













大語言模型兵馬未動,數據準備糧草先行
從OpenAI正式發布ChatGPT開始,大型語言模型(LLM)就變得風靡一時。對業界和吃瓜群眾來說,這種技術最大的吸引力來自于理解、解釋和生成人類語言的能力,畢竟這曾被認為是人類獨有的技能。類似CoPilot這樣的工具正在迅速融入開發者的日常工作,而由ChatGPT驅動的應用程序也開始變得日益主流。
延伸閱讀,點擊鏈接了解 Akamai cloud-computing
大語言模型的流行,另一方面也要歸功于普通開發者也能輕松用上這樣的技術。隨著大量開源模型陸續涌現,每天都有新的科技初創公司提出基于大語言模型的解決方案。
然而,就算到了AI時代,數據依然是一種“新的石油”。在機器學習領域,數據充當了訓練、測試和驗證模型的原材料。高質量、多樣化、有代表性的數據對于創建準確、可靠和健壯的大語言模型至關重要。
我們在構建自己的大語言模型時可能會面臨挑戰,特別是在收集和存儲數據這方面。大量非結構化數據如何處理,以及該如何存儲和管理對數據的訪問,這些可能只是各種挑戰中的一小部分。
本文將探討與數據管理有關的挑戰,借此讓讀者清楚了解數據在大語言模型中的關鍵作用,并在此基礎上,為讀者在自己的大語言模型項目中有效管理數據提供所需知識。
首先,一起看看有關大語言模型的基礎知識吧。
大語言模型的工作原理以及現有模型的選擇
從較高層次來看,大語言模型的工作原理很簡單:將單詞(或句子)轉換為一種稱為嵌入(Embedding)的數值表達。這些“嵌入”捕獲了單詞間的語義含義和關系,模型就是借此理解語言的。例如,大語言模型會學習到“狗”和“小狗”這兩個詞是相關的,并且會將它們放在數值空間中更接近的位置,而“樹”這個詞則會較遠。

大語言模型最關鍵的部分是神經網絡,這是一類受到人腦功能啟發創建出的計算模型。神經網絡可以從訓練數據中學習這些嵌入及其相互之間的關系。與大多數機器學習應用一樣,大語言模型需要大量數據。通常情況下,對于模型訓練而言,數據量越大、質量越高,模型的準確性就越高,這意味著我們需要一種良好的方法來管理大語言模型用到的數據。
權衡現有模型時需要考慮的因素
幸運的是,對于開發者而言,目前有很多開源的大語言模型可供選擇,其中不乏一些流行的,甚至可商用的,例如Databricks提供的Dolly、Meta提供的Open LLaMA等。
面對如此廣泛的選擇,想要找到合適的開源大語言模型可能就有些棘手了。我們必須了解大語言模型所需的計算和內存資源。模型的大小(例如輸入參數為30億與70億之間的模型)會影響運行和使用模型所需的資源量。因此必須考慮選擇能與自己能力相匹配的模型。例如,一些DLite模型專門設計為能在筆記本電腦上運行,而不需要高成本的云資源。
在研究每個大語言模型時,一定要注意該模型是如何訓練的,以及通常適用于什么樣的任務。這些區別也會影響我們的選擇。此時的規劃工作包括:篩選開源模型,了解每個模型的最佳適用場景,并預測自己將需要為每個模型使用的資源。
根據需要大語言模型的應用程序或環境,我們可以選擇從現有大語言模型開始,也可以選擇從零開始訓練一個自己的大語言模型。對于現成的大語言模型,我們可以直接使用它,或者也可以使用額外的數據對模型進行微調,使其更符合自己所要處理的任務特點。
為了根據需求選擇最佳方法,還要求我們對用于訓練大語言模型的數據有深入了解。
大語言模型中使用的數據類型
當涉及到大語言模型的訓練時,通常使用的數據是文本數據。然而,這些文本數據的性質可能有很大差異,了解可能遇到的不同類型數據是很重要的。一般來說,大語言模型用到的數據可分為兩種類型:半結構化數據和非結構化數據。結構化數據(即以表格數據集形式表示的數據)通常不太可能用在大語言模型的訓練工作中。
· 半結構化數據
半結構化數據會以某種預定義的方式組織,并遵循某種模型。這種組織方式使得數據的搜索和查詢變得相當簡單直接。在大語言模型領域,半結構化數據的類型有很多,例如文本語料庫,其中的每一項都與某些標簽或元數據相關聯。半結構化數據的其他例子包括:
- 新聞文章,每篇文章都與一個類別(如體育、政治或技術)相關聯。
- 用戶評論,每條評論都與評分和產品信息相關聯。
- 社交媒體帖子,每個帖子都與發布者、發布時間和其他元數據相關聯。
在這些情況下,大語言模型可能會根據新聞文章預測類別,根據評論文本預測評分,或根據內容預測社交媒體帖子蘊含的情緒。
· 非結構化數據
另一方面,非結構化數據缺乏預定義的組織或模型。這些數據通常以文本為主,并且可能包含日期、數字和事實,這使得它更加復雜,難以處理和分析。在大語言模型領域,非結構化數據非常普遍,例如:
- 書籍、文章和其他長篇內容
- 從采訪或播客中提取的文本記錄
- 網頁或文檔
由于缺乏明確的標簽或組織標記,非結構化數據對大語言模型的訓練更具挑戰性。然而,這類數據也可以產生更通用的模型。例如,用大量書籍語料庫訓練出的模型可能會學會生成逼真的散文,就像GPT-3那樣。

可想而知,數據是大語言模型的核心。但這些數據如何從原始狀態轉換為大語言模型可以使用的格式?讓我們將焦點轉移到其中涉及的關鍵過程上。
大語言模型的數據管道和數據攝入
用于獲取和處理大語言模型數據的基本構件在于數據管道(Data pipeline)和數據攝入(Data ingestion)的概念。
1.數據管道是什么?
數據管道在原始的非結構化數據與完全訓練好的大語言模型之間形成了一個通道,借此確保數據被正確地收集、處理和準備,使其能夠在大語言模型構建過程的訓練和驗證階段順利使用。
數據管道是一組流程,可將數據從源頭移動到一個可以存儲和分析的目的地。通常情況下,其中包括:
- 數據提取:從源頭提取數據,這個源頭可以是數據庫、數據倉庫,甚至外部API。
- 數據轉換:原始數據需要經過清洗和轉換,以便轉換為適合分析的格式。轉換包括處理缺失值、糾正不一致的數據、轉換數據類型或對類別變量進行獨熱編碼(One-hot encoding)。
- 數據加載:轉換后的數據被加載到存儲系統(例如數據庫或數據倉庫)。這些數據隨后可以立即用于機器學習模型中。
當談論數據攝入時,我們指的是這些管道過程的前端,即數據的獲取和為后續使用所進行的準備。
2.大語言模型的數據管道是什么樣子的?
雖然大語言模型的數據管道在一般情況下可能與數據團隊使用的大多數管道有所相似,但大語言模型為管理的數據提出了一些獨特的挑戰。例如:
- 數據提取:大語言模型的數據提取通常更復雜、多樣化且計算密集。由于數據來源可能是網站、書籍、文本記錄或社交媒體,每個來源都有自己的細微差別,需要獨特的方法。
- 數據轉換:由于大語言模型的數據來源范圍非常廣泛,每種類型數據的每個轉換步驟都將不同,需要獨特的邏輯將數據處理成大語言模型可以用于訓練的更標準化的格式。
- 數據加載:在許多情況下,數據加載的最后一步可能需要使用非常規的數據存儲技術。非結構化文本數據可能需要使用NoSQL數據庫,而不像很多數據管道那樣使用關系型數據存儲。
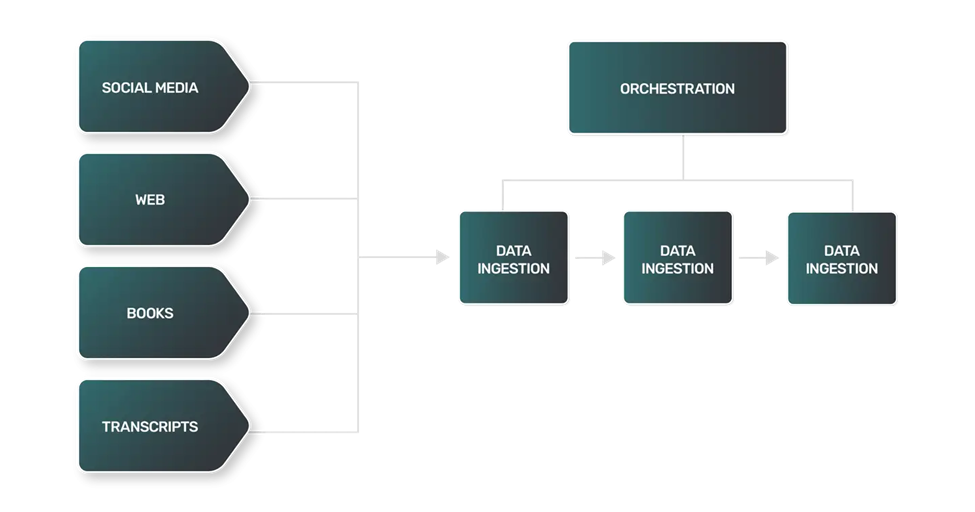
大語言模型的數據轉換過程包括了與自然語言處理(NLP)中類似的技術:
- 詞元化:將文本分解為單個單詞或詞元(Token)。
- 停用詞去除:消除常用詞如“and”、“the”和“is”。然而,根據大語言模型所訓練任務的不同,有時候這類停用詞可能會被保留,這可能是為了保留重要的句法和語義信息。
- 詞形還原:將單詞減少到其基本形式或詞根形式。
可想而知,將所有這些步驟結合起來,從各種來源攝取海量數據,可能會導致一個非常復雜且龐大的數據管道。為了順利完成任務,我們需要適合的工具和資源。
數據攝入的常見工具
數據工程領域有幾個極其流行的工具可以幫助我們處理構成數據管道的一部分復雜數據攝入過程。如果正在構建自己的大語言模型,我們的大部分開發時間將用于收集、清理和存儲用于訓練的數據。那些能夠幫助我們管理大語言模型數據的工具可以按以下方式加以分類:
- 管道編排:用于監視和管理數據管道中過程的平臺。
- 計算:處理大規模數據所用的資源。
- 存儲:用于存儲有效大語言模型訓練所需的大量數據的數據庫。
讓我們詳細看看這三類工具。
1.管道編排
Apache Airflow是一個流行的開源平臺,可用于以編程方式編寫、調度和監視數據工作流。它可以幫助我們使用基于Python的編程接口創建復雜數據管道,這種接口不僅功能豐富,而且易于使用。Airflow中的任務可以組織成有向無環圖(DAG),其中每個節點代表一個任務,邊表示任務之間的依賴關系。
Airflow已被廣泛用于數據提取、轉換和加載操作,它已經成為數據攝入過程中的寶貴工具。Linode Marketplace提供了Apache Airflow,用戶可以借此通過簡單的設置快速上手使用。
2.計算
除了使用諸如Airflow之類的工具進行管道管理,我們還需要能夠可靠地運行大規模處理所需的計算資源。隨著攝入大量文本數據并從許多來源進行下游處理,我們的任務將需要能夠根據需求擴展計算資源,最好是以水平的方式進行擴展。
Kubernetes是一種流行的可擴展計算選項。Kubernetes帶來了靈活性,能與許多工具(包括Airflow)很好地集成。通過利用托管的Kubernetes,我們可以快速、簡單地啟動靈活的計算資源。
3.存儲
數據庫對于數據攝入過程至關重要,它可充當經過清理和轉換后攝入數據的主要目的地。我們可以采用各種類型的數據庫。具體使用哪種類型,這取決于數據的性質和用例的具體要求:
- 關系型數據庫使用表格結構來存儲和表示數據。它適用于具有清晰關系和數據完整性至關重要的數據。盡管我們的大語言模型將依賴于非結構化數據,但像PostgreSQL這樣的關系型數據庫也可以處理非結構化數據類型。
- NoSQL數據庫:NoSQL數據庫包括面向文檔的數據庫,它不使用表格結構來存儲數據,適用于處理大量非結構化數據,可提供高性能、高可用性和易擴展性。
作為大語言模型數據存儲的替代方案,一些工程師更喜歡使用分布式文件系統,例如AWS S3或Hadoop。雖然分布式文件系統是存儲大量非結構化數據的好選擇,但需要額外的工作來組織和管理大型數據集。
在Linode Marketplace提供的各種存儲選項中,我們可以看到托管的PostgreSQL和托管的MySQL。這兩個選項都易于設置,可與大語言模型數據管道連接。
雖然小型大語言模型可能會使用較少的數據進行訓練,并且可以使用較小的數據庫(如單個PostgreSQL節點),但更重的用例將需要處理大量數據。在這些情況下,我們可能需要類似PostgreSQL Cluster的東西來支持將要處理的數據量,并為大語言模型管理數據以及可靠地提供數據服務。
在選擇用于管理大語言模型數據的數據庫時,別忘了考慮數據的性質和具體要求。我們攝入的數據類型將決定哪種數據庫最適合自己的需求。當然,實際用例要求(如性能、可用性和可擴展性)也是重要的考慮因素。
有效和準確地攝入數據對大語言模型的成功至關重要。通過正確使用工具,我們可以為自己的管道構建可靠、高效的數據攝入過程,處理大量數據,并確保大語言模型具備學習和提供準確結果所需的一切。
總結
大語言模型的迅猛崛起在技術領域開辟了新的大門。這項技術對開發者來說易于訪問,但如何管理大語言模型的數據以及利用數據來訓練新的大語言模型或調整現有大語言模型,將決定開發者能否在長期范圍內持續獲得成功。
如果你最近剛開始進行大語言模型項目的相關工作,那么需要在深入研究前先了解基礎知識。為了有效使用大語言模型,我們需要攝入大量非結構化數據,這個過程包括從來源中提取、預處理、轉換和導入。執行這些任務需要Airflow和Kubernetes這樣的工具來進行管道編排和實現可擴展的計算資源。此外,用于大語言模型訓練的數據通常具有非結構化的特性,因此需要像PostgreSQL這樣的數據存儲選項,通過集群可靠地進行規模化運行。
整個數據攝入流程中,大部分環節用到的工具,都已經發布到Linode Marketplace,有需要的用戶只需輕點鼠標即可快速部署并運行。用最短時間完成所有準備工作,然后開始基于大語言模型進行創新吧!
Linode Marketplace是為Linode用戶開放的應用商店
點擊鏈接了解Akamai Linode的解決方案


























