Kafka六大使用場景以及核心概念,你知道幾個?
1. 為什么介紹Kafka
1.高吞吐量:單機(jī)每秒處理十萬級的消息量。即使存儲了許多TB的消息,它也保持穩(wěn)定的性能。
2.高性能:單節(jié)點(diǎn)支持上千個客戶端,并保證零停機(jī)和零數(shù)據(jù)丟失。
- 利用Linux的頁緩存
- 順序讀,順序?qū)?/li>
- 零拷貝
3.持久化數(shù)據(jù)存儲:將消息持久化到磁盤。通過將數(shù)據(jù)持久化到硬盤以及replication防止數(shù)據(jù)丟失。
4.分布式系統(tǒng): 易于向外擴(kuò)展。所有的Producer、Broker和Consumer都會有多個,均為分布式的。無需停機(jī)即可擴(kuò)展機(jī)器。多個Producer、Consumer可能是不同的應(yīng)用。
5.可靠性: Kafka是分布式,分區(qū),復(fù)制和容錯的。
6.客戶端狀態(tài)維護(hù):消息被處理的狀態(tài)是在Consumer端維護(hù),而不是由server端維護(hù)。當(dāng)失敗時(shí)能自動平衡。
7.支持online和offline的場景。
8.支持多種客戶端語言。Kafka支持Java、.NET、PHP、Python等多種語言。
2. Kafka應(yīng)用場景
2.1. 消息隊(duì)列
Kafka 最常見的應(yīng)用場景就是作為消息隊(duì)列。 Kafka 提供了一個可靠且可擴(kuò)展的消息隊(duì)列,可以處理大量數(shù)據(jù)。
Kafka 可以實(shí)現(xiàn)不同系統(tǒng)間的解耦和異步通信,如訂單系統(tǒng)、支付系統(tǒng)、庫存系統(tǒng)等。在這個基礎(chǔ)上 Kafka 還可以緩存消息,提高系統(tǒng)的可靠性和可用性,并且可以支持多種消費(fèi)模式,如點(diǎn)對點(diǎn)或發(fā)布訂閱。
2.2. 日志處理與分析(最常用的場景)
公司可以用Kafka可以收集各種服務(wù)的Log,典型就是 ELK(Elastic-Logstash-Kibana)。Kafka 有效地從每個實(shí)例收集日志流。
 圖片
圖片
2.3. 推薦數(shù)據(jù)流
流式處理是 Kafka 在大數(shù)據(jù)領(lǐng)域的重要應(yīng)用場景之一,其與流處理框架(如Spark Streaming、Storm、Flink等)框架進(jìn)行集成。主要內(nèi)容包括:
Kafka作為流式處理平臺的數(shù)據(jù)源或數(shù)據(jù)輸出:Kafka可以作為流數(shù)據(jù)的中介,將實(shí)時(shí)數(shù)據(jù)發(fā)送到Kafka中,同時(shí)也可以從Kafka中讀取數(shù)據(jù)進(jìn)行處理和分析。 推薦系統(tǒng)的工作流程:以淘寶、京東等線上商城網(wǎng)站的推薦系統(tǒng)為例,描述了推薦系統(tǒng)的工作流程。主要包括:
- 將用戶的點(diǎn)擊流數(shù)據(jù)發(fā)送到Kafka中。
- 使用Flink等流處理框架讀取Kafka中的流數(shù)據(jù),進(jìn)行實(shí)時(shí)聚合處理。
- 機(jī)器學(xué)習(xí)算法使用來自數(shù)據(jù)湖的聚合數(shù)據(jù)進(jìn)行訓(xùn)練,同時(shí)算法工程師也會對推薦模型進(jìn)行調(diào)整。
- 推薦系統(tǒng)持續(xù)改進(jìn)對每個用戶的推薦相關(guān)性。
 圖片
圖片
2.4. 系統(tǒng)監(jiān)控與報(bào)警
與日志分析系統(tǒng)類似,我們需要收集系統(tǒng)指標(biāo)以進(jìn)行監(jiān)控和故障排除。不同之處在于,指標(biāo)是結(jié)構(gòu)化數(shù)據(jù),而日志是非結(jié)構(gòu)化文本。指標(biāo)數(shù)據(jù)被發(fā)送到 Kafka 中,并在 Flink 中進(jìn)行聚合。下圖展示了常見監(jiān)控報(bào)警系統(tǒng)的工作流程:
- 采集器讀取購物車指標(biāo)發(fā)送到 Kafka 中
- Flink 讀取 Kafka 中的指標(biāo)數(shù)據(jù)進(jìn)行聚合處理
- 實(shí)時(shí)監(jiān)控系統(tǒng)和報(bào)警系統(tǒng)讀取聚合數(shù)據(jù)作展示以及報(bào)警處理
 圖片
圖片
2.5. CDC(數(shù)據(jù)變更捕獲)
CDC(Change data capture) 將數(shù)據(jù)庫更改流式傳輸?shù)狡渌到y(tǒng),以便進(jìn)行復(fù)制或緩存/索引更新。例如,在下圖中,事務(wù)日志被發(fā)送到 Kafka,并由 ElasticSearch、Redis 和輔助數(shù)據(jù)庫引入。
 圖片
圖片
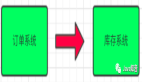
2.6. 系統(tǒng)遷移
Kafka 可以用來作為老系統(tǒng)升級到新系統(tǒng)過程中的消息傳遞中間件(Kafka),以此來降低遷移風(fēng)險(xiǎn)。 在下圖中,為了升級下圖中的訂單服務(wù),我們更新了舊版訂單服務(wù),以使用 Kafka 的輸入并將結(jié)果寫入 ORDER 主題。新的訂單服務(wù)使用相同的輸入,并將結(jié)果寫入 ORDERNEW 主題,對帳服務(wù)比較 ORDER 和 ORDERNEW。如果它們相同,則新服務(wù)通過測試。
 圖片
圖片
3. Kafka核心概念
3.1. 生產(chǎn)者(Producer)
生產(chǎn)者: 創(chuàng)建消息,將消息發(fā)布到Kafka的topic中。broker接收到生產(chǎn)者發(fā)送的消息后,broker將該消息追加到當(dāng)前用于追加數(shù)據(jù)的 segment 文件中 一般情況下,一個消息會被發(fā)布到一個特定的主題上。
- 默認(rèn)情況下通過輪詢把消息均衡地分布到主題的所有分區(qū)上。
- 在某些情況下,生產(chǎn)者會把消息直接寫到指定的分區(qū)。這通常是通過消息鍵和分區(qū)器來實(shí)現(xiàn)的,分區(qū)器為鍵生成一個散列值,并將其映射到指定的分區(qū)上。這樣可以保證包含同一個鍵的消息會被寫到同一個分區(qū)上。
- 生產(chǎn)者也可以使用自定義的分區(qū)器,根據(jù)不同的業(yè)務(wù)規(guī)則將消息映射到分區(qū)。
3.2. 消費(fèi)者(Consumer)
消費(fèi)者讀取消息。
- 消費(fèi)者訂閱一個或多個主題,并按照消息生成的順序讀取它們。
- 消費(fèi)者通過檢查消息的偏移量來區(qū)分已經(jīng)讀取過的消息。偏移量是另一種元數(shù)據(jù),它是一個不斷遞增的整數(shù)值,在創(chuàng)建消息時(shí),Kafka 會把它添加到消息里。在給定的分區(qū)里,每個消息的偏移量都是唯一的。消費(fèi)者把每個分區(qū)最后讀取的消息偏移量保存在Zookeeper 或Kafka上,如果消費(fèi)者關(guān)閉或重啟,它的讀取狀態(tài)不會丟失。
- 消費(fèi)者是消費(fèi)組的一部分。群組保證每個分區(qū)只能被一個消費(fèi)者使用。
- 如果一個消費(fèi)者失效,消費(fèi)組里的其他消費(fèi)者可以接管失效消費(fèi)者的工作,再平衡,分區(qū)重新分配。
3.3. Broker
一個獨(dú)立的Kafka 服務(wù)器被稱為broker。
broker 為消費(fèi)者提供服務(wù),對讀取分區(qū)的請求作出響應(yīng),返回已經(jīng)提交到磁盤上的消息。
- 如果某topic有N個partition,集群有N個broker,那么每個broker存儲該topic的一個partition。
- 如果某topic有N個partition,集群有(N+M)個broker,那么其中有N個broker存儲該topic的一個partition,剩下的M個broker不存儲該topic的partition數(shù)據(jù)。
- 如果某topic有N個partition,集群中broker數(shù)目少于N個,那么一個broker存儲該topic的一個或多個partition。在實(shí)際生產(chǎn)環(huán)境中,盡量避免這種情況的發(fā)生,這種情況容易導(dǎo)致Kafka集群數(shù)據(jù)不均衡。
broker 是集群的組成部分。每個集群都有一個broker 同時(shí)充當(dāng)了集群控制器的角色(自動從集群的活躍成員中選舉出來)控制器負(fù)責(zé)管理工作,包括將分區(qū)分配給broker 和監(jiān)控broker 在集群中,一個分區(qū)從屬于一個broker,該broker 被稱為分區(qū)的首領(lǐng)。
 圖片
圖片
3.4. Topic
每條發(fā)布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。
物理上不同Topic的消息分開存儲。
Topic就好比數(shù)據(jù)庫的表,尤其是分庫分表之后的邏輯表。
3.5. 分區(qū)(Partition)
- Topic可以被分為若干個分區(qū),一個分區(qū)就是一個提交日志
- 消息以追加方式寫入分區(qū),然后以先入先出的順序讀取
- 無法在整個主題范圍內(nèi)保證消息的順序,但可以保證消息在單個分區(qū)內(nèi)的順序
- Kafka 通過分區(qū)來實(shí)現(xiàn)數(shù)據(jù)冗余和伸縮性
- 在需要嚴(yán)格保證消息的消費(fèi)順序的場景下,需要將partition數(shù)目設(shè)為1
 圖片
圖片