













編譯 | 汪昊
審校 | 重樓
推薦系統是 1992 年施樂公司的 David Goldberg 在論文中首次提出的。人類歷史上第一個發表的推薦系統算法是協同過濾。該算法長期占據著主導地位。一直到最近,仍然有研究者發問稱對比了大量的推薦算法,發現基于物品的協同過濾性能優異,吊打其他算法。

隨著時間的推移,出現了越來越多的推薦系統算法。1998年,亞馬遜公司的員工發明了基于物品的推薦系統。隨后在 2006 年,因為 Netflix 推薦系統大賽的緣故,基于矩陣分解的推薦系統被發明出來。隨后在 2010 年左右,線性模型和排序學習算法風靡一時。從 2016 年開始,基于深度學習的推薦算法后來居上,一舉占據了包括 RecSys 在內的各大學術會議的顯要位置,給推薦系統領域帶來了一場徹底的革命。
2017 年開始,人工智能領域的研究者開始廣泛關注人工智能倫理問題。隨后,推薦系統的具體場景落地問題得到了關注,尤其是序列化推薦,成為了熱門研究課題。本文將帶領讀者閱讀數據挖掘頂級會議 ACM KDD 2023 年的論文 Text Is All You Need: Learning Language Representations for Sequential Recommendation。論文的作者來自美國高校 UCSD 和美國公司亞馬遜。
 圖一輸入數據中用戶信息
圖一輸入數據中用戶信息
圖一中顯示了這篇文章中的算法利用的輸入數據與其他算法的不同:物品不再是由物品 ID 唯一表示的數字,而是一個鍵值對構成的數據集合。例如,一臺蘋果筆記本電腦,不再由一個數字 315 表示,而是由產品名稱、品牌名稱和顏色代表的數據集合表示。
 圖二算法架構圖
圖二算法架構圖
在作者設計的算法架構中,共有 4 個嵌入層:
- 元素嵌入向量:鍵值對中每個元素的嵌入向量
- 元素位置向量:用于表示元素在序列中位置的向量
- 元素類型向量:用于表示元素類型的向量
- 物品位置向量:用于表示物品在序列中位置的向量
算法架構在 4 個嵌入層求和之后加入了一個 Layer Normalization 層:

隨后我們得到嵌入層的終極表示方法:
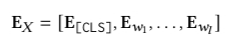
我們隨后利用雙向 Transformer 結構 Longformer 對嵌入層編碼,得到物品的嵌入式向量表示:
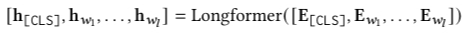
給定序列 S,序列中下一個出現的物品為物品 i 的評分由下述公式計算:
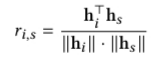
預測出現的物品 i 為使上面公式得分值最高的物品:
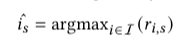
為了讓算法效率更高,作者提出了預訓練模型+兩階段微調算法來實現算法架構:
為了使上面的算法執行速度更加高效,研究者提出了利用預訓練模型來實現上述算法結構。第一種預訓練模式是 MLM,也就是 Masked Language Modeling 。MLM 的算法架構流程如下:
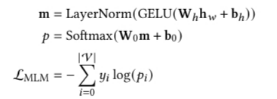
另一種預訓練模式是 item-item contrative (IIC)。這種預訓練模式的損失函數定義如下:
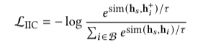
在算法的實際執行中,我們采用了加權和的形式:
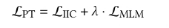
最后,我們對算法做兩階段微調。算法的偽代碼如下:

作者最后在論文中針對該算法做了對比實驗:
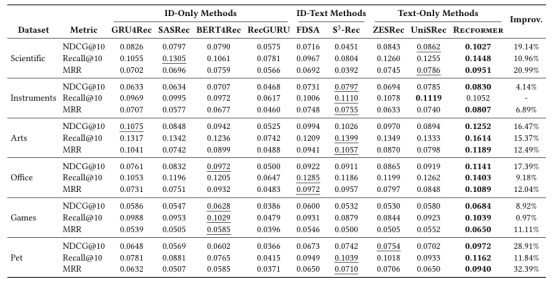
通過實驗,我們發現作者在論文中提出的算法性能優越。
推薦系統自誕生以來,算法架構變得越來越復雜。隨著大模型的興起,如何利用大模型進行推薦也成為了研究的熱點。如果有一天大模型被證明能使推薦的效果明顯好于其他方法,推薦系統的研發將被集中在極少數有能力提供數據和大規模 GPU 集群的公司。因此,趁著這一切還沒有發生,廣大中小企業,還有高校師生,以及獨立研究者應該抓緊時間為這一領域增磚添瓦。
作者簡介
汪昊,達評奇智董事長兼創始人。汪先生在 ThoughtWorks、豆瓣、百度、聯想和趣加等公司有超過 13 年的研發和管理經驗。擅長推薦系統、風控反欺詐、爬蟲和自然語言處理等技術。成功上線了包括豆瓣小組推薦、聯想電商推薦和網易段子項目等 10 余款科技產品。在國際學術會議和期刊發表論文 44 篇。獲得 IEEE SMI 2008 (CCF-C) 最佳論文獎,ICBDT 2020、IEEE ICISCAE 2021、AIBT 2023 和 ICSIM 2024 最佳論文報告獎。




















