面試官問:排序算法都有哪些?你寫幾個出來?
 圖片
圖片
穩定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不穩定:如果a原本在b的前面,而a=b,排序之后a可能會出現在b的后面;
內排序:所有排序操作都在內存中完成;
外排序:由于數據太大,因此把數據放在磁盤中,而排序通過磁盤和內存的數據傳輸才能進行;
時間復雜度: 一個算法執行所耗費的時間。
空間復雜度: 運行完一個程序所需內存的大小。
冒泡排序
冒泡排序是最簡單直觀的排序方式,通過比較前后兩個元素的大小,然后交換位置來實現排序。
每次比較相鄰兩個數的大小,如果前面的數大于后面的數,則交換兩個數的位置(否則不變),向后移動。
// 冒泡排序
func BubbleSort(arr []int){
n := len(arr)
for i:=0; i<n-1; i++{
for j:=i+1; j<n; j++{
if arr[i] > arr[j]{
arr[i], arr[j] = arr[j], arr[i]
}
}
}
fmt.Println(arr)
}改進冒泡排序:
冒泡排序第1次遍歷后會將最大值放到最右邊,這個最大值也是全局最大值。
同理,當前輪的最大值也都會放在最后,每輪結束后,最大值、次大值。。。都會固定,但是普通版冒泡排序每次都會比較全部元素。可以記錄每輪比較后最后一個位置,也可以逆序遍歷。
// 改進的冒泡排序
func BubbleSort2(arr []int){
n := len(arr)
for i:=n-1; i>0; i--{ // 逆序遍歷
for j:=0; j<i; j++{
if arr[j] > arr[j+1]{
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
fmt.Println(arr)
}選擇排序
選擇排序是一種簡單直觀的排序算法,無論什么數據進去都是 O(n2) 的時間復雜度。所以用到它的時候,數據規模越小越好。唯一的好處可能就是不占用額外的內存空間了吧。
算法步驟:
- 初始序列arr,無序。分成有序區和無序區,有序區初始為0,不斷變大;無序區初始為len(arr),不斷變小。
- 遍歷無序找到最小值,與無序區最左邊交換。有序區長度+1。
- 重復第二步。
// 選擇排序
func SelectionSort(arr []int){
n := len(arr)
for i:=0; i<n-1; i++{
minNumIndex := i // 無序區第一個
for j:=i+1; j<n; j++{
if arr[j] < arr[minNumIndex]{
minNumIndex = j
}
}
arr[i], arr[minNumIndex] = arr[minNumIndex], arr[i]
}
fmt.Println(arr)
}插入排序
插入排序的代碼實現雖然沒有冒泡排序和選擇排序那么簡單粗暴,但它的原理應該是最容易理解的了,因為只要打過撲克牌的人都應該能夠秒懂。
插入排序是一種最簡單直觀的排序算法,它的工作原理是通過構建有序序列,對于未排序數據,在已排序序列中從后向前掃描,找到相應位置并插入。
插入排序和冒泡排序一樣,也有一種優化算法,叫做拆半插入。
將第一待排序序列第一個元素看做一個有序序列,把第二個元素到最后一個元素當成是未排序序列。
從頭到尾依次掃描未排序序列,將掃描到的每個元素插入有序序列的適當位置。(如果待插入的元素與有序序列中的某個元素相等,則將待插入元素插入到相等元素的后面。)
// 插入排序
func InsertionSort(arr []int){
for i := range arr{
preIndex := i-1
current := arr[i]
for preIndex >= 0 && arr[preIndex] > current{ // 移動
arr[preIndex+1] = arr[preIndex]
preIndex--
}
arr[preIndex+1] = current
}
fmt.Println(arr)
}改進插入排序: 查找插入位置時使用二分查找的方式
// 改進版插入排序
func InsertionSort2(arr []int){
n := len(arr)
for i:=1; i<n; i++{ // 無序區
tmp := arr[i]
left, right := 0, i-1
for left<=right{
mid := (left+right)/2
if arr[mid] > tmp{
right = mid-1
}else{
left = mid+1
}
}
j:=i-1
for ; j>=left; j--{ // 有序區
arr[j+1] = arr[j]
}
arr[left] = tmp
}
fmt.Println(arr)
}希爾排序
希爾排序又稱遞減增量排序、縮小增量排序,是簡單插入排序的改進版,但是是非穩定算法。
希爾排序是基于插入排序的以下兩點性質而提出改進方法的:
- 插入算法在對幾乎已經排好序的數據操作時,效率高,即可達線性排序效率
- 但插入排序一般來說是低效的,因為每次只能將數據移動一位
希爾排序的基本思想是:先將整個待排序列分割成若干個子序列,對若個子序列分別進行插入排序,待整個待排序列基本有序時,對整體進行插入排序。
算法步驟:
- 選擇一個增量序列t1,t2,…,tk,其中ti>ti+1,tk=1;
- 按增量序列個數k,對序列進行k 趟排序;
- 每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序。僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
其實是兩個兩個換位置,將整個序列變成基本排好序的
 圖片
圖片
// 希爾排序
func ShellSort(arr []int){
n := len(arr)
for gap:=n/2; gap>=1; gap=gap/2{ // 縮小增量序列,希爾建議每次縮小一半
for i:=gap; i<n; i++{ // 子序列
tmp := arr[i]
j:=i-gap
for ; j>=0 && tmp<arr[j]; j=j-gap{
arr[j+gap] = arr[j]
}
arr[j+gap] = tmp
}
}
fmt.Println(arr)
}歸并排序
歸并排序(Merge sort)是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。
作為一種典型的分而治之思想的算法應用,歸并排序的實現由兩種方法:
- 自上而下的遞歸(所有遞歸的方法都可以用迭代重寫,所以就有了第 2 種方法);
- 自下而上的迭代;
遞歸版:
// 歸并排序--遞歸版
func MergeSort(arr []int) []int{
n := len(arr)
if n < 2{
return arr
}
mid := n/2
left := arr[:mid]
right := arr[mid:]
return merge(MergeSort(left), MergeSort(right))
}
func merge(left, right []int) []int{
res := []int{}
for len(left)!=0 && len(right)!=0{
if left[0] <= right[0]{
res = append(res, left[0])
left = left[1:] // 將頭一個直接切出去
}else {
res = append(res, right[0])
right = right[1:]
}
}
if len(left) == 0{ // left結束,right剩下的直接拖下來
res = append(res, right...)
}
if len(right) == 0{ // right結束,left剩下的直接拖下來
res = append(res, left...)
}
return res
}迭代版:
// 歸并排序--迭代版
func MergeSort2(arr []int) []int{
n := len(arr)
min := func(a, b int) int{
if a < b{
return a
}
return b
}
for step:=1; step<=n; step<<=1{ // 外層控制步長
offset := 2*step
for i:=0; i<n; i+=offset{ // 內層控制分組
h2 := min(i+step, n-1) // 第二段頭部,防止超過數組長度
tail2 := min(i+offset-1, n-1) // 第二段尾部
merge2(arr, i, h2, tail2)
}
}
return arr
}
func merge2(arr []int, h1 int, h2 int, tail2 int){
start := h1
tail1 := h2-1 // 第一段尾部
length := tail2-h1+1 // 兩段長度和
tmp := []int{}
for h1 <= tail1 || h2 <= tail2{ // 其中一段未結束
if h1 > tail1 { // 第一段結束,處理第二段
tmp = append(tmp, arr[h2])
h2++
}else if h2 > tail2{ // 第二段結束,處理第一段
tmp = append(tmp, arr[h1])
h1++
}else { // 兩段都未結束
if arr[h1] <= arr[h2]{
tmp = append(tmp, arr[h1])
h1++
}else {
tmp = append(tmp, arr[h2])
h2++
}
}
}
for i:=0; i<length; i++{ // 將排序好兩段合并寫入arr
arr[start+i] = tmp[i]
}
}快速排序
快速排序是東尼-霍爾發展來的一種排序算法。 平均狀態下,排序n個項目要做O(nlogn)次比較,最壞情況下,要做O(n2)次比較,但是比較少見。
事實上,快速排序通常明顯比其他O(nlogn)算法速度要快,因為它的內部循環能夠再大部分框架上很有效地被實現出來。
快速排序使用分治法(Divide and conquer)策略來把一個串行(list)分為兩個子串行(sub-lists)。
為什么快速排序比其他O(nlogn)排序算法快呢?
快速排序的最壞運行情況是 O(n2),比如說順序數列的快排。但它的平攤期望時間是 O(nlogn),且 O(nlogn) 記號中隱含的常數因子很小,比復雜度穩定等于 O(nlogn) 的歸并排序要小很多。所以,對絕大多數順序性較弱的隨機數列而言,快速排序總是優于歸并排序。
算法步驟:
- 選擇一個基準。
- 將比基準小的數放到基準左邊,比基準大的數放到基準右邊(相同的數可以放在任意一邊)在這個分區退出之后,該基準就處于數列的中間位置。這個稱為分區(partition)操作。
- 遞歸地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序。
func QuickSort(arr []int) []int{
return _QuickSort(arr, 0, len(arr)-1)
}
func _QuickSort(arr []int, left int, right int) []int{
if left < right{
partitionIndex := Partition1Way(arr, left, right)
// partitionIndex := Partition2Way(arr, left, right)
_QuickSort(arr, left, partitionIndex-1)
_QuickSort(arr, partitionIndex+1, right)
}
return arr
}單路快排:從左向右遍歷
// 快速排序--單路
func Partition1Way(arr []int, left int, right int) int{
// 先分區,最后把基準換到邊界上
privot := left
index := privot + 1
for i := index; i<=right; i++{
if arr[privot] > arr[i]{ // 當前值小于基準就交換,大于的不用管
arr[index], arr[i] = arr[i], arr[index]
index++ // 交換后的下一個
}
}
// arr[index]是大于基準的
arr[privot], arr[index-1] = arr[index-1], arr[privot]
return index-1
}雙路快排:雙指針從首尾向中間移動
// 快速排序--雙路版
func Partition2Way(arr []int, low int, high int) int{
tmp := arr[low] // 基準
for low < high{
// 當隊尾的元素大于等于基準數據時,向前挪動high指針
for low < high && arr[high] >= tmp{
high--
}
// 如果隊尾元素小于tmp了,需要將其賦值給low
arr[low] = arr[high]
// 當隊首元素小于等于tmp時,向前挪動low指針
for low < high && arr[low] <= tmp{
low++
}
// 當隊首元素大于tmp時,需要將其賦值給high
arr[high] = arr[low]
}
// 跳出循環時low和high相等,此時的low或high就是tmp的正確索引位置
// 由原理部分可以很清楚的知道low位置的值并不是tmp,所以需要將tmp賦值給arr[low]
arr[low] = tmp
return low
}三路排序:分成小于區、等于區、大于區,不對等于區進行遞歸操作
// 快速排序--三路
func QuickSort3Way(arr []int) []int{
// 確定分區位置
return _QuickSort3Way(arr, 0, len(arr)-1)
}
func _QuickSort3Way(arr []int, left int, right int) []int{
if left < right{
lo, gt := Partition3Way(arr, left, right)
_QuickSort3Way(arr, left, lo-1)
_QuickSort3Way(arr, gt, right)
}
return arr
}
func Partition3Way(arr []int, left, right int) (int, int){
key := arr[left]
lo, gt, cur := left, right+1, left+1 // lo和gt是相等區左右邊界
for cur < gt{
if arr[cur] < key{ // 小于key,移到前面
arr[cur], arr[lo+1] = arr[lo+1], arr[cur] // lo+1,保證最后arr[lo]小于key
lo++ // 左邊界右移
cur++ // 能夠確定換完之后該位置值小于key,
}else if arr[cur] > key{
arr[cur], arr[gt-1] = arr[gt-1], arr[cur]
gt-- // 從后面換到前面,不知道是否比key的大,還要再比一下,所以cur不移動
}else {
cur++
}
}
arr[left], arr[lo] = arr[lo], arr[left] // 最后移動基準,arr[lo]一定比key小
return lo, gt
}堆排序
堆排序(Heapsort)是指利用堆這種數據結構所設計的一種排序算法。
堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點。堆排序可以說是一種利用堆的概念來排序的選擇排序。
分為兩種方法:
大頂堆:每個節點的值都大于或等于其子節點的值,在堆排序算法中用于升序排列;
小頂堆:每個節點的值都小于或等于其子節點的值,在堆排序算法中用于降序排列;
堆排序的平均時間復雜度為 Ο(nlogn)。
- 創建一個堆 H[0……n-1]
- 把堆首(最大值)和堆尾互換;
- 把堆的尺寸縮小 1,并調用 shift_down(0),目的是把新的數組頂端數據調整到相應位置;
- 重復步驟 2,直到堆的尺寸為 1。
// 堆排序
func HeapSort(arr []int) []int{
arrLen := len(arr)
BuildMaxHeap(arr, arrLen) // 初始化大頂堆
for i:=arrLen-1; i>=0; i--{
swap(arr, 0, i) // 交換根節點和最后一個節點
arrLen--
heapify(arr, 0, arrLen)
}
return arr
}
func BuildMaxHeap(arr []int, arrLen int){
for i:=arrLen/2; i>=0; i--{
heapify(arr, i, arrLen)
}
}
func heapify(arr []int, i, arrLen int){
left := 2*i+1 // 左子
right := 2*i+2 // 右子
largest := i // 當前最大值位置
if left<arrLen && arr[left]>arr[largest]{
largest = left
}
if right<arrLen && arr[right]>arr[largest]{
largest = right
}
if largest != i{
swap(arr, i, largest) // 交換
heapify(arr, largest, arrLen) // 調整二叉樹
}
}
func swap(arr []int, i, j int) {
arr[i], arr[j] = arr[j], arr[i]
}計數排序
計數排序的核心在于將輸入的數據值轉化為鍵存儲在額外開辟的數組空間中。
作為一種線性時間復雜度的排序,計數排序要求輸入的數據必須是有確定范圍的整數。
計數排序的特征
當輸入的元素是 n 個 0 到 k 之間的整數時,它的運行時間是 Θ(n + k)。計數排序不是比較排序,排序的速度快于任何比較排序算法。
由于用來計數的數組C的長度取決于待排序數組中數據的范圍(等于待排序數組的最大值與最小值的差加上1),這使得計數排序對于數據范圍很大的數組,需要大量時間和內存。
例如:計數排序是用來排序0到100之間的數字的最好的算法,但是它不適合按字母順序排序人名。但是,計數排序可以用在基數排序中的算法來排序數據范圍很大的數組。
通俗地理解,例如有 10 個年齡不同的人,統計出有 8 個人的年齡比 A 小,那 A 的年齡就排在第 9 位,用這個方法可以得到其他每個人的位置,也就排好了序。
當然,年齡有重復時需要特殊處理(保證穩定性),這就是為什么最后要反向填充目標數組,以及將每個數字的統計減去 1 的原因。
算法的步驟如下:
1)找出待排序的數組中最大和最小的元素
2)統計數組中每個值為i的元素出現的次數,存入數組C的第i項
3)對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加)
4)反向填充目標數組:將每個元素i放在新數組的第C(i)項,每放一個元素就將C(i)減去1
// 計數排序
func CountingSort(arr []int) []int{
length := len(arr)
maxValue := getMaxValue(arr)
bucketLen := maxValue+1
bucket := make([]int, bucketLen)
sortedIndex := 0
// 統計每個元素出現的個數
for i:=0; i<length; i++{
bucket[arr[i]] += 1
}
// 按照統計結果寫入arr
for j:=0; j<length; j++{
for bucket[j] > 0{
arr[sortedIndex] = j // bucket[j]的值是統計結果,后面會變化,j是真正值
sortedIndex++
bucket[j]--
}
}
return arr
}
// 獲得數組的最值差
func getMaxValue(arr []int) int{
largest := math.MinInt32
smallest := math.MaxInt32
for i:=0; i<len(arr);i++{
if arr[i] > largest{
largest = arr[i]
}
if arr[i] < smallest{
smallest = arr[i]
}
}
maxValue := largest-smallest
return maxValue
}桶排序
桶排序是計數排序的升級版。它利用了函數的映射關系,高效與否的關鍵就在于這個映射函數的確定。
為了使桶排序更加高效,我們需要做到這兩點:
1 在額外空間充足的情況下,盡量增大桶的數量
2 使用的映射函數能夠將輸入的 N 個數據均勻的分配到 K 個桶中
同時,對于桶中元素的排序,選擇何種比較排序算法對于性能的影響至關重要。
- 什么時候最快
當輸入的數據可以均勻的分配到每一個桶中。
- 什么時候最慢
當輸入的數據被分配到了同一個桶中。
示意圖:
 圖片
圖片
// 桶排序
func BucketSort(arr []int, bucketSize int) []int{
// 獲得arr的最值
length := len(arr)
maxNum, minNum := arr[0], arr[0]
for i:=0; i<length; i++{
if arr[i]>maxNum{
maxNum = arr[i]
}else if arr[i]<minNum{
minNum = arr[i]
}
}
maxValue := maxNum - minNum
// 初始化桶
bucketNum := maxValue/bucketSize + 1 // 桶個數
buckets := make([][]int, bucketNum)
for i:=0; i<bucketNum; i++{
buckets[i] = make([]int, 0)
}
// 利用映射將元素分配到每個桶中
for i:=0; i<len(arr); i++{
id := (arr[i]-minNum)/bucketSize // 桶ID
buckets[id] = append(buckets[id], arr[i])
}
// 對每個桶進行排序,然后按順序將桶中數據放入arr
arrIndex := 0
for i:=0; i<bucketNum; i++{
if len(buckets[i]) == 0{ // 空桶
continue
}
InsertionSort2(buckets[i]) // 桶內排序
for j:=0; j<len(buckets[i]); j++{ // 將每個桶的排序結果寫入arr
arr[arrIndex] = buckets[i][j]
arrIndex++
}
}
return arr
}基數排序
基數排序是一種非比較型整數排序算法,其原理是將整數按位數切割成不同的數字,然后按每個位數分別比較。
由于整數也可以表達字符串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用于整數。
基數排序 vs 計數排序 vs 桶排序
這三種排序算法都利用了桶的概念,但對桶的使用方法上有明顯差異:
基數排序:根據鍵值的每位數字來分配桶;
計數排序:每個桶只存儲單一鍵值;
桶排序:每個桶存儲一定范圍的數值;
思路
基數排序是按照低位先排序,然后收集;
再按照高位排序,然后再收集;
依次類推,直到最高位。
有時候有些屬性是有優先級順序的,先按低優先級排序,再按高優先級排序。
最后的次序就是高優先級高的在前,高優先級相同的低優先級高的在前。
 圖片
圖片
// 基數排序
func RadixSort(arr []int, ) []int{
maxn := maxBitNum(arr) // arr最大位數
dev := 1 // 除數,保證商最后一位是我們想要的
mod := 10 // 模,取商的最后一位
for i:=0; i<maxn; i++{ // 進行maxn次排序
bucket := make([][]int, 10) // 定義10個空桶
result := make([]int, 0) // 存儲中間結果
for _, v := range arr{
n := v / dev % mod // 取出對應位的值,放入對應桶中
bucket[n] = append(bucket[n], v)
}
dev *= 10
// 按順序存入中間數組
for j:=0; j<10; j++{
result = append(result, bucket[j]...)
}
// 轉存到原數組(結果)
for k := range arr{
arr[k] = result[k]
}
}
return arr
}
// 獲取數組的最大位數
func maxBitNum(arr []int) int{
ret := 1
count := 10
for i:=0; i<len(arr); i++{
for arr[i]>count{ // 對arr變化會修改內存里的值
count *= 10 // 所以這里對count進行放大
ret++
}
}
return ret
}總結
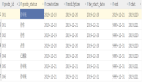
按時間復雜度分類:
- O(n2):冒泡排序、選擇排序、插入排序
- O(nlogn):希爾排序、歸并排序、快速排序、堆排序
- O(n):計數排序、桶排序、基數排序
按穩定性分類
- 穩定:冒泡排序、插入排序、歸并排序、計數排序、桶排序、基數排序
- 不穩定:選擇排序、希爾排序、快速排序、堆排序
按排序方式
- In-Place:冒泡排序、選擇排序、插入排序、希爾排序、快速排序、堆排序
- Out-Place:歸并排序、計數排序、桶排序、基數排序