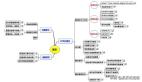
PostgreSQL 索引類型詳解
索引類型
B-tree 索引:
適用場景:范圍查詢、等值查詢、排序操作。
特點:適用于大部分查詢場景,是 PostgreSQL 默認的索引類型。
哈希索引:
適用場景:等值查詢,對于頻繁的等值查詢有性能優勢。
特點:不支持范圍查詢和排序操作,大小寫敏感。
GIN 索引:
適用場景:全文搜索、數組包含查詢、JSONB 數據類型查詢。
特點:支持對復雜查詢條件的優化,如使用數組和 JSONB 類型的數據。
GiST 索引:
適用場景:空間數據類型(如幾何形狀)、全文搜索。
特點:支持多種數據類型的復雜查詢優化。
BRIN 索引:
適用場景:大表的列存儲,適合有序數據。
特點:適合于大數據量表的存儲,減少索引的存儲空間。
Partial 索引:
適用場景:對表中特定子集數據的查詢優化。
特點:只對表中滿足條件的行建立索引,節省存儲空間和提高查詢性能。
SP-GiST 索引:
適用場景:空間數據類型(如幾何形狀)、全文搜索。
特點:支持多種數據類型的復雜查詢優化。
bloom 索引:
適用場景:適用于高基數列的等值查詢優化。
特點:布隆過濾器索引,適合于檢查元素是否屬于一個集合,但可能存在誤報(false positive),因此需要使用實際數據再次驗證
多列索引
只有B 樹、GiST、GIN 和 BRIN索引類型支持多列鍵索引。索引是否可以有多個鍵列與是否可以向索引中添加列無關。每個索引最多可以有32列,包括鍵列
示例
CREATE INDEX test2_mm_idx ON test2 (major, minor);1)B 樹索引
多列B 樹索引可以與涉及索引任意子集的查詢條件一起使用,但在約束條件應用于前導(最左邊)列時效率最高。
對于多列索引,等式約束應用于前導列,并且在第一個沒有等式約束的列上應用不等式約束,這些約束將限制掃描索引的部分。
對于后續列的約束也會在索引中檢查,這樣可以減少對實際表的訪問次數,但并不會減少需要掃描的索引部分。
2)GiST 索引
多列GiST索引可以與涉及任意子集的查詢條件一起使用。對額外列的條件限制會限制索引返回的條目,但第一列上的條件最為重要,影響需要掃描的索引部分。
3)GIN 索引:
多列GIN索引可以與涉及任意子集的查詢條件一起使用。與B 樹或GiST不同的是,無論查詢條件使用哪些索引列,索引搜索的效果都是相同的。
4)BRIN 索引:
多列BRIN索引可以與涉及任意子集的查詢條件一起使用。與GIN類似,與B 樹或GiST不同的是,無論查詢條件使用哪些索引列,索引搜索的效果都是相同的。
在單個表上,多個BRIN索引通常沒有必要,除非需要使用不同的存儲參數(pages_per_range)。
總結:
每種索引類型對多列索引的支持和效果略有不同,應根據具體查詢模式、數據類型和性能需求選擇合適的索引類型。
多列索引應謹慎使用,因為單列索引通常已經足夠提供良好的性能,并節省存儲空間和維護成本。
對于超過三列的索引,除非表的使用非常特殊,否則可能不會有幫助。
索引和ORDER BY
目前 PostgreSQL 支持的索引類型中,只有 B 樹能夠產生排序的輸出結果 — 其他索引類型返回的匹配行的順序是未指定的,依賴于具體實現。
默認情況下,B 樹索引以升序存儲條目,空值排在最后。這意味著對于列 x 的索引正向掃描會生成滿足 ORDER BY x 或 ORDER BY x ASC NULLS LAST 的輸出。索引也可以反向掃描,生成滿足 ORDER BY x DESC 或 ORDER BY x DESC NULLS FIRST 的輸出。
在創建 B 樹索引時,可以通過包括 ASC、DESC、NULLS FIRST 和 NULLS LAST 選項來調整索引的排序順序。
例如:
CREATE INDEX test2_info_nulls_low ON test2 (info NULLS FIRST);
CREATE INDEX test3_desc_index ON test3 (id DESC NULLS LAST);在單列索引中,這些選項可能看起來有些冗余,但在多列索引中它們非常有用。考慮一個兩列索引 (x, y):正向掃描可以滿足 ORDER BY x, y,反向掃描可以滿足 ORDER BY x DESC, y DESC。但如果應用程序頻繁需要使用 ORDER BY x, y ASC,則普通索引無法提供此順序,但可以通過定義為 (x ASC, y ASC) 或 (x DESC, y ASC) 來實現。
顯然,具有非默認排序順序的索引是一種相對特殊的功能,但有時它們可以為某些查詢帶來巨大的性能提升。是否值得維護這樣的索引取決于查詢中需要特定排序順序的頻率。
組合多個索引
單索引限制:
- 單個索引掃描僅能使用涉及索引列和相應操作符的查詢子句。例如,復合條件如 (a = 5 AND b = 6) 可以使用索引,但像 (a = 5 OR b = 6) 這樣的查詢則不能直接使用索引。
多索引組合優勢:
- PostgreSQL 提供了能力來結合多個索引(包括同一索引的多次使用),以處理單個索引無法覆蓋的查詢情況。系統可以通過多次索引掃描形成 AND 和 OR 條件來實現復雜的查詢需求。
操作原理:
- 結合多個索引時,系統會對每個索引進行掃描,生成一個位圖表示匹配該索引條件的表行位置。這些位圖根據查詢的需要進行 AND 和 OR 運算。最終,實際的表行按物理順序訪問并返回結果。
性能考慮:
- 盡管多索引組合可以解決復雜查詢,每個額外的索引掃描會增加時間成本。因此,對于需要大量掃描的查詢,可能會選擇使用簡單的索引掃描,而不是結合多個索引。
索引設計策略:
- 在設計索引時,數據庫開發人員需權衡決策哪些索引能夠最好地支持常見的查詢模式。有時候選擇多列索引是最優的,但在某些情況下,創建單獨的索引并依賴索引組合功能可能更為有效。
唯一索引
聲明唯一索引:
- 使用 CREATE UNIQUE INDEX 語句可以創建唯一索引,目前只有 B 樹索引支持唯一性約束。
示例:CREATE UNIQUE INDEX name ON table (column [, ...]);唯一索引特性:
- 聲明唯一索引后,索引列的數值在表中必須唯一,不允許出現相同的索引值對應多行數據。
- 默認情況下,唯一索引對空值不視為相同,因此允許多個空值存在于索引列中。使用 NULLS NOT DISTINCT 可以修改此行為,使得空值視為相同。
自動創建唯一索引:
- 當為表定義唯一約束或主鍵時,PostgreSQL 會自動創建唯一索引。該索引覆蓋構成主鍵或唯一約束的列(如果適用,會創建多列索引),并用于實施約束。
注意事項:
在唯一約束列上手動創建索引通常是多余的,因為系統會自動創建該索引。手動創建索引可能會導致重復,不建議這樣做。
表達式的索引
索引列不必只是基礎表的一列,還可以是從表的一列或多列計算得出的函數或標量表達式。此功能對于根據計算結果快速訪問表非常有用。
例子:大小寫不敏感比較
- 使用函數 lower 進行大小寫不敏感的比較:
SELECT * FROM test1 WHERE lower(col1) = 'value';- 如果在 lower(col1) 的結果上定義了索引,這個查詢可以利用索引:
CREATE INDEX test1_lower_col1_idx ON test1 (lower(col1));- 這種索引可以防止插入值僅在大小寫上有區別的行,以及確保實際值相同的行不會重復插入,因此索引表達式可以用于實施不能定義為簡單唯一約束的約束。
- 如果經常執行像下面這樣的查詢:
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';- 可以考慮創建以下索引,結合 first_name 和 last_name:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));- 在定義索引表達式時,通常需要在表達式周圍加上括號,如第二個例子所示。當表達式僅為函數調用時,可以省略括號,如第一個例子。
索引表達式的性能
- 索引表達式的維護成本較高,因為對于每次行插入和非 HOT 更新,必須計算派生表達式。然而,在索引搜索期間,不需要重新計算索引表達式,因為它們已經存儲在索引中。
- 索引表達式適用于檢索速度比插入和更新速度更重要的場景。
部分索引
主要用途:
- 避免索引常見值:部分索引的一個主要原因是避免索引常見值。如果一個查詢搜索的是常見值(即占表行總數超過幾個百分點的值),那么索引將不會被使用,因此沒有必要在索引中保留這些行。通過部分索引,可以減小索引的大小,加快那些使用索引的查詢速度。此外,由于索引不需要在所有情況下都更新,部分索引還可以加快許多表更新操作的速度。
- 索引數據:不在索引范圍內的數據,不能使用部分索引。
例 11.1設置部分索引以排除公共值
假設你在數據庫中存儲 Web 服務器訪問日志。大多數訪問來自于你組織的 IP 地址范圍,但有些來自于其他地方(比如員工使用撥號連接)。如果你的 IP 地址搜索主要針對外部訪問,那么你可能不需要索引與你組織子網對應的 IP 范圍。
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE NOT (client_ip > inet '192.168.100.0' AND
client_ip < inet '192.168.100.255');例 11.2.設置部分索引以排除不感興趣的值
如果您的表同時包含計費訂單和未計費訂單,其中未計費訂單僅占總表的一小部分,但這些行是訪問次數最多的行,則可以通過僅在未計費行上創建索引來提高性能。創建索引的命令如下所示:
CREATE INDEX orders_unbilled_index ON orders (order_nr)
WHERE billed is not true;例 11.3.設置部分唯一索引
假設我們有一個描述測試結果的表格。我們希望確保給定的主題和目標組合只有一個“成功”條目,但可能存在任意數量的“不成功”條目。這是一種方法:
CREATE TABLE tests (
subject text,
target text,
success boolean,
faill boolean
...
);
CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target)
WHERE success;當成功的測試很少而失敗的測試很多時,這是一種特別有效的方法。也可以通過創建具有限制的唯一部分索引,在列中只允許一個 null。IS NULL
例 11.4.不要使用部分索引來替代分區
在數據庫中,不應該通過創建大量非重疊的部分索引來替代分區。例如,像下面這樣創建一組部分索引:
CREATE INDEX mytable_cat_1 ON mytable (data) WHERE category = 1;
CREATE INDEX mytable_cat_2 ON mytable (data) WHERE category = 2;
CREATE INDEX mytable_cat_3 ON mytable (data) WHERE category = 3;
...
CREATE INDEX mytable_cat_N ON mytable (data) WHERE category = N;這種做法是不明智的!更好的方式是使用一個單獨的非部分索引,如下所示:
CREATE INDEX mytable_cat_data ON mytable (category, data);注意事項
這種部分索引需要預先確定共同的值,因此最適合用于數據分布不會經常變化的情況。這樣的索引偶爾需要重新創建以適應新的數據分布,但這會增加維護工作量。
僅索引掃描和覆蓋索引
索引類型與索引只掃描:
- 所有的索引在PostgreSQL中都是輔助索引(Secondary Index),與表的主數據區域(Heap)分開存儲。
- 索引只掃描要求索引類型必須支持,例如B-tree索引始終支持,GiST和SP-GiST索引則根據操作類別支持不同的索引只掃描。
索引只掃描的條件:
- 查詢必須僅引用存儲在索引中的列,如果查詢引用了非索引列,則無法使用索引只掃描。
- 對于表掃描,還需要驗證每個檢索的行對于查詢的MVCC快照是否可見,這是通過可見性映射(Visibility Map)實現的。
覆蓋索引(Covering Index):
- 為了有效利用索引只掃描功能,可以創建覆蓋索引,即包含查詢所需列的索引。
- 使用INCLUDE子句可以添加非搜索鍵的列到索引中,提高特定查詢模式的性能。
注意事項:
- 添加非鍵列到索引可能會增加索引的大小,可能導致性能下降,尤其是對于寬列。
- 在表數據變化較慢的情況下,才有利于索引只掃描不訪問堆。
- 目前表達式索引不支持作為包含列,而且只有B-tree、GiST和SP-GiST索引支持包含列。
檢查和優化索引的使用情況
使用 EXPLAIN 命令分析單個查詢:
使用 EXPLAIN 命令可以分析單個查詢的執行計劃,包括查詢是否使用了索引以及使用了哪些索引。
這對于了解實際查詢工作負載中索引的使用情況非常重要。
收集統計信息:
在優化索引前,始終先運行 ANALYZE 命令。這個命令用于收集關于表中值分布的統計信息。
統計信息對于評估查詢返回行數的分布是必要的,優化器需要根據這些信息為每個可能的查詢計劃分配合理的成本。
如果沒有實際的統計信息,優化器會使用默認值,這幾乎肯定是不準確的。
使用真實數據進行實驗:
在設置索引時,使用真實數據進行實驗可以告訴你針對測試數據集需要哪些索引。
使用非常小的測試數據集通常是不可取的,因為這可能無法準確反映真實數據的查詢性能。
強制使用索引:
當索引未被使用時,可以通過運行時參數強制其使用,例如關閉順序掃描 (enable_seqscan) 或嵌套循環連接 (enable_nestloop)。
如果強制使用索引后確實使用了索引,那么有兩種可能性:系統正確地判斷索引不適合使用,或者查詢計劃的成本估算不符合實際情況。
使用 EXPLAIN ANALYZE 命令:
使用 EXPLAIN ANALYZE 命令可以獲取查詢的詳細執行統計信息,包括實際執行時間和成本估算。
這對于評估查詢計劃的實際性能表現非常有用,特別是在調整查詢計劃的成本估算時。
調整查詢計劃的成本估算:
如果成本估算不準確,可以通過調整運行時參數來調整計劃節點的成本估算,或者通過優化統計信息收集參數來提高查詢選擇性估算的準確性。
總體而言,優化索引的過程涉及實驗、分析和調整,需要根據具體的查詢工作負載和實際數據來進行。通過這些步驟,可以更有效地提升 PostgreSQL 數據庫的查詢性能和響應速度。
索引的選擇和使用
在設計和選擇索引時,需要考慮以下因素:
- 查詢模式:經常執行的查詢類型是什么?
- 數據類型:表中存儲的數據類型及其特點。
- 數據分布:索引列上數據的分布情況,是否均勻?
- 寫入操作:索引對寫入操作的影響如何?
綜上所述,每種索引類型在不同的場景下都有其優勢和劣勢。正確選擇和設計索引是優化 PostgreSQL 數據庫性能的關鍵一步。