













自定義 Yolov10 和 Ollama(Llama 3)增強 OCR
最近,我大部分時間都在玩大型語言模型(LLMs),但我對計算機視覺的熱愛從未真正消退。因此,當有機會將兩者結合起來時,我迫不及待地想要深入研究。在Goodreads上掃描書的封面并將其標記為“已讀”總是感覺像一種魔法,我忍不住想要為自己重現這種體驗。

通過結合自定義訓練的YOLOv10模型和OCR技術,你可以獲得巨大的準確性提升。但當你加入一個LLM(Llama 3)時,真正的魔法就發生了——那些混亂的OCR輸出突然變成了干凈、可用的文本,非常適合實際應用。
為什么我們需要在OCR中使用YOLO和Ollama?
傳統的OCR(光學字符識別)方法在從簡單圖像中提取文本方面做得很好,但當文本與其他視覺元素交織在一起時,往往難以應對。通過使用自定義的YOLO模型首先檢測文本區域等對象,我們可以為OCR隔離這些區域,顯著減少噪聲并提高準確性。讓我們通過在沒有YOLO的圖像上運行一個基本的OCR示例來演示這一點,以突出單獨使用OCR的挑戰:
import easyocr
import cv2
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Load the image
image = cv2.imread('book.jpg')
# Run OCR directly
results = reader.readtext(image)
# Display results
for (bbox, text, prob) in results:
print(f"Detected Text: {text} (Probability: {prob})")THE 0 R |G |NAL B E STSELLE R THE SECRET HISTORY DONNA TARTT Haunting, compelling and brilliant The Times雖然它可以很好地處理更簡單的圖像,但當存在噪聲或復雜的視覺模式時,錯誤就開始堆積。這時,YOLO模型介入并真正發揮作用。
1. 訓練自定義Yolov10數據集
用對象檢測增強OCR的第一步是在你數據集上訓練一個自定義的YOLO模型。YOLO(You Only Look Once)是一個強大的實時對象檢測模型,它將圖像劃分為網格,允許它在單次前向傳遞中識別多個對象。這種方法非常適合檢測圖像中的文本,特別是當你想要通過隔離特定區域來提高OCR結果時。

書籍封面數據集
我們將使用這里鏈接的預注釋書籍封面數據集,并在它上面訓練一個YOLOv10模型。YOLOv10針對較小的對象進行了優化,使其非常適合在視頻或掃描文檔等具有挑戰性的環境中檢測文本。
from ultralytics import YOLO
model = YOLO("yolov10n.pt")
# Train the model
model.train(data="datasets/data.yaml", epochs=50, imgsz=640)你可以調整周期數量、數據集大小等參數,或者嘗試調整超參數以提高模型的性能和準確性。
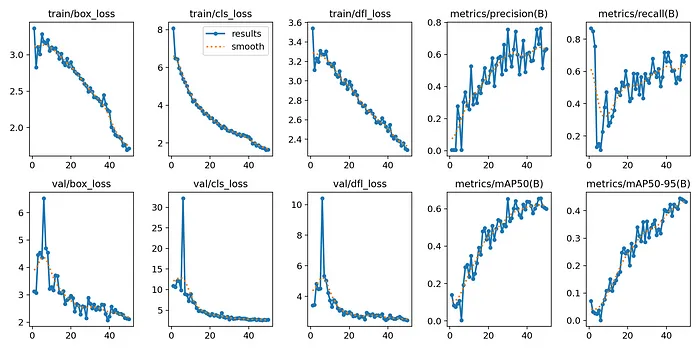
YOLOv10自定義數據集訓練的關鍵指標
2. 在視頻上運行自定義模型以獲取邊界框
一旦你的YOLO模型訓練完成,你可以將其應用于視頻以檢測文本區域周圍的邊界框。這些邊界框隔離了感興趣的區域,確保了更干凈的OCR過程:
import cv2
# Open video file
video_path = 'books.mov'
cap = cv2.VideoCapture(video_path)
# Load YOLO model
model = YOLO('model.pt')
# Function for object detection and drawing bounding boxes
def predict_and_detect(model, frame, conf=0.5):
results = model.predict(frame, conf=conf)
for result in results:
for box in result.boxes:
# Draw bounding box
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
return frame, results
# Process video frames
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Run object detection
processed_frame, results = predict_and_detect(model, frame)
# Show video with bounding boxes
cv2.imshow('YOLO + OCR Detection', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video
cap.release()
cv2.destroyAllWindows()
這段代碼實時處理視頻,繪制檢測到的文本周圍的邊界框,并隔離這些區域,為下一步——OCR——做好了完美的準備。
3. 在邊界框上運行OCR
現在我們已經用YOLO隔離了文本區域,我們可以在這些特定區域內應用OCR,與在整個圖像上運行OCR相比,大大提高了準確性:
import easyocr
# Initialize EasyOCR
reader = easyocr.Reader(['en'])
# Function to crop frames and perform OCR
def run_ocr_on_boxes(frame, boxes):
ocr_results = []
for box in boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0].tolist())
cropped_frame = frame[y1:y2, x1:x2]
ocr_result = reader.readtext(cropped_frame)
ocr_results.append(ocr_result)
return ocr_results
# Perform OCR on detected bounding boxes
for result in results:
ocr_results = run_ocr_on_boxes(frame, result.boxes)
# Extract and display the text from OCR results
extracted_text = [detection[1] for ocr in ocr_results for detection in ocr]
print(f"Extracted Text: {', '.join(extracted_text)}")'THE, SECRET, HISTORY, DONNA, TARTT'結果明顯改善,因為OCR引擎現在只處理被特別識別為包含文本的區域,減少了從無關圖像元素中誤解的風險。
4. 使用Ollama改進文本
使用easyocr提取文本后,Llama 3可以進一步通過完善通常不完美和混亂的結果。OCR功能強大,但它仍然可能誤解文本或返回無序的數據,特別是書籍標題或作者名稱。LLM介入整理輸出,將原始OCR結果轉化為結構化、連貫的文本。通過用特定提示引導Llama 3來識別和組織內容,我們可以將不完美的OCR數據完善為整潔格式化的書籍標題和作者名稱。最好的部分?你可以使用Ollama在本地運行它!
import ollama
# Construct a prompt to clean up the OCR output
prompt = f"""
- Below is a text extracted from an OCR. The text contains mentions of famous books and their corresponding authors.
- Some words may be slightly misspelled or out of order.
- Your task is to identify the book titles and corresponding authors from the text.
- Output the text in the format: '<Name of the book> : <Name of the author>'.
- Do not generate any other text except the book title and the author.
TEXT:
{output_text}
"""
# Use Ollama to clean and structure the OCR output
response = ollama.chat(
model="llama3",
messages=[{"role": "user", "content": prompt}]
)
# Extract cleaned text
cleaned_text = response['message']['content'].strip()
print(cleaned_text)The Secret History : Donna Tartt一旦LLM清理了文本,拋光后的輸出可以存儲在數據庫中,或用于各種實際應用,例如:
- 數字圖書館或書店:自動分類并顯示書籍標題及其作者。
- 檔案系統:將掃描的書籍封面或文件轉換為可搜索的數字記錄。
- 自動元數據生成:根據提取的信息為圖像、PDF或其他數字資產生成元數據。
- 數據庫輸入:將清理后的文本直接插入數據庫,確保更大系統中的數據結構化和一致性。
通過結合對象檢測、OCR和LLMs,你解鎖了一個強大的管道,用于更結構化的數據處理,非常適合需要高精度的應用。
結論
你可以通過結合自定義訓練的YOLOv10模型和EasyOCR,并使用LLM增強結果,顯著改進文本識別工作流程。無論你是在處理棘手的圖像或視頻中的文本,清理OCR混亂,還是使一切超級拋光,這個管道都能為你提供實時、激光精確的文本提取和細化。
完整代碼:https://github.com/tapanBabbar9/yolov10/tree/main/book-cover

























