秒殺系統架構解析:應對高并發的藝術
作者 | 蔡佳新
秒殺活動是大家耳熟能詳的購物方式,它伴隨著一個極端的場景:極度的商品供不應求。這里面既有需求真實且迫切的用戶,也有試圖從中牟利的黃牛。反應到系統應對的挑戰上,就是相較于以往千倍萬倍的用戶規模,可能是真人可能是機器人,在同一瞬間對系統發起沖擊,需要海量的計算資源才能支撐。

對于各大電商平臺而言,爆款運營和促銷活動的日常化已成為常態,而支撐這些的秒殺系統自然是不可或缺的一環。同時,秒殺活動的巨大流量就像一頭洪荒之獸,若控制不當,可能會沖擊整個交易體系。因此,秒殺系統在交易體系中便扮演著至關重要的角色。
從個人角度來看,秒殺系統的設計套路往往適用于其他高并發場景,具有較高的借鑒價值。同時,其特殊的挑戰和需求,需要架構師在設計中權衡考量,這也有助于培養個人在權衡取舍方面的能力。
無損的技術方案
應對高并發就好比應對水患:
- 通過分流讓支流分攤壓力,隔離風險。對應到軟件設計就是系統隔離,分割流量;
- 通過建造水庫存儲洪水,再緩慢排出,削峰填谷。對應到軟件設計就是無損消峰;
- 通過拓寬河道,清除淤沙提高水流流速。對應到軟件設計就是常說的性能優化,比如通用的多級緩存,特定場景的高性能庫存扣減。
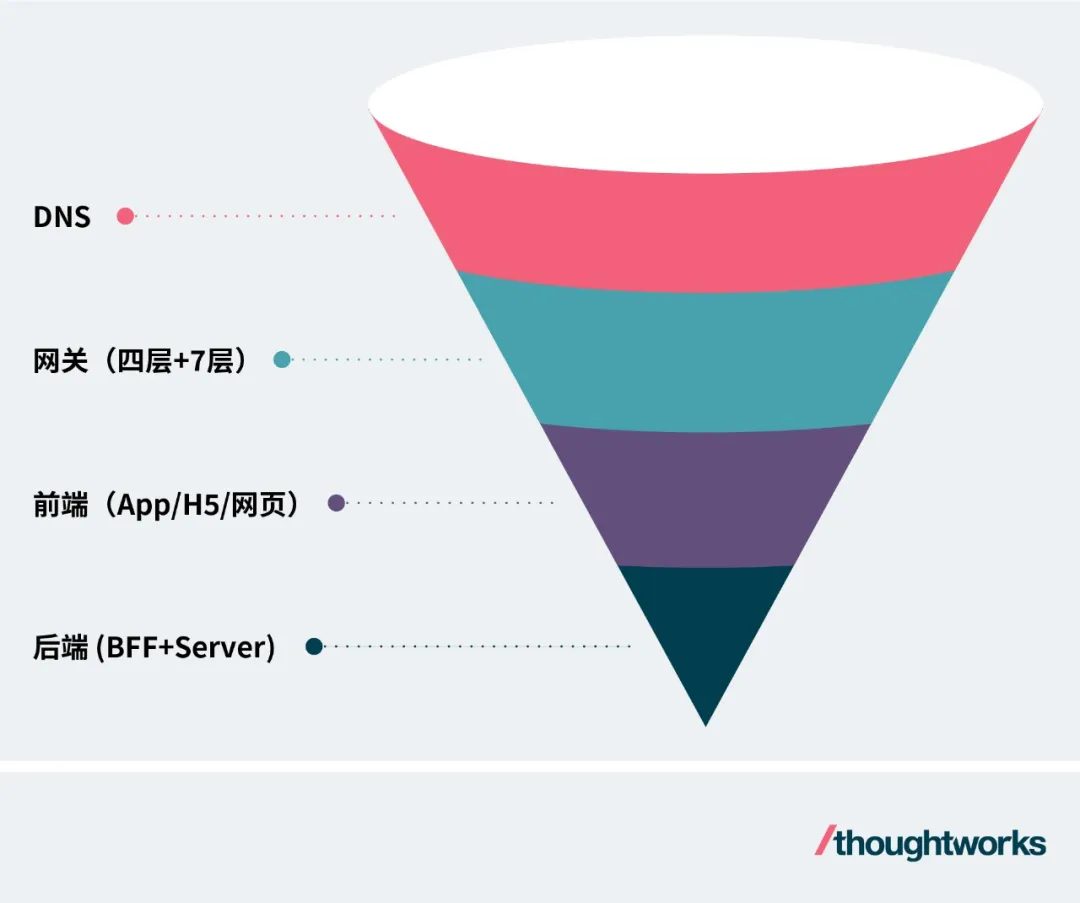
因為后續方案會圍繞請求經過的多個層級展開,所以在介紹方案之前,我們需要先了解一個基本情況:一個請求打到服務器的基本鏈路為:DNS->網關->前端/后端,其中流量峰值也應該逐層減少。如圖:
1.系統隔離
分布式系統由一個個發布單元共同組成。獨立的發布單元可以按需做容量伸縮,也可以在發生故障時及時做故障隔離,以保證不會出現個別服務故障導致整個系統不可用的情況。
秒殺活動因為其高峰值的特性,所以一般我們會把它隔離出來,成一個獨立的秒殺系統(常規服務都是按領域特性做縱切,但這里我們按品類做橫切,帶有秒殺活動標的商品將會分流到獨立的秒殺系統集群)。
考慮到交易系統體量是很大的,如果為秒殺品類把整個交易系統都復制一份,那成本就太大了。所以我們把隔離區分為物理隔離和邏輯隔離:
- 把需要定制化邏輯的能力和有特殊非功能性要求的能力剝離出來做物理隔離
- 標準化且沒有特殊非功能要求的能力就采用邏輯隔離。
畫成部署架構如下:
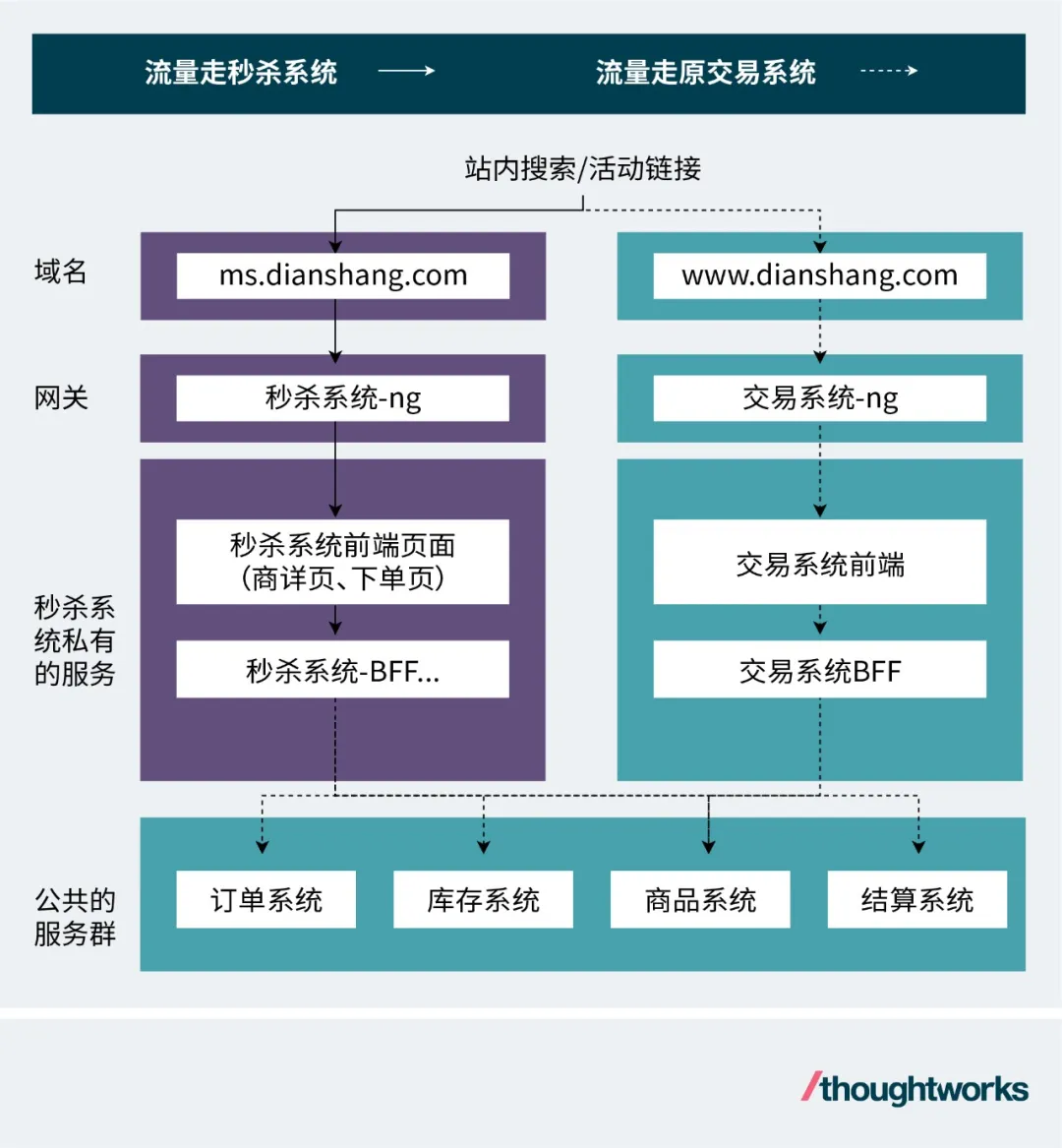
首先,我們采用獨立的秒殺域名和nginx集群(物理隔離)。這樣:
- 可以隔離流量大頭,防止峰值沖擊交易系統(非功能性需求);
- 能夠靈活擴展,針對不同時段的流量預估擴展nginx及后邊服務的規模(非功能性需求);
- 能夠靈活增減私有的防控邏輯,而不影響原交易系統(定制化邏輯)。
接著,我們將商詳頁和下單頁獨立部署(前端+BFF,物理隔離)。基于秒殺活動的玩法特征,海量用戶在活動快開始時會反復刷新商詳頁,在活動開始時又會瞬時并發到訪問下單頁,所以這兩個頁面都是承受流量沖擊的大頭,需要隔離開(非功能性需求)。同時因為秒殺活動的特性,商品屬于極端供不應求的場景,賣家占優勢,所以可以做服務降級,以降低計算資源消耗、提高性能(定制化邏輯)。比如:
- 商詳頁可以把履約時效拿掉,不再計算預計多久能到貨。還可以拿掉評價信息,不再展示評價;
- 下單頁可以不再計算優惠金額分攤,秒殺商品不參與任何疊加的優惠活動。僅保留必要的信息,比如商品信息,商品主圖,購買按鈕,下單按鈕等等。
- 至于結算頁、收銀臺看情況,如果流量壓力不大可以不用做物理隔離的(支付扣減庫存下單的壓力會直接傳遞到結算,但下單扣減就不需要并發支付,僅搶到的用戶需要結算,壓力就很小了。秉著降低流量影響面積的角度,這里假設下單扣減,畢竟秒殺商品也不怕客戶下單后不支付)。
- …
最后,商品購買成功還需要依賴,訂單系統創建訂單,庫存系統扣減商品庫存,結算系統確認支付等等步驟。到達這里流量相對已經比較平穩,并且邏輯上沒有什么定制化訴求(壓力小了,沒必要圍繞性能做定制化了),所以就采用邏輯隔離復用原交易系統的集群。邏輯隔離有兩種實現思路:
- 第一種是依賴限流框架,比如在訂單系統設置來源是秒殺系統BFF的創建訂單請求,TPS不能超過100,并發連接數不能超過20;
- 第二種是依賴RPC框架,RPC框架可以設置分組,只要把訂單系統集群里面部分服務節點設置成“秒殺組”,再把秒殺服務BFF的客戶端也設置為“秒殺組”,那么秒殺系統的流量就只會打到訂單系統集群里面屬于“秒殺組”的節點上。這種隔離方式分割了集群,集群節點少了,出現故障發生過載的可能就提高了,可能會導致秒殺系統不可用。
為什么集群節點少了,出現故障發生過載的可能就提高了?就好比公里原本4條道能并行4輛車,現在給按車輛類型分成了機動車和公交車專用,機動車道2條。如果其中1條機動車道發生車禍,原本分散在2條道上的車流就要匯聚在1條道,原本順暢的通行可能立馬就開始堵車了。
2.多級緩存
多級緩存,無非就是在系統的多個層級進行數據緩存,以提高響應效率,這是高并發架構中最常用的方案之一。
(1) DNS層
一般我們會將靜態資源掛到CDN上,借助CDN來分流和提高響應效率。以秒殺系統為例,就是將秒殺前端系統的商詳頁和下單頁緩存到CDN網絡上。一個借助CDN的用戶請求鏈路如下:
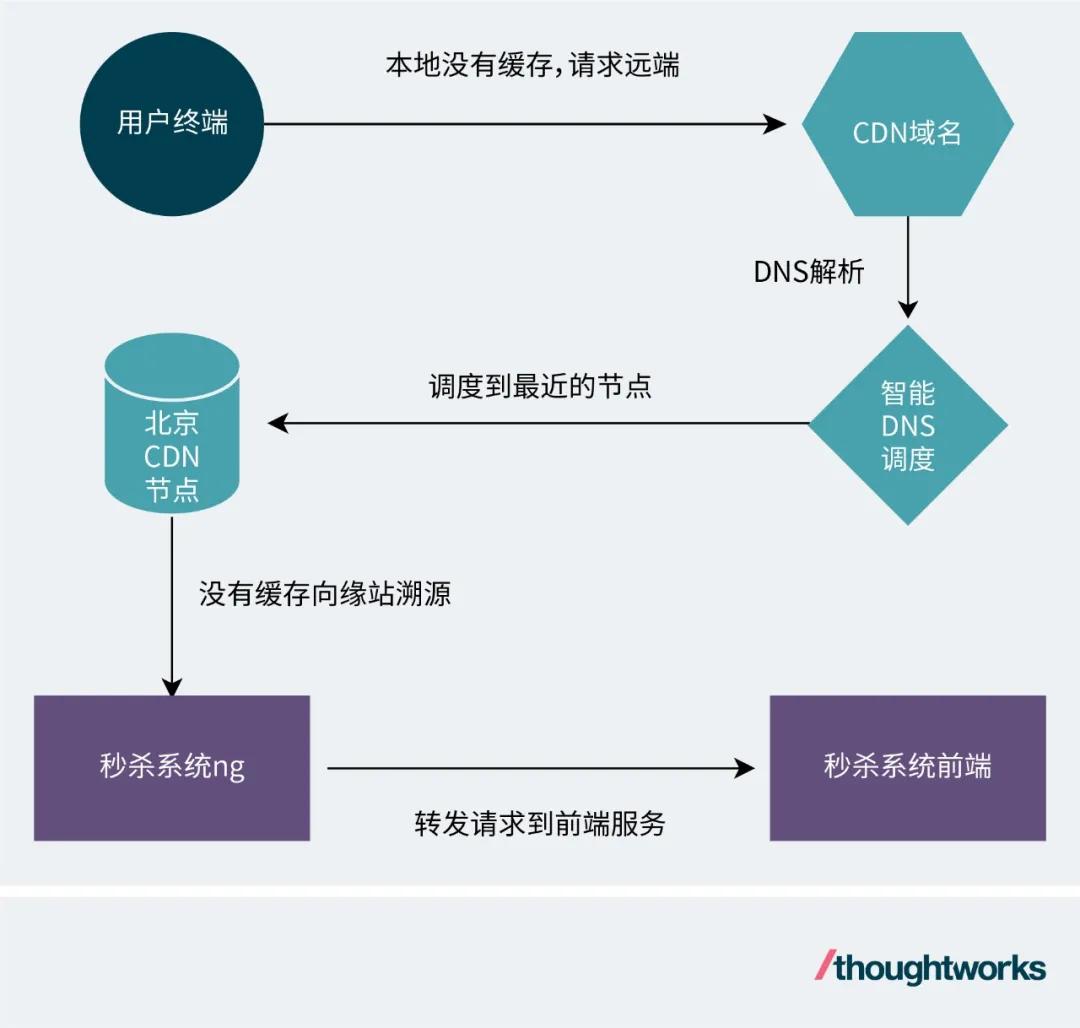
如果用戶終端有頁面緩存就走終端本地緩存,沒有就請求遠端CDN的域名(靜態資源走CDN域名),請求來到DNS調度的節點,調度一個最近的CDN節點,如果該CDN節點有頁面緩存則返回,沒有則向緣站發起溯源,請求就會走普通鏈路過秒殺系統ng到秒殺系統前端。
(2) 網關層
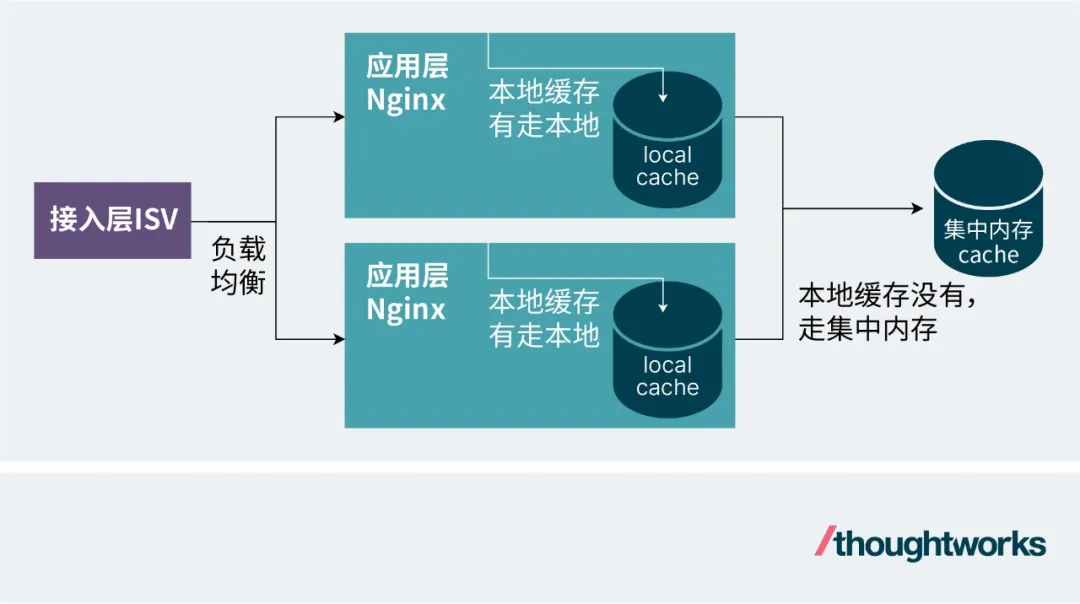
網關這個有多種組合情況,最簡單的就是一個接入層網關加一個應用層網關,比如:ISV(四層)-> Nginx(七層)。以這個為例,這里的緩存優化主要看接入層的負載均衡算法和應用層的本地緩存和集中內存緩存。
之所以說緩存還要提負載均衡算法,是因為節點的本地緩存的有效性和負載均衡算法是強綁定的。常用的負載均衡算法有輪詢(也叫取模)和一致性哈希。輪詢可以讓請求分發更均衡,但同個緩存key的請求不一定會路由到同個應用層Nginx上,Nginx的本地緩存命中率低。一致性哈希可以讓同個緩存key路由到同個應用層Nginx上,Nginx的本地緩存命中率高,但其請求分發不均衡容易出現單機熱點問題。有一種做法是設置一個閾值,當單節點請求超過閾值時改為輪詢,可以算是自適應性負載均衡的變種。但這種基于閾值判斷的做法在應對真正的高并發時效果并不理想。
所以想要運用本地緩存強依賴業務運營,需要對每個熱點商品key有較為準確的流量預估,并人為的組合這些商品key,進而控制流量均勻的落到每個應用層Nginx上(其實就是數據分片,然后每片數據流量一致)。這非常困難,所以筆者認為,還是采用輪詢加集中內存緩存比較簡單有效。
一個從接入層開始帶有本地緩存和集中內存緩存的請求鏈路如下:
(3) 服務層
應用層ngnix->秒殺系統BFF->訂單服務,其實兩兩組合和網關層是一樣的場景。應用層ngnix基于ngnix的負載均衡轉發請求到秒殺系統BFF,秒殺系統BFF基于RPC框架的負載均衡轉發請求到訂單服務。都面臨著負載均衡策略選擇和是否啟用本地緩存的問題。不一樣的點只是緩存的粒度和啟用緩存的技術棧選擇。
(4) 多級緩存失效
多級緩存因為緩存分散到多個層級,所以很難用單一的技術棧來應對緩存失效的問題,但都等到緩存過期,這種更新時延較長又不一定能被業務接受。所以這里就再提下這個話題。有一個做法是基于DB的binlog監聽,各層監聽自己相關的binlog信息,在發生緩存被變更的情況時,及時讓集成內存的緩存失效。本地緩存在這里還有個缺陷,就是緩存失效時需要廣播到所有節點,讓每個節點都失效,對于頻繁變更的熱key就可能產生消息風暴。
3.無損消峰
秒殺活動的特點是瞬時高峰的流量,就像一座高聳的尖塔,短時間內涌入大量請求。為這個峰值準備對應的服務集群,首先成本太高,接著單純的水平擴展也不一定能做到(分布式架構存在量變引起質變的問題,資源擴展到一定量級,原先的技術方案整個就不適用了。比如,當集群節點太多,服務注冊發現可能會有消息風暴;出入口的帶寬出現瓶頸,需要在部署上分流)。更別說這個峰值也不受控制,想要高枕無憂就會有很高的冗余浪費。
所以一般我們會采用消峰的方式:
- 一種是直接斷頭,把超出負荷的流量直接都丟棄掉,也就是我們常見的限流,也稱為有損消峰(如果這是大促的訂單,砍掉的可能都是錢,這個有損是真的資損);
- 另一種就是分流,也叫消峰填谷,通過技術或者業務手段將請求錯開,鋪到更長的時間線上,從而降低峰值,常見的有MQ異步消費和驗證碼問答題。
這里我們先聊下無損消峰,有損放后邊談。
(1) MQ異步消費
MQ依賴三個特性可以做到平滑的最終一致,分別是消息堆積,勻速消費和至少成功一次:
- 有消息堆積才能起到蓄水池的效果,在出水口流速恒定的情況下能接住入水口瞬時的大流量;
- 有勻速消費才能讓下游集群的流量壓力恒定,不會被沖擊;
- 有至少成功一次,才能保證事物最終一致。
以秒殺系統BFF下單操作向訂單服務創建訂單為例。如果沒有消息隊列(MQ),同時有100W個創建請求,訂單系統就必須承擔100W個并行連接的壓力。但是,如果使用了MQ,那么100W個創建請求的壓力將全部轉移到MQ服務端,訂單系統只需要維持64個并行連接,以穩定地消費MQ服務端的消息。
這樣一來,訂單系統的集群規模就可以大大減小,而且更重要的是,系統的穩定性得到了保障。由于并行連接數的減少,資源競爭也會降低,整體響應效率也會提高,就像在食堂排隊打飯一樣,有序排隊比亂搶效率更高。但是,用戶體驗可能會受到影響,因為點擊搶購后可能會收到排隊提示(其實就是友好提示),需要延遲幾十秒甚至幾分鐘才能收到搶購結果。
(2) 驗證碼問答題
引入驗證碼問答題其實有兩層好處,一層是消峰,用戶0.5秒內并發的下單事件,因為個人的手速差異,被平滑的分散到幾秒甚至幾十秒中;另外一層是防刷,提高機器作弊的成本。
① 驗證碼
基本實現步驟如下:
- 請求到來時生成1串6位隨機字符串 verification_code
- 用特定前綴拼接用戶ID作為key,verification_code做為value存redis,超時5s
- 生成一個圖片,將 verification_code 寫到圖片上,返回給用戶
- 用戶輸入圖片中字符串
- 從redis里面取出 verification_code 做比對,如果一致,執行下單操作
但這樣其實是可以用暴力破解的,比如,用機器仿照一個用戶發起10W個請求攜帶不同的6位隨機字符。所以校驗驗證碼時可以使用 GETDEL ,讓驗證碼校驗無論對錯都讓驗證碼失效。
② 問答題
基本實現思路和驗證碼幾乎一樣。差別在于,問答題的題庫要提前生成,請求到來時從題庫中拿到一組問題和答案。然后把答案存redis,問題塞到圖片里返回給用戶。
驗證碼和問答題具有很好的消峰效果。特別是問答題,想要提高消峰效果只要提高問題難度就行,例如,筆者曾經在12306上連續錯了十幾次問答題。但是這也是用戶體驗有損的,例如,雖然筆者當初未能成功搶到票而感到沮喪,但這魔性的題庫依然把筆者成功逗笑。
無損消峰,無損了流量,但損失了用戶體驗。現如今技術水平在不斷進步,解決方法在增多,這些有損用戶體驗的技術方案可能都會慢慢退出歷史舞臺,就像淘寶取消618預售。
4.庫存扣減
我們知道,用戶購買商品需要扣減庫存,扣減庫存需要查詢庫存是否足夠,足夠就占用庫存,不夠則返回庫存不足(這里不區分庫存可用、占用、已消耗等狀態,統一成扣減庫存數量,簡化場景)。
在并發場景,如果查詢庫存和扣減庫存不具備原子性,就有可能出現超賣,而高并發場景超賣的出現概率會增高,超賣的數額也會增高。處理超賣問題是件麻煩事,一方面,系統全鏈路刷數會很麻煩(多團隊協作),客服外呼也會有額外成本。另一方面,也是最主要的原因,客戶搶到了訂單又被取消,會嚴重影響客戶體驗,甚至引發客訴產生公關危機。
(1) 實現邏輯
業內常用的方案就是使用redis+lua,借助redis單線程執行+lua腳本中的邏輯可以在一次執行中順序完成的特性達到原子性(原子性其實不大準確,叫排它性可能更準確些,因為這里不具備回滾動作,異常情況需要自己回滾)。
lua腳本基本實現大致如下:
-- 獲取庫存緩存key KYES[1] = hot_{itemCode-skuCode}_stock
local hot_item_stock = KYES[1]
-- 獲取剩余庫存數量
local stock = tonumber(redis.call('get', hot_item_stock))
-- 購買數量
local buy_qty = tonumber(ARGV[1])
-- 如果庫存小于購買數量 則返回 1, 表達庫存不足
if stock < buy_qty thenreturn1end
-- 庫存足夠
-- 更新庫存數量
stock = stock - buy_qty
redis.call('set', hot_item_stock, tostring(stock))
-- 扣減成功 則返回 2, 表達庫存扣減成功
return2end但這個腳本具備一些問題:
- 不具備冪等性,同個訂單多次執行會出現重復扣減的問題,手動回滾也沒辦法判斷是否會回滾過,會出現重復增加的問題。
- 不具備可追溯性,庫存被誰被哪個訂單扣減了不知道。
結合以上問題,我們對方案做些增強。
增強后的lua腳本如下:
-- 獲取庫存扣減記錄緩存key KYES[2] = hot_{itemCode-skuCode}_deduction_history
-- 使用 Redis Cluster hash tag 保證 stock 和 history 在同個槽
local hot_deduction_history = KYES[2]
-- 請求冪等判斷,存在返回0, 表達已扣減過庫存
local exist = redis.call('hexists', hot_deduction_history, ARGV[2])
if exist = 1thenreturn0end
-- 獲取庫存緩存key KYES[1] = hot_{itemCode-skuCode}_stock
local hot_item_stock = KYES[1]
-- 獲取剩余庫存數量
local stock = tonumber(redis.call('get', hot_item_stock))
-- 購買數量
local buy_qty = tonumber(ARGV[1])
-- 如果庫存小于購買數量 則返回 1, 表達庫存不足
if stock < buy_qty thenreturn1end
-- 庫存足夠
-- 1.更新庫存數量
-- 2.插入扣減記錄 ARGV[2] = ${扣減請求唯一key}-${扣減類型} 值為 buy_qty
stock = stock - buy_qty
redis.call('set', hot_item_stock, tostring(stock))
redis.call('hset', hot_deduction_history, ARGV[2], buy_qty)
-- 如果剩余庫存等于0 則返回 2, 表達庫存已為0
if stock = 0thenreturn2end
-- 剩余庫存不為0 返回 3 表達還有剩余庫存
return3end- 利用Redis Cluster hash tag保證stock和history在同個槽,這樣lua腳本才能正常執行。
- 利用hot_deduction_history,判斷扣減請求是否執行過,以實現冪等性。
- 借助hot_deduction_history的value值判斷追溯扣減來源,比如:用戶A的交易訂單A的扣減請求,或者用戶B的借出單B的扣減請求。
- 回滾邏輯會先判斷hot_deduction_history里面有沒有 ${扣減請求唯一key} ,有則執行回補邏輯,沒有則認定回補成功。
但是以上邏輯依舊有漏洞,比如(消息亂序消費),訂單扣減庫存超時成功觸發了重新扣減庫存,但同時訂單取消觸發了庫存扣減回滾,回滾邏輯先成功,超時成功的重新扣減庫存就會成為臟數據留在redis里。
處理方案有兩種,一種是追加對賬,定期校驗hot_deduction_history中數據對應單據的狀態,對于已經取消的單據追加一次回滾請求,存在時延(業務不一定接受)以及額外計算資源開銷。另一種,是使用有序消息,讓扣減庫存和回滾庫存都走同一個MQ topic的有序隊列,借助MQ消息的有序性保證回滾動作一定在扣減動作后面執行,但有序串行必然帶來性能下降。
(2) 高可用
存在redis終究是內存,一旦服務中斷,數據就消失的干干凈凈。所以需要追加保護數據不丟失的方案。
運用redis部署的高可用方案來實現,方案如下:
- 采用 Redis Cluster(數據分片+ 多副本 + 同步多寫 + 主從自動選舉)。
- 多寫節點分(同城異地)多中心防止意外災害。
定期歸檔冷數據。定期 + 庫存為0觸發redis數據往DB同步,流程如下:
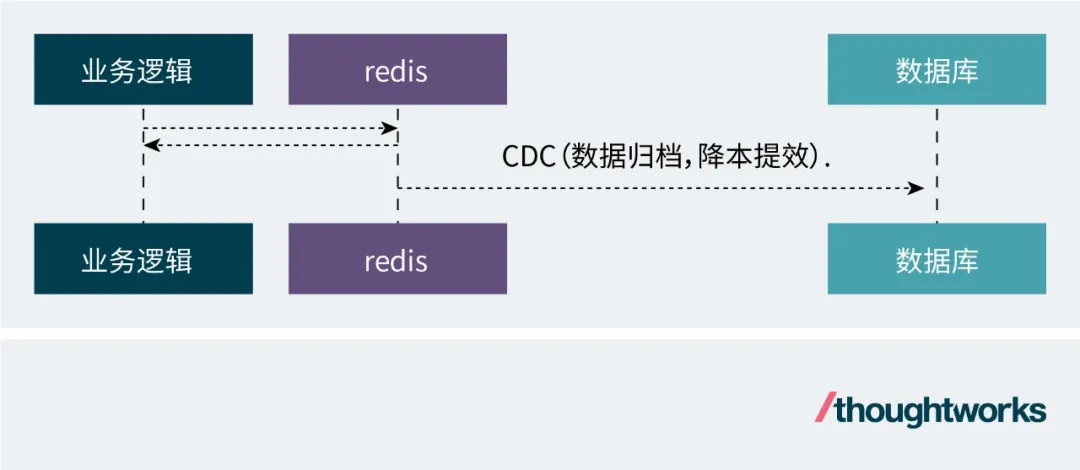
CDC分發數據時,秒殺商品,hot_deduction_history的數據量不高,可以一次全量同步。但如果是普通大促商品,就需要再追加一個map動作分批處理,以保證每次執行CDC的數據量恒定,不至于一次性數據量太大出現OOM。具體代碼如下:
/**
* 對任務做分發
* @param stockKey 目標庫存的key值
*/
public void distribute(String stockKey){
final String historyKey = StrUtil.format("hot_{}_deduction_history", stockKey);
// 獲取指定庫存key 所有扣減記錄的key(一般會采用分頁獲取,防止數據量太多,內存波動,這里偷懶下)
final List<String> keys = RedisUtil.hkeys(historyKey, stockKey);
// 以100為大小,分片所有記錄 key
final List<List<String>> splitKeys = CollUtil.split(keys, 100);
// 將集合分發給各個節點執行
map(historyKey, splitKeys);
}
/**
* 對單頁任務做執行
* @param historyKey 目標庫存的key值
* @param stockKeys 要執行的頁面大小
*/
public void mapExec(String historyKey, List<String> stockKeys){
// 獲取指定庫存key 指定扣減記錄的map
final Map<String, String> keys = RedisUtil.HmgetToMap(historyKey, stockKeys);
keys.entrySet()
.stream()
.map(stockRecordFactory::of)
.forEach(stockRecord ->{
//(冪等+去重)扣減+保存記錄
stockConsumer.exec(stockRecord);
//刪除redis中的 key 釋放空間
RedisUtil.hdel(historyKey, stockRecord.getRecordRedisKey());
});
}(3) 為什么不走DB
商品庫存數據在DB最終會落到單庫單表的一行數據上。無法通過分庫分表提高請求的并行度。而在單節點的場景,數據庫的吞吐遠不如redis。最基礎的原因:IO效率不是一個量級,DB是磁盤操作,而且還可能要多次讀盤,redis是一步到位的內存操作。
同時,一般DB都是提交讀隔離級別,為了保證原子性,執行庫存扣減,得加鎖,無論悲觀還是樂觀。這不僅性能差(搶不到鎖要等待),而且因為非公平競爭,容易出現線程饑餓的問題。而redis是單線程操作,不存在共享變量競爭的問題。
有一些優化思路,比如,合并扣減,走批降低請求的并行連接數。但伴隨而來的是集單的時延,以及按庫分批的訴求;還有拆庫存行,商品A100個庫存拆成2行商品A50庫存,然后扣減時分發請求,以此提高并行連接數(多行可落在不同庫來提高并行連接數)。
但伴隨而來的是復雜的庫存行拆分管理(把什么庫存行在什么時候拆分到哪些庫),以及部分庫存行超賣的問題(加鎖優化就又串行了,不加總量還有庫存,個別庫存行不足是允許一定系數超賣還是返回庫存不足就是一個要決策的問題)。
部分頭部電商還是采用弱緩存抗讀(非庫存不足,不實時更新),DB抗寫的方案。這個的前提在于,通過一系列技術方案,流量落到庫存已經相對低且平滑了(扛得住,不用再自己實現操作原子性)。
有損的技術方案
秒殺活動有極高的瞬時流量,但僅有極少數流量可以請求成功。這為我們繞開海量計算資源采用一些特定方案達到同樣的活動效果提供了空間。因為絕大部分流量都是要請求失敗的,是真實搶購庫存失敗還是被規則過濾掉失敗,都一樣是失敗,對于參與者來說是一樣的活動體驗。所以我們不用耿直地去承接所有流量,變成用一系列過濾手段,公平公正地過濾掉絕大部分流量,僅保留有限的優質流量可以請求到服務群即可。
基本思路就是,通過業務干預阻止無效流量,通過有損消峰丟棄超荷流量,通過防刷風控攔截非法流量,最終留給下游優質且少量的流量。如圖:
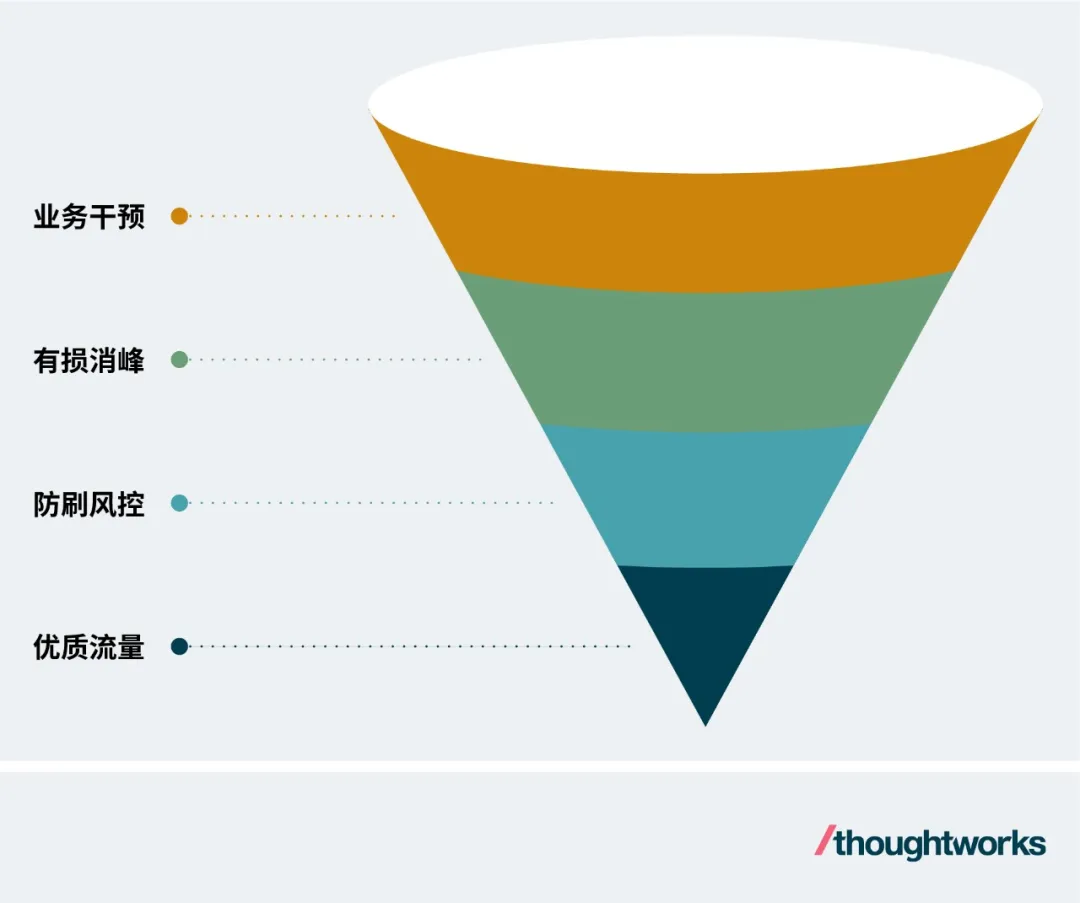
1.業務干預
(1) 提報
借助提報系統,商戶開展高壓力的活動時都提早報備接受審批和調控。這樣,可以提早知道商品、價格、活動開始時間、面向什么地域、預計參與人數、會員要求等等信息。幫助預估出大致流量,支撐編排活動調整活動組合,錯位壓力(也能不斷保持熱點),平滑流量,調整計算機資源應對高并發。設置參與門檻,阻擋非目標人群參與。
(2) 預約
借助預約系統,對活動做預熱、幫助預估大致參與活動的人數幫助評估計算資源容量。引入風控規則,提早過濾刷子人群。采用發放參與資格(類似游戲預約測試資格和發放測試資格),控制參與人數大小。結合提報系統的參數,過濾非目標人群,并盡可能提高參與人員離散度(比如參與證書1W,華南華北華東華西各2500)(假設中獎的人影響范圍是一個圓,人群集中這個圓就有交集,影響范圍就會減少,所以會希望離散些。但也不排除有故意集中發放創造熱點的營銷手段)。
(3) 會員
借助會員系統,篩選出優質用戶。愿意購買會員的用戶相對粘性就比較高(可以借助會員體系做一些提高用戶粘性的舉措,比如信用分,積分,會員等級,優惠卷等等)。同時會員用戶的規模也能幫助預估活動參與流量。
(4) 限購
借助限購系統,比如加強特定區域市場覆蓋,從地區限制,僅華東可以參與購買;輿情公關防控,從用戶限制,自家員工禁止購買(不能既做裁判也下場踢球);提高離散度,從商品限制,一次只能購買一件,一人一個月只能購買一次。
2.有損消峰
前邊講了分流的無損消峰,這里我們講直接去頭的有損消峰。常規方案就是采用限流降級手段,這也是應對高并發必用的手段。
限流是系統自我保護的最底層手段。再厲害的系統,總有其流量承載的上限,一旦流量突破這個上限,就會引起實例宕機,進而發生系統雪崩,帶來災難性后果。所以達到這個流量上限后,橫豎都無法再響應請求,于是直接拋棄這部分請求,保證有限的流量能夠正常交互便成了最優解。
(1) 分層限流
我們知道一個請求會走過多個層級,最終才能到達響應請求的服務節點。假設一個請求會走過網關->單服務集群->單服務節點->單接口這幾個層級,每個層級考慮承載上限的維度和容量都不一樣,所以一般都會有獨立的限流規則。
網關一般是以一個路由配置或者一組api的吞吐指標進行限流,具體配置大致如下:
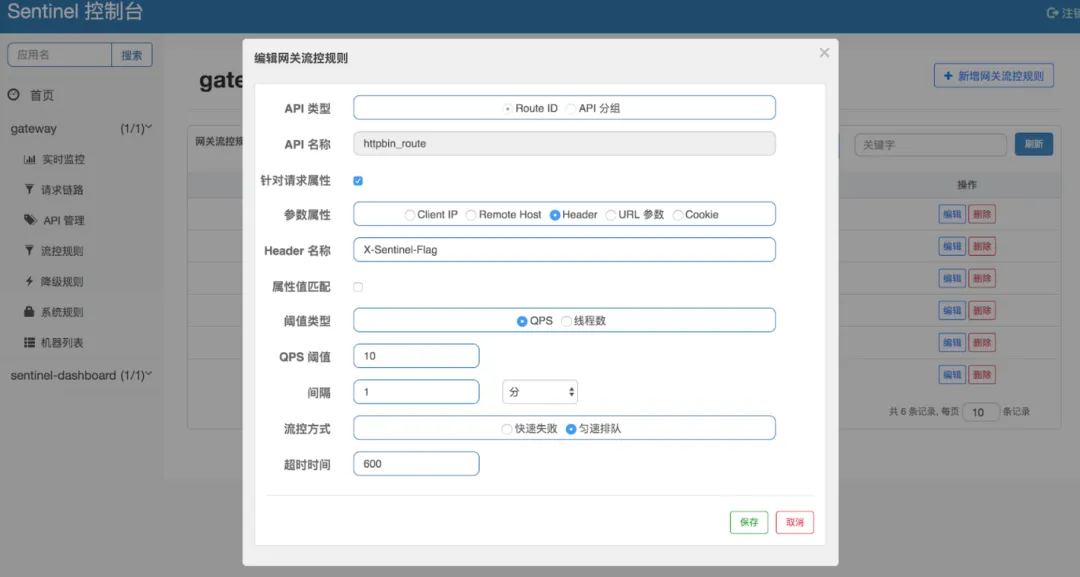
單服務集群一般是以整個集群所有API和所有服務節點為吞吐指標進行限流(不常用),具體配置大致如下:
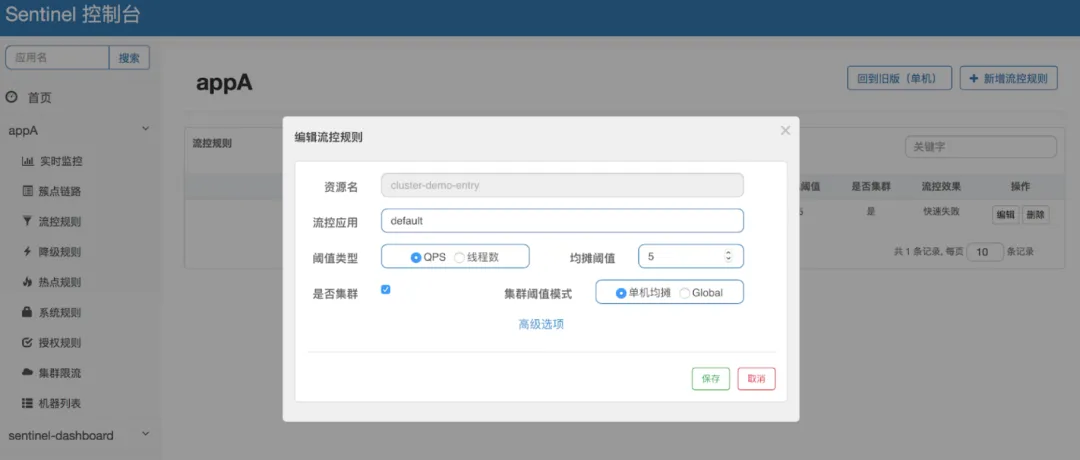
- 單服務節點一般是以服務節點的負載情況來進行限流,比如 Load(綜合計算值)、CPU、內存等等。
- 單接口一般是以整個集群的一個API的吞吐指標來進行限流。
(2) 熱點參數限流
除開分層的限流,還有參數維度的限流。
比如,基于IP地址的吞吐量指標做限流。這個維度,對公司用戶很不友好。因為一般公司就幾個IP出口,大家都連著wifi,很容易就觸發限流。所以,一般參與秒殺活動時還是切換回自己的4G網,wifi再快也架不住被限流。
比如,基于熱點商品的吞吐量指標做限流。在沒有商品維度限流的情況下,假設秒殺下單接口的集群并發限流為100,同一時間參與秒殺活動的商品有10個,商品A在一瞬間就搶占了80并發連接數,剩下的9商品就只能分攤20并發連接數,這會嚴重影響其活動體驗。
限流的口徑有很多,幸運的是它們可以組合使用。這樣就能夠確保服務在各種場景下都有一個可靠的底層防護。
3.防刷風控
秒殺活動中的供需失衡,也會吸引黑產用戶借助非常規手段搶購。比如,通過物理或軟件的按鍵精靈,用比正常用戶更快的速度搶購;通過分析接口模仿下單請求,同時發起千萬個請求,用比正常用戶更高的頻次搶購。這些行為不僅破壞了活動公平性,威脅到普惠和離散訴求,還對系統的高并發峰值帶來了新的量級的挑戰,嚴重影響活動的健康發展。
(1) 防刷
從更快的速度搶購的角度很難區分是正常用戶還是黑產用戶,但更高頻次是很好被捕捉的,畢竟正常人總不能1秒鐘千萬次的點擊吧。所以我們可以針對高頻次這個場景構建一些防刷手段。
(2) 基于userID限流
我們可以采用熱點參數限流的方式,基于用戶ID的吞吐量指標做限流。例如,規定每個用戶ID每秒僅能發起兩次請求。并且,我們應將此限流措施盡可能地置于請求鏈路的上游,如應用網關上,以便在最外層就隔離掉主要流量,從而減少計算資源的浪費。這樣的限流目的與常規的有損消峰略有所不同,它不僅旨在保護服務的穩定性,也在防止黑產用戶的攻擊,以此維護活動的公平性。
(3) 基于黑名單限流
依舊是采用熱點參數限流的方式。但不再是看吞吐量指標,而是看是否命中黑名單來實現限流。黑名單里面的名單,一方面靠一些內部行為分析,比如發現某個用戶每秒可以請求千萬次來識別(就像游戲里面發現外掛封號)。另一方面就是靠外部風控數據的導入了。
(4) 風控
風控在系統防護中占據重要地位,然而其建立卻頗為艱難。健全的風控體系需要依賴大量數據,并通過實際業務場景的嚴苛考驗。簡單來說,風控就像繪制用戶畫像,需要收集用戶的靜態信息,如身份證、IP、設備號(如同一設備或同一IP的多賬戶并行搶購)、信貸記錄、社保信息、工作信息等多維度信息。同時,還要關注用戶的動態信息,如是否存在每秒發起千萬次請求的情況,或者用戶是否只在特定活動中才呈現活躍等。
小結
高并發的主要挑戰在于瞬時激增的大量用戶請求需要同時使用大量的計算資源。為了解決這一挑戰,互聯網應用選用了水平伸縮的發展路線,即分布式架構,通過不斷橫向擴展集群節點來增加計算能力。而我們列舉的方案大部分都直接或間接依賴于分布式架構設計,所以掌握分布式架構其實就等同于掌握高并發系統設計的核心。
優秀的架構更注重權衡,而不是追求極端。應該從業務場景和企業實際情況出發,尋找合適且投資回報率高的方案,而非過度設計或追求最極致的解決方案。更不應出于恐懼落后或投機取巧的心態,盲目追求所謂的"最佳實踐"。