系統設計:隨用戶擴展的策略
單服務器設置
在單服務器設置中,所有內容都運行在一臺服務器上。這包括網頁應用程序、數據庫、緩存等。
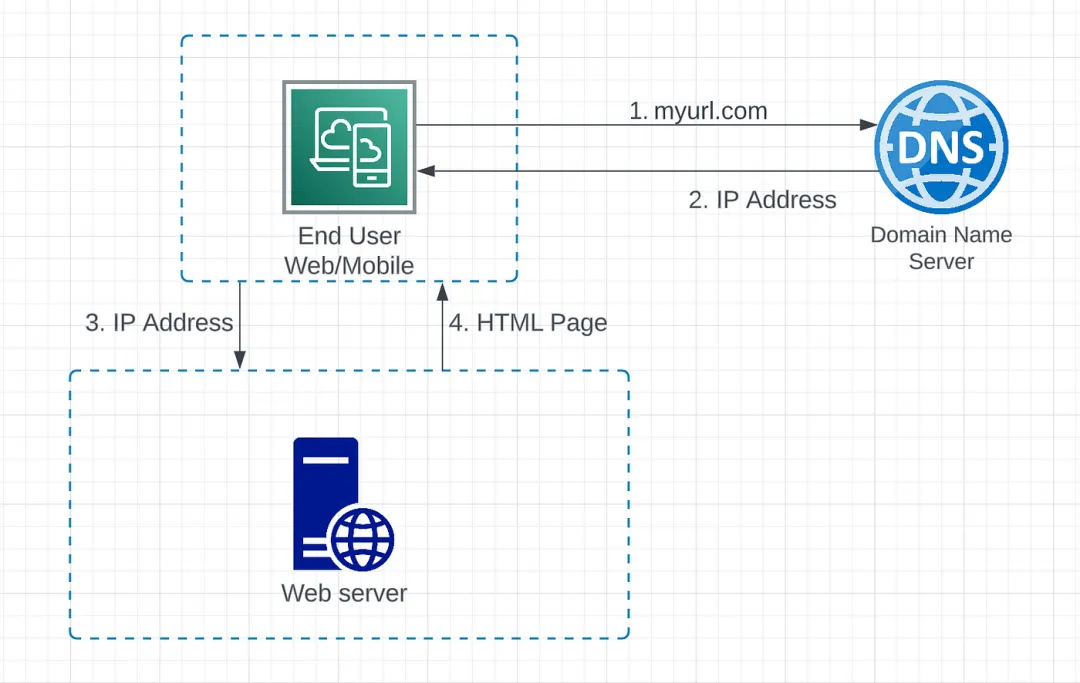
圖1.1 請求流程
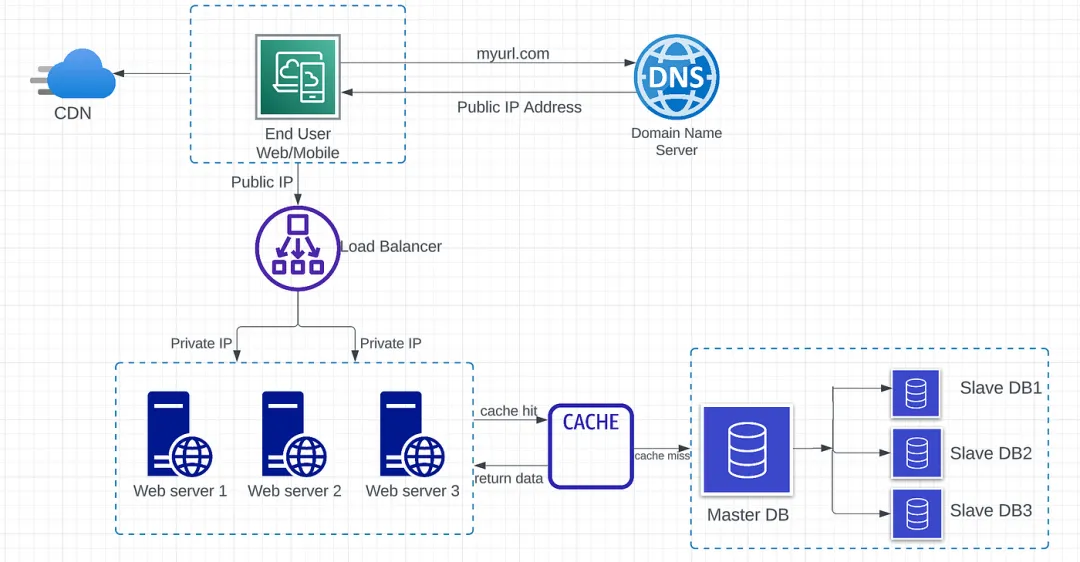
- 最終用戶通過域名(myurl.com)訪問網站。請求發送到 DNS,將域名映射到 IP 地址。
- IP 地址返回給網頁瀏覽器或移動應用程序。
- HTTP 請求直接發送到 web 服務器。
- Web 服務器然后將請求的資源返回給客戶端。在上圖中,返回 HTML 頁面進行渲染。
圖中使用的組件定義如下:
- Web 服務器:一臺能夠通過互聯網向最終用戶提供網頁內容的計算機系統。它包括網頁服務器軟件和網站組件文件,如 HTML 文檔、圖像、CSS 樣式表、JavaScript 文件等。
- Web 客戶端(Web/移動):用于通過 HTTP 連接到 Web 服務器的客戶端應用程序。通常是一個網頁瀏覽器或 Web 應用程序,用于顯示從服務器接收的網頁并允許用戶與 Web 服務器進行交互。
- 域名系統(DNS):充當互聯網的電話簿。人們通過域名(google.com)訪問信息,但 Web 服務器使用互聯網協議(IP)地址進行交互。DNS 將域名轉換為 IP 地址,以便瀏覽器可以加載互聯網資源。互聯網中的每個設備都有唯一的 IP 地址,其他機器使用該地址查找設備。通常,DNS 是由第三方提供的付費服務,不由 Web 服務器托管。
將數據庫與 Web 服務器分離
隨著用戶數量的增長,為了更獨立地擴展,第一步是將數據庫與 Web 服務器分離。
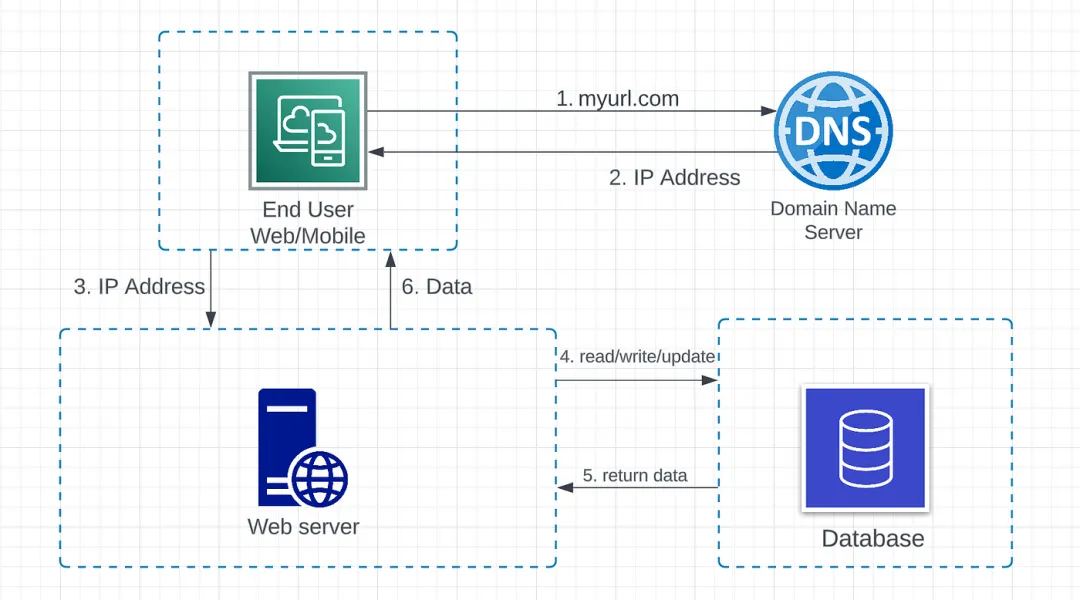
圖1.2 請求流程
- 最終用戶通過域名(myurl.com)訪問網站。請求發送到 DNS,將域名映射到 IP 地址。
- IP 地址返回給網頁瀏覽器或移動應用程序。
- HTTP 請求直接發送到 web 服務器。
- Web 服務器向數據庫服務器發送請求,執行讀取、寫入或更新數據操作。
- 數據從數據庫服務器返回到 web 服務器。
- 數據在 web 服務器中處理,最終返回給 Web 客戶端。
圖中新增的組件定義如下:
- 數據庫:存儲在計算機系統中的結構化或非結構化信息集合。數據庫的選擇取決于存儲的信息類型。數據庫可以從傳統關系型數據庫到非關系型數據庫等各種類型。
- 傳統關系型數據庫:以表、行和列的方式結構化信息。關系型數據庫能夠通過連接表之間的關系來建立鏈接,這使得理解和獲取有關各種數據點關系的見解變得容易。常見的傳統數據庫有 MySQL、Oracle 數據庫、PostgreSQL 等。
- 非關系型數據庫:也稱為 NoSQL 數據庫,使用針對存儲的數據類型的特定要求進行優化的存儲模型。它可以進一步分為多種不同的類別,如鍵值存儲、圖形存儲、列存儲、文檔存儲等。一些常見的例子包括 Cassandra、MongoDB、Neo4j 等。
擴展 Web 服務器
隨著用戶基數的增長和流量的增加,擴展 Web 服務器的能力變得至關重要。擴展的方式有兩種,即垂直擴展和水平擴展。在垂直擴展中,通過向同一臺服務器添加更多 CPU、RAM 等來“擴展”,而在水平擴展中,通過向資源池中添加更多服務器來“擴展”。盡管垂直擴展在性質上更加簡單,但它也有自己的局限性。其中一些限制包括硬件限制(無法向單個服務器添加無限制的內存和 CPU),而且存在單點故障,這可能是一個巨大的缺點。因此,在大規模應用程序的情況下,使用水平擴展可能是更好的選擇,通過負載均衡器將流量分布到多個服務器上。
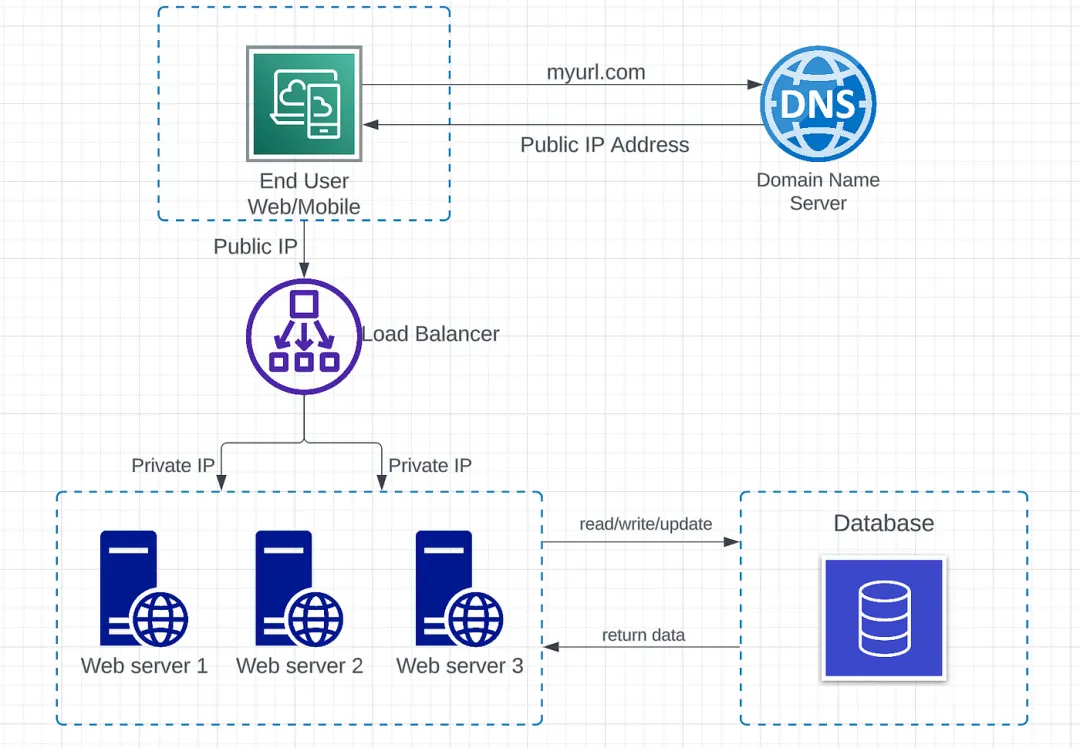
負載均衡器:負載均衡器充當流量管理器,位于服務器前面,將客戶端請求路由到能夠滿足這些請求的所有服務器上,以最大化速度和容量利用率。負載均衡器的一些主要責任包括:
- 高效地將客戶端請求或網絡負載分布到多個服務器上。
- 僅將請求發送到在線的服務器,確保高可用性和可靠性。
- 根據需求靈活添加或移除服務器。
用戶直接連接到負載均衡器的公共 IP。在此架構中,無法使用公共 IP 訪問 Web 服務器。負載均衡器使用私有 IP 與不同的服務器進行通信。私有 IP 僅用于在同一網絡內進行通信。
一些常見的負載均衡算法:
- 輪詢法(Round Robin)— 順序分發請求。
- 最少連接法(Least Connections)— 發送到當前連接最少的服務器。
- 最少時間法(Least Time)— 發送到響應最快且連接最少的服務器。
- 哈希法(Hash)— 根據您定義的鍵(如客戶端 IP 地址、URL 等)進行分發。
數據可用性和復制
擴展的最關鍵方面之一是增強數據的可用性和可靠性。數據復制是實現這一目標的重要方式,它通過在不同服務器上創建和維護數據庫的副本來實現。
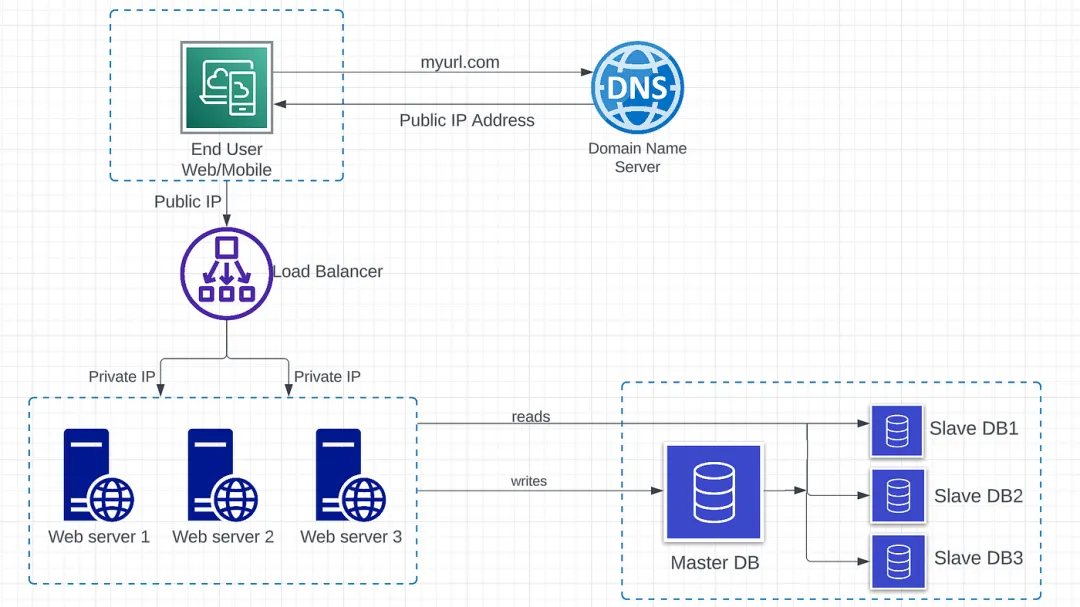
在圖1.4中,我們可以看到原始(主)數據庫和副本(從)數據庫之間的主從關系。
- 主數據庫:僅支持來自 Web 服務器的寫入操作。所有修改數據的操作,如插入、刪除、更新,都必須發送到主數據庫。如果主數據庫下線,一個從數據庫將被提升為新的主數據庫。
- 從數據庫:僅支持來自 Web 服務器的讀取操作。通常情況下,從數據庫比主數據庫多,因為讀取和寫入的比例總是更高。如果從數據庫下線,一個新的從數據庫將取代舊的從數據庫。
數據復制的優勢:
- 更好的性能 — 允許更多查詢并行處理。
- 可靠性 — 數據在多個服務器上復制。我們不需要擔心數據丟失。
- 高可用性 — 如果一個數據服務器下線,您可以從另一個數據庫訪問存儲的數據。
一些其他常見的數據復制類型:
- 主-主復制 — 對任何主數據庫進行的更改會復制到配置中的其他主數據庫。
- 快照復制 — 在特定時間點創建整個數據庫的副本,然后將快照復制到一個或多個目的地。
討論了 Web 層和數據層之后,我們將簡要介紹對改善負載/響應時間起著關鍵作用的兩個其他概念:緩存和內容傳遞網絡(CDN)。
緩存
緩存是一個臨時存儲區,用于在內存中存儲昂貴響應的結果或頻繁訪問的數據。
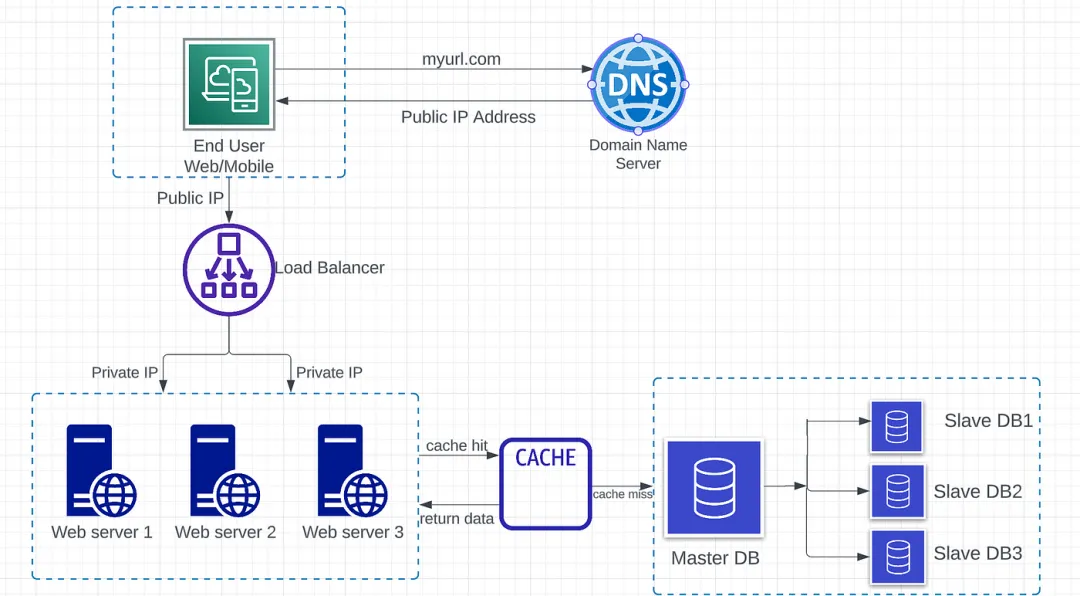
- 緩存命中 — Web 服務器從緩存中請求數據。如果數據存在于緩存中,則為緩存命中。在這種情況下,無需向數據庫服務器發出網絡調用。
- 緩存未命中 — Web 服務器從緩存中請求數據。如果緩存中不包含數據,則為緩存未命中。此時,需要從數據庫獲取數據,然后將數據保存到緩存中。
使用緩存的一些關鍵考慮因素:
- 數據讀取頻率高于修改頻率。
- 實施良好的過期策略,這很重要,因為延遲的過期策略可能導致緩存中的數據過時,而頻繁的過期策略可能會降低緩存的效果,因為這會導致頻繁從數據庫重新加載數據。
- 為了減少故障,請考慮添加多個緩存服務器,以避免單點故障。
- 必須有一個良好的驅逐策略。一旦緩存已滿,為了添加新項目,現有項目應根據驅逐策略進行刪除。
緩存的類型:
- 應用程序服務器緩存 — 緩存與應用程序服務器一起存儲在內存中。在多 Web 服務器系統中,此架構中的一個缺點是,每個服務器將不知道已緩存請求,因此會產生大量的緩存未命中。
- 分布式緩存 — 每個節點將擁有整個緩存空間的一部分,然后使用一致性哈希函數將每個請求路由到可找到緩存請求的地方。
- 全局緩存 — 您將擁有單個緩存空間,所有節點都將使用此單個空間。
內容傳遞網絡(CDN)
CDN 是一個由地理位置分散的服務器網絡,用于傳遞靜態內容,包括圖像、視頻、CSS、JavaScript 文件等。CDN 由像亞馬遜、Akamai 等第三方提供商運行。
使用 CDN 的請求流程:
- 用戶通過 URL 請求資源。這些 URL 是由 CDN 提供商提供的。
- 如果 CDN 緩存中沒有資源,則從源(如亞馬遜 S3)請求。
- 源然后將資源返回給 CDN 服務器。
- CDN 緩存資源并將其返回給用戶。該圖像將在 TTL(存活時間)過期之前保留在緩存中。
- 當另一個用戶請求相同資源時,如果 TTL 尚未過期,則從緩存中獲取。
總之,與用戶規模的擴展不僅是技術上的挑戰,更是現代數字系統的戰略必需品。從設計彈性架構到實施有效的擴展策略,我們探討了確保您的系統可以與用戶需求無縫增長的關鍵要素。