













全球首個(gè)基于大語(yǔ)言模型的自動(dòng)駕駛語(yǔ)言控制模型

Arxiv論文鏈接:https://arxiv.org/abs/2312.03543
項(xiàng)目主頁(yè):https://github.com/Petrichor625/Talk2car_CAVG
近年來,工業(yè)界和學(xué)術(shù)界都爭(zhēng)先恐后地研發(fā)全自動(dòng)駕駛汽車(AVs)。盡管自動(dòng)駕駛行業(yè)已經(jīng)取得了顯著進(jìn)展,但公眾仍然難以完全接受且信任自動(dòng)駕駛汽車。公眾對(duì)完全將控制權(quán)交給人工智能的接受度仍然相對(duì)謹(jǐn)慎,這主要受到了對(duì)人機(jī)交互可靠性的擔(dān)憂以及對(duì)失去控制的恐懼的阻礙。這些挑戰(zhàn)在復(fù)雜的駕駛情境中尤為凸顯,車輛必須做出分秒必爭(zhēng)的決定,這強(qiáng)調(diào)了加強(qiáng)人與機(jī)器之間溝通的緊迫需求。因此,開發(fā)一個(gè)能讓乘客通過語(yǔ)言指令控制車輛的系統(tǒng)顯得尤為重要。這要求系統(tǒng)允許乘客基于當(dāng)前的交通環(huán)境給出相應(yīng)指令,自動(dòng)駕駛汽車需準(zhǔn)確理解這些口頭指令并做出符合發(fā)令者真實(shí)意圖的操作。
得益于大型語(yǔ)言模型(LLMs)的快速發(fā)展,與自動(dòng)駕駛汽車進(jìn)行語(yǔ)言交流已經(jīng)變得可行。澳門大學(xué)智慧城市物聯(lián)網(wǎng)國(guó)家重點(diǎn)實(shí)驗(yàn)室須成忠教授、李振寧助理教授團(tuán)隊(duì)聯(lián)合重慶大學(xué),吉林大學(xué)科研團(tuán)隊(duì)提出了首個(gè)基于大語(yǔ)言模型的自動(dòng)駕駛自然語(yǔ)言控制模型(CAVG)。該研究使用了大語(yǔ)言模型(GPT-4)作為乘客的語(yǔ)意情感分析,捕捉自然語(yǔ)言命令中的細(xì)膩情感內(nèi)容,同時(shí)結(jié)合跨模態(tài)注意力機(jī)制,讓自動(dòng)駕駛車輛識(shí)別乘客的語(yǔ)意目的,進(jìn)而定位到對(duì)應(yīng)的交通道路區(qū)域,改變了傳統(tǒng)乘客和自動(dòng)駕駛汽車交互的方式。該研究還利用區(qū)域特定動(dòng)態(tài)層注意力機(jī)制(RSD Layer Attention)作為解碼器,幫助汽車精確識(shí)別和理解乘客的語(yǔ)言指令,定位到符合意圖的關(guān)鍵區(qū)域,從而實(shí)現(xiàn)了一種高效的“與車對(duì)話”(Talk to Car)的交互方式。

自動(dòng)駕駛汽車?yán)斫獬丝驼Z(yǔ)意,涉及到兩個(gè)關(guān)鍵領(lǐng)域——計(jì)算機(jī)視覺和自然語(yǔ)言處理。如何利用跨模態(tài)的算法,在復(fù)雜的語(yǔ)言描述和實(shí)際場(chǎng)景之間建立有效的橋梁,使得駕駛系統(tǒng)能夠全面理解乘客的意圖,并在多樣的目標(biāo)中進(jìn)行智能選擇,是當(dāng)前研究的一個(gè)關(guān)鍵問題。
鑒于乘客的語(yǔ)言表達(dá)與實(shí)際場(chǎng)景之間存在較大的差異,傳統(tǒng)方法通常難以準(zhǔn)確地將乘客的語(yǔ)言描述轉(zhuǎn)化為實(shí)際駕駛目標(biāo)。現(xiàn)有的挑戰(zhàn)在于:傳統(tǒng)模型很難實(shí)現(xiàn)乘客的意圖分析,模型往往無法在全局場(chǎng)景下進(jìn)行綜合信息分析,由于陷入局部分析而給出錯(cuò)誤的定位結(jié)果。同時(shí)在面對(duì)多個(gè)符合語(yǔ)義的潛在目標(biāo)時(shí),模型如何判斷篩選,從中選擇最符合乘客期待的結(jié)果也是研究的一個(gè)關(guān)鍵難題。

現(xiàn)有的視覺定位的算法主要分為兩大類,One-Stage Methods和Two-Stage Methods:
- One-Stage Methods: One-Stage Methods本質(zhì)上是一種端到端的算法,它只需要一個(gè)單一的網(wǎng)絡(luò)就能夠同時(shí)完成定位和分類兩件事。在這種方法中的核心思想是將文本特征和圖片特征進(jìn)行編碼,然后映射到特定的語(yǔ)意空間中,接著直接在整張圖像上預(yù)測(cè)對(duì)象的類別和位置,沒有單獨(dú)的區(qū)域提取步驟。
- Two-Stage Methods:在Two-Stage Methods中,視覺定位任務(wù)拆成先定位、后識(shí)別的兩個(gè)階段。其核心思想是利用一個(gè)視覺網(wǎng)絡(luò)(如CenterNet),在圖像中識(shí)別出潛在的感興趣區(qū)域(Regions of Interest, ROI),將潛在的符合語(yǔ)意的位置和對(duì)應(yīng)的特征向量保存下來。ROI區(qū)域?qū)⒂杏玫那熬靶畔⒈M可能多地保留下來,同時(shí)濾除掉對(duì)后續(xù)任務(wù)無用的背景信息,隨后在第二個(gè)識(shí)別階段,結(jié)合對(duì)應(yīng)的語(yǔ)意信息在多個(gè)ROI區(qū)域中挑選出最符合語(yǔ)意的結(jié)果。
但不管是哪個(gè)任務(wù),如何更好地理解不同模態(tài)信息之間的交互關(guān)系是圖文視覺定位必須解決的核心問題。
算法和模型介紹
作者將視覺定位問題歸納為:“通過給出乘客的目標(biāo)指令與自動(dòng)駕駛汽車的前視圖,模型能夠處理一幅車輛的正面視圖圖像,以遵循給定的命令,在圖像中準(zhǔn)確指出車輛應(yīng)導(dǎo)航至的目的地區(qū)域。”
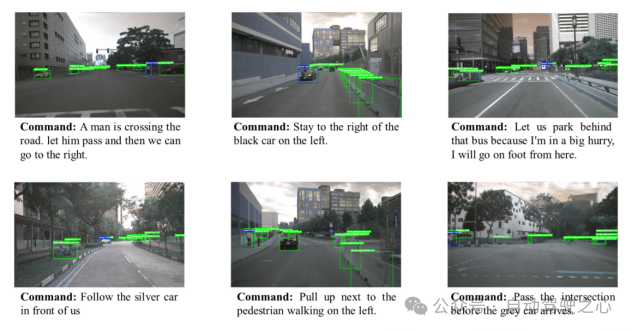
圖1.1 Region Proposal示意圖
為了使這一目標(biāo)具體化,模型將考慮為一個(gè)映射問題:將文本向量映射到候選子區(qū)域中最合適的子區(qū)域。具體而言,CAVG基于Two-Stage Methods的架構(gòu)思想,利用CenterNet模型在圖像I提取分割出多個(gè)候選區(qū)域(Region Proposal),提取出對(duì)應(yīng)區(qū)域的區(qū)域特征向量和候選區(qū)域框(bounding boxes)。如下圖所示, CAVG使用Encoder-Decoder架構(gòu):包含文本、情感、視覺、上下文編碼器和跨模態(tài)編碼器以及多模態(tài)解碼器。該模型利用最先進(jìn)的大語(yǔ)言模型(GPT-4V)來捕捉上下文語(yǔ)義和學(xué)習(xí)人類情感特征,并引入全新的多頭跨模態(tài)注意力機(jī)制和用于注意力調(diào)制的特定區(qū)域動(dòng)態(tài)(RSD)層進(jìn)一步處理和解釋一系列跨模態(tài)輸入,在所有Region Proposals中選擇最契合指令的區(qū)域。
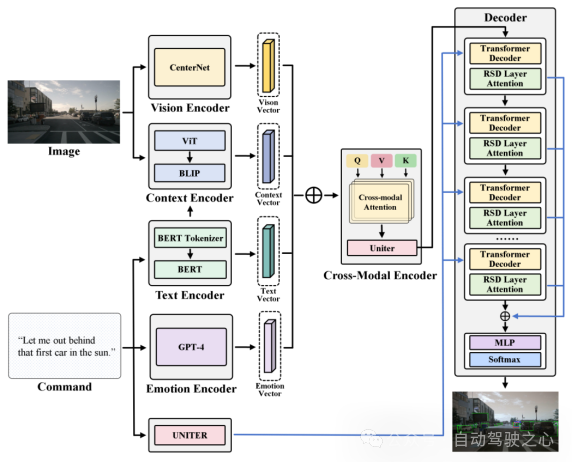
圖1.2 CAVG模型架構(gòu)圖
- Text Encoder: 文本編碼器使用BERT的文本編碼表示生成對(duì)映Command的文本向量,表示為c。輸入命令c通過BERT的Tokenizer分詞器分詞成序列,然后輸入到BERT模型中,生成對(duì)應(yīng)的文本向量,包含了輸入命令的文本特征。

- Emotion Encoder: 情感編碼器調(diào)用 GPT-4 進(jìn)行情感分析。利用GPT4將每條輸入命令都經(jīng)過預(yù)處理,然后它分析文本,識(shí)別乘客對(duì)應(yīng)的情感狀態(tài),劃分歸類為預(yù)定義的類別之一。如Urgent,Comamanding,Informative等。假如對(duì)乘客的指令的情感分析歸類為Urgent,意味著乘客的命令由于其時(shí)間敏感性或關(guān)鍵性質(zhì)需要立即采取行動(dòng)。例如,乘客使用的指令為:“Wow hold on! That looks like my stolen bike over there! Drop me off next to it.”,指令中傳達(dá)了一種需要立即關(guān)注的緊急情緒。情感編碼器識(shí)別出這種情感狀態(tài),作為文本情感向量輸入到模型中,幫助模型推斷的目的地應(yīng)該在最近的靠邊區(qū)域搜索。

- Vison Encoder: 視覺編碼器專門用于從輸入的視覺圖像中提取豐富的視覺信息。視覺編碼器的架構(gòu)基于先進(jìn)的圖像處理技術(shù),編碼器利用CenterNet提取出候選區(qū)域(如樹木、車輛、自行車和行人等),利用ResNet-101網(wǎng)絡(luò)架構(gòu)將這候選區(qū)域的局部特征向量提取出來。

- Context Encoder: 上下文編碼器利用預(yù)訓(xùn)練模型BLIP作為骨架,輸入對(duì)應(yīng)的提取文本向量和全局圖片,將這部分向量進(jìn)行文本-圖片跨模態(tài)對(duì)齊。上下文編碼器采取了一種更全面的方法。該部分編碼器不僅旨在識(shí)別輸入圖像中的關(guān)鍵焦點(diǎn),而且還超越了Region Proposal局部區(qū)域邊界框的限制,辨別整個(gè)視覺場(chǎng)景中更廣泛的上下文關(guān)系。這部分全局特征向量捕捉了一些例如車道標(biāo)記、行人路徑、交通標(biāo)志的關(guān)鍵的上下文細(xì)節(jié)。通過引入全局向量擴(kuò)展的視野使我們的模型能夠吸收更廣泛的視覺信息和上下文線索,確保全面的語(yǔ)義解釋。


圖1.3 Context Encoder中不同層輸出示意圖
- Cross-Modal Encoder: 文章通過提出一種新的跨模態(tài)注意力機(jī)制方法,將跨模態(tài)編碼器通過多頭注意力機(jī)制融合前面的多種模態(tài)向量,將視覺和文本數(shù)據(jù)對(duì)齊和整合。將文本編碼器和情感編碼器得到的文本向量和拼接后,通過線性層映射到和和圖片向量同一個(gè)維度,作為多頭注意力機(jī)制中的查詢向量Q 。同理將視覺編碼器和上下文編碼器得到的向量和分別映射到多頭注意力機(jī)制中的和和特征向量。
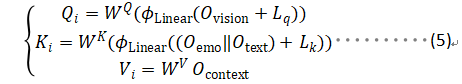


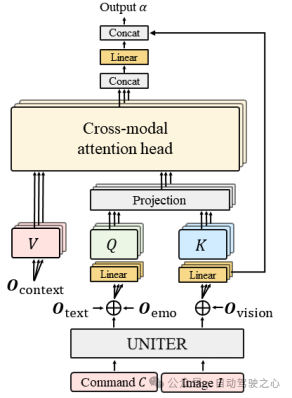
圖1.4 跨模態(tài)注意力機(jī)制示意圖
數(shù)據(jù)集介紹
本工作采用了Talk2Car數(shù)據(jù)集。下圖詳細(xì)比較了Talk2Car和其他Visual Grounding相關(guān)數(shù)據(jù)集(如ReferIt、RefCOCO、RefCOCO+、RefCOCOg、Cityscape Ref和CLEVR-Ref)的異同。Talk2Car數(shù)據(jù)集包含11959個(gè)自然語(yǔ)言命令和對(duì)應(yīng)場(chǎng)景環(huán)境視圖的數(shù)據(jù)集,用于自動(dòng)駕駛汽車的研究。這些命令來自nuScenes訓(xùn)練集中的850個(gè)視頻,其中55.94%的視頻拍攝于波士頓,44.06%的視頻拍攝于新加坡。數(shù)據(jù)集對(duì)每個(gè)視頻平均給出了14.07個(gè)命令。每個(gè)命令平均由11.01個(gè)單詞、2.32個(gè)名詞、2.29個(gè)動(dòng)詞和0.62個(gè)形容詞組成。在每幅圖像中,平均有4.27個(gè)目標(biāo)與描述目標(biāo)屬于相同類別,平均每幅圖片有10.70個(gè)目標(biāo)。下圖解釋了文章所統(tǒng)計(jì)數(shù)據(jù)集中的指令長(zhǎng)度和場(chǎng)景中交通車輛種類的布局。
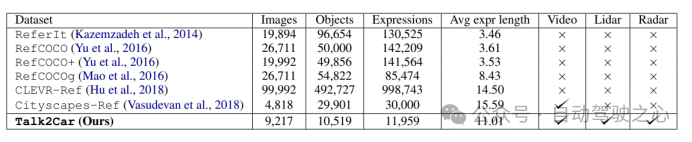
圖1.5 不同Visual Grounding任務(wù)數(shù)據(jù)集之間的場(chǎng)景比較
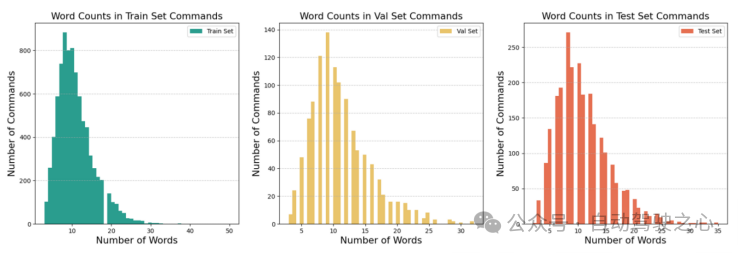
圖1.6 對(duì)Talk2Car挑戰(zhàn)任務(wù)的統(tǒng)計(jì)分析結(jié)果
符合C4AV挑戰(zhàn)賽的要求,我們將預(yù)測(cè)區(qū)域利用bounding boxes在圖中標(biāo)出表示,同時(shí)采用左上坐標(biāo)和右下坐標(biāo)(x1,y1,x2,y2)的格式來提交對(duì)應(yīng)的數(shù)據(jù)結(jié)果。t同時(shí)我們使用scores作為評(píng)估指標(biāo),定義為預(yù)測(cè)的bounding boxes中交并區(qū)域與實(shí)際邊界框相交的比中超過0.5閾值的占比(IoU0.5)。這一評(píng)估指標(biāo)在PASCAL(Everingham和Winn,2012年)、VOC(Everingham等人,2010年)和COCO(Lin等人,2014年)數(shù)據(jù)集等挑戰(zhàn)和基準(zhǔn)測(cè)試中廣泛使用,為我們的預(yù)測(cè)準(zhǔn)確性提供了嚴(yán)格的量化,并與計(jì)算機(jī)視覺和對(duì)象識(shí)別任務(wù)中的既定實(shí)踐相一致。以下方程詳細(xì)說明了預(yù)測(cè)邊界框和實(shí)際邊界框之間的IoU的計(jì)算方法:
實(shí)驗(yàn)結(jié)果
本文使用度量在Talk2Car數(shù)據(jù)集上的模型與各種SOTA方法的性能比較。模型分為三種類型:One-stage、Two-stage和Others,并基于架構(gòu)骨干進(jìn)行評(píng)估:視覺特征提取視覺、語(yǔ)義信息提取語(yǔ)言和整體數(shù)據(jù)同化全局。其他被評(píng)估的成分包括是否使用情緒分類(EmoClf.),全局圖像特征提取(全局Img特征表示),語(yǔ)言增強(qiáng)(NLP Augm.),和視覺增強(qiáng)(Vis Augm.)。“Yes”表示使用了相關(guān)的技術(shù)或者功能組件,“No”表示模型未使用對(duì)應(yīng)的功能和組件,“-”表示
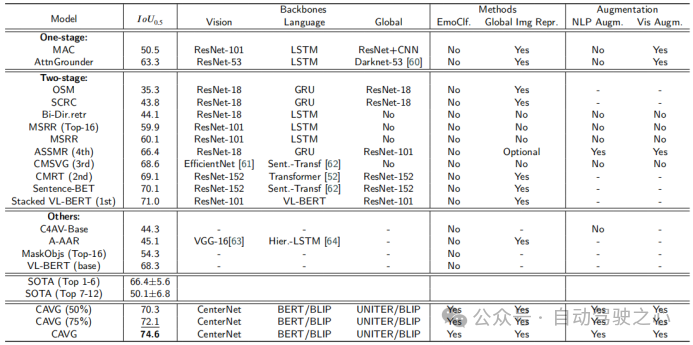
在對(duì)應(yīng)文章中未公開相關(guān)的星系。這種分類闡明了影響每個(gè)模型性能的基本組件和策略。下圖中的粗體值和下劃線值分別代表最佳的模型和第二好的模型。
為了嚴(yán)格評(píng)估CAVG的模型在現(xiàn)實(shí)場(chǎng)景中的有效性,文章根據(jù)語(yǔ)言命令的復(fù)雜性和視覺環(huán)境的挑戰(zhàn),文章精心地劃分了測(cè)試集。一方面,由于較長(zhǎng)的命令可能會(huì)引入不相關(guān)的細(xì)節(jié),或者對(duì)自動(dòng)駕駛汽車來說更難理解。對(duì)于長(zhǎng)文本測(cè)試集,我們采用了一種數(shù)據(jù)增強(qiáng)策略,在不偏離原始語(yǔ)義意圖的情況下,增加了數(shù)據(jù)集的豐富性。我們使用GPT擴(kuò)展了命令長(zhǎng)度,得到的命令范圍從23到50個(gè)單詞。進(jìn)一步評(píng)估模型處理擴(kuò)展的語(yǔ)言輸入的能力,對(duì)模型的適應(yīng)性和魯棒性進(jìn)行全面的評(píng)估。
另一方面,為了進(jìn)一步衡量模型的泛用性,本文還額外選取構(gòu)造了特定的測(cè)試場(chǎng)景場(chǎng)景:如低光的夜晚場(chǎng)景、復(fù)雜物體交互的擁擠城市環(huán)境、模糊的命令提示以及能見度下降的場(chǎng)景,使預(yù)測(cè)更具困難。將而外構(gòu)造的兩個(gè)測(cè)試集合分別稱為為L(zhǎng)ong-text Test和Corner-case Test。
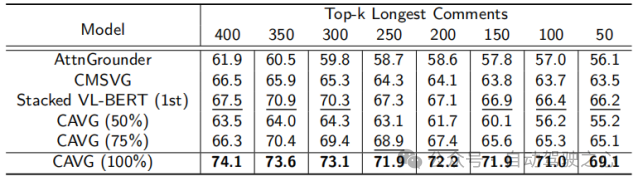
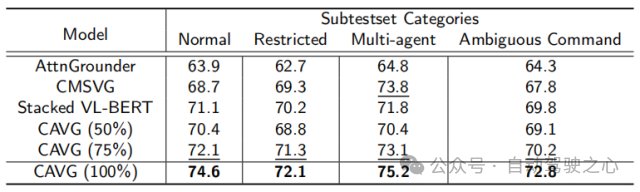
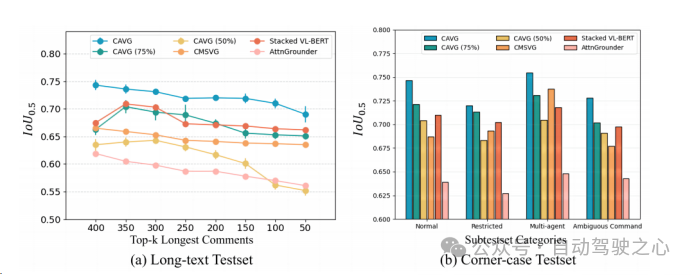

除此之外,僅使用一半的數(shù)據(jù)集CAVG(50%)和CAVG(75%)迭代顯示出令人印象深刻的性能。提供足夠的訓(xùn)練數(shù)據(jù)時(shí),我們的模型CAVG和CAVG(75%)在部分特殊場(chǎng)景中表現(xiàn)出色。


本文在RSD Layer Attention機(jī)制的多模態(tài)解碼器中可視化了13層的層注意權(quán)值的分布,以進(jìn)一步展示文章所使用的RSD層注意機(jī)制的有效性。根據(jù)其與地面真實(shí)區(qū)域?qū)R,將輸入?yún)^(qū)域劃分為兩個(gè)不同的組:> 0:包含所有超過0的區(qū)域,表明與地面真實(shí)區(qū)域有重疊。= 0:構(gòu)成沒有重疊的區(qū)域,其精確地為0。如下圖所示,較高的解碼器層(特別是第7至第10層)被賦予了較大比例的注意權(quán)重。這一觀察結(jié)果表明,向量對(duì)這些更高的層有更大的影響,可能是由于增加的跨模態(tài)相互作用。與直觀預(yù)期相反,最頂層并不主導(dǎo)注意力的權(quán)重。這與傳統(tǒng)的主要依賴于最頂層表示來預(yù)測(cè)最佳對(duì)齊區(qū)域的技術(shù)明顯不同,RSD Layer Attention機(jī)制會(huì)避開其他層中固有的微妙的跨模態(tài)特征。
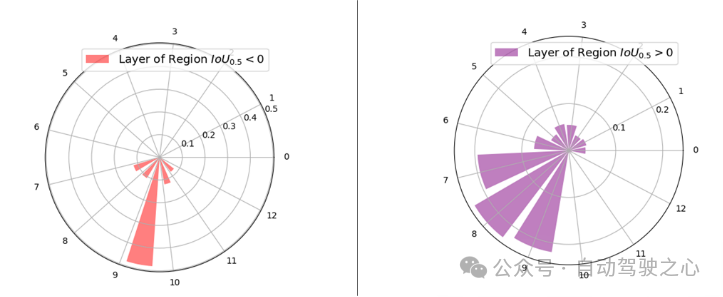

圖1.7 VIT中不同層的注意力分布示意圖

圖1.8 調(diào)研用戶歲數(shù)和駕駛經(jīng)驗(yàn)分布

圖1.9 用戶調(diào)研結(jié)果






























