極速優化:十倍提升JS代碼運行效率的技巧
作者 | ecznlai@騰訊文檔
前段時間通過優化業務里的相關實現,將高頻調用場景性能優化到原來的十倍,使文檔核心指標耗時達到 10~15% 的下降。本文將從 V8 整體架構出發,深入淺出 V8 對象模型,從匯編細節點出其 ICs 優化細節以及原理,最后根據這些優化原理來編寫超快的 JS 代碼 。

一、V8 compiler pipeline
js 代碼從源碼到執行 —— v8 編譯器管線:

parser 將源碼編譯為 AST,并在 AST 基礎上編譯為「字節碼 bytecode」
ignition 是 v8 的字節碼解釋器,可以運行字節碼,并在運行過程中持續收集「feedback」即綠線,給到 turbofan 做最終的機器碼編譯優化。
而由于 js 是相當動態的語言,編譯出來的「機器指令」未必能正確,因此其運行過程中有可能要回滾到 ignition 解釋器來運行,這些問題通過「紅線」反饋給 ignition 解釋器,這個過程叫做「反優化」。
—— 更具體來說:
(1) Parser (Source => Token => AST)
將源碼一段線性 buffer string 解析為 Token 流,最后依據 Token 流生成 AST 樹狀構造,這是所有語言都會有的過程。
(2) 綠線與 feedback
運行過程中產生并持續收集的反饋信息,比如多次調用 add(1, 2) 就會產生「add 函數的兩個參數 “大概率” 是整數」的反饋,v8 會收集這類信息,并在后續 TurboFan codegen 的時候根據這些反饋來做假設,并依據這些假設做深度優化,后文將從匯編的角度討論這個細節。
(3) 紅線與反優化 deoptimize
前面提到 「add 函數的兩個參數 “大概率” 是整數」 的假設,當假設被打破的時候會觸發所謂的「deoptimize」反優化,比如你在運行了很久的 add(number, number) 上突然來一個 add("123", "abc") 那么此時就會降級重新回到 ignition bytecode 執行。
(4) Iginition 和 TurboFan
前者生成 byte code,后者根據執行過程中收集的 feedback 來生成深度優化的 machine code
二、V8 核心組件:Ignition 與字節碼 / TurboFan 與機器碼
1. 代碼的執行層次: 從源碼到字節碼再到機器碼其實就是不斷編譯的過程
世界上能執行代碼的地方有很多,數軸上的兩個極端: 左邊是抽象程度最高的人腦,右邊是抽象程度最低的 CPU:

上圖中三個實體以不同的角度理解下面這樣的代碼,從源碼到字節碼再到機器碼其實就是不斷編譯為另外一個語言的過程:
const a = 3 + 4;(1) 人腦的理解
計算 3+4 存儲到 js 變量 const a 中。
(2) V8 parser 的理解
將代碼解析為 AST 樹(一種 JSON 結構):
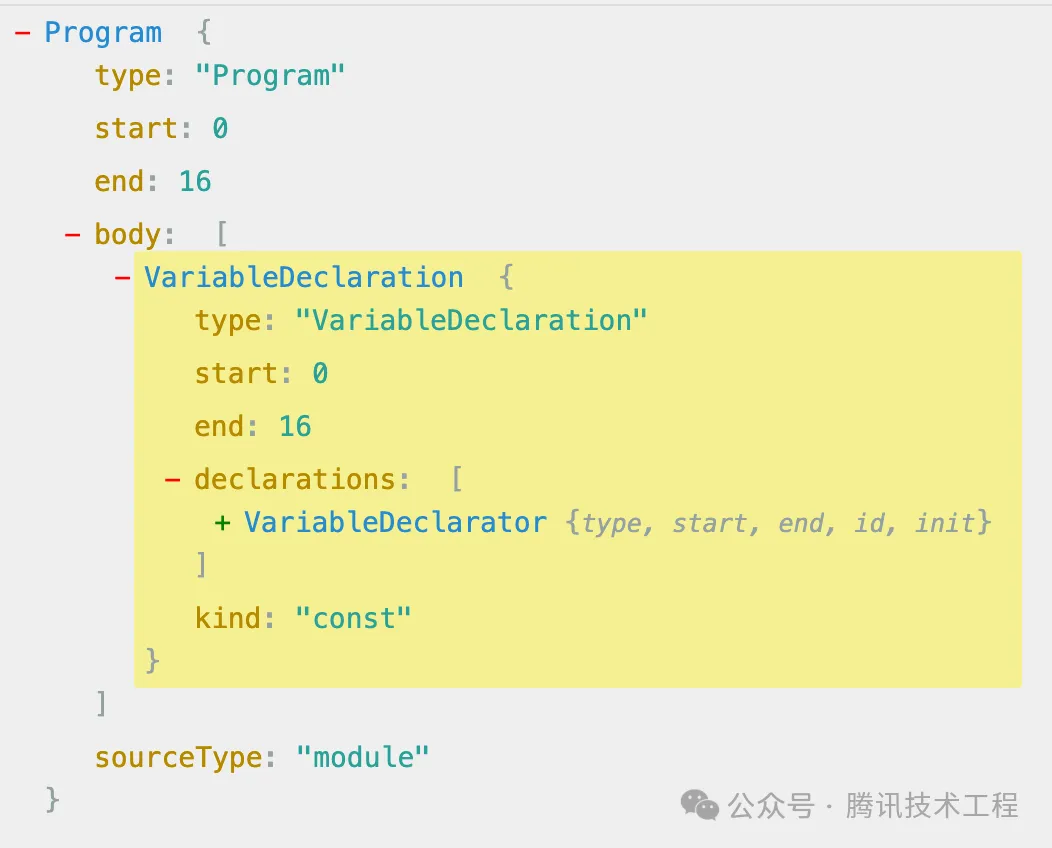
(3) V8 iginition 的理解
iginition 會將代碼理解編譯為 bytecode :
(4) V8 TurboFan 的理解
TurboFan 會將代碼理解為匯編:
2. 本質上來說 bytecode 和 x86 匯編是一樣的
本質上來說 v8 bytecode 和 x86 匯編是一樣的,只是世界上沒有裸機能跑出 v8 所理解的 bytecode 而已,機器碼為什么快是因為 CPU 能在硬件層面上裸跑匯編,因此速度特別快。
總之為了充分表達 js 動態特性以及方便優化為 CPU 能直接裸跑的匯編,v8 引入了 bytecode 這個層次,它比 AST 更接近物理機,因為它沒有層次嵌套,是一種基于寄存器的指令集。
3. 編譯時機:JIT / AOT
JIT 指的是邊運行邊優化為機器碼的編譯技術,其中的代表有 jvm / lua jit / v8,這類優化技術會在運行過程中持續收集執行信息并優化程序性能。AOT 指的是傳統的編譯行為,在靜態類型語言(如 C、C++、Rust)和某些動態類型語言(如 Go、Swift)中得到了廣泛應用,由于能提前看到完整代碼,編譯器/語言運行時可以在編譯階段進行充分的優化,從而提高程序的性能。
由于 JIT 語言并不能提前分析代碼并優化執行,因此 JIT 語言的「編譯期」很薄,而「運行時」相當厚實,諸多編譯優化都是在代碼運行的過程中實現的。
4. Ignition 與字節碼
ignition 負責解釋執行 V8 引入的中間層次字節碼,上接人腦里的 js 規范,下承底層 CPU 機器指令
5. TurboFan 與機器碼
TurboFan 可以將字節碼編譯為最快的機器碼,讓裸機直接運行,達到最快的執行速度。
三、V8 內置 runtime 指令 --allow-natives-syntax
利用這個參數開啟 v8 注入的 runtime call,幫助分析和調試 v8:
# node 下開啟
$ node --allow-natives-syntax
# chrome 下開啟
$ open -a Chromium --args --js-flags="--allow-natives-syntax"
下面是一些常用指令說明。
1. %DebugPrint(something);
可以打印對象在 v8 的內部信息,比如打印一個函數:

2. %OptimizeFunctionOnNextCall(fn);
告訴 v8 下次調用主動觸發優化函數 fn
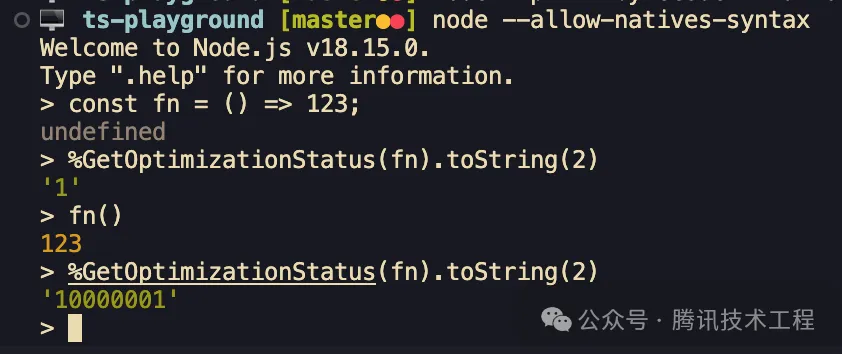
3. %GetOptimizationStatus(fn);
獲取函數當前的優化 status,后文會詳細介紹:
對應的是 V8 源碼里的這個枚舉:
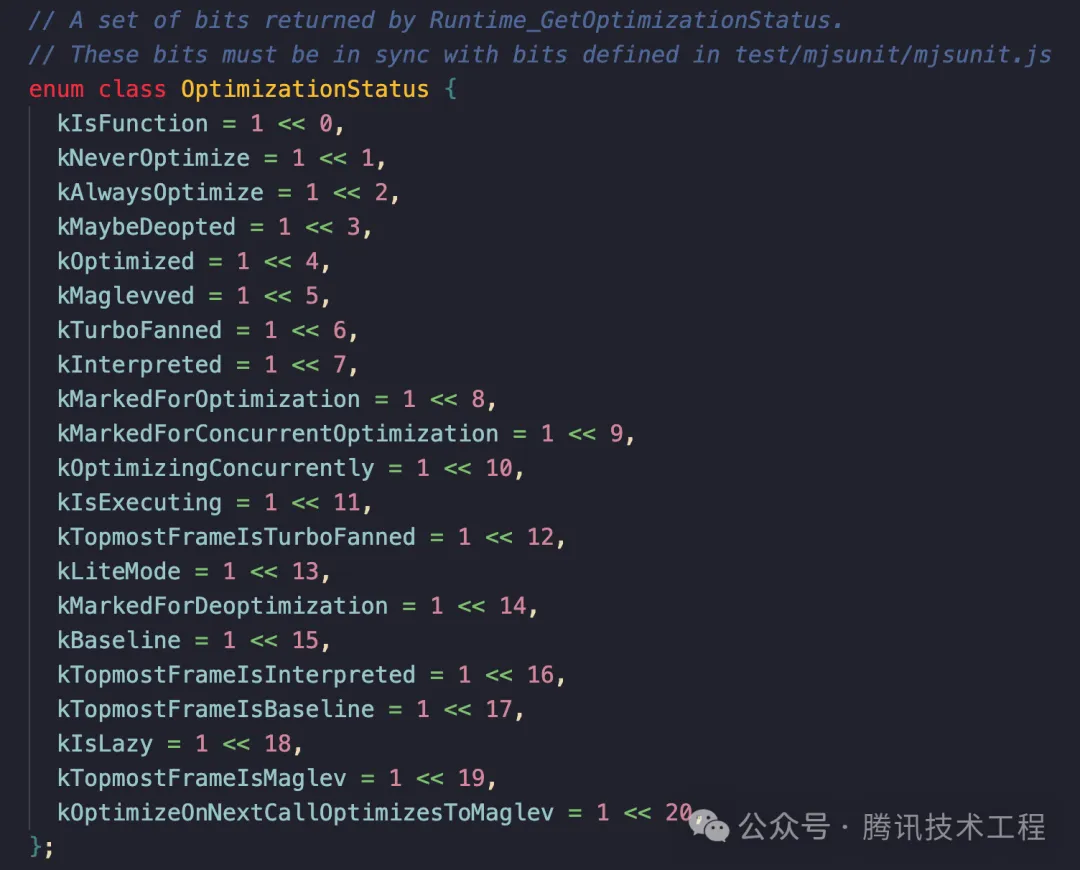
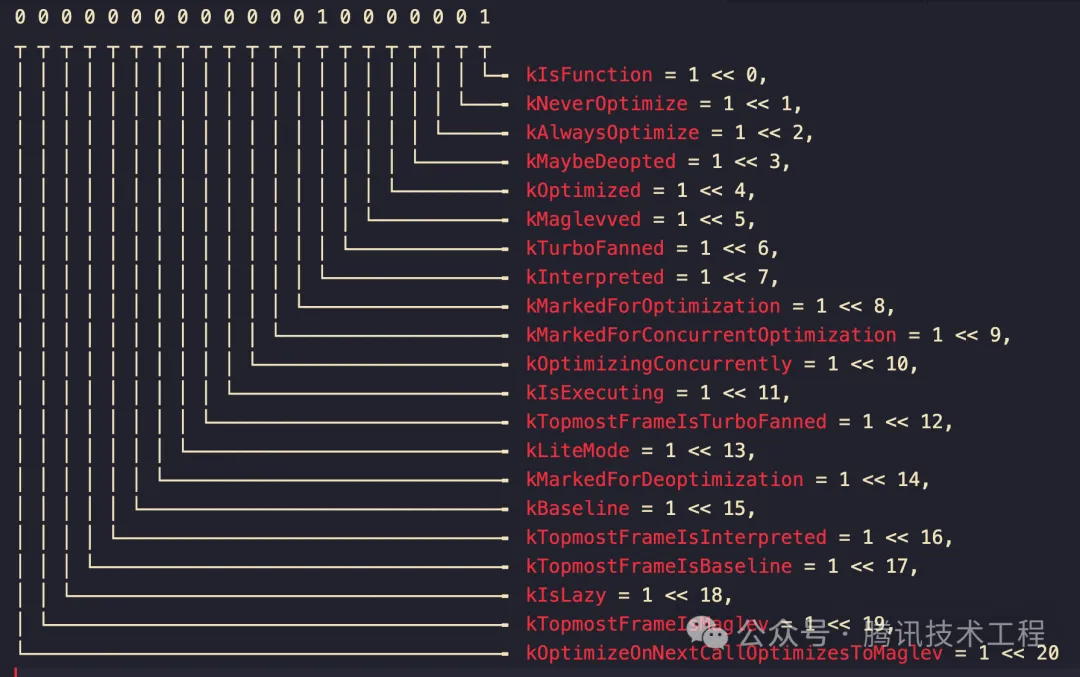
從開發視角來看,一個函數最佳的 status 應該是 00000000000001010001 (81) 即:

4. %HasFastProperties(obj);
%HasFastProperties 可以用來打印對象是否是 Fast Properties 模式

后文會介紹這個 Fast Properties 和與之對立的 Slow Properties。
四、V8 Tagged Pointer
首先 Tagged Pointer 是 C/C++ 里常用的優化技術,不只在 V8 里有用,具體來說就是依據 pointer 自身的數值的某些位來決定 pointer 的行為,也就是說這類指針的特點是「其指針數值上的某些位有特殊含義」。
比如在 v8 里,js 堆指針和 SMI 小整數類型(small intergers)是通過 Tagged Pointer 來表達和引用的,區別就在于最低一位是不是 0 來決定其指針類型:
對象指針(32 位):
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxx1SMI 小整數(32 位)其中 xxx 部分為數值部分:
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxx0用 C 表達就是這樣:
#include <stdio.h>
void printTaggedPointer(void * p) {
// 強轉一下, 關注 p 本身的數值
unsigned int tp = ((unsigned int) p);
if ((tp & 0b1) == 0b0) {
printf("p 是 SMI, 數值大小為 0x%x \n", tp >> 1);
return;
}
printf("p 是堆對象指針, Object<0x%x> \n", tp);
// printObject(*p); // 假設有個方法可以打印堆對象
}
int main() {
printTaggedPointer(0x1234 << 1); // smi
printTaggedPointer(17); // object
return 0;
}運行效果:

備注:
- void * 是 C 的 any,強轉比較多,請忽略 warning;
- 從這也可以看到超過 2^31 的整數或者浮點數就不能用 SMI 了,此時會裝箱為特殊的 HeapObject 放進堆里 );
- 你可以通過 %DebugPrint({}) 和 %DebugPrint(123) 來看看其指針數值是不是整數,然后你會發現所有對象的指針數值都是奇數 Tagged Pointer ( 實際上 heap 內的都是奇數 heapdump 里也能看到這個細節 )。
五、V8 基于 assumption 的 JIT 機器碼優化
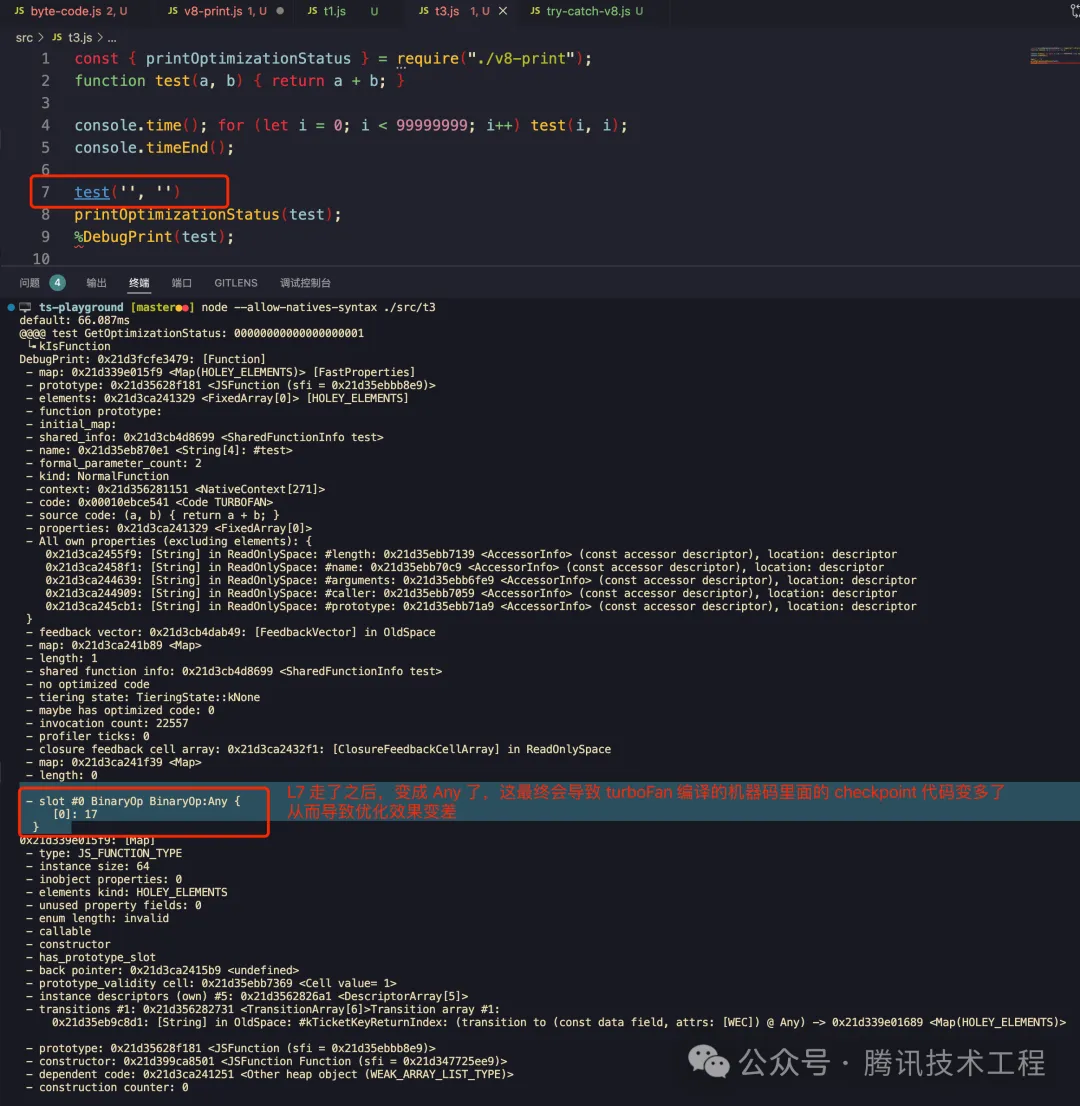
我們先來看這個例子,一個 add(x,y) 函數,如果運行期間出現了多種類型的傳參,那么會導致代碼變慢:
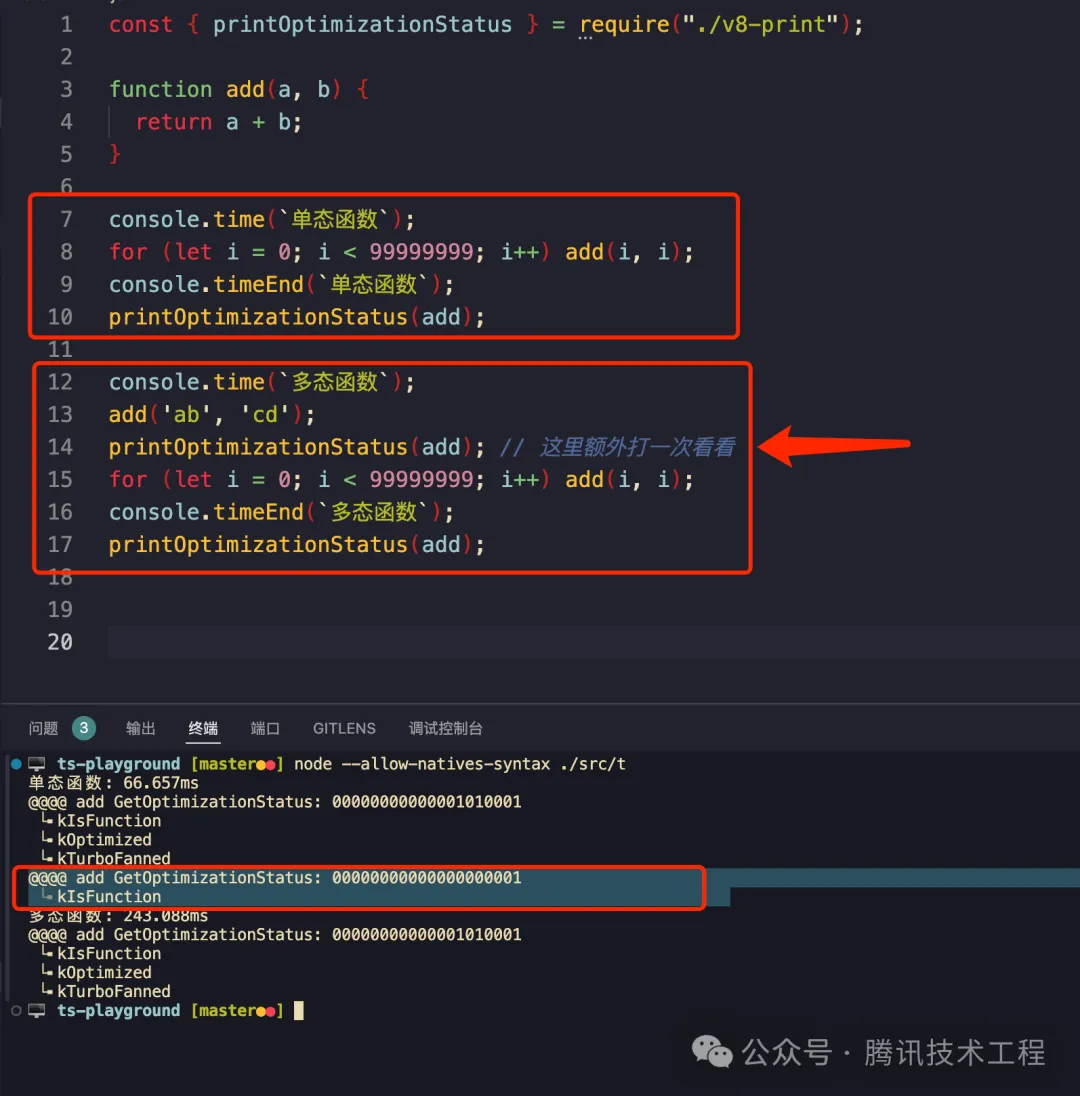
我們可以看到,L15 速度慢了非常多,比一開始的 66ms 慢了幾倍。
原因:
- 一開始只會傳數字的時候,V8 會假設這是數字加法,可以極致優化。(66 毫秒可以跑完)
- L13 傳入其他參數,上述假設會被推翻,此時打印一次優化狀態可以看看出現了 反優化,在 L13 執行的時候實際走的是 iginition 解釋器去跑的。
- 執行 L15 for 循環走了足夠多次后,V8 收集到足夠的 feedback 后會重新建立假設來做優化,不過這次的假設是「入參可能是 number 也可能是 string」—— 這意味著調用的時候要多判斷入參類型是 string 還是 number 從而導致了最終的性能劣化 (一模一樣的代碼要 243 毫秒才跑完,慢了有三倍吧)。
1. assumption 被打破的時候不會 crash / 硬件錯誤 / 段錯誤嗎?
比如一開始傳的是 number,走到了優化過的代碼,里面走的是匯編指令 add;當傳入 string 或者 其他什么合法的 JSValue 后,編譯為匯編的 add 函數的執行真的沒問題嗎?—— 不會有問題,因為 TurboFan 在編譯后的「機器碼」里會帶上很多 checkpoint,其實這些 checkpoint 就是在做類型檢查 type guard,如果類型對不上立刻就會終止這次調用并執行「反優化」讓 ignition 走字節碼解釋執行。
上述說法可能會比較含糊,我們可以具體看看打出來的匯編是咋樣的,可以通過以下方式打印出優化后的 x86 匯編(m1 芯片的蘋果電腦應該是 arm 指令)。
$ node --print-opt-code --allow-natives-syntax --trace-opt --trace-deopt ./a.js$ node --print-opt-code --allow-natives-syntax --trace-opt --trace-deopt ./a.js如下圖所示,這個 test 函數實現是將第一個入參加上 0x1234 并返回,而這個核心邏輯對應 L37 那行匯編,而其他的部分除了 v8 自身的「調用約定」外,其他的就是 checkpoint 檢查類型,以及一些 debug 斷點了:
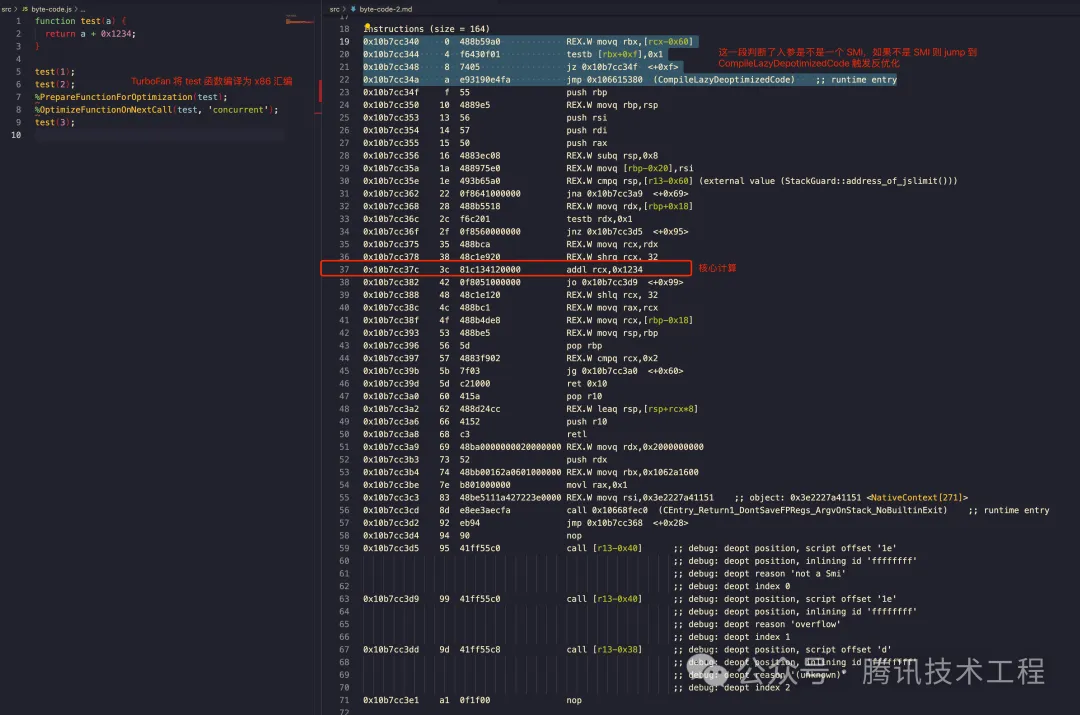
從前面的 Tagged Pointer 的相關討論可知,L19 ~ L22 其實就是在判斷入參是不是 SMI,具體來說是 [rbx+0xf] 與 0x1 做按位與操作([rbx+0xf] 是通過棧傳遞的參數,是 v8 里 js 的調用約定)如果結果是 0 則跳轉 0x10b7cc34f 即后續的正常流程,否則走到 CompileLazyDeoptimizedCode 走反優化流程用字節碼解釋器去執行了,我這里大概寫了一個反匯編偽碼對照:
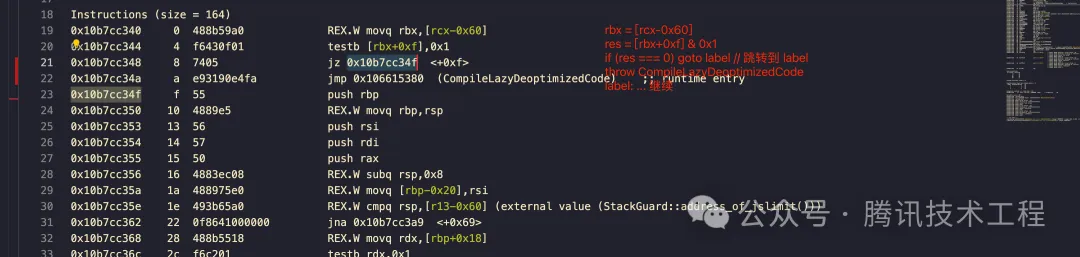
另外我們也可以看到,核心邏輯對應到匯編也就一行,剩余的指令要么是 checkpoint 要么是 v8/js 的調用約定,在這么多冗余指令的情況下執行性能依然很快,可見匯編的執行效率比起 line-by-line 的解釋器要高得多了。
2. 哪里可以打印所謂 feedback ?
通過 %DebugPrint 可以看到

當打破這個 assumption 后,會變成 Any:
3. 多態 return 會導致優化效果打折嗎?
不會

4. feedback slot 里的{Mono|Poly|Mega|}morphic是?
- Monomorphic 單態:指參數的類型只有一種,不會變
- Polymorphic 多態:指參數的類型有多種 (比較短的 union type)
- Megamorphic 巨態:指參數的類型非常復雜 (非常長的 union type)
根據前面提到的 checkpoint,上面三個 mono 的 checkpoint 最少,而最后的 mega 將會非常多,優化性能最差,或者 V8 干脆就不會對這類函數做更深度的機器碼優化了(比如后文會提到的 ICs)
5. TurboFan 過程本身耗時怎么樣?
從 JS AST / bytecode 編譯到機器碼也需要開銷,毫秒級。

6. 反優化太多次怎么辦?
根據這篇文章 V8 function optimization - Blog by Kemal Erdem 如果某個函數「反優化」超過 5 次后,v8 以后就不再會對這個函數做優化了,不過我無法復現他說的這個情況,可能是老版本的 v8 的表現,node16 不會這樣,不管怎樣只要 run 了足夠多次都turbofanned,只是如果「曾經傳的參數類型太 union typed」會導致優化效果出現非常大的折損。
7. 什么時候會啟動 TutboFan ?
前面我們已經知道了「運行足夠多次」會觸發優化,而這只是其中一種情況,具體可以參考 v8 里 ShouldOptimize 的實現,里面有詳細定義何時啟動優化:

作為開發視角來看:
- L371 已經優化過的代碼不會再優化;
- L375 這段邏輯決定是否啟用 maglev (具體見備注);
- L386 通過參數主動禁用/或者省電模式等這類不會優化 ( 比如 node --v8-optinotallow="--turbo_filter=xxxxx" );
- L394 運行足夠多次才會優化 (還有個配置項 efficiency_mode_delay_turbofan 配置延遲多久啟動 turbofan);
- L402 太長的函數不會優化。
備注:maglev 是去年 chrome v8 團隊搞的新特性 —— 編譯層次優化,總的來說就是根據 feedback 對機器碼的編譯層次做精細控制來達到更好的優化效果,下圖是 v8 團隊發布的 benchmark 對比:

具體可參考 v8.dev/blog/maglev
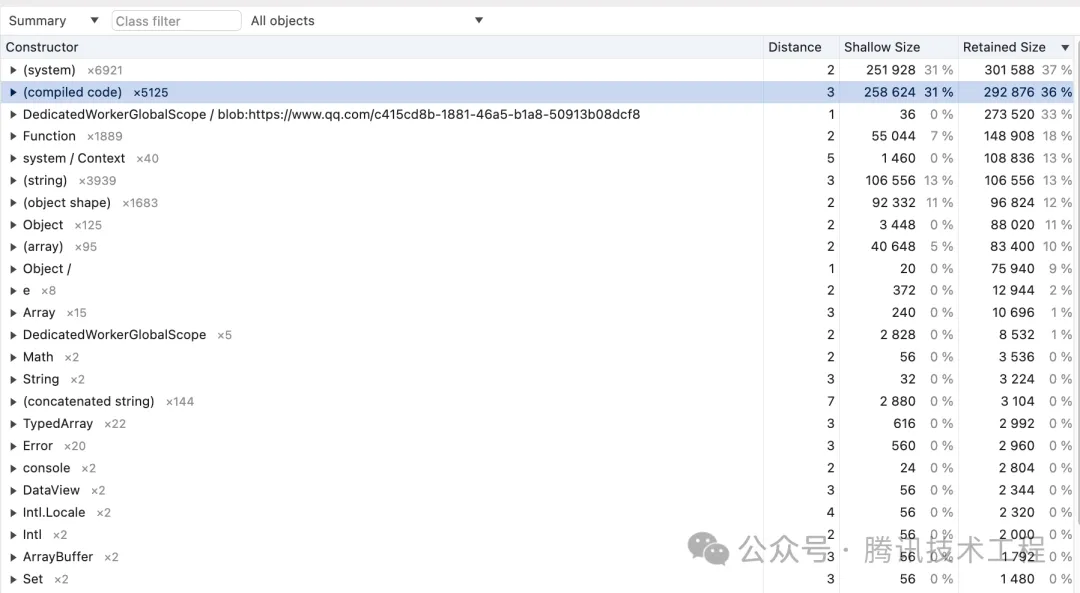
8. 編譯后的代碼會占內存嗎?
會的,而且有時候這部分內存占用非常多,這也是 Chrome 經常被調侃為內存殺手的重要原因之一,以 qq.com 為例,具體對應是 heapdump 里的 (compiled code) 包含了編譯后的代碼內存占用:
六、?? V8 對象模型
本節開始是本文的重點部分,因為只有了解 V8 對象的內存構造,才能真正理解 V8 諸多優化的理由。
1. C 語言的 struct 是怎么實現「點讀」的 ?
在正式進入之前,我們先看看 C 里面 struct 的「點讀」是怎么做的。
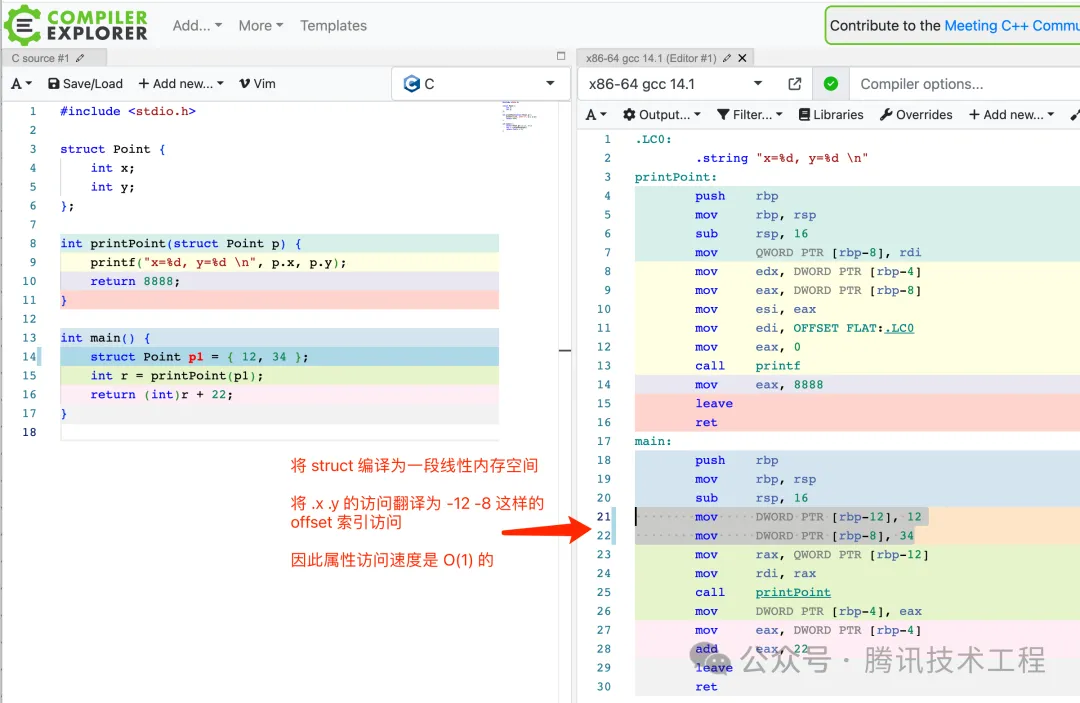
C 會將 struct 理解為一段連續的線性 buffer 結構,并在上面根據字段的類型來劃分好從下標的哪里到哪里是哪個字段(對齊),因此在編譯 point.x 的時候會改成 base+4 的方式進行屬性訪問,如下圖所示,時間復雜度是 O(1) 的:
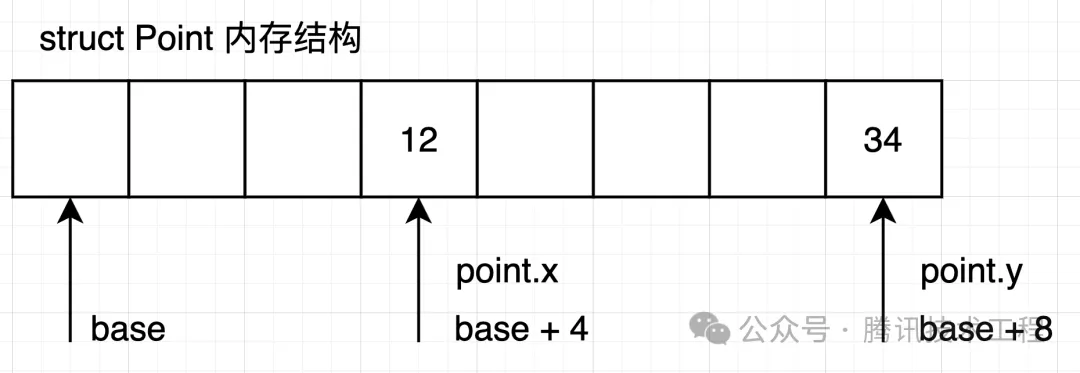
也因此 C 里面沒提供從字段 key 名的方式去取 struct value 的方法,也就是不支持 point['x'] 這樣,需要你自己寫 getter 才能實現類似操作。
這類根據 string value 來從對象取值的技術通常在現代編程語言里都是自帶了的,通常稱為反射,可以在運行時訪問源碼信息。
但在 JS 里,對象是動態的,可以有任意多的 key-values,而且這些 kv 鍵值對還可能在運行時期間動態發生變化,比如我可以隨時 p.xxx =123 又或者 delete p.xxx 去刪掉它,這意味著一個 object 的 “shapes” 及其「內存結構」是無法被靜態分析出來的,而且這種內存結構必然不是「定長固定」的,是需要動態 malloc 變長的。
假設現在是 2008 年,你是 google 的工程師,正在 chrome v8 項目組開發,你會怎樣設計 JS 的對象的內存結構?
const obj = { x: 3, y: 5 }
// obj 的內存結構可以設計成怎樣?一眼丁真,開搞:

一個 key 定義加一個值,然后將這個結構數組化就可以表達對象的 kv 結構,增加屬性就在后面繼續擴增,查找算法則是從頭查到尾,時間復雜度為 O(n)

但是如果按這個設計,下面兩個 obj 就會有重復的 key 定義內存消耗了:
const obj1 = { x: 11, y: 22 } // "x" 11 "y" 22
const obj1 = { x: 33, y: 44 } // "x" 33 "y" 44
// 會重復 "x" 和 "y"好了就上面這樣簡單弄一下就搞出了好多問題了。從下面開始正式進入,V8 是如何描述對象,參見下文。
2. JSObject 與 named-properties & indexed-elements
在 js 標準里 Array 是一類特殊的 Object,但出于性能考慮 V8 底層針對對象和數組的處理是不同的:
- 所謂 indexed-elements 指的是數組元素(以數字下標作為 key)存儲于 *elements,是一段線性內存空間,可以直接用下標直接訪問,查找速度非常快;
- 而其他的普通成員所謂 named-properties 則存儲于 *properties 查找速度比較慢,需要遍歷對比。
如下圖所示,JSObject:
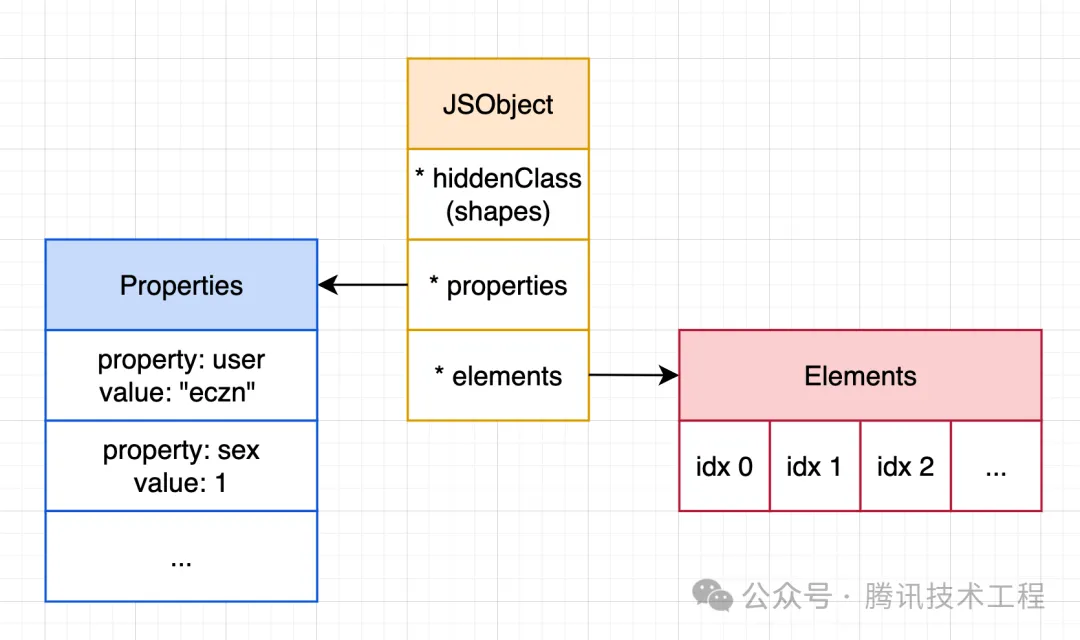
在 V8 里:
- Array-indexed 的屬性存儲在 *elements 里,查找速度快;Named Properties 則存儲在 *properties 里,查找速度慢;
- Properties/Elements 這兩個結構可以是數組,但有時候也會變成字典(比如稀疏數組場景,線性內存空間就不夠性能了);
- 每個 JSObject 都有一個 *hiddenClass,用于保存對象的 Shapes。
嗯?對象的 Shapes?那是什么?
3. 對象的 Shapes
所謂對象的 shapes,其實就是對象上有什么 key,前面提到過 V8 的優化需要在運行時不斷收集 feedback,比如當執行下面這段代碼的時候,引擎就可以知道「obj 有兩個 key,一個是 a 一個是 b」:
const obj = {}
obj.a = 123;
obj.b = 124;
doSomething(obj);V8 通過 Hidden Class 結構來記錄 JSObject 在運行時的時候有哪些 key,也就是記錄對象的 shapes,由于 JSObject 是動態的,后續也可以隨意設置 obj.xxx = 123,也就是對象的 shapes 會變,也因此對象持有的 Hidden Class 會隨著特定代碼的運行而變化
Hidden Class 是比較學術的說法,在 V8 源碼里的「工程命名」是 Map,在微軟 Edge Chakra (edge) 里叫做 Types,在 JavaScriptCore (WebKit Safari) 里叫做 Structure,在 SpiderMonkey (FireFox) 里叫做 Shapes .... 總之各個主流引擎都有實現追蹤「對象 shapes 變化」
后文可能會混淆上面幾個用語,它們都是指 Hidden Class,用來描述對象的 shapes。
4. Hidden Class DescriptorArrays 與 in-object properties
前面提到除了 *properties 和 *elements 可以用來存儲對象成員之外,JSObject 還提供了所謂 in-object properties 的方式來存儲對象成員,也就是將對象成員保存在「JSObject 結構體」上,并配合 Hidden Class 進行鍵值描述:

上圖里 Hidden Class 里底下有個叫做 DescriptorArrays 的子結構,這個結構會記錄對象成員 key 以及其對應存儲的 in-object 下標,也就是上面的紫框。
或許你會問:
- 為什么要這樣,這樣做能幫助提升性能么?別急,后文會扣回來。
- 什么時候用 in-object 什么時候用 *properties 存儲,兩者做的是同一件事,不會沖突嗎?別急,后文會提。
5. 變化中的 Hidden Class
如果 Hidden Class 是靜態的,那么這圖就足夠描述 Hidden Class 了:
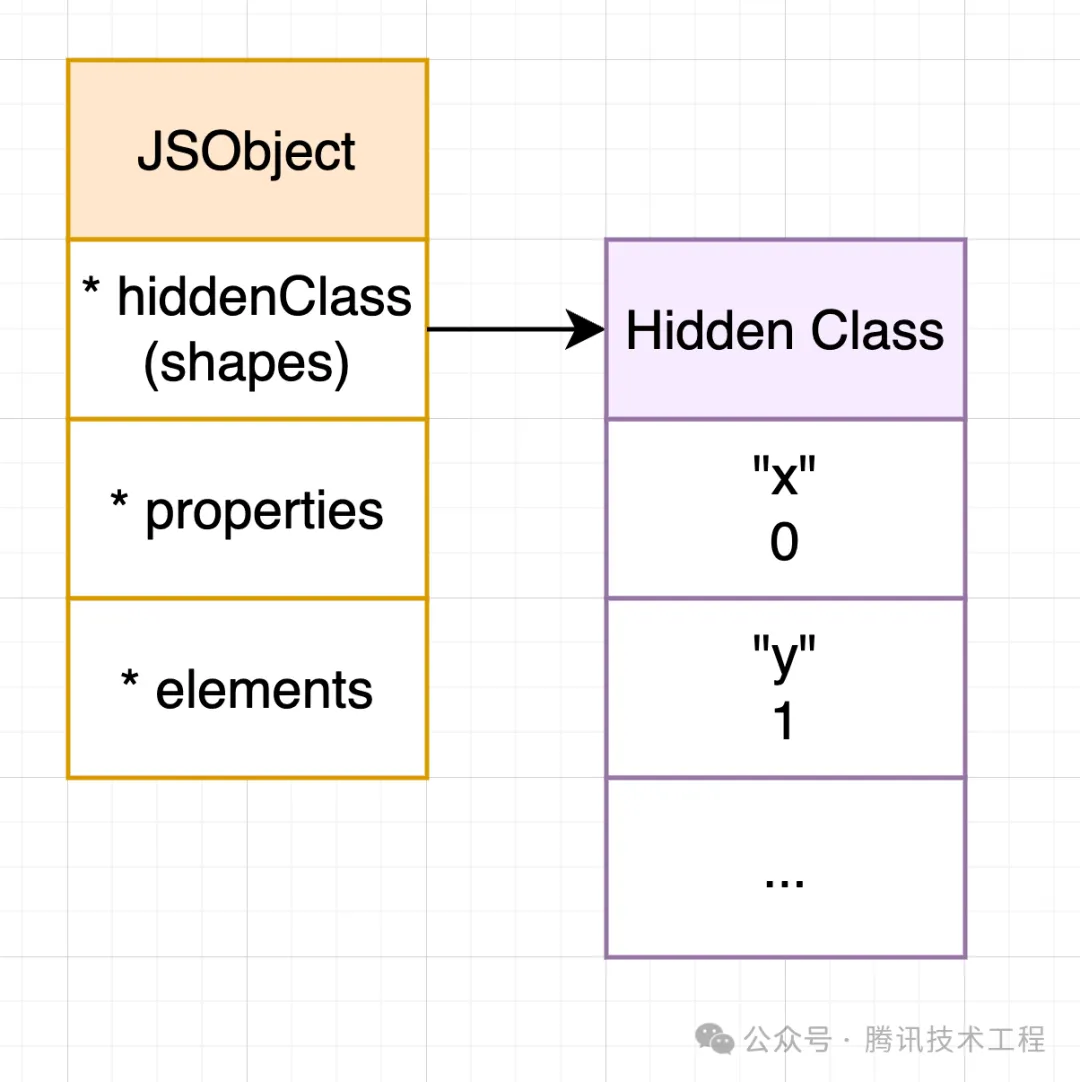
但是對象的 shapes 會變,也因此對象持有的 Hidden Class 會隨著特定代碼的運行而變化,V8 使用了 Transition Chain,一種基于鏈表構造的方式來描述「變化中的 Hidden Class」:

備注:為了方便討論,后文可能不會將 Hidden Class 畫成鏈表,而是畫成一起并且省略空對象的 shapes,另外 Hidden Class Node 上還有其他字段,相對不那么重要,就忽略了
由于鏈表的特性,顯然可以比較容易地讓具有相同 shapes 的對象能復用同一個 Hidden Class ,比如下面這個 case,o1 o2 均復用了地址為 0xABCD 的 Hidden Class 節點:
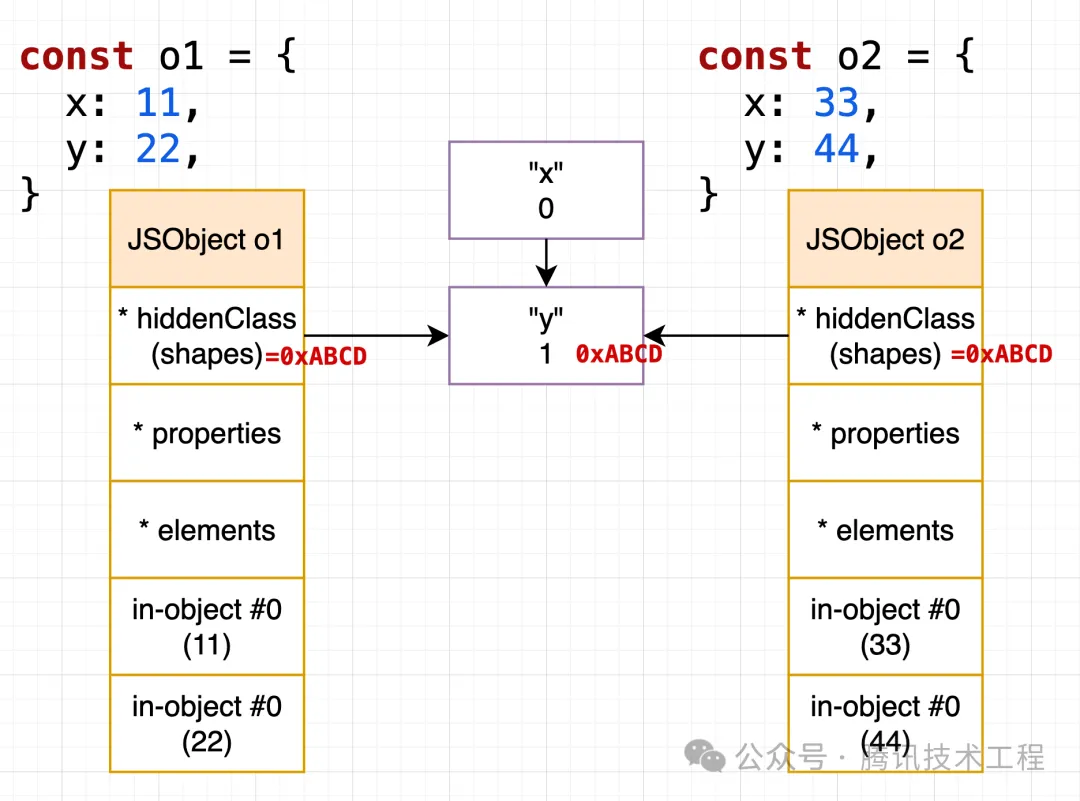
當出現不同走向的時候,此時會單獨開一個 branch 來描述這種情況,此時 o1 和 o2 就不再一樣了:

6. V8 對象模型總結
從前文的討論,可以得到的結論:
- V8 使用 JSObject 來描述對象,上面有若干個字段(除了上面那些還有 prototype 原型鏈那些,相對不那么重要,就沒畫出);
- V8 還使用 Tagged Pointer 來描述對象指針(前文有提);
- named properties 成員存儲在 *properties 里,可以為數組,也可以為字典
- named properties 也可以存儲在 in-object properties 里,可以動態增長;
- 數字下標成員存儲在 *elements 里,可以為數組,也可以為字典(稀疏數組場景)。
懸而未決的問題:
- 何時用 in-object properties 何時用 *properties ?
- 為什么看起來 Hidden Class 這套機制下屬性查找依然是 O(n) 的操作?追蹤對象的 shapes 意義在哪?
請帶著這兩個問題到下一章 Inline Caches 繼續閱讀。
七、?? Inline Caches (ICs) 優化原理
引入 Hidden Class 后,為了讀取某個成員,那不還得查一次 Hidden Class 拿到 in-object 的下標,這個過程不還是 O(n) 嗎?
是的,如果事先不知道 JSObject 的 shapes 的情況下去讀取成員確實是 O(n) 的,但前面我已經提過了:
V8 的諸多優化是基于 assumption 的,那么在已知 obj 的 Shapes 的情況下,你會怎么優化下面這個 distance 函數?

如此優化就可以將「通過遍歷 *properties訪問成員的O(n) 過程」直接優化為「直接按下標偏移直接讀取 `in-object` 的 O(1)過程」了,這種優化手段就叫做 Inline Caches (ICs),有點類似 C 語言的 struct 將字段點讀編譯為偏移訪問,只不過這個過程是 JIT 的,不是 C 那樣 AOT 靜態編譯確定的,是 V8 在函數執行多次收集了足夠多的 feedback 后實現的。
你可能還會問:在調用優化后的 distance2 的時候具體要怎么確定傳入的 p1 p2 的 shapes 是否有變化?還記得前面那個 0xABCD 嗎?沒錯,編譯后的匯編 checkpoint 就是直接判斷傳入對象的 hidden classs 指針數值是不是 *0xABCD*,如果不是就觸發「反優化」兜底解釋器模式運行即可。
—— 下面這個實例將手把手介紹 ICs 的真實場景以及匯編細節
1. 匯編實例:為什么靜態的比動態的要好 ?
從前面 Inline Cache 的討論中可以得知,必須要確定了訪問的 key 才能做 ICs 優化,因此寫代碼的過程中,如有可能請盡量避免下面這樣通過 key string 動態查找對象屬性:
function test(obj: any, key: string) {
return obj[key];
}如果能明確知道 key 的具體值,此時建議寫為:
function test(obj: any, key: 'a' | 'b') {
if (key === 'a') return obj.a;
if (key === 'b') return obj.b;
}即使確實不得不動態查詢,但是你知道某個子 case 占了 99% 的調用次數,此時也可以這樣優化:
function test(obj, key: 'a' | 'b') {
// 為 'a' 的調用次數占了 99% 可以這樣提前優化
if (key === 'a') return obj.a;
return obj[key];
}靜態和動態兩種寫法風格可能會有幾倍甚至上百倍的差距,如果業務里有大幾百萬次的調用 test,優化后能省不少毫秒,比如下面這個「簡化的服務發現」例子有近百倍的差距:

原因是 s2.js 里那些屬性訪問都被 ICs 技術優化成 O(1) 訪問了,速度很快 —— 為了探究內部的 ICs 相關匯編邏輯,嘗試輸出 serviecMap 的 Hidden Class (V8 里 hidden class 別名是 Map) 以及匯編源碼:

首先 %DebugPrint 出 serviceMap 的 Hidden Class 的物理地址,可以看到是 0x3a8d76b74971 然后看后續編譯優化的 arm machine code 是怎么利用這個地址實現 ICs 技術優化的:(筆者這會的電腦是 mac m1 因此是 arm 匯編,不是 x86 匯編)。

可以看到,ICs 優化后匯編的 checkpoint 其實就是將 Hidden Map 的指針物理地址直接 Inline 到匯編里了,通過判等的方式來驗證假設,然后就可以直接將屬性訪問優化為 O(1) 的 in-object properties 訪問了,這也是這個技術為什么叫做 Inline Cahce (ICs) 了。
(這幾乎是 V8 里效果最好的優化了,也因此部分 benchmark 里 nodejs 對象可能比 Java 對象還快,因為 Java 里有可能濫用反射導致對象性能非常差)。
2. Fast Properties 和 Slow Properties
如果知道 ICs 技術內涵的話,理解 Fast Properties 和 Slow Properties (或者稱字典模式) 就不會有困難了。
下圖描述了 JSObject 的主要構造:當把對象成員存儲到 in-object properties 的時候,此時稱對象是 Fast Properties 模式,這意味著對象訪問 V8 會在合適的時候將其 Inline Cache 到優化后的匯編里;反之,當成員存儲到 *properties 的時候,此時稱為 Slow Properties,此時就不會對這類對象做 inline cache 優化了,此時對象訪問性能最差(因為要遍歷 *properties 字典,通常慢幾十到幾百倍,取決于對象成員數量)。

我們可以用 %HasFastProperties 來打印對象是否是 Fast Properties 模式,如下圖所示:
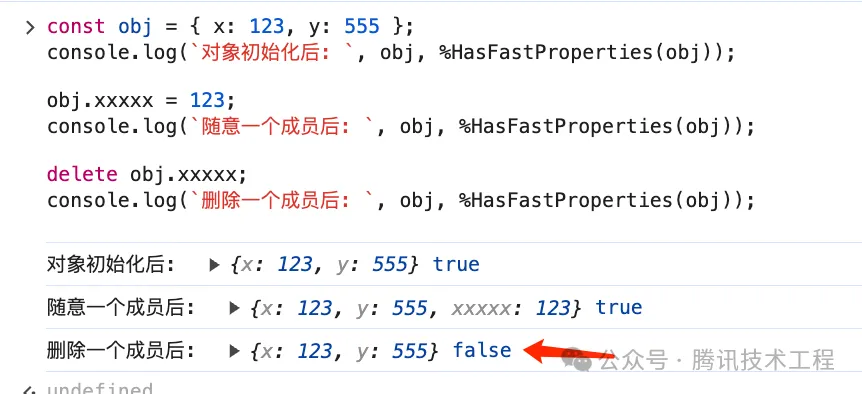
delete 會將對象轉為 slow properties 模式,為什么呢?因為 delete 帶來的問題可太多了,緩存技術最怕的就是 delete,如圖所示:
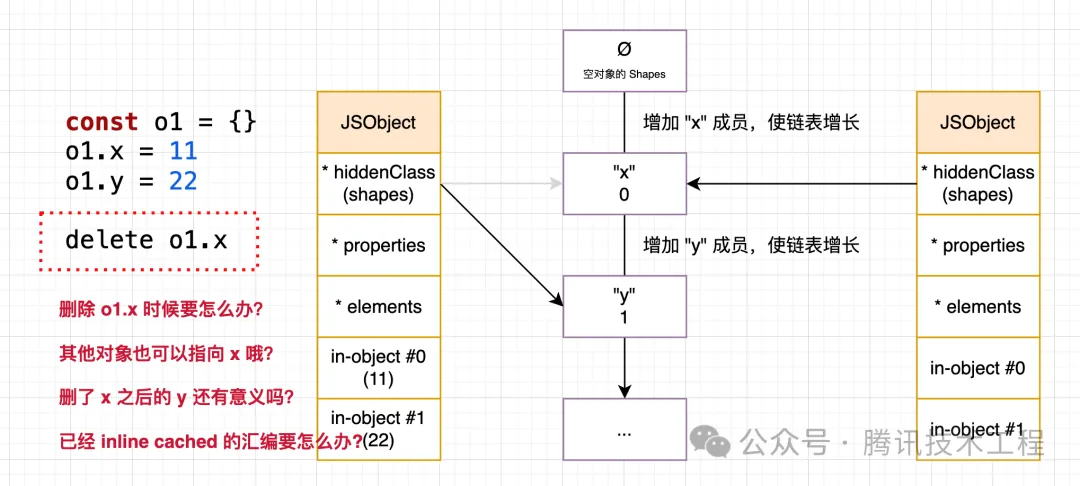
我拍腦子就能想到上面四個問題,要完整的確保 delete 的安全性可太難了,因此維護 delete 后的 hidden class 非常麻煩,V8 采取的方式是直接將 in-object 釋放掉,然后將對象屬性都復制存儲到 *properties 里了,以后這個對象就不再開啟 ICs 優化了,此時這種退化后的對象就稱為 slow properties (或者稱字典模式)。
3. 利用 Hidden Class 來查找內存溢出 (heapdump)
Hidden Class 是比較學術的名字,在 V8 里對應的「工程命名」是 Map,可以在 heapdump 里看到:
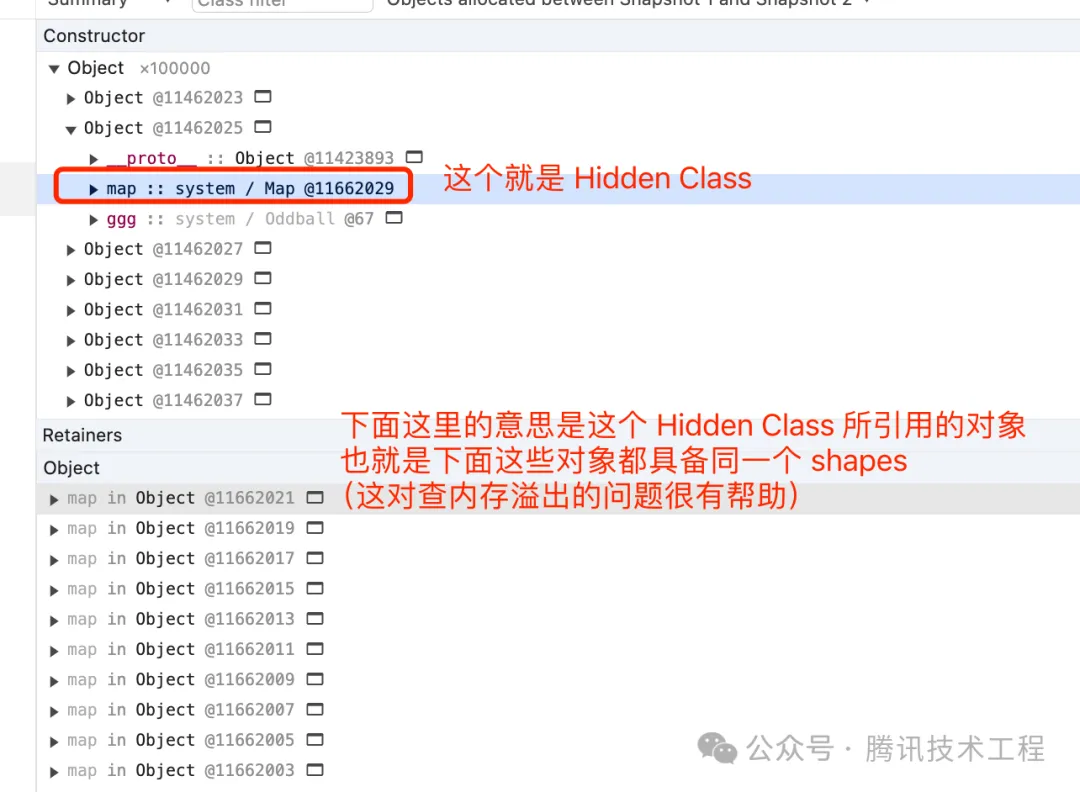
利用查找 Hidden Class 的方式可以快速定位大批量相同 shapes 的對象哦,很方便查找內存溢出問題。
八、V8 其他優化
1. inline 展開
跟 C++ 里的 inline 關鍵字一樣,將函數直接提前展開,少一次調用棧和函數作用域開銷。

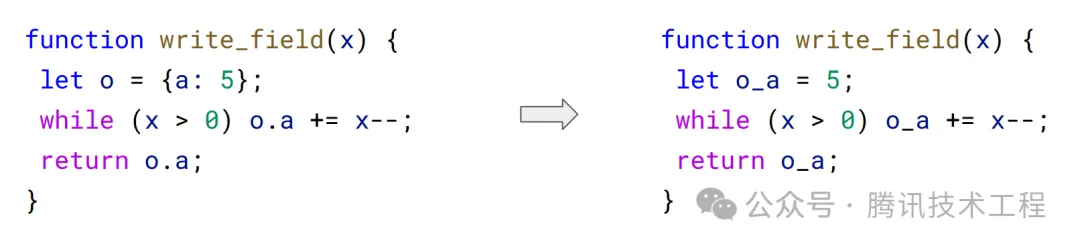
2. 逃逸分析
基于 Sea Of Nodes 的 PL 理論進行優化,分析對象生命周期,如果對象是一次性的,那么就可以做編譯替換提升性能,比如下圖里對象 o 只用到了 a,那么就可以優化成右邊那樣,減少對象內存分配并提升尋址速度:
3. 提前為空對象申請 in-object 內存空間
通過打 heapdump 的方式可以發現下面第二行的空對象的 shallow size 是 28 字節,而后一個是 16 字節:
window.arr = []; // 打一次 heapdump
arr.push({}); // 打一次 heapdump
arr.push({ ggg: undefined });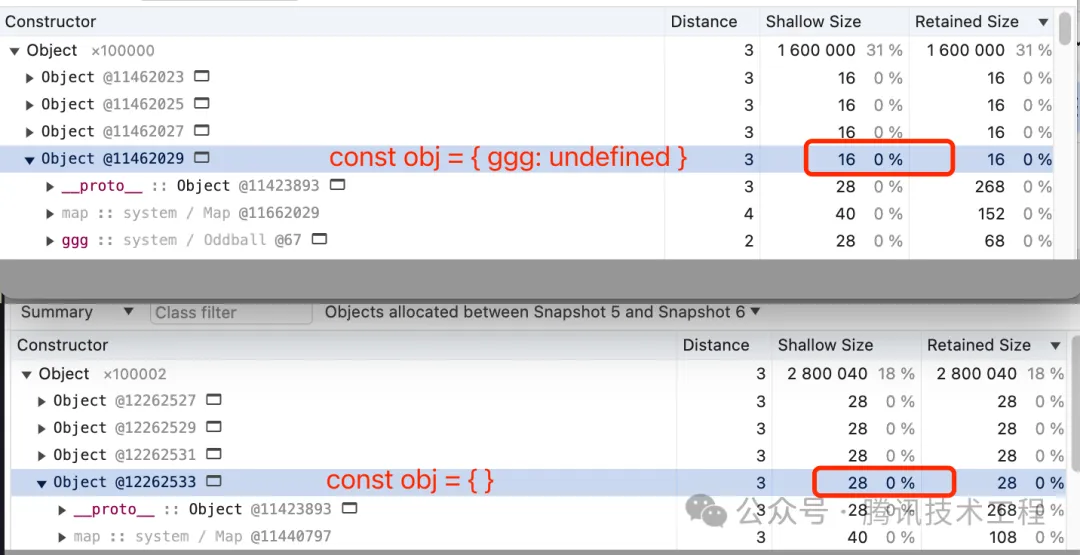
原因:V8 假設空對象后面都會設置新的 key 上去,因此會預先 malloc 了一些 in-object 字段到 JSObject 上,最后就是 28,比 16 要大;而第三行這樣固定就只會 malloc 一個 in-object 字段了(其實看圖里還有一個 proto 字段)。
那么 new Object() 呢?一樣會;如果是 Object.create(null) 呢?這種情況就不會申請了,shallow size 此時最小,為 12 字節。
28 - 12 = 16 字節,而一個指針占 4 字節,因此 V8 對一個空對象會默認為其多創建 4 個 in-object 字段以備后續使用,而這類預分配的內存空間,會在下次 GC 的時候將沒用到的回收掉,這項技術叫做 「Slack Tracking 松弛追蹤」。
4. 其他優化技術
v8 里還有很多針對 string / Array 的優化技術,本次技術優化主要涉及 ICs 相關優化,就不展開寫了,參見后文鏈接(其實大部分對象優化技術都是圍繞 V8 對象模型來進行的)。
九、Safari 也有 JIT 也有 ICs 技術
Safari 的 WebKit JSCore 引擎也有基于 LLVM 后端的 JIT 技術,因此很多優化手段是共通的,比如 safari 也有 type feedback 和屬性追蹤,也有自己的 hidden class / ICs 實現,可以打開 safari 的調試工具看到運行時的 type feedback:(macOS、iOS、iPadOS 上都有 JIT,在 chrome 上優化后全平臺都能受益)。

在這些優化技術的加持上,safari jscore 某些情況下甚至會比 chrome v8 還要快:
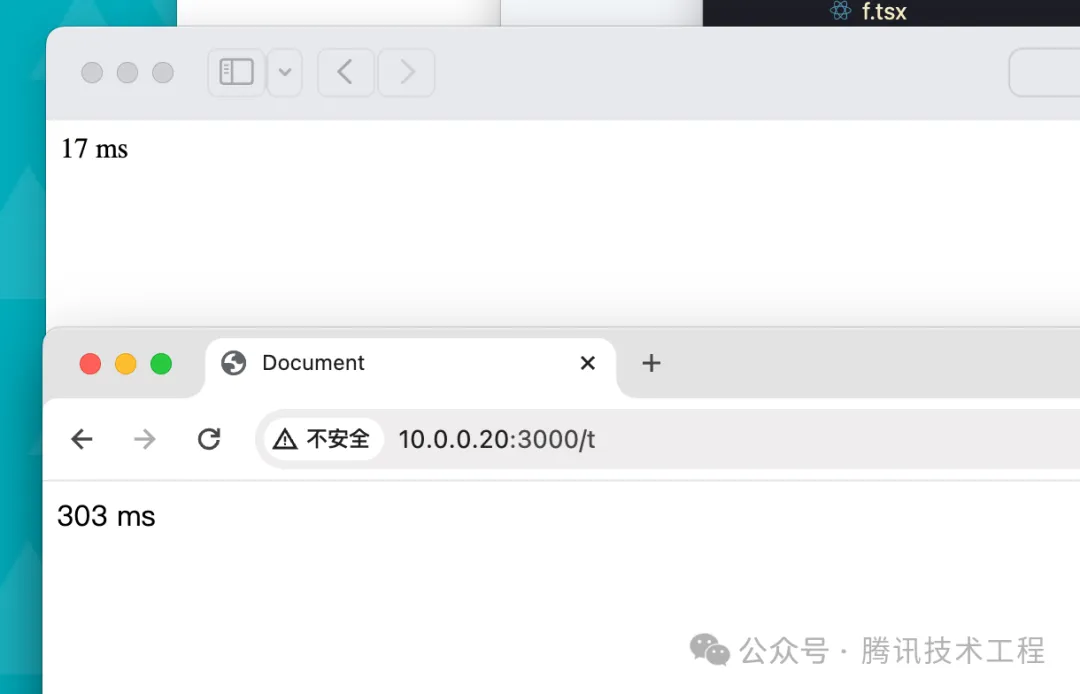
十、高性能 JS 編寫建議
大部分業務場景里更關心可維護性,性能不是最重要的,另外就是面向引擎/底層優化邏輯寫的 js 未必是符合最佳實踐的,有時候會顯得非常臟,這里總結一下個人遇到的常見實例對照,供參考:
1. 熱點函數(Hot Function)
熱點函數會優先走 turbofan 編譯為機器碼,性能會更好,要如何利用好這個特性?將項目里的一些高頻原子操作拆成獨立函數,人為制造熱點代碼,比如計算點距離,單位換算等等這些需要高性能的地方:
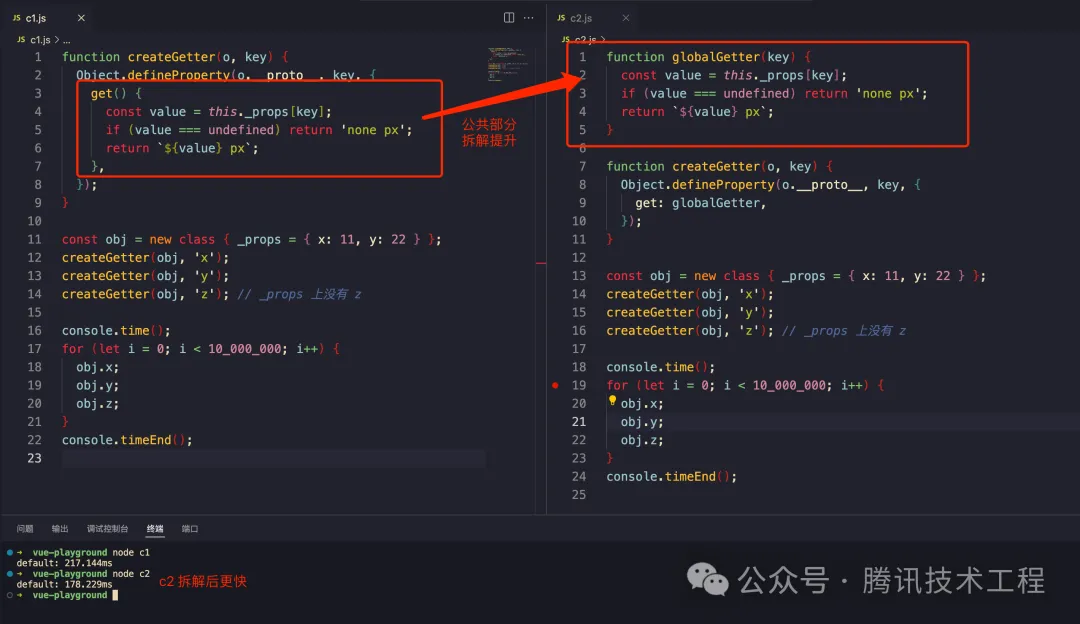
2. 函數拆解
除了前面提到的熱區之外,拆解后的函數如果足夠短,那么 V8 在調用的時候會做 inline 展開優化,節省一次調用棧開銷。

3. 減少函數狀態(Mono)
從前面的 add 的例子我們可以知道,V8 TurboFan 優化是基于 assumption 的,應該盡量保持函數的單態性 (Monomorphic),或者說減少函數的狀態,具體來說高頻函數不要傳 Union Types 作為參數。(這個不夠準確,最好是不要打破參數的 V8 內部類型表示以及匯編 checkpoint,比如一會傳浮點數、一會傳 SMI 這樣即使都是 number 也會打破 v8 的假設,因為 v8 內部實現的浮點數會裝箱,而小整數 SMI 不會,兩者的匯編邏輯不一樣)。
推薦使用 TypeScript 來寫 js 應用,限制函數的入參類型可以有效保證函數的單態性質,更容易編寫高性能的 js 代碼
4. 保持對象賦值順序不變(Hidden Class)
賦值順序的不同會產生不同的 Hidden Class 鏈,不同的鏈不能做 ICs 優化。
5. class 里的字段聲明最好加上一個默認值
class A {
a?: number
}
class A {
a = undefined // 或 null
}理由跟前一點一樣,前者 A 有 shapes 鏈是 空對象+a,而后者就是確定的 a 了。
但是,賦值會多消耗一點內存,內存敏感型場景慎用。
6. 避免使用 delete
delete 后會將對象轉為 Slow Properties 模式,這種模式下的對象不會被 inline cache 到優化后的匯編機器碼里,對性能影響比較大,另外這樣的對象如果到處傳的話就會到處觸發「反優化」將污染已經優化過的代碼。
7. 避免反優化
前面的例子里提到,反優化后的函數再優化性能不會比最開始要好,換言之被「feedback 污染」了,我們應當盡量避免反優化的出現(即 checkpoint 被打破的情況)。
8. 靜態的比動態的好
前面已經討論過這類情況了,靜態種寫法 V8 可以做 ICs 優化,將屬性訪問直接改為 in-object 訪問,速度可以比動態 key 查找快近百倍。
9. 字面量聲明比過程式聲明更好
const obj = { a: 1, b: 2 };
const obj = {};
obj.a = 1;
obj.b = 2;從 Hidden Class 的角度來看,第二種會使 Hidden Class 變化三次,而第一種直接聲明其實就隱含了 Hidden Class 了,V8 可以直接提前靜態分析得出。
10. 盡量保證對象就只作用在一個函數內(逃逸分析)

v8 會分析 ast,將左側優化成右側。
11. Ref<T> 性能問題
在 React / Vue 里有這種 Ref 構造來實現訪問同一個實例的操作(類似指針)
type Ref<T> = {
ref: T
}
// React 的是 current 作為 key
type ReactRef<T> = { current: T }前面提到過的 ICs 優化,因此上述這樣的構造并不會造成嚴重的性能損失,會多消耗一點內存,大多數情況下可以放心使用(多消耗 16 字節)。