攜程注冊中心整體架構與設計取舍
作者簡介
Siegfried,攜程軟件技術專家,負責攜程注冊中心的研發。
一、前言
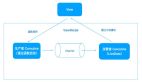
目前,攜程大部分業務已經完成了微服務改造,基本架構如圖。每一個微服務的實例都需要和注冊中心進行通訊:服務端實例向注冊中心注冊自己的服務地址,客戶端實例通過向注冊中心查詢得知服務端地址,從而完成遠程調用。同時,客戶端會訂閱自己關心的服務端地址,當服務端發生變更時,客戶端會收到變更消息,觸發自己重新查詢服務端地址。

疫情剛過去那會,公司業務回暖跡象明顯,微服務實例總數在1個月左右的時間里上漲30%,個別服務的單服務實例數在業務高峰時可達萬級別。按照這個勢頭,預計全公司實例總數可能會在短時間內翻倍。
實例數變大會引起連接數變大,請求量變高,網絡報文變大等一系列現象,對注冊中心的性能產生挑戰。
如果注冊中心遇到性能瓶頸或是運行不穩定,從業務視角看,這會導致新增的實例無法及時接入流量,以至被調方緊急擴容見效慢;或者導致下線的實例不能被及時拉出,以至調用方業務訪問到已下線的實例產生報錯。
如今,業務回暖已經持續接近2年,攜程注冊中心穩定運行,強勁地支撐業務復蘇與擴張,特別是支撐了業務日常或緊急情況下短時間內大量擴縮容的場景。今天就來簡單介紹一下攜程注冊中心的整體架構和設計取舍。
二、整體架構
攜程注冊中心采用兩層結構,分為和數據層(Data)和會話層(Session)。Data負責存放被調方的元信息與實例狀態、計算RPC調用相關的路由策略。Session與SDK直接通訊,負責扛連接數,聚合轉發SDK發起的心跳/查詢請求。

注冊 – 定時心跳
微服務架構下,服務端的一個實例( 被調方)想要被客戶端(調用方)感知,它需要將自己注冊到注冊中心里。服務端實例會發起5秒1次的心跳請求,由Session轉發到對應分片的Data。如果數據層能夠持續不斷的收到一個實例的心跳請求,那么數據層就會判斷這個實例是健康的。
與此同時,數據層會對這一份數據設置TTL,一旦超過TTL沒有收到后續的心跳請求,那么這份數據也就會被判定為過期。也就是說,注冊中心認為對應的這個實例不應再被調方繼續訪問了。
發現 - 事件推送/保底輪詢
當收到新實例的第一個心跳時,數據層會產生一個NEW事件,相對應地,當實例信息過期時,數據層會產生一個DELETE事件。NEW/DELETE事件會通過SDK發起的訂閱連接通知到調用方。
由于網絡等一些不可控的因素,事件推送是有可能丟失,因而SDK也會定時地發起全量查詢請求,以彌補可能丟失的事件。
多分片方案
如圖所示,Data被分成了多分片,不同分片的數據互不重復,從而解決了單臺Data的垂直瓶頸問題(比如內存大小、心跳QPS等)。
Session會對服務ID進行哈希,根據哈希結果將心跳請求、訂閱請求、查詢請求分發到對應的Data分片中。調用方SDK對多個被調方進行信息查詢時,可能會涉及到多個Data分片,那么Session會發起多個請求,并最終負責將所有必要信息聚合起來一并返回給客戶端。

單點故障
與很多其他系統類似,注冊中心也會遇到故障/維護等場景從而遭遇單點故障。我們把具體情況分為Data單點故障和Session單點故障,在兩種情況下,我們都需要保證系統整體的可用性。
單點故障 – Data
如圖所示,SDK發起的心跳請求會被復制到多臺Data上,以保證同一分片中每一臺Data的數據完整性。也就是說,同一個分片的每臺Data都會擁有該分片對應的所有服務的數據。當任一Data出現故障,或是參與到日常運維被踢出集群的情況下,其他任一Data能夠很好的接替它的工作。

這樣的多寫機制相比于之前版本注冊中心采用的Data間復制機制更加簡單。在Data層發生故障時,當前方案對于集群的物理影響會更小,可以做到無需物理切換,因而也更加可靠。
在當前多寫機制下,Data層的數據是最終一致的。心跳請求被分成多個副本后是陸續到達各個Data實例的,在實例發生上線或者下線時,每臺data變更產生的時間點通常會略有不同。
為了盡可能避免上述情況對調用方產生影響,每臺Session會在每個Data分片中選擇一臺Data進行粘滯。同時,SDK對Session也會盡可能地粘滯。
單點故障 – Session
參考上文提到Data分片方案,任一Session都可以獲取到所有Data分片的數據,所有Session節點都具備相同的能力。
因此,任一Session故障時,SDK只需要切換到其他Session即可。
集群自發現
攜程注冊中心是基于Redis做集群自發現的。如下圖所示,Redis維護了所有注冊中心實例的信息。當一個注冊中心實例被創建時,新實例首先會向Redis索要所有其他實例的信息,同時開始持續對Redis發起心跳請求,于是Redis維護的實例信息中也會新增新實例。新實例還會根據從Redis拿到的數據向其他注冊中心實例發起內部的心跳請求。一旦其他實例從Redis獲得了新實例的信息,再加上收到的心跳,就會認可新實例加入集群。

如下圖所示,當時注冊中心實例需要維護或故障時,實例停止運行后不再發起內部心跳。其他實例在該節點的內部心跳過期后,標記該節點為unhealthy,并在任何功能中都不會再使用該節點。這里有一個細節,節點下線不會參考Redis側的數據,Redis故障無法響應查詢請求時,所有注冊中心實例都以兩兩心跳為準。

我們可以了解到,注冊中心實例的上線是強依賴Redis的,但是運行時并不依賴Redis。在Redis故障和運維時,注冊中心的基本功能不受影響,只是無法進行擴容。
三、設計取舍
新增代理還是Smart SDK?
注冊中心設計之初只有Data一層,由于要引入分片機制,才有了Session。那么是不是也可以把分片的邏輯做到SDK,而不引入Session這一層呢?
這也是一種方式,業界也一直有著代理和Smart SDK之爭。我們基于注冊中心所對應的業務場景,認為新增一層代理是更加合適的。
最重要的一點,注冊中心的相關功能運行不在BU業務邏輯主鏈路上,其響應時間并非直接影響業務的響應時間。因此我們對注冊中心的請求響應時間并沒有極致的要求,代理層引入的幾百微秒的延遲可以被接受。
其次注冊中心的請求是一定程度容忍失敗的,SDK請求數據失敗后可以繼續使用內存中的老數據,不會對業務線產生致命影響。因此代理層引入的失敗率也可以被接受。
另一側,代理的加入帶來了諸多好處。最直接地,落地分片邏輯不需要所有的SDK升級,分片邏輯迭代時,對業務也是無感。
其次,代理層也隔離了連接數這一瓶頸,當SDK層的實例不斷變多,連接數不斷增加時,只需要擴容代理層就能解決連接數的問題。這也是我們將它取名為Session的原因。
同時,我們也希望作為物理層的SDK邏輯更加輕量,比較重的邏輯放在邏輯層,這樣穩定性更強更不容易出錯。比如后續會提到的“Data按業務隔離分組”就是在Session層實現的。
普通哈希還是一致性哈希?
攜程注冊中心的數據分片是采用普通哈希的,并沒有采用一致性哈希。
我們知道,一致性哈希相比普通哈希的最大賣點是當節點數量變化時,不需要遷移所有數據。
結合注冊中心的場景,我們用服務ID做哈希,而服務數量(也包括實例數量)是相對穩定的,因此哈希節點的擴容周期會比較長,基本用不到一致性哈希的優勢特性。哪怕一段時間內業務迅速擴張,只要提前做好預估,留好余量一次性擴容就好了。
我們選擇普通的固定的哈希,并讓每一個分片都具備多個備份節點,這樣就基本可以認為每個分片都不會徹底掛掉,不用去實現數據遷移的邏輯,整個機制更簡單了。
要知道,數據遷移需要對注冊請求、查詢請求和訂閱請求進行同步切換,要處理好各種狀態,避免在數據遷移過程中錯查到空數據或者丟失變更事件,非常復雜危險。
自發現是否強依賴Redis?
前面也提到,注冊中心自發現的運行時是不依賴Redis的。有的同學可能會想到,如果運行時強依賴Redis,就可以去掉兩兩注冊了。
兩兩注冊確實是一個不好的設計,隨著集群的節點數越來越大,其產生的性能開銷肯定也會更大,影響整個注冊中心集群的拓展能力。
但在目前規模下,內部心跳占用的系統資源并不可觀。哪怕規模再拓展,通過降低心跳的頻率,進一步降低資源開銷。
最大的好處是,Redis集群故障或者維護時,并不會對注冊中心的功能產生影響。
基于Redis還是用Java寫?
目前注冊中心的Data是用Java實現的。有的同學可能會想,Data層主要就是維護微服務實例的存活狀態,能不能直接用Redis實現呢?如果用Redis,不就可以直接復用Redis體系的擴容/切換能力了嗎?
比如基于Redis 6.0的Client Cache功能,通過Invalidate機制通知SDK重新更新服務信息。
不過在攜程注冊中心設計之初,Redis版本還比較老,沒有這些新feature,感覺基于pub/sub機制做注冊中心還挺麻煩的。現在注冊中心已經穩定運行了好久,加了很多功能,比如路由策略一部分的計算過程就是在Data層完成的,暫時沒有必要推倒重建。
總的來說,用Java寫更可控,后續自定義程度更高。
四、需要注意的場景
突發流量
在遇到節假日,或是公司促銷活動,亦或是友商故障的情況下,公司集群會因為業務量急劇上升而迅速自動擴容,因而注冊中心會受到強勁的流量沖擊。
期間因為系統資源被榨干,注冊/發現請求可能會偶發失敗,事件推送延遲和丟失率會上升。嚴重時,部分調用方業務會無法及時感知到被調方的變動,從而導致請求失敗,或流量無法被分攤到新擴容的被調方實例。
我們發現,這些場景產生的流量有著很高的重復度,比如某個被調方實例擴容,調用方的眾多實例需要知道的信息是完全一樣的,又比如調用方實例擴容,這些新擴的實例部署著相同的代碼,它們依賴的被調方信息也是完全一樣的。

因此我們針對性的做了不少聚合與去重,大大降低了突發流量情況下的資源開銷。
流量不均衡
關于Data粘滯,這里有一個細節。那么多Data機器,Session選誰呢?目前Session是用類似隨機的方式選擇Data的。那就會有一個場景,我們對Data層進行版本更替,逐個實例重新發布,當一個實例被重置時,Session就會因為丟失粘滯對象而重新隨機選擇。
我們會發現,最后一個Data實例完成發布時,它不會被任何Session選中。而第一個發布的Data實例,它傾向于被更多的Session選中。
通常來說,越早發布的Data實例,就會被越多的Session選中。也正因為如此,更早發布的Data會承擔更多的流量,而最后發布的Data一般不承擔流量。這顯然是不合理的。
解決這個問題的方法也很簡單,我們引入擁有全局視角的第三者,整體調控Session的粘滯,保證Data盡可能地被相同數量的Session選中。
全局風險
前面也提到,Data層被分成了多分片,Session會對服務ID進行哈希,將心跳請求、訂閱請求、查詢請求分發到對應的Data層分片中。
當程序出現預期外的問題(程序bug,OOM等等)導致某個Data無法正常的履行功能職責時,那些被分配到這個Data實的服務就會受到影響。
如果調配方式是對服務ID做哈希,那么所有業務線的任意服務都可能參與其中,從業務視角去看,就是整個公司都受到了影響。
對服務ID做哈希是有它的優勢的,它無需引入過多的外部依賴,只需要一小段代碼就能工作。但我們還是認為避免全局故障更加重要。
因此我們最近對Data引入了業務語義,將Data分為多個組,以各個業務線命名。且我們可以按服務粒度對數據進行分配。默認情況下,我們會將服務分配到自己BU的分組上。
這樣,我們就具備了以下能力:
1)不同業務線的數據可以被很好的隔離,任一業務線的Data數據出現問題,不會影響到其他業務線。
2)注冊中心將獲得故障切換的能力,當個別服務的數據出現問題時,我們可以將它單獨切走。
3)我們可以將一些不重要的應用單獨隔離到一個灰度分組,新代碼可以先發布到灰度分組上,盡可能避免新代碼引入的問題直接影響核心業務分組。
4)注冊中心將獲得應用粒度的部署能力。在集群分配上,具備更強的靈活度,針對業務規模的大小合理分配系統資源。

從圖中可以看到,我們在引入分組邏輯的同時也兼容老的分片邏輯,這樣做是為了在分組邏輯上線過程初期,服務信息在Data層的分布可以盡可能保持不變,可以讓少數的服務先灰度切換到新增的分組上進行驗證。
當然,從去復雜度的角度考慮,最終分片邏輯還是要下線,垂直擴容的能力也可以由分組實現。
五、后續規劃
因為注冊中心引入了分組機制,并對各個業務線數據進行了隔離,注冊中心的集群規模也在因此膨脹,分組數量較多,運維成本也隨之上升。
后續我們計劃進一步優化優化單機性能,精簡優化一些不必要的機制,降低機器數量。
同時,我們也希望注冊中心能夠支持彈性,能夠在業務高峰時自動擴容,在業務低峰時自動縮容。