算法在 58 畫像平臺建設中的應用

一、58 畫像平臺建設背景
首先和大家分享下 58 畫像平臺的建設背景。
1. 傳統的畫像平臺

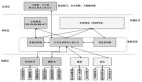
傳統的思路來看,建設用戶畫像平臺依賴數倉建模能力,整合多業務線數據,構建準確的用戶畫像;還需要數據挖掘,理解用戶行為、興趣和需求,提供算法側的能力;最后,還需具備數據平臺能力,高效存儲、查詢和共享用戶畫像數據,提供畫像服務。業務自建畫像平臺和中臺類型畫像平臺主要區別在于,業務自建畫像平臺服務單條業務線,按需定制;中臺平臺服務多條業務線,建模復雜,提供更為通用的能力。
2. 58 中臺畫像建設的背景

58 的用戶畫像平臺建設主要源于以下幾種業務需求:
- 個性化推薦:業務方需要基于用戶畫像做千人千面的內容分發。
- 精細化運營:產品運營需要畫像平臺提供人群洞察、人群圈選等功能對不同人群做更精細的運營活動。
- 用戶價值增長:粗放式流量增長已經過去,如何利用畫像平臺做好存量用戶價值增長是相當迫切的需求。
3. 萬象

在當前業務需求和外部環境挑戰下,我們提出了 UA+CDP+MA 這一套用戶畫像平臺解決方案。通過 OneID 服務構建用戶畫像基礎數據,結合流量和人群洞察,利用算法智能生成人群,并匹配物料進行精準營銷。同時監測效果并回收數據,優化策略迭代人群。為業務方提供智能化增長解決方案,實現精準運營和業務增長。
二、算法在 58 畫像平臺建設中的作用

算法側在 58 用戶畫像平臺的建設主要包括兩個方面,一個是標簽體系的建設,另一個是平臺能力的構建。
1. 標簽體系的建設
萬象標簽體系包含社會屬性、地理位置、行為習慣、偏好屬性、用戶分層等多個分類,一共有 1500 余個標簽。我們根據生產方式分為兩種類型:
- 事實類標簽:數倉同學利用統計或者規則,通過 SQL 等開發生產。
- 算法類標簽:算法團隊通過數據挖掘等手段加工生產。
2. 算法類標簽舉例

算法類標簽可根據數據源和粒度分類。如性別、年齡、業務傾向等標簽,數據源一般為結構化數據,常作為分類任務處理,模型可選用 XGBoost、DeepFM 等。還有租房目的標簽,需要從用戶瀏覽的帖子文本中識別用戶目的,這類標簽數據源為非結構化數據,可以用文本分類等方式處理。在我們的內容偏好標簽中,如用戶在不同業務的帖子偏好 topN,則需要構建離線的推薦流程生產這類標簽。
3. 以內容偏好標簽為例解釋標簽的流程

以內容類偏好標簽為例,生產該標簽需建立離線推薦流程。面對百萬甚至更多的帖子,我們首先通過召回階段進行初步篩選,采用熱門、規則、協同過濾等方法,如圖卷積神經網絡(LightGCN)和雙塔(DSSM)模型等。然后,基于召回的帖子,利用 Pointwise 方式通過 CTR 模型進行排序。最終產出用戶最感興趣的 Top N 帖子。在實際應用中,以 push 場景為例,可以從 Top 1 帖子中提取關鍵屬性,生成個性化文案。同時,落地頁可以是 Top 1 帖子的詳情頁或 Top N 帖子的列表頁。

在生產內容偏好類標簽時,考慮到 58 同城業務的地域和類目特性,用戶在推薦中通常只對特定地域或類目的帖子感興趣。因此,在向量化召回(如使用 EGES 模型)時,可能會出現大量異地或非本類目的帖子。為解決這一問題,我們將城市信息以 16 進制表示,將 0 替換為 -1,然后將此編碼直接拼接到之前生成的向量中,這樣做可以確保同城市或同類目的帖子在相似度計算中具有最大相似性,從而提高召回和推薦的準確性。
在排序階段,利用多模態信息,包括文本內容,以提升推薦的準確性。例如帖子標題作為文本特征,可以采用 BERT、M3E 等預訓練模型進行 embedding 表示。然而,由于帖子數量龐大,這對計算資源構成了挑戰。為解決這一問題,我們采用了 Spark NLP,這是一個基于 Apache Spark Machine Learning 的自然語言處理庫。盡管原生庫中沒有中文的 BERT 模型,但通過一些轉換,我們成功地將其應用于大規模離線推理。

在 58 同城用戶畫像平臺的功能建設中,算法同樣發揮著核心作用。以智能運營能力為例,我們利用流量地圖識別不同業務之間的相關性,為業務方提供運營建議或結論。業務方可以根據這些建議直接通過智能圈人功能生成運營人群包,并對接到相應渠道進行投放。投放效果可以通過平臺進行監測,并根據效果數據進行迭代優化,從而不斷提升運營效果。

算法是如何發揮作用的呢?接下來分幾個環節來介紹。首先是流量地圖這一塊。我們利用 OLAP 數據挖掘和數據可視化技術,深入分析 58APP 用戶在不同業務之間的瀏覽情況。通過分析和加工這些數據,可以展示出用戶在不同業務之間的流轉路徑,為運營團隊提供直觀的用戶行為視圖。在這個過程中,算法不僅可以幫助我們識別出用戶的行為模式,還可以通過關聯分析等技術,挖掘出不同業務之間的相關性。這些相關性為我們提供了寶貴的運營建議,支持運營團隊進行交叉運營。

在得到運營建議后,運營團隊可以通過智能圈人功能來圈選目標人群。為了實現這一目標,運營團隊需要首先配置個性化運營目標,明確目標是拉新、促活還是促轉等。接著,需要設定期望達到的效果,包括人群包的大小和預期的投放效果等。此外,運營團隊還需要選擇適合的投放渠道,以確保目標人群能夠接收到相關的運營活動信息。

生成人群包的過程對于運營團隊來說是一個黑盒。為了解決這個問題,我們提供了更多關于算法原理和步驟的解釋和說明,以便運營團隊更好地理解和應用該技術。同時,我們提供了更多的可視化工具和界面,幫助運營團隊直觀地查看和分析人群包的特征和效果。
在生成人群包的過程中,我們主要采用了 Look-alike 技術。在該技術的演進上,我們經歷了幾個階段,前期借鑒 Yahoo 的方案,將人群包的產出分為召回和排序模塊。召回模塊,首先構建所有用戶的特征向量,然后采用 minHash 和局部敏感哈希技術進行特征向量的壓縮,并通過類似聚類分桶的方法實現了近似于 k-NN 的檢索,快速計算種子用戶與候選人群之間的兩兩相似度,選取 topN 作為每個種子用戶的召回人群。在排序階段,首先使用 Information Value 進行特征篩選,然后基于篩選后的特征計算分值,最后根據分值進行排序,最終產出人群包。整個過程中,算法起到了關鍵作用,確保了人群包的準確性和有效性。

除了基于相似度的方案,同樣基于機器學習的方式也有不錯的效果。在實際應用中,用戶可以通過場景圈人或種子人群上傳兩種方式發起請求。區別在于種子人群由用戶上傳還是我們自動挖掘。在拿到種子人群,也就是正樣本后,我們需要選擇負樣本,可以暴力的全局隨機負采樣,也可以用 PU learning 或者 TSA 等算法完成負樣本的選取。接下來是特征選擇階段,分為兩種方案,一種是提前預制人工挑選的特征,經過固定的特征工程,可以使用 DeepFM 等模型完成訓練和 CTR 的預估,根據 CTR 選擇 TopN 作為人群包;還有一種方案是我們使用全量的標簽作為特征,通過 IV 值和相關性自動化挑選和剔除特征,然后使用 AutoML 框架完成特征工程、模型訓練,最后對 58App 的人群池進行推理,并根據 TopN 產出人群包,對接到渠道進行觸達,最后回收投放效果數據來完成樣本選擇迭代。
上述方案有一些值得關注的點,首先是樣本的迭代,回收效果數據時,不僅需要對曝光數據進行篩選,同時需要對未曝光數據,也就是 Exposure Bias 做 Debias 處理。同時迭代后的效果需要離線評估驗證,保證迭代的效果。此外,特征方面也需要考慮穿越問題,特別是拉新場景,需要考慮特征選擇的時間因素。

隨著在運營場景中積累的數據越來越多,我們開始嘗試利用這些數據進行離線實驗,以優化我們的迭代方案。其中之一就是基于騰訊微信的 Look-alike 方式,它采用元學習的方法。具體來說,這種方法通過構建一個泛化模型,在離線階段完成模型的構建,然后在在線階段利用少量的數據集進行定制化模型的訓練,并進行推理工作。這種方式能夠解決樣本量相對較少時,模型容易出現過擬合的問題。多場景多目標的人群擴散,也是我們下一步迭代的方向之一。
三、58 畫像平臺應用案例
1. 個性化資源位投放
個性化資源位的投放,在 58App 資源位包含開屏、banner 位、浮窗、fees 流卡片等等,都有用到 58 用戶畫像平臺相應的功能,比如用價運營通過畫像平臺的標簽圈選能力去產出人群包為其推送特定的內容,完成千人千面的精細化運營。
2. 個性化 push 推送
我們的畫像平臺與 58 的 push 平臺也完全打通,運營同學可以通過萬象圈選或者 Look-alike 等形式創建人群,配置個性化文案,通過 push 觸達用戶,達成運營目的。
3. 搜索推薦
搜索推薦是基于用戶畫像最常見的應用。58 新車、二手車這兩個業務方沒有算法人員,但是又想做一些個性化的應用,因此接入了前文中提到的內容偏好類標簽。首頁的新車推薦,相關推薦等資源位都用到了內容偏好 TopN 標簽。在二手車的搜索位置上,搜索框的提示語以及搜索發現頁的相關車系也用到了這一標簽。相比于之前通過規則的方式,通過接入內容偏好標簽作為項目初期的解決方案,也取得了很好的效果。
四、展望與總結
當前 58 的畫像平臺已經具備了業界通用的畫像平臺能力,并且通過算法加持,實現了智能運營等能力。不僅提升了業務方運營效果,在為用戶提供個性化服務的同時也帶來了更好的用戶體驗。接下來,還將與業務方深度合作,探索更多的應用場景,在合作的過程當中進行總結和提煉、優化與創新,升級技術以應對各種需求和挑戰,我們期待為用戶和企業創造更大的價值。