













新目標檢測模型YOLOv9實踐 :訓練自定義數據
新YOLOv9模型的更新
YOLO系列模型有了一個新成員,在2024年2月發布了一篇新論文,標題為“YOLOv9: 使用可編程梯度信息學習您想要學習的內容”,詳細論文可以在這個鏈接中查看:https://arxiv.org/pdf/2402.13616.pdf。以下是一個快速概述:
- 解決方案的核心是引入了可編程梯度信息(PGI)和一種新的輕量級網絡架構,稱為廣義高效層聚合網絡(GELAN)。
- 可編程梯度信息(PGI):論文將PGI引入為一種方法,以減輕數據通過深度神經網絡層時的信息丟失。PGI確保完整的輸入信息可用于目標任務以計算目標函數,從而可以獲得可靠的梯度信息,用于更新網絡權重。
- 廣義高效層聚合網絡(GELAN):GELAN基于梯度路徑規劃設計,旨在優化參數利用。這種架構在輕量級模型中展示出優異的結果,特別是與PGI結合時,在MS COCO數據集上的對象檢測任務中表現比現有的最先進方法更好。
- 優越的性能:在基于MS COCO數據集的對象檢測上,GELAN和PGI的組合表現出優于其他方法的性能,特別是在參數利用和準確性方面,甚至超過了在大型數據集上預訓練的模型。

MS COCO對象檢測數據集的性能
與新YOLOv9進行實際交互
在本節中,我將向您展示如何使用Roboflow在您的自定義數據集上使用新模型,以下是詳細步驟:
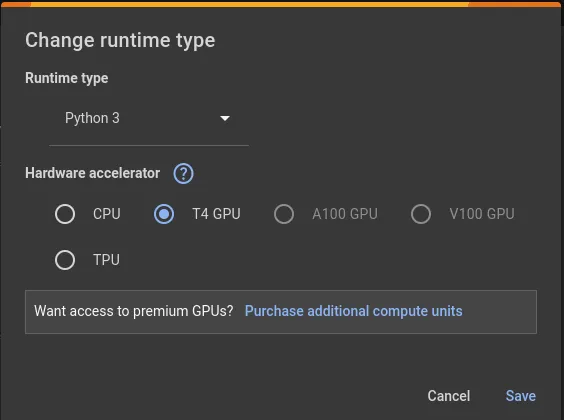
1.確保您的運行時類型設置為GPU:
您可以通過選擇Runtime > Change runtime type來檢查,確保選擇了GPU選項。
現在運行以下部分以確認我們正在使用正確的機器類型,并使得在我們的數據集中更容易進行使用。
!nvidia-smi
import os
HOME = os.getcwd()
print(HOME)2.設置和安裝
現在是時候克隆YOLOv9存儲庫,并安裝roboflow庫,以便我們可以直接在筆記本中輕松下載我們的數據集,并下載模型權重。
!git clone https://github.com/SkalskiP/yolov9.git%cd yolov9
!pip install -r requirements.txt -q
!pip install -q roboflow
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt
!ls -la {HOME}/weights3.創建您的Roboflow數據集
下一步是創建您想要使用的自定義數據集。
順便一提,不必使用roboflow,只要您的訓練和測試數據的文件結構符合YOLOv9文件結構標準,您也可以在自己的計算機上手動完成。我鼓勵熱心的讀者這樣做,但是對于本文,我們將繼續使用Roboflow,因為它提供了更便捷的交互。
轉到Roboflow項目頁面,然后選擇創建新項目:

然后您將被重定向到創建頁面,請確保填寫所有被請求的詳細信息,以下是一個示例:
從這一點上開始,您將被要求上傳您的數據集數據,因此請確保將所有相關的圖像添加在那里,然后點擊上傳。
接下來,您需要對圖像進行標注。這非常直觀:
使用提示框圍繞正確的對象創建方框。
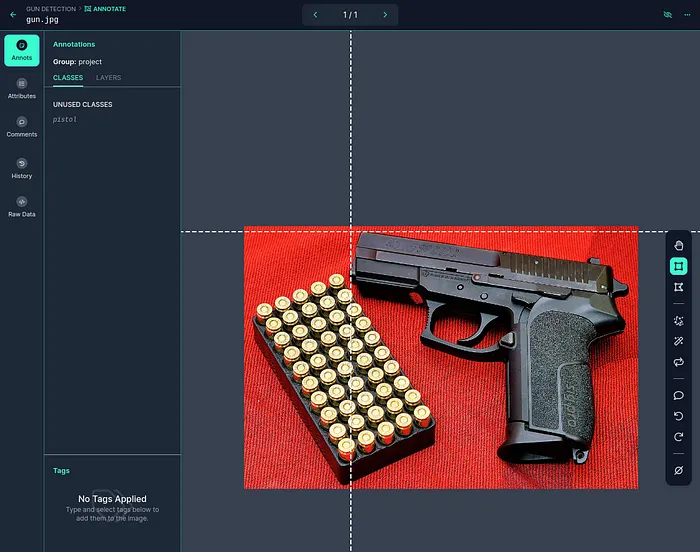
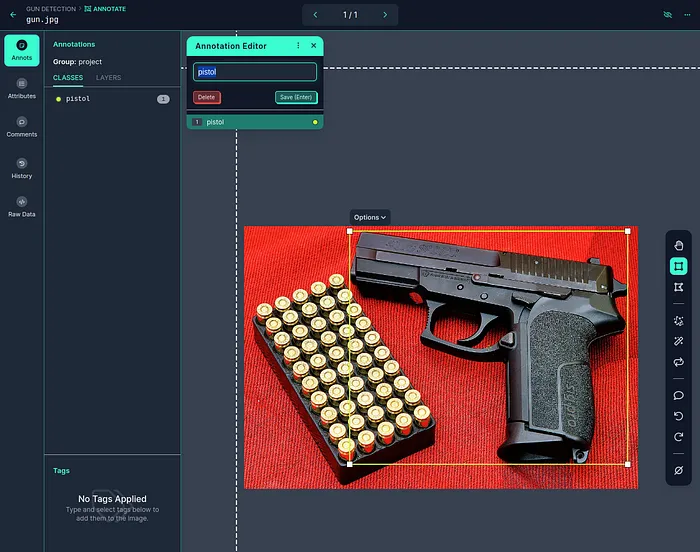
然后將所選框分配給相應的類別。
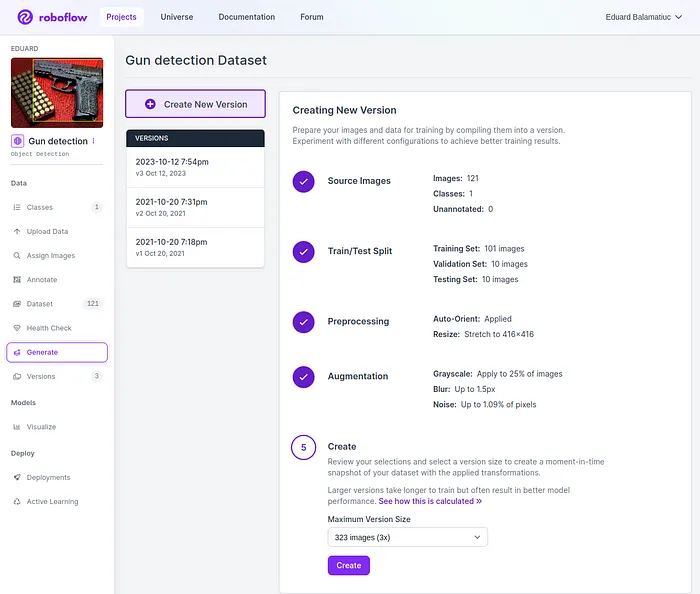
下一步是生成階段,您需要創建一個版本,在此階段確保配置所有您認為與您的特定情況相關的預處理和增強步驟,然后繼續。完成選擇選項后,點擊創建。
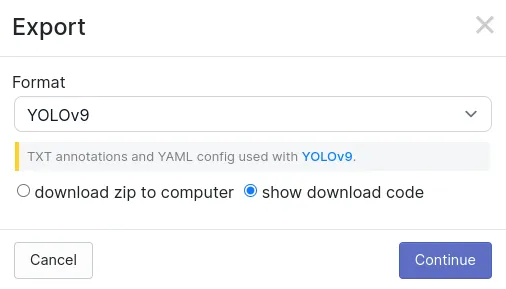
現在,在右上角選擇導出數據集選項,檢查顯示下載代碼選項和YOLOv9格式,然后點擊繼續。
您將獲得一個下載代碼,請復制它,并將其粘貼到筆記本的以下部分:
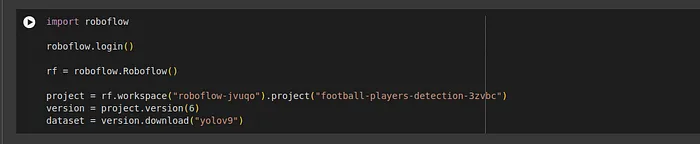
開始訓練
最后,現在我們需要訓練我們的自定義模型,請根據您的項目需求設置參數,并相應地更改批量大小、時期數和圖像分辨率大小:
%cd {HOME}/yolov9
!python train.py \
--batch 16 --epochs 25 --img 640 --device 0 --min-items 0 --close-mosaic 15 \
--data {dataset.location}/data.yaml \
--weights {HOME}/weights/gelan-c.pt \
--cfg models/detect/gelan-c.yaml \
--hyp hyp.scratch-high.yaml訓練過程可能需要一些時間,具體取決于您的數據集大小和所選擇的參數配置。
要查看我們的模型在訓練過程中的表現,以下是繪制出漂亮指標圖的代碼片段。我將展示我的結果和指標,但不要期望它們很好,因為我的數據集相當小且貧乏,目標只是展示訓練新模型的可能性。
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/train/exp/results.png", width=1000)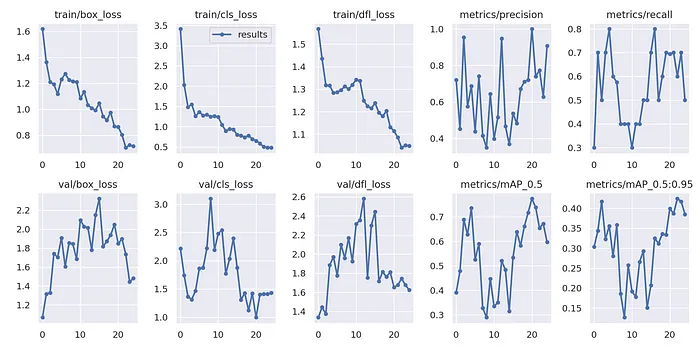
訓練結果
還有沒有混淆矩陣?
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/train/exp/confusion_matrix.png", width=1000)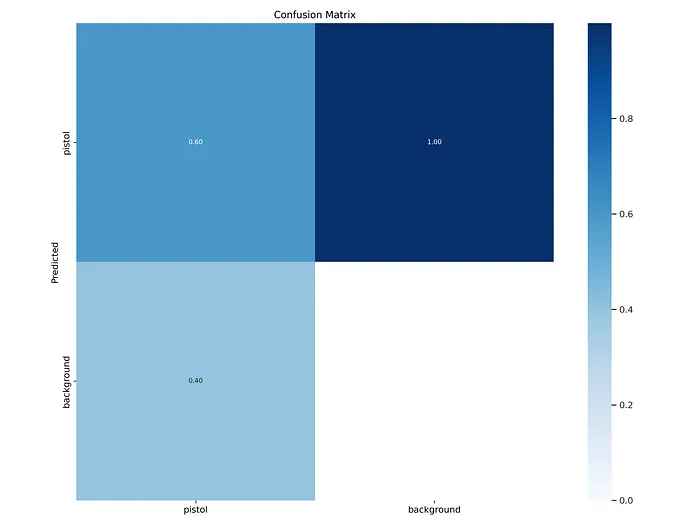
訓練后的淆矩陣
如果要檢查模型的預測,可以這樣做:
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/train/exp/val_batch0_pred.jpg", width=1000)


























