














本文將探討大語言模型(LLMs)與網絡抓取的集成,以及如何利用LLMs高效地將復雜的HTML轉換為結構化的JSON。
作為一名數據工程師,我的職業生涯可以追溯到2016年。那時,我的主要職責是利用自動化工具從不同網站上獲取海量數據,這個過程被稱為“網絡抓取”。網絡抓取通常是從網站的HTML代碼中提取所需數據。
在構建相關應用程序時,我不得不深入研究HTML代碼,努力尋找最佳的抓取解決方案。我所面臨的主要挑戰之一是應對網站的頻繁變化:例如,我所抓取的亞馬遜頁面每一到兩周就會發生結構上的變化。
隨著我開始閱讀有關大語言模型(LLMs)的文獻,我突然意識到:能否利用LLMs來規避我之前在網頁結構化數據方面所遇到的種種問題?讓我們探討一下,看看是否能夠實現這一目標。
網絡抓取工具和技術
在網絡抓取領域,工具和技術的選擇至關重要,當時,我主要使用的工具包括Requests、BeautifulSoup和Selenium。每種工具都有不同的用途,各自針對不同類型的網絡環境。
- Requests 是一個基于Python的HTTP庫,旨在簡化HTTP請求的發送和響應的接收,通常被用于獲取可由BeautifulSoup解析的HTML內容。
- BeautifulSoup 則是一款基于Python的HTML/XML解析庫,它能夠構建解析樹,方便開發者訪問頁面中的各種元素。通常情況下,BeautifulSoup會與其他庫(如Requests或Selenium)結合使用,對從這些庫獲取的HTML源代碼進行解析。
- Selenium 主要應用于包含大量JavaScript的網站。與BeautifulSoup不同的是,Selenium除了能分析HTML代碼外,還能通過模擬用戶操作(如點擊和滾動)與網站進行交互。這有助于從動態網站中獲取數據。
在網絡抓取過程中,這三種工具是必不可少的利器。然而,它們也帶來了一定的挑戰:由于網站布局和結構的變化,開發者不得不定期更新代碼、標簽和元素,這無疑增加了長期維護的復雜性。
什么是大語言模型(LLMs)?
大語言模型(LLMs)被視為下一代計算機程序,它們可以通過閱讀和分析海量文本數據進行學習。在當今時代,LLMs具備了以人類般的敘述方式進行寫作的驚人能力,使其成為處理語言和理解人類語言的高效工具。這種出色的能力在需要深入把握文本上下文的場景中表現尤為突出。
將LLMs集成入網絡抓取
在網絡抓取實施過程中,LLMs可以帶來極大優化。我們只需將網頁的HTML代碼輸入到LLM中,LLM即可提取出其中所涉及的對象。因此,這種策略有助于簡化維護,原因在于即使標記結構發生了變化,內容本身通常也會固定不變。
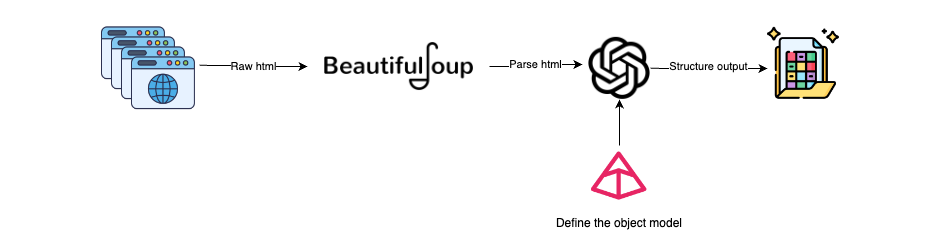
將大語言模型(LLMs)集成入網絡抓取的工作流程大致如下:
獲取HTML:使用Selenium或Requests等工具獲取網頁的HTML內容。其中,Selenium適用于處理包含JavaScript的動態頁面內容,而Requests則更適合靜態頁面。
解析HTML:使用BeautifulSoup,我們可以將HTML解析為文本,從而去除HTML中的噪音數據(頁腳、頁眉等)。
創建Pydantic模型:定義需抓取數據對象的Pydantic模型。這一步確保了待抓取數據的類型和結構符合預定義的模式。
為LLMs生成提示:設計一個提示語,明確告知LLM應該提取哪些信息。
LLM處理:使用LLM模型讀取HTML內容,理解其語義,并根據數據處理和結構化的指令進行操作。
結構化數據的輸出:LLM將以Pydantic模型定義的結構化對象形式提供輸出。
上述工作流程有助于利用LLMs將HTML(非結構化數據)轉化為結構化數據,從而解決了網頁源HTML設計不規范或動態修改所帶來的問題。
LangChain與BeautifulSoup和Pydantic的集成
以下是我們選擇的靜態網頁示例,目標是從中抓取所有列出的活動,并以結構化的方式呈現。
這種方法首先從靜態網頁中提取原始HTML,并在LLM處理之前對其進行清理。
from bs4 import BeautifulSoup
import requests
def extract_html_from_url(url):
try:
# Fetch HTML content from the URL using requests
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad responses (4xx and 5xx)
# Parse HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
excluded_tagNames = ["footer", "nav"]
# Exclude elements with tag names 'footer' and 'nav'
for tag_name in excluded_tagNames:
for unwanted_tag in soup.find_all(tag_name):
unwanted_tag.extract()
# Process the soup to maintain hrefs in anchor tags
for a_tag in soup.find_all("a"):
href = a_tag.get("href")
if href:
a_tag.string = f"{a_tag.get_text()} ({href})"
return ' '.join(soup.stripped_strings) # Return text content with preserved hrefs
except requests.exceptions.RequestException as e:
print(f"Error fetching data from {url}: {e}")
return None當我們從網頁中進行數據抓取時,下一步是定義需要從網頁中抓取的 Pydantic 對象。我們需要創建兩個對象:
Activity:這是一個 Pydantic 對象,用于表示與活動相關的所有元數據,其中指定了屬性和數據類型。我們已將某些字段標記為可選,以防它們在所有活動中均不可用。為屬性提供描述、示例和任何元數據將有助于更好地定義。
ActivityScraper:這是基于 Activity 的 Pydantic 封裝。該對象的目的是確保 LLM 理解需要從多個活動中抓取數據。
from pydantic import BaseModel, Field
from typing import Optional
class Activity(BaseModel):
title: str = Field(description="The title of the activity.")
rating: float = Field(description="The average user rating out of 10.")
reviews_count: int = Field(description="The total number of reviews received.")
travelers_count: Optional[int] = Field(description="The number of travelers who have participated.")
cancellation_policy: Optional[str] = Field(description="The cancellation policy for the activity.")
description: str = Field(description="A detailed description of what the activity entails.")
duration: str = Field(description="The duration of the activity, usually given in hours or days.")
language: Optional[str] = Field(description="The primary language in which the activity is conducted.")
category: str = Field(description="The category of the activity, such as 'Boat Trip', 'City Tours', etc.")
price: float = Field(description="The price of the activity.")
currency: str = Field(description="The currency in which the price is denominated, such as USD, EUR, GBP, etc.")
class ActivityScrapper(BaseModel):
Activities: list[Activity] = Field("List of all the activities listed in the text")最后,我們來看一下 LLM 的配置。我們將使用 LangChain 庫,該庫提供了一個出色的工具包,可幫助您入門。
其中一個關鍵組件是 PydanticOutputParser。它將把我們的對象轉換為指令(如提示中所示),并解析 LLM 的輸出,以獲取相應的對象列表。
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(temperature=0)
output_parser = PydanticOutputParser(pydantic_object = ActivityScrapper)
prompt_template = """
You are an expert making web scrapping and analyzing HTML raw code.
If there is no explicit information don't make any assumption.
Extract all objects that matched the instructions from the following html
{html_text}
Provide them in a list, also if there is a next page link remember to add it to the object.
Please, follow carefulling the following instructions
{format_instructions}
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["html_text"],
partial_variables={"format_instructions": output_parser.get_format_instructions}
)
chain = prompt | llm | output_parser在這一步中,您需要調用鏈式模型并檢索結果。
url = "https://www.civitatis.com/es/budapest/"
html_text_parsed = extract_html_from_url(url)
activites = chain.invoke(input={
"html_text": html_text_parsed
})
activites.Activities這就是抓取出來的數據,整個網頁抓取耗時46 秒。
[Activity(title='Paseo en barco al anochecer', rating=8.4, reviews_count=9439, travelers_count=118389, cancellation_policy='Cancelación gratuita', description='En este crucero disfrutaréis de las mejores vistas de Budapest cuando se viste de gala, al anochecer. El barco es panorámico y tiene partes descubiertas.', duration='1 hora', language='Espa?ol', category='Paseos en barco', price=21.0, currency='€'),
Activity(title='Visita guiada por el Parlamento de Budapest', rating=8.8, reviews_count=2647, travelers_count=34872, cancellation_policy='Cancelación gratuita', description='El Parlamento de Budapest es uno de los edificios más bonitos de la capital húngara. Comprobadlo vosotros mismos en este tour en espa?ol que incluye la entrada.', duration='2 horas', language='Espa?ol', category='Visitas guiadas y free tours', price=27.0, currency='€')
...
]演示和完整代碼庫
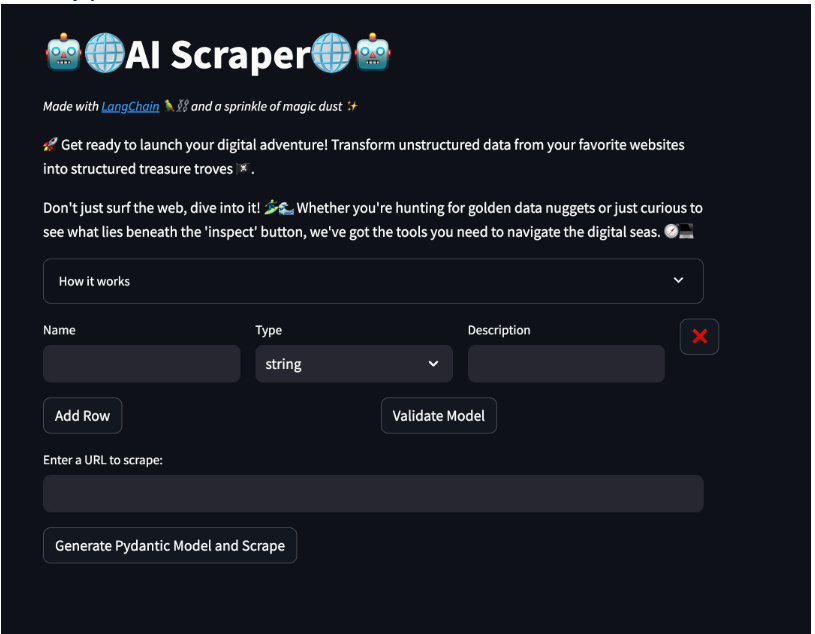
我創建了一個使用Streamlit的快速演示,可以在此處訪問。
在這個演示中,您將了解有關模型的詳細信息。您可以根據需要添加多行文本,并為每個屬性指定名稱、類型和描述。這將自動生成一個Pydantic模型,用于在網頁抓取組件中使用。
接下來的部分允許您輸入一個URL地址,并通過點擊網頁上的按鈕來抓取所有數據。當抓取完成后,會出現一個下載按鈕,允許您以JSON格式下載數據。
請隨意嘗試!
結論
當處理非結構化數據時,LLM確實為從非結構化數據(如網站、PDF等)中高效提取數據提供了新的可能性。自動化網絡抓取不僅可以節省時間,還可以確保檢索到的數據質量。
然而,將原始HTML發送給LLM可能會增加令牌成本并降低效率。這是因為HTML通常包含各種標簽、屬性和內容,導致成本迅速上升。
因此,在使用LLM作為網絡數據提取器時,預處理和清理HTML是關鍵的一步。我們應該刪除所有不必要的元數據和非實際使用的信息,以保持合理的成本。
總之,選擇正確的工具對于正確的工作至關重要!
譯者介紹
劉濤,51CTO社區編輯,某大型央企系統上線檢測管控負責人。
原文標題:Enhancing Web Scraping With Large Language Models: A Modern Approach,作者:Nacho Corcuera
鏈接:https://dzone.com/articles/enhancing-web-scraping-with-large-language-models。




















