













不想炸薯?xiàng)l的Ilya和不送GPU的英偉達(dá),Hinton最新專訪:道路千萬條,安全第一條
從谷歌離職一年之際,「人工智能教父」Hinton接受了采訪。
——也許是因?yàn)橥降躀lya終于被從核設(shè)施中放了出來?(狗頭)

視頻地址:https://www.youtube.com/watch?v=tP-4njhyGvo
當(dāng)然了,采訪教父的小伙子也非等閑之輩,Joel Hellermark創(chuàng)立的Sana已經(jīng)融資超過8000萬美元,
他本人也曾因?yàn)樵谕七M(jìn)AI方面的工作,而入選福布斯30 under 30(30位30歲以下精英)。最近,《衛(wèi)報(bào)》又將Joel評(píng)為35歲以下改變世界的前10名。
——這個(gè)13歲學(xué)編程、16歲開公司的小天才,與真正的科學(xué)家之間,又能碰撞出怎樣的火花呢?

下面,讓我們跟隨兩人的對(duì)話,一同探尋AI教父的心路歷程,以及幼年Ilya的一些趣事。
劍橋白學(xué)了
為了弄清楚人類的大腦如何工作,年輕的教父首先來到劍橋,學(xué)習(xí)了生理學(xué),而后又轉(zhuǎn)向哲學(xué),但最終也沒有得到想要的答案。
「That was extremely disappointing」。
于是,Hinton去了愛丁堡,開始研究AI,通過模擬事物的運(yùn)行,來測(cè)試?yán)碚摗?/span>
你在愛丁堡時(shí)候的直覺是什么?
「在我看來,必須有一種大腦學(xué)習(xí)的方式,顯然不是通過將各種事物編程到大腦中,然后使用邏輯推理。我們必須弄清楚大腦如何學(xué)會(huì)修改神經(jīng)網(wǎng)絡(luò)中的連接,以便它可以做復(fù)雜的事情。」
「我總是受到關(guān)于大腦工作原理的啟發(fā):有一堆神經(jīng)元,它們執(zhí)行相對(duì)簡(jiǎn)單的操作,它們是非線性的,它們收集輸入,進(jìn)行加權(quán),然后根據(jù)加權(quán)輸入給出輸出。問題是,如何改變這些權(quán)重以使整個(gè)事情做得很好?」
Ilya:我不想炸薯?xiàng)l了
某個(gè)星期日,Hinton坐在辦公室,突然有人在外面哐哐敲門(原話:that's sort of an urgent knock)。
Hinton去開門,門外的年輕人正是Ilya。

Ilya:這個(gè)夏天我在炸薯?xiàng)l,實(shí)在是干夠了,還不如來你實(shí)驗(yàn)室干活。
Hinton:你應(yīng)該先預(yù)約,然后我們談一下。
Ilya:就現(xiàn)在怎么樣?
——Hinton表示,這就是Ilya的性格特點(diǎn)。
Hinton給了Ilya一篇關(guān)于反向傳播的論文,兩人于一周后再次見面。
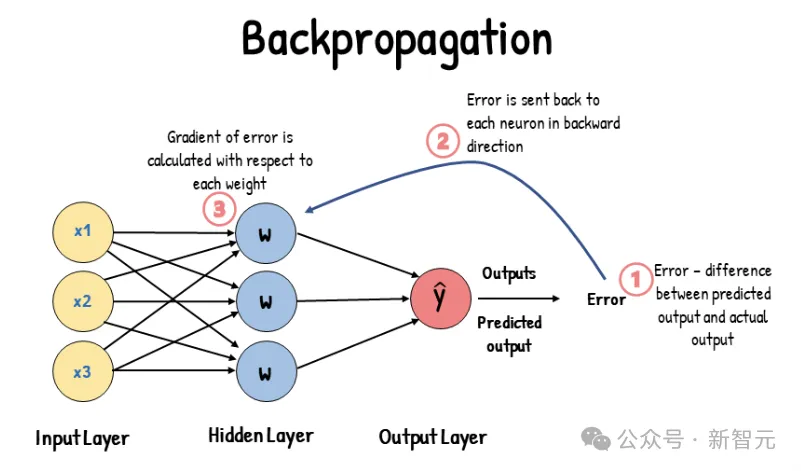
Ilya:I didn't understand it.
Hinton:?這不就是鏈?zhǔn)椒▌t嗎,小伙子你怎么回事?
Ilya:不是那個(gè),我不明白你為啥不用個(gè)更好的優(yōu)化器來處理梯度?
——Hinton的眼睛亮了一下,這是他們花了好幾年時(shí)間在思考的問題。

Hinton表示,Ilya總是有很好的直覺,他從小就對(duì)人工智能感興趣,并且顯然很擅長數(shù)學(xué)。
Hinton還記得,有一次的項(xiàng)目比較復(fù)雜,涉及到大量的代碼重組,以進(jìn)行正確的矩陣乘法。
Ilya受夠了折磨,于是有一天跑過來找Hinton,
Ilya:我要為Matlab寫一個(gè)接口,自動(dòng)做這些轉(zhuǎn)換。
Hinton:不行,Ilya,那需要你一個(gè)月的時(shí)間。我們必須繼續(xù)這個(gè)項(xiàng)目,不要分散注意力。
Ilya:沒關(guān)系,我今天早上寫完了。
Ilya的直覺
Ilya很早就有一種直覺:只要把神經(jīng)網(wǎng)絡(luò)模型做大一點(diǎn),就會(huì)得到更好的效果。Hinton認(rèn)為這是一種逃避,必須有新的想法或者算法才行。
但事實(shí)證明,Ilya是對(duì)的。
新的想法確實(shí)重要,比如像Transformer這樣的新架構(gòu)。但實(shí)際上,當(dāng)今AI的發(fā)展主要源于數(shù)據(jù)的規(guī)模和計(jì)算的規(guī)模。
或許正是因?yàn)镮lya的這種直覺,才有了后來OpenAI的驚人成就。

當(dāng)時(shí)過境遷、滄海桑田,光陰讓Ilya變?yōu)榱顺墒斓拇笕耍瑫r(shí)也帶走了他的頭發(fā)。
模型真的能思考
2011年,Hinton帶領(lǐng)Ilya和另一名研究生James Martins,發(fā)表了一篇字符級(jí)預(yù)測(cè)的論文。他們使用維基百科訓(xùn)練模型,嘗試預(yù)測(cè)下一個(gè)HTML字符。
模型首次采用了嵌入(embedding)和反向傳播,將每個(gè)符號(hào)轉(zhuǎn)換為嵌入,然后讓嵌入相互作用以預(yù)測(cè)下一個(gè)符號(hào)的嵌入,并通過反向傳播來學(xué)習(xí)數(shù)據(jù)的三元組。
當(dāng)時(shí)的人們不相信模型能夠理解任何東西,但實(shí)驗(yàn)結(jié)果令人震驚,就像是模型已經(jīng)學(xué)會(huì)了思考。

預(yù)測(cè)下一個(gè)符號(hào),與傳統(tǒng)的自動(dòng)完成功能有很大的不同。傳統(tǒng)的自動(dòng)完成功能會(huì)存儲(chǔ)一組三元組單詞。然后,你會(huì)看到不同的單詞出現(xiàn)在第三位的頻率,這樣你就可以進(jìn)行預(yù)測(cè)。
但現(xiàn)在,情況已經(jīng)不同了。要預(yù)測(cè)下一個(gè)符號(hào),你必須理解所說的內(nèi)容。我認(rèn)為通過預(yù)測(cè)下一個(gè)符號(hào)可以強(qiáng)迫模型進(jìn)行理解,它的理解方式與我們非常相似。
舉個(gè)例子,如果你問GPT-4,為什么堆肥堆像原子彈?大多數(shù)人都無法回答這個(gè)問題,因?yàn)樗麄冋J(rèn)為原子彈和堆肥堆是完全不同的東西。
但GPT-4會(huì)告訴你,兩者能量尺度不同,時(shí)間尺度也不同。但相同的是,當(dāng)堆肥堆變熱時(shí),它會(huì)更快地產(chǎn)生熱量;而當(dāng)原子彈產(chǎn)生更多的中子時(shí),其產(chǎn)生中子的速度也會(huì)隨之加快。
——這就引出了鏈?zhǔn)椒磻?yīng)的概念。通過這種理解,所有的信息都被壓縮到模型權(quán)重中。
在這種情況下,模型將能夠?qū)ξ覀儚奈匆娺^的各種類比進(jìn)行處理,這就是人類能從模型中獲得創(chuàng)造力的地方。
大型語言模型所做的是尋找共同的結(jié)構(gòu),使用共同的結(jié)構(gòu)對(duì)事物進(jìn)行編碼,這樣效率更高。
超越訓(xùn)練數(shù)據(jù)
在與李世石的那場(chǎng)著名比賽中,AlphaGo在第37步做出了所有專家都認(rèn)為是錯(cuò)誤的舉動(dòng),——但后來被證明是AI絕妙的創(chuàng)造力。

AlphaGo的不同之處在于它使用了強(qiáng)化學(xué)習(xí),使它能夠超越當(dāng)前狀態(tài)。它從模仿學(xué)習(xí)開始,觀察人類如何玩游戲,然后通過自我對(duì)弈,逐漸超越了訓(xùn)練數(shù)據(jù)。
Hinton還舉了訓(xùn)練神經(jīng)網(wǎng)絡(luò)識(shí)別手寫數(shù)字的例子,他把訓(xùn)練數(shù)據(jù)的一半答案故意替換成錯(cuò)誤的(誤差率50%),但是通過反向傳播的訓(xùn)練,最終模型的誤差率會(huì)降到5%或更低。
這就像是聰明的學(xué)生最終會(huì)超過自己的老師。大型神經(jīng)網(wǎng)絡(luò)實(shí)際上具有超越訓(xùn)練數(shù)據(jù)的能力,這是大多數(shù)人未曾意識(shí)到的。
此外,Hinton認(rèn)為當(dāng)今的多模態(tài)模型將帶來很大的改變。
僅從語言角度來看,模型很難理解一些空間事物。但是,當(dāng)模型成為多模態(tài)時(shí)(既能接收視覺信息,又能伸手抓東西,能拿起物體并翻轉(zhuǎn)),它就會(huì)更好地理解物體。多模態(tài)模型需要更少的語言,學(xué)習(xí)起來會(huì)更容易。
預(yù)測(cè)下一個(gè)視頻幀、預(yù)測(cè)下一個(gè)聲音,我們的大腦或許就是這樣學(xué)習(xí)的。
英偉達(dá)不送GPU
Hinton是最早使用GPU處理神經(jīng)網(wǎng)絡(luò)計(jì)算的人之一。
2006年,一位研究生建議Hinton使用GPU來計(jì)算矩陣乘法。他們最開始使用游戲GPU,發(fā)現(xiàn)運(yùn)算速度提高了30倍。之后Hinton購買了一個(gè)配備四個(gè)GPU的Tesla系統(tǒng)。
2009年,Hinton在NIPS會(huì)議上發(fā)表了演講,告訴在場(chǎng)的一千名機(jī)器學(xué)習(xí)研究人員:「你們都應(yīng)該去購買英偉達(dá)的GPU,這將是未來的趨勢(shì),你們需要GPU來進(jìn)行機(jī)器學(xué)習(xí)。」
然后,Hinton給英偉達(dá)發(fā)了一封郵件,說我已經(jīng)告訴一千名機(jī)器學(xué)習(xí)研究人員去購買你們的顯卡,你們能否免費(fèi)給我一個(gè)?
——英偉達(dá)并沒有回復(fù)。
很久以后,Hinton把這個(gè)故事告訴老黃,老黃趕緊送了一個(gè)。

硬件模擬神經(jīng)網(wǎng)絡(luò)
在谷歌的最后幾年里,Hinton一直在思考如何嘗試進(jìn)行模擬計(jì)算。這樣,我們就可以使用跟大腦一樣的功率(30瓦),來運(yùn)行大型語言模型,而不是一兆瓦的功率。
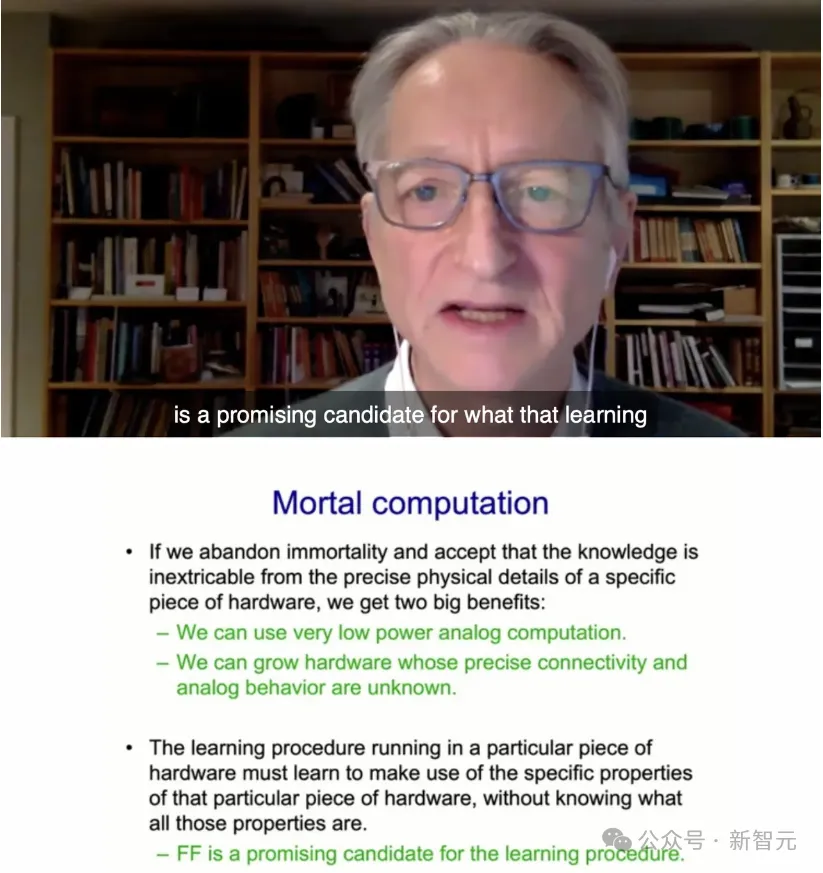
每個(gè)人的大腦都不相同,所以在這種低功耗的模擬計(jì)算中,每個(gè)硬件都會(huì)有所不同,各個(gè)神經(jīng)元的精確屬性也不同。
人終有一死,大腦中的權(quán)重在人死后就會(huì)丟失,但數(shù)字系統(tǒng)是不朽的,權(quán)重可以被存儲(chǔ)起來,計(jì)算機(jī)壞了也不影響。
假設(shè)有一大批數(shù)字系統(tǒng),它們從相同的權(quán)重開始,各自進(jìn)行微量的學(xué)習(xí),然后共享權(quán)重,這樣它們都能知道其他系統(tǒng)學(xué)到了什么。然而,我們?nèi)祟悷o法做到這一點(diǎn),因此在知識(shí)共享方面,數(shù)字系統(tǒng)遠(yuǎn)勝于我們。
快速權(quán)重
到目前為止,神經(jīng)網(wǎng)絡(luò)模型都只有兩個(gè)時(shí)間尺度:接收輸入時(shí)的快速變化,和調(diào)整權(quán)重時(shí)的緩慢變化。
然而在大腦中,權(quán)重的時(shí)間尺度有很多。
比如我說了一個(gè)詞「黃瓜」,五分鐘后,你戴上耳機(jī),聽到很多噪音和一些模糊的單詞,但你能更好地識(shí)別「黃瓜」這個(gè)詞,因?yàn)槲椅宸昼娗罢f過這個(gè)詞。
大腦中的這些知識(shí)是如何存儲(chǔ)的呢?顯然是突觸的暫時(shí)變化,而不是神經(jīng)元在重復(fù)「黃瓜」這個(gè)詞——Hinton稱之為快速權(quán)重。
Hinton的擔(dān)憂
Hinton認(rèn)為,科學(xué)家應(yīng)該做一些有助于社會(huì)的事情,當(dāng)你被好奇心驅(qū)使時(shí),你會(huì)做最好的研究。但是,這些事情會(huì)帶來很多好處,也可能會(huì)造成很多傷害,我們需要關(guān)注它們對(duì)社會(huì)的影響。
比如壞人使用AI做壞事,將人工智能用于殺手機(jī)器人,操縱公眾輿論或進(jìn)行大規(guī)模監(jiān)視。這些都是非常令人擔(dān)憂的事情。
而人工智能領(lǐng)域的發(fā)展不太可能放緩,因?yàn)槭撬菄H性的,即使一個(gè)國家放緩,其他國家也不會(huì)。
這種擔(dān)憂也讓小編想起了與Hinton一脈相承的Ilya。
從多倫多的實(shí)驗(yàn)室,到OpenAI的核設(shè)施,Ilya一直牢記恩師的教誨:道路千萬條,安全第一條。監(jiān)管不規(guī)范,教父兩行淚。























