













首次證實白盒Transformer可擴展性!馬毅教授CRATE-α:鯨吞14億數據,性能穩步提升
在過去的幾年里,Transformer架構在自然語言處理(NLP)、圖像處理和視覺計算領域的深度表征學習中取得了顯著的成就,幾乎成為了AI領域的主導技術。
然而,雖然Transformer架構及其眾多變體在實踐中取得了巨大成功,但其設計大多是基于經驗的,并沒有嚴格的數學解釋,也在一定程度上限制了研究人員的思路,無法開發出更高效、更具可解釋性的Transformer新變體。
為了填補這一空白,馬毅教授團隊曾發布過白盒Transformer模型CRATE,其架構的每一層都是通過數學推導得到的,可以完全解釋為展開的梯度下降迭代;此外,CRATE學習到的模型和特征在語義上也比傳統的Transformer模型具有更好的可解釋性,例如,即使模型僅在分類任務上進行訓練,可視化圖像的特征也能自然地形成該圖像的零樣本分割。
然而,到目前為止,CRATE的應用規模仍然相對有限,CRATE-Large只包含77.6M參數,與標準Vision Transformer(ViTs)的22B參數量形成了鮮明對比。
最近,加利福尼亞大學圣克魯斯分校和伯克利分校的研究團隊聯合提出了CRATE-α,首次探索了不同規模的CRATE用于視覺任務(從Tiny到Huge)時的模型性能,研究人員在CRATE架構設計中對稀疏編碼塊進行了策略性但最小化的(strategic yet minimal)修改,并設計了一種輕量級的訓練方法,以提高CRATE的可擴展性。

論文鏈接:https://arxiv.org/pdf/2405.20299
項目鏈接:https://rayjryang.github.io/CRATE-alpha/
具體來說,CRATE中的ISTA模塊是限制進一步擴展的因素,為了克服這一限制,CRATE-α主要做了三個修改:
1. 大幅擴展了通道,對稀疏編碼塊進行過參數化(overparameterized),使用過完備字典(overcomplete dictionary)對token表征進行稀疏化。
2. 解耦了關聯矩陣,在稀疏編碼塊的最后一部中引入一個解耦字典(decoupled dictionary)
3. 添加了殘差連接。
實驗結果證明,CRATE-α能夠隨著模型尺寸和訓練數據集的增大而擴展,性能可以持續提升。
例如,CRATE-α-B在ImageNet分類任務上的性能顯著超過了之前最好的CRATE-B模型,準確率提高了3.7%,達到了83.2%;進一步對模型進行擴展時,CRATE-α-L在ImageNet分類任務上達到了85.1%的準確率。
值得注意的是,模型性能的提升是在保持甚至增強了CRATE模型可解釋性的同時實現的,因為更大尺寸的CRATE-α模型學到的token表征能夠生成更高質量的無監督圖像分割。
實驗結果
從基礎尺寸(base)到大尺寸(large)
ImageNet-21K是一個廣泛用于圖像識別和分類任務的大型數據集,文中用于訓練的數據集版本包含19,000個類別和大約1300萬張圖片,由于數據丟失,比標準數據集(包含21,000個類別和大約1400萬張圖片)的數據量要少一點。
在預訓練時,從數據集中隨機選取1%作為驗證集。
預訓練完成后,在ImageNet-1K數據集上對模型進行微調,其中ImageNet-1K是一個更小的子集,包含1000個類別,通常用于模型的最終評估。在微調階段,模型會針對這1000個類別進行更精細的訓練,以提高其在特定任務上的性能。
最后,在ImageNet-1K的驗證集上評估模型的性能。

研究人員對比了在32、16和8像素塊大小下的CRATE-α-B和CRATE-α-L,從實驗結果中可以看到,CRATE-α-L在所有像素塊大小上都取得了顯著的改進,但從CRATE-B增加到CRATE-L只能帶來0.5%的性能提升,表明了收益遞減的情況,證明了CRATE-α模型的可擴展性顯著優于普通CRATE

同時,預訓練階段的訓練損失顯示,隨著模型容量的增加,訓練損失的趨勢可預測地得到改善。
從大(large)到巨大(huge)
多模態數據集DataComp1B包含14億圖文對,可以提供足夠的數據來訓練和擴展模型。
研究人員采用對比學習的方法來訓練CRATE-α,不僅能夠利用上龐大的圖文對數據集,還能在模型尺寸從大到巨大的提升過程中,觀察到顯著的性能提升。
然而,直接訓練一個類似CLIP的模型需要巨大的計算資源,研究人員采用了優化后的CLIPA協議,可以在減少計算資源消耗的同時,可以保持與CLIP相當的性能。
最后,為了評估CRATE-α模型的性能,研究人員采用了零樣本學習的方法,在ImageNet-1K數據集上測試模型的準確率,該方法可以有效地評估模型在面對未見過類別數據時的泛化能力,提供了一個衡量模型可擴展性和實用性的重要指標。
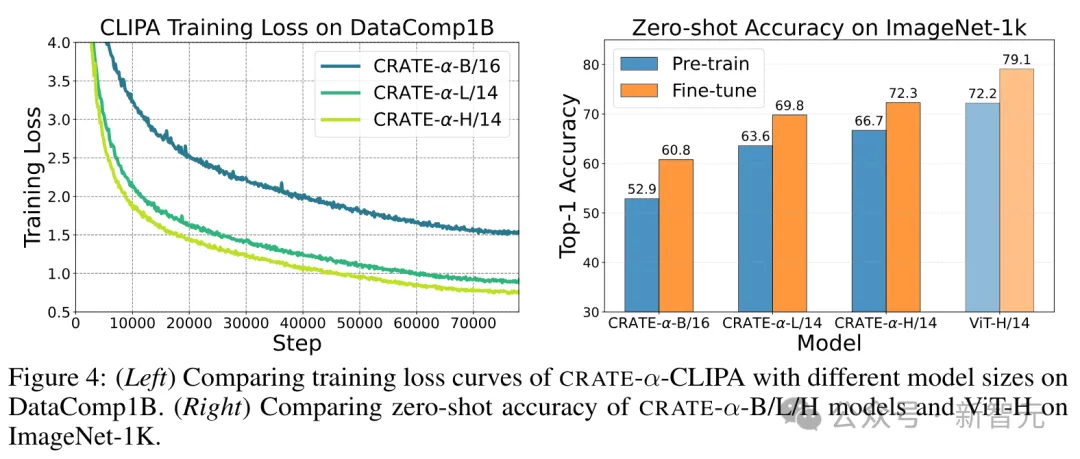
從實驗結果中可以看到,
1. 模型尺寸的影響:CRATE-α-CLIPA-L/14在預訓練和微調階段的ImageNet-1K零樣本準確率上,分別比CRATE-α-CLIPA-B/16高出11.3%和9.0%,表明學習到的表征質量可能受到模型尺寸的限制,即增加模型尺寸可以利用上更多數據。
2. 擴展模型尺寸的益處:當繼續增加模型尺寸時,可以觀察到CRATE-α-CLIP-H/14從更大的訓練數據集中繼續獲益,在預訓練和微調階段的ImageNet-1K零樣本準確率上,分別比CRATE-α-CLIP-L/14高出3.1%和2.5%,證明了CRATE-α模型的強大可擴展性。
3. 性能上限的探索:為了探索性能的上限,研究人員從頭開始訓練了一個標準的ViT-CLIPA-H/14,并觀察到了性能的提升。
節省計算資源的擴展策略
在追求模型擴展的效率和計算資源的優化方面,研究人員發現,通過調整預訓練階段的圖像token序列長度,可以在極大減少計算資源消耗的同時,保持模型性能。
具體來說,研究人員嘗試了一種新的方法:在預訓練時使用較長序列長度的CRATE-α-L/32,在微調時切換到較短序列長度的CRATE-α-L/14或CRATE-α-L/8,不僅大幅度降低了預訓練階段的計算成本,而且在微調后,模型在ImageNet-1K數據集上的準確率仍然非常接近全尺寸模型的性能。
例如,使用CRATE-α-L/32進行預訓練,然后微調到CRATE-α-L/14,可以節省約70%的計算資源,而準確率只是略有下降;更進一步,當從CRATE-α-L/32預訓練后微調到CRATE-α-L/8時,僅使用了原模型所需訓練時間的10%,準確率依然達到了84.2%,與全尺寸模型的85.1%相差無幾。
上述結果表明,通過精心設計預訓練和微調階段的策略,可以在資源有限的情況下,有效地擴展CRATE-α模型。
CRATE-α的語義可解釋性得到提升
除了可擴展性,文中還研究了不同模型大小的CRATE-α的可解釋性,使用MaskCut來驗證和評估模型捕獲的豐富語義信息,包括定性和定量結果。

為CRATE-α、CRATE和ViT在COCO val2017上提供了分割可視化后,可以發現,CRATE-α模型保持甚至提高了CRATE的(語義)可解釋性優勢。
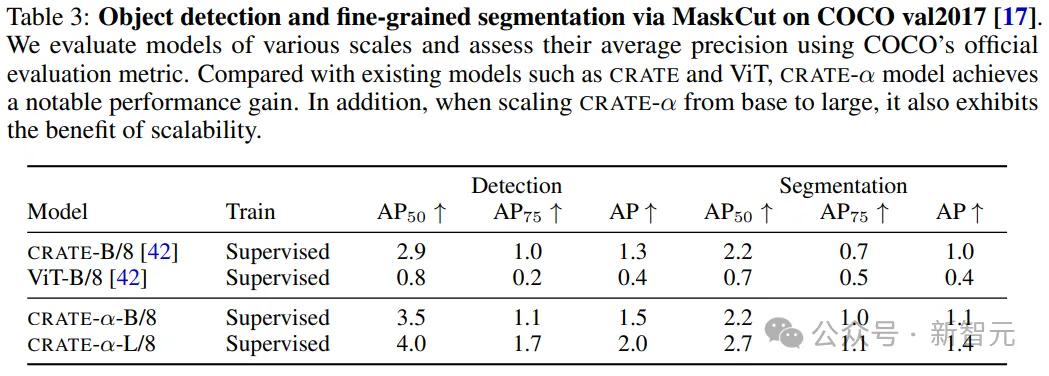
在COCO val2017上的定量評估結果顯示,當為CRATE-α擴展模型大小時,大型模型在目標檢測和分割方面比base模型有所提高。
















