎是它們的 35 倍。同樣地,即使考慮到過度擬合的因素,Mistral 模型仍然是最強的開源模型之一。這為本文結論提供了更多證據,即足夠強大的模型可以學習基本推理,即使基準數據意外泄漏到訓練分布中,大多數過擬合模型也可能出現這種情況。
結論 4: 數據污染可能不是過擬合的完整解釋
一個先驗的、自然的假設是,造成過擬合的主要原因是數據污染,例如,在創建模型的預訓練或指令微調部分,測試集被泄露了。以往的研究表明,模型會對其在訓練過程中見過的數據賦予更高的對數似然性(Carlini et al. [2023])。研究者通過測量模型從 GSM8k 測試集中生成樣本的概率,并將其與 GSM8k 和 GSM1k 相比的過擬合程度進行比較,來驗證數據污染是造成過擬合的原因這一假設。

研究者表示,數據污染可能并不是全部原因。他們通過幾個異常值觀察到了這一點。仔細研究這些異常值可以發現,每個字符對數似然值最低的模型(Mixtral-8x22b)和每個字符對數似然值最高的模型(Mixtral-8x22b-Instruct)不僅是同一模型的變體,而且具有相似的過擬合程度。更有趣的是,過擬合程度最高的模型(Math-Shepherd-Mistral-7B-RL (Yu et al. [2023]))的每個字符對數似然值相對較低(Math Shepherd 使用合成數據在流程級數據上訓練獎勵模型)。
因此,研究者假設獎勵建模過程可能泄露了有關 GSM8k 的正確推理鏈的信息,即使這些問題本身從未出現在數據集中。最后他們發現, Llema 模型具有高對數似然和最小過擬合。由于這些模型是開源的,其訓練數據也是已知的,因此正如 Llema 論文中所述,訓練語料庫中出現了幾個 GSM8k 問題實例。不過,作者發現這幾個實例并沒有導致嚴重的過擬合。這些異常值的存在表明,GSM8k 上的過擬合并非純粹是由于數據污染造成的,而可能是通過其他間接方式造成的,例如模型構建者收集了與基準性質相似的數據作為訓練數據,或者根據基準上的表現選擇最終模型檢查點,即使模型本身可能在訓練的任何時候都沒有看到過 GSM8k 數據集。反之亦然:少量的數據污染并不一定會導致過擬合。
更多研究細節,可參考原論文。

















