YOLOv10來啦!真正實時端到端目標檢測
本文經自動駕駛之心公眾號授權轉載,轉載請聯(lián)系出處。
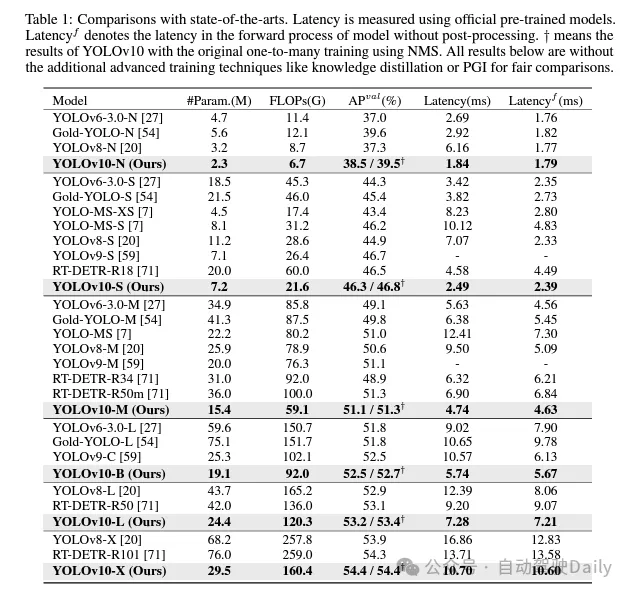
過去幾年里,YOLOs因在計算成本和檢測性能之間實現(xiàn)有效平衡而成為實時目標檢測領域的主流范式。研究人員針對YOLOs的結構設計、優(yōu)化目標、數(shù)據(jù)增強策略等進行了深入探索,并取得了顯著進展。然而,對非極大值抑制(NMS)的后處理依賴阻礙了YOLOs的端到端部署,并對推理延遲產生負面影響。此外,YOLOs中各種組件的設計缺乏全面和徹底的審查,導致明顯的計算冗余并限制了模型的性能。這導致次優(yōu)的效率,以及性能提升的巨大潛力。在這項工作中,我們旨在從后處理和模型架構兩個方面進一步推進YOLOs的性能-效率邊界。為此,我們首先提出了用于YOLOs無NMS訓練的持續(xù)雙重分配,該方法同時帶來了競爭性的性能和較低的推理延遲。此外,我們?yōu)閅OLOs引入了全面的效率-準確性驅動模型設計策略。我們從效率和準確性兩個角度全面優(yōu)化了YOLOs的各個組件,這大大降低了計算開銷并增強了模型能力。我們的努力成果是新一代YOLO系列,專為實時端到端目標檢測而設計,名為YOLOv10。廣泛的實驗表明,YOLOv10在各種模型規(guī)模下均達到了最先進的性能和效率。例如,在COCO數(shù)據(jù)集上,我們的YOLOv10-S在相似AP下比RT-DETR-R18快1.8倍,同時參數(shù)和浮點運算量(FLOPs)減少了2.8倍。與YOLOv9-C相比,YOLOv10-B在相同性能下延遲減少了46%,參數(shù)減少了25%。代碼鏈接:https://github.com/THU-MIG/yolov10。
YOLOv10有哪些改進?
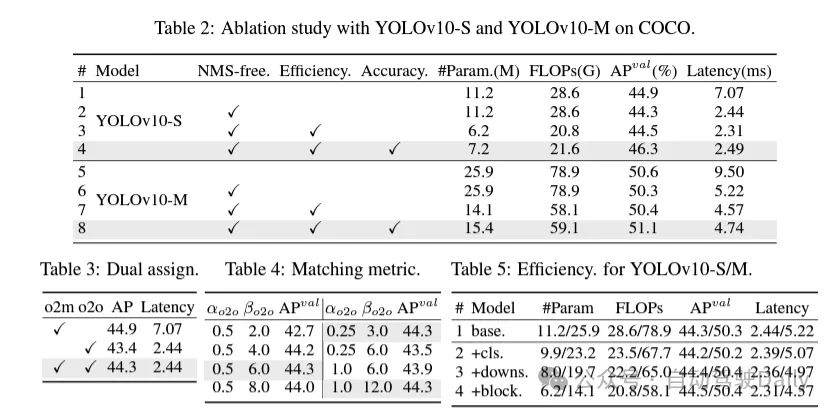
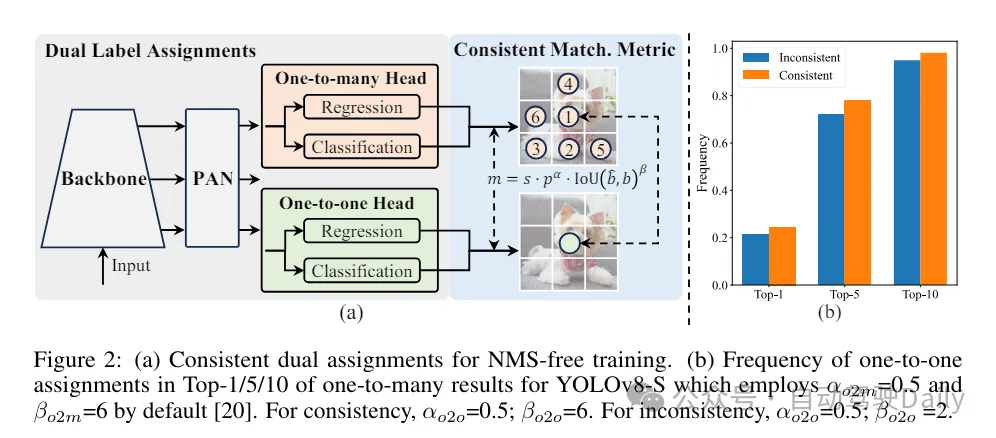
首先通過為無NMS的YOLOs提出一種持續(xù)雙重分配策略來解決后處理中的冗余預測問題,該策略包括雙重標簽分配和一致匹配度量。這使得模型在訓練過程中能夠獲得豐富而和諧的監(jiān)督,同時消除了推理過程中對NMS的需求,從而在保持高效率的同時獲得了競爭性的性能。
其次,為模型架構提出了全面的效率-準確度驅動模型設計策略,對YOLOs中的各個組件進行了全面檢查。在效率方面,提出了輕量級分類頭、空間-通道解耦下采樣和rank引導block設計,以減少明顯的計算冗余并實現(xiàn)更高效的架構。
在準確度方面,探索了大核卷積并提出了有效的部分自注意力模塊,以增強模型能力,以低成本挖掘性能提升潛力。
基于這些方法,作者成功地實現(xiàn)了一系列不同模型規(guī)模的實時端到端檢測器,即YOLOv10-N / S / M / B / L / X。在標準目標檢測基準上進行的廣泛實驗表明,YOLOv10在各種模型規(guī)模下,在計算-準確度權衡方面顯著優(yōu)于先前的最先進模型。如圖1所示,在類似性能下,YOLOv10-S / X分別比RT-DETR R18 / R101快1.8倍/1.3倍。與YOLOv9-C相比,YOLOv10-B在相同性能下實現(xiàn)了46%的延遲降低。此外,YOLOv10展現(xiàn)出了極高的參數(shù)利用效率。YOLOv10-L / X在參數(shù)數(shù)量分別減少了1.8倍和2.3倍的情況下,比YOLOv8-L / X高出0.3 AP和0.5 AP。YOLOv10-M在參數(shù)數(shù)量分別減少了23%和31%的情況下,與YOLOv9-M / YOLO-MS實現(xiàn)了相似的AP。

在訓練過程中,YOLOs通常利用TAL(任務分配學習) 為每個實例分配多個正樣本。采用一對多的分配方式產生了豐富的監(jiān)督信號,有助于優(yōu)化并實現(xiàn)卓越的性能。然而,這也使得YOLOs 必須依賴于NMS(非極大值抑制)后處理,這導致在部署時的推理效率不是最優(yōu)的。雖然之前的工作探索了一對一的匹配方式來抑制冗余預測,但它們通常會增加額外的推理開銷或導致次優(yōu)的性能。在這項工作中,我們?yōu)閅OLOs提出了一種無需NMS的訓練策略,該策略采用雙重標簽分配和一致匹配度量,實現(xiàn)了高效率和具有競爭力的性能。
效率驅動的模型設計。YOLO中的組件包括主干(stem)、下采樣層、帶有基本構建塊的階段和頭部。主干部分的計算成本很低,因此我們對其他三個部分進行效率驅動的模型設計。
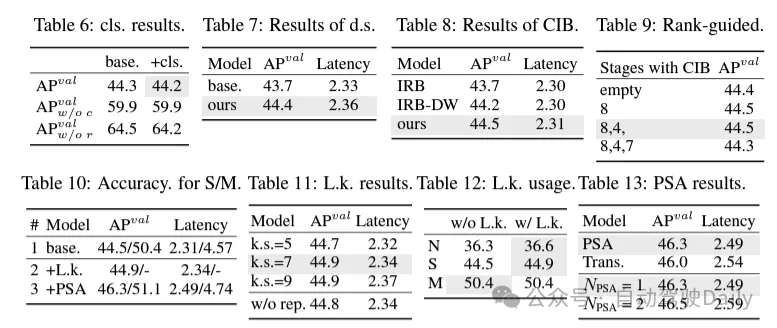
(1)輕量級的分類頭。在YOLO中,分類頭和回歸頭通常具有相同的架構。然而,它們在計算開銷上存在顯著的差異。例如,在YOLOv8-S中,分類頭(5.95G/1.51M的FLOPs和參數(shù)計數(shù))的FLOPs和參數(shù)計數(shù)分別是回歸頭(2.34G/0.64M)的2.5倍和2.4倍。然而,通過分析分類錯誤和回歸錯誤的影響(見表6),我們發(fā)現(xiàn)回歸頭對YOLO的性能更為重要。因此,我們可以在不擔心對性能造成太大損害的情況下減少分類頭的開銷。因此,我們簡單地采用了輕量級的分類頭架構,它由兩個深度可分離卷積組成,卷積核大小為3×3,后跟一個1×1卷積。
(2)空間-通道解耦下采樣。YOLO通常使用步長為2的常規(guī)3×3標準卷積,同時實現(xiàn)空間下采樣(從H × W到H/2 × W/2)和通道變換(從C到2C)。這引入了不可忽視的計算成本 和參數(shù)計數(shù)。相反,我們提出將空間縮減和通道增加操作解耦,以實現(xiàn)更高效的下采樣。具體來說,首先利用逐點卷積來調制通道維度,然后利用深度卷積進行空間下采樣。這將計算成本降低到并將參數(shù)計數(shù)降低到。同時,它在下采樣過程中最大限度地保留了信息,從而在降低延遲的同時保持了競爭性能。
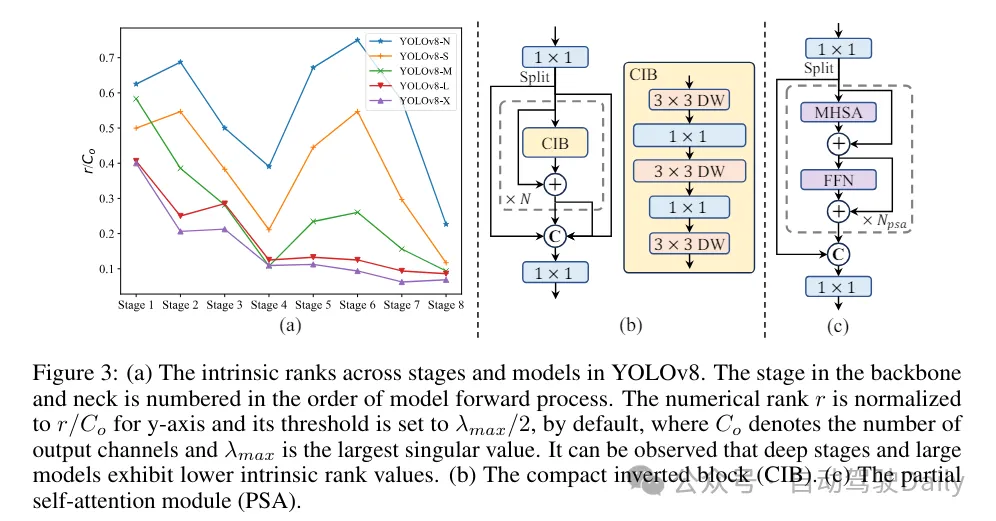
(3)基于rank引導的模塊設計。YOLOs通常對所有階段都使用相同的基本構建塊,例如YOLOv8中的bottleneck塊。為了徹底檢查YOLOs的這種同構設計,我們利用內在秩來分析每個階段的冗余性。具體來說,計算每個階段中最后一個基本塊中最后一個卷積的數(shù)值秩,它計算大于閾值的奇異值的數(shù)量。圖3(a)展示了YOLOv8的結果,表明深層階段和大型模型更容易表現(xiàn)出更多的冗余性。這一觀察表明,簡單地對所有階段應用相同的block設計對于實現(xiàn)最佳容量-效率權衡來說并不是最優(yōu)的。為了解決這個問題,提出了一種基于秩的模塊設計方案,旨在通過緊湊的架構設計來降低被證明是冗余的階段的復雜性。
首先介紹了一種緊湊的倒置塊(CIB)結構,它采用廉價的深度卷積進行空間混合和成本效益高的逐點卷積進行通道混合,如圖3(b)所示。它可以作為有效的基本構建塊,例如嵌入在ELAN結構中(圖3(b))。然后,倡導一種基于秩的模塊分配策略,以在保持競爭力量的同時實現(xiàn)最佳效率。具體來說,給定一個模型,根據(jù)其內在秩的升序對所有階段進行排序。進一步檢查用CIB替換領先階段的基本塊后的性能變化。如果與給定模型相比沒有性能下降,我們將繼續(xù)替換下一個階段,否則停止該過程。因此,我們可以在不同階段和模型規(guī)模上實現(xiàn)自適應緊湊塊設計,從而在不影響性能的情況下實現(xiàn)更高的效率。
基于精度導向的模型設計。論文進一步探索了大核卷積和自注意力機制,以實現(xiàn)基于精度的設計,旨在以最小的成本提升性能。
(1)大核卷積。采用大核深度卷積是擴大感受野并增強模型能力的一種有效方法。然而,在所有階段簡單地利用它們可能會在用于檢測小目標的淺層特征中引入污染,同時也在高分辨率階段引入顯著的I/O開銷和延遲。因此,作者提出在深層階段的跨階段信息塊(CIB)中利用大核深度卷積。這里將CIB中的第二個3×3深度卷積的核大小增加到7×7。此外,采用結構重參數(shù)化技術,引入另一個3×3深度卷積分支,以緩解優(yōu)化問題,而不增加推理開銷。此外,隨著模型大小的增加,其感受野自然擴大,使用大核卷積的好處逐漸減弱。因此,僅在小模型規(guī)模上采用大核卷積。
(2)部分自注意力(PSA)。自注意力機制因其出色的全局建模能力而被廣泛應用于各種視覺任務中。然而,它表現(xiàn)出高計算復雜度和內存占用。為了解決這個問題,鑒于普遍存在的注意力頭冗余,作則提出了一種高效的部分自注意力(PSA)模塊設計,如圖3.(c)所示。具體來說,在1×1卷積之后將特征均勻地按通道分成兩部分。只將一部分特征輸入到由多頭自注意力模塊(MHSA)和前饋網(wǎng)絡(FFN)組成的NPSA塊中。然后,將兩部分特征通過1×1卷積進行拼接和融合。此外,將MHSA中查詢和鍵的維度設置為值的一半,并將LayerNorm替換為BatchNorm以實現(xiàn)快速推理。PSA僅放置在具有最低分辨率的第4階段之后,以避免自注意力的二次計算復雜度帶來的過多開銷。通過這種方式,可以在計算成本較低的情況下將全局表示學習能力融入YOLOs中,從而很好地增強了模型的能力并提高了性能。
實驗對比
這里就不做過多介紹啦,直接上結果!!!latency減少,性能繼續(xù)增加。