













如何在自定義數據集上訓練 YOLOv8 實例分割模型
在本文中,我們將介紹微調 YOLOv8-seg 預訓練模型的過程,以提高其在特定目標類別上的準確性。Ikomia API簡化了計算機視覺工作流的開發過程,允許輕松嘗試不同的參數以達到最佳結果。

使用 Ikomia API 入門
通過 Ikomia API,我們只需幾行代碼就可以訓練自定義的 YOLOv8 實例分割模型。要開始,請在虛擬環境中安裝 API。
pip install ikomia在本教程中,我們將使用 Roboflow 的珊瑚數據集。您可以通過以下鏈接下載此數據集:https://universe.roboflow.com/ds/Ap7v6sRXMc?key=ecveMLIdNa
使用幾行代碼運行訓練 YOLOv8 實例分割算法
您還可以直接加載我們準備好的開源筆記本。
from ikomia.dataprocess.workflow import Workflow
# Initialize the workflow
wf = Workflow()
# Add the dataset loader to load your custom data and annotations
dataset = wf.add_task(name='dataset_coco')
# Set the parameters of the dataset loader
dataset.set_parameters({
'json_file': 'Path/To/Mesophotic Coral/Dataset/train/_annotations.coco.json',
'image_folder': 'Path/To/Mesophotic Coral/Dataset/train',
'task': 'instance_segmentation',
})
# Add the YOLOv8 segmentation algorithm
train = wf.add_task(name='train_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
train.set_parameters({
'model_name': 'yolov8m-seg',
'batch_size': '4',
'epochs': '50',
'input_size': '640',
'dataset_split_ratio': '0.8',
'output_folder':'Path/To/Folder/Where/Model-weights/Will/Be/Saved'
})使用 NVIDIA GeForce RTX 3060 Laptop GPU(6143.5MB),50個時期的訓練過程大約需要1小時。
什么是 YOLOv8 實例分割?
在進行具有所有參數詳細信息的逐步方法之前,讓我們更深入地了解實例分割和 YOLOv8。
1.什么是實例分割?
實例分割是計算機視覺任務,涉及在圖像中識別和描繪單個對象。與語義分割不同,后者將每個像素分類為預定義的類別,實例分割旨在區分和分離對象的各個實例。
在實例分割中,目標不僅是對每個像素進行分類,還要為每個不同的對象實例分配一個唯一的標簽或標識符。這意味著將同一類別的對象視為單獨的實體。例如,如果圖像中有多個汽車實例,實例分割算法將為每輛汽車分配一個唯一的標簽,以實現精確的識別和區分。

實例檢測、語義分割和實例分割之間的比較
與其他分割技術相比,實例分割提供了有關對象邊界和空間范圍的更詳細和精細的信息。它廣泛用于各種應用,包括自動駕駛、機器人技術、目標檢測、醫學圖像和視頻分析。
許多現代實例分割算法,如 YOLOv8-seg,采用深度學習技術,特別是卷積神經網絡(CNN),以同時執行像素級分類和對象定位。這些算法通常結合了目標檢測和語義分割的優勢,以實現準確的實例級分割結果。
2.YOLOv8概述
(1) 發布和優勢
由Ultralytics開發的YOLOv8是一種專門用于目標檢測、圖像分類和實例分割任務的模型。它以其準確性和緊湊的模型大小而聞名,成為YOLO系列的顯著補充,該系列在YOLOv5方面取得了成功。憑借其改進的架構和用戶友好的增強功能,YOLOv8為計算機視覺項目提供了一個出色的選擇。

與其他實時目標檢測器的比較:YOLOv8實現了最先進(SOTA)的性能
(2) 架構和創新
雖然YOLOv8的官方研究論文目前不可用,但對存儲庫和可用信息的分析提供了有關其架構的見解。YOLOv8引入了無錨檢測,該方法預測對象中心而不依賴錨框。這種方法簡化了模型并改善了后處理步驟,如非最大抑制。
該架構還包含新的卷積和模塊配置,傾向于ResNet樣式的結構。有關網絡架構的詳細可視化,請參閱GitHub用戶RangeKing創建的圖像。
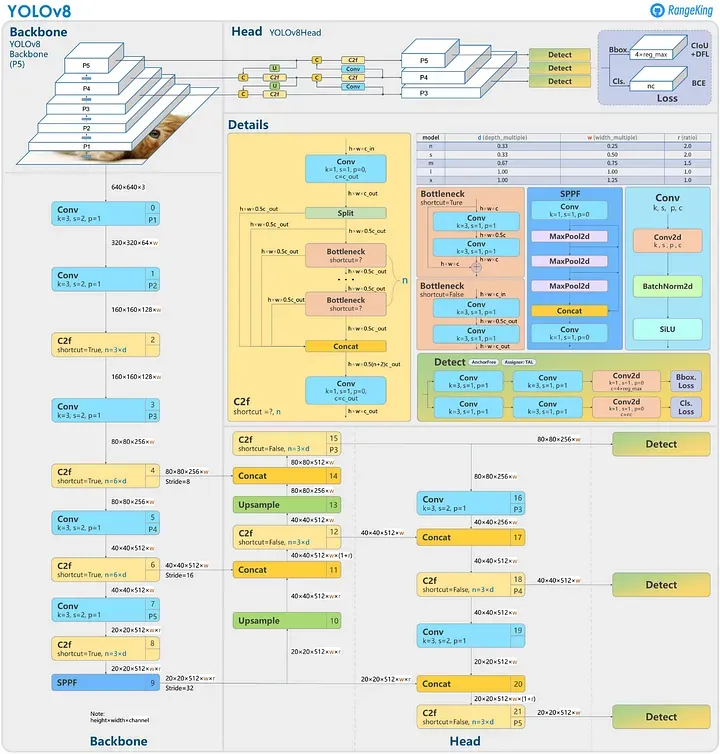
YOLOv8模型結構(非官方)
(3) 訓練例程和數據增強
YOLOv8的訓練例程包括馬賽克增強,其中多個圖像被組合在一起,使模型暴露于對象位置、遮擋和周圍像素的變化。但是,在最終訓練時關閉此增強以防止性能降低。
(4) 準確性和性能
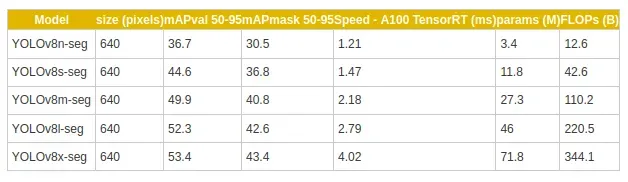
YOLOv8的準確性改進已在廣泛使用的COCO基準測試上得到驗證,在該基準測試中,該模型實現了令人印象深刻的平均精度(mAP)分數。例如,YOLOv8m-seg模型在COCO上實現了令人矚目的49.9% mAP。以下表格提供了YOLOv8-seg不同變體的模型大小、mAP分數和其他性能指標的摘要:
以下是使用YOLOv8x檢測和實例分割模型的輸出示例:

YOLOv8x檢測和實例分割模型
逐步操作:使用Ikomia API微調預訓練的YOLOv8-seg模型
使用您下載的航拍圖像數據集,您可以使用Ikomia API訓練自定義的YOLO v7模型。
第1步:導入并創建工作流
from ikomia.dataprocess.workflow import Workflow
wf = Workflow()Workflow是創建工作流的基本對象。它提供了設置輸入(如圖像、視頻和目錄)、配置任務參數、獲取時間度量和訪問特定任務輸出(如圖形、分割掩碼和文本)的方法。我們初始化一個工作流實例。然后,“wf”對象可用于向工作流實例添加任務,配置它們的參數,并在輸入數據上運行它們。
第2步:添加數據集加載器
下載的COCO數據集包括兩種主要格式:.JSON和圖像文件。圖像被分成train、val、test文件夾,每個文件夾都有一個包含圖像注釋的.json文件:
- 圖像文件名
- 圖像大小(寬度和高度)
- 具有以下信息的對象列表:對象類別(例如“person”、“car”);邊界框坐標(x、y、寬度、高度)和分割掩碼(多邊形)
我們將使用Ikomia API提供的dataset_coco模塊加載自定義數據和注釋。
# Add the dataset loader to load your custom data and annotations
dataset = wf.add_task(name='dataset_coco')
# Set the parameters of the dataset loader
dataset.set_parameters({
'json_file': 'Path/To/Mesophotic Coral/Dataset/train/_annotations.coco.json',
'image_folder': 'Path/To/Mesophotic Coral/Dataset/train,
'task': 'instance_segmentation'
})第3步:添加YOLOv8分割模型并設置參數
我們向工作流添加'train_yolo_v8_seg'任務,用于訓練自定義的YOLOv8-seg模型。為了自定義我們的訓練,我們指定以下參數:
# Add the YOLOv8 segmentation algorithm
train = wf.add_task(name='train_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
train.set_parameters({
'model_name': 'yolov8m-seg',
'batch_size': '4',
'epochs': '50',
'input_size': '640',
'dataset_split_ratio': '0.8',
'output_folder':'Path/To/Folder/Where/Model-weights/Will/Be/Saved'
})這是可配置的參數及其相應的描述:
- batch_size:在更新模型之前處理的樣本數。
- epochs:在訓練數據集上的完整通過次數。
- input_size:訓練和驗證期間的輸入圖像大小。
- dataset_split_ratio:算法自動將數據集分為訓練和評估集。值為0.8表示使用80%的數據進行訓練,20%進行評估。
您還可以修改以下參數:
- workers:數據加載的工作線程數。當前設置為'0'。
- optimizer:要使用的優化器。可用的選擇包括SGD、Adam、Adamax、AdamW、NAdam、RAdam、RMSProp和auto。
- weight_decay:優化器的權重衰減。當前設置為'5e-4'。
- momentum:SGD動量/Adam beta1值。當前設置為'0.937'。
- lr0:初始學習率。對于SGD,設置為1E-2,對于Adam,設置為1E-3。
- lrf:最終學習率,計算為lr0 * lrf。當前設置為'0.01'。
第4步:運行您的工作流
最后,我們運行工作流以開始訓練過程。
wf.run()您可以使用Tensorboard或MLflow等工具監視培訓的進度。一旦訓練完成,train_yolo_v8_seg任務將在output_folder中的時間戳文件夾內保存最佳模型。您可以在時間戳文件夾的weights文件夾中找到您的best.pt模型。
測試微調的YOLOv8-seg模型
首先,我們可以在預訓練的YOLOv8-seg模型上運行珊瑚圖像:
from ikomia.dataprocess.workflow import Workflow
from ikomia.utils.displayIO import display
# Initialize the workflow
wf = Workflow()
# Add the YOLOv8 segmentation alrogithm
yolov8seg = wf.add_task(name='infer_yolo_v8_seg', auto_connect=True)
# Set the parameters of the YOLOv8 segmentation algorithm
yolov8seg.set_parameters({
'model_name': 'yolov8m-seg',
'conf_thres': '0.2',
'iou_thres': '0.7'
})
# Run on your image
wf.run_on(path="Path/To/Mesophotic Coral Identification.v1i.coco-segmentation/valid/TCRMP20221021_clip_LBP_T109_jpg.rf.a4cf5c963d5eb62b6dab06b8d4b540f2.jpg")
# Inspect your results
display(yolov8seg.get_image_with_mask_and_graphics())
瑚檢測使用YOLOv8-seg預訓練模型
我們可以觀察到,infer_yolo_v8_seg默認的預訓練模型將珊瑚錯誤地識別為熊。這是因為該模型是在COCO數據集上進行訓練的,該數據集不包含任何珊瑚對象。
要測試我們剛剛訓練的模型,我們使用'model_weight_file'參數指定路徑到我們的自定義模型。然后在先前使用的相同圖像上運行工作流。
# Set the path of you custom YOLOv8-seg model to the parameter
yolov8seg.set_parameters({
'model_weight_file': 'Path/To/Output_folder/[timestamp]/train/weights/best.pt',
'conf_thres': '0.5',
'iou_thres': '0.7'
})
珊瑚檢測使用自定義模型
將我們的結果與地面實況進行比較,我們成功地識別了Orbicella spp.的物種。然而,我們觀察到一些假陰性的情況。為了提高我們自定義模型的性能,進一步訓練更多的時期并使用更多圖像進行數據增強可能會有益處。另一個展示有效檢測結果的示例是用Agaricia agaricites物種演示的:
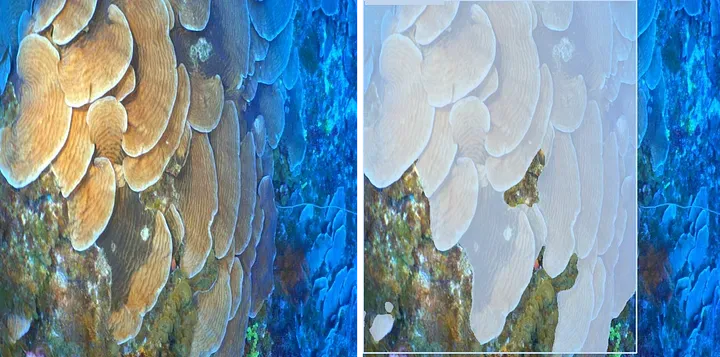
YOLOv8檢測珊瑚物種:Agaricia agaricites























