













GPT-4o版「Her」終于來了!講笑話、學貓叫,AI女友能有多撩人?
奧特曼的承諾,終于兌現了。
趕在7月結束前,GPT-4o語音模式終于開啟了灰度測試,一小部分ChatGPT Plus用戶已經拿到了嘗鮮入場券。
 圖片
圖片
如果打開ChatGPT App之后看到了下面這個界面,恭喜你成為了首批幸運兒。
 圖片
圖片
OpenAI稱,高級語音模式提供了更加自然、實時對話,可以隨意打斷,甚至它還可以感知、回應你的情緒。
預計在今年秋季,所有ChatGPT Plus用戶,都能用上這個功能。
 圖片
圖片
另外,視頻和屏幕共享更強大的也在稍后推出。也就是,開啟攝像頭,就能和ChatGPT「面對面」聊天了。
 圖片
圖片
一些被灰度到的網友們紛紛開啟測試,發現了GPT-4o語音模式的諸多用例。
 圖片
圖片
這不,有人就讓它充當「二外教練」,教自己練習口語。
 圖片
圖片
ChatGPT在下面的教學中,幫助網友糾正了Croissant(羊角面包)、Baguette(法式長棍)的發音。
與此同時,GPT-4o的輸出token暴漲了16倍,從最初4000個token增加到64000個token。
這是OpenAI最近在官方網頁中,悄然推出的測試版新模型gpt-4o-64k-output-alpha。
 圖片
圖片
更長的輸出token,就意味著,一次性可以得到大約4個完整的長篇電影劇本。
 圖片
圖片
Her已來
之所以現在才放出GPT-4o語音功能,是因為過去幾個月里,OpenAI一直對其進行安全性、質量測試。
他們與100+紅隊人員,就45種語言對GPT-4o語音能力進行了測試。
 圖片
圖片
為保護人們的隱私,團隊訓練模型只使用4種「預設聲音」說話。
他們還創建了一個系統,去阻止在這4種聲音之外,其他聲音的輸出。
此外,內容過濾也是必不可少,團隊還采取措施阻止暴力、有關版權內容的生成。
OpenAI預告,計劃在8月初,會發布一份關于GPT-4o能力、局限性、安全評估的詳細報告。
 圖片
圖片
全網實測
下面是網友分享的GPT-4o語音模式的一些案例。
ChatGPT可以表演節奏口技。
 圖片
圖片
ChatGPT還可以以害羞、生氣、更憤怒的語氣講出了關于啤酒的笑話。
還有網友專為ChatGPT講了一個笑話「為什么科學家不相信Adam-Atom,因為它們構成了一切」。
ChatGPT不失尷尬地笑了起來。
更搞笑的是,ChatGPT學起貓叫還是有一套的。
有人經過一番測試下來,發現ChatGPT高級語音模式非常快,回答幾乎沒有延遲。
當被要求模仿一些聲音時,它總是可以真實復刻出聲音。而且不同口音,也可以模仿出來。
 圖片
圖片
下面這個視頻中,展示了AI充當足球比賽解說員的場景。

ChatGPT用中文講故事,也很生動。

OpenAI雖然聲稱,視頻和屏幕共享功能稍后推出,不過已經有網友先用上了。
 圖片
圖片
網友有一只貓咪新寵,為它搭建了小窩,準備了吃食,但不知道怎么樣,于是就問問ChatGPT。
在視頻的對話中,網友向它展示了貓咪的屋子,ChatGPT看過后評價道,「一定非常舒適」,并關心貓咪如何。
網友表示,它目前為止還沒有吃東西,看起來有點擔心。ChatGPT安慰道,「這很正常,對于貓咪來說需要適應的時間」。
可以看出,整個問答過程非常流暢,給人一種與真人交流的感受。
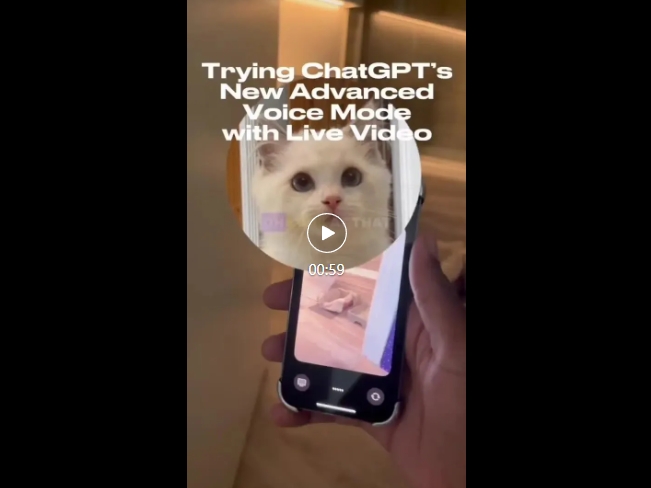
網友還翻出了日語版界面游戲機,但是自己又不會日語。
這時,他一邊向ChatGPT展示游戲界面,一邊讓其幫自己做翻譯,最后胡一起通關游戲。
不得不說,有了視覺+語音模式的加持,ChatGPT強了很多。

GPT-4o Long Output悄悄上線,輸出高達64K
另外,支持更大token輸出的GPT-4o隨之而來。
就在昨天,OpenAI正式宣布向提供測試者GPT-4o Alpha版本,每次請求支持最多輸出64K token,相當于200頁小說。
測試者可以從「gpt-4o-64k-output-alpha」,訪問GPT-4o的長輸出功能。
不過,新模型的價格再次刷新天花板。每百萬輸入token 6美元,每百萬輸出token 18美元。
雖說輸出token是GPT-4o的16倍,但價格也漲了3美元。
 圖片
圖片
這么一比,果然還是gpt-4o-mini價格香!
 圖片
圖片
研究員Simon Willison表示,長輸出主要用于數據轉換用例。
比如,將文檔從一種語言翻譯成另一種語言,或從文檔中提取結構化數據,幾乎每個輸入token都需要在輸出的JSON中使用。
在此之前,他所知道的最長輸出模型是GPT-4o mini,為16K token。
 圖片
圖片
為什么推出更長輸出的模型?
顯然,更長的輸出,可以讓GPT-4o提供更全面、細致的響應,對于一些場景非常有幫助。
比如,編寫代碼、以及對寫作的改進。
這也是基于用戶的反饋——需要更長輸出內容才能滿足用例,OpenAI才做出的調整。
上下文和輸出之間的區別
GPT-4o自推出以來,便提供了最大128K的上下文窗口。而對于GPT-4o Long Output,最大上下文窗口仍然是128K。
那么,OpenAI如何在保持整體上下文窗口為128K的情況下,將輸出token數量從4,000增加到64,000呢?
這是因為,OpenAI在最初就限制了輸出token數量,最大為4000個token。
這意味著,用戶可以在一次交互中最多以124,000個token作為輸入,也最多只能得到4000個輸出token。
當然,你也可以輸入更多token,那就意味著輸出token更少了。
畢竟長下文長度(128K)就固定在那里,不管輸入怎么變,輸出token也不會過4000。
而現在,OpenAI將輸出token長度限制在64,000 token,也就是說,你可以比以往多輸出16倍的token。
畢竟,輸出計算量更大,價格漲幅也更大。
同樣,對于最新的GPT-4o mini,上下文也是128K,但最大輸出已提升至16,000個token。
那么,用戶可以提供最多112,000個token作為輸入,最終得到最多16,000個token的輸出。
總的來說,OpenAI在這里提供了一個方案,限制輸入token,以獲取LLM更長的響應,而不是直接擴大上下文長度。
而市面上其他模型,長的都已經超過百萬了(Gemini),稍微短一些的也有200K(Claude);甚至有的模型輸出都已經達到了200K,而OpenAI還在這兒摳摳搜搜。
這也就把難題扔給了開發者:想要輸入多,那就得接受輸出少;想要輸出多,那就得輸入少一些。
具體怎么衡量,看你們自己愿意犧牲哪一個了......
參考資料:
https://x.com/OpenAI/status/1818353580279316863
https://x.com/tsarnick/status/1818402307115241608
https://x.com/kimmonismus/status/1818409637030293641
https://www.reddit.com/r/singularity/comments/1eg51gz/chatgpt_advanced_audio_helping_me_pronouce/






























