還沒排上SearchGPT?比Perplexity更好用的國產開源平替了解一下?
有 AI 在的科技圈,似乎沒有中場休息。除了大模型發布不斷,各家科技大廠也在尋找著第一個「殺手級」AI 應用的落腳之地。
OpenAI 首先瞄準的是谷歌 1750 億美元的搜索業務市場。7 月 25 日,OpenAI 帶著 AI 搜索引擎——SearchGPT 高調入場。在演示 demo 中,搜索引擎的使用體驗不再像以往一樣,需要我們逐個點開網頁鏈接,判斷信息有沒有用。SearchGPT 像端上了一桌精美的套餐,所有答案都幫你總結好了。

在演示 demo 中,SearchGPT 分析了在應季最適合種植哪種品種的番茄。
不過,鑒于年初發布的 Sora 到目前都還未正式開放,估計很多人排上 SearchGPT 的體驗名額也遙遙無期。
然而,有一款國產的開源平替,在和能聯網的 ChatGPT 和專攻 AI 搜索引擎的 Perplexity.ai 的 PK 中,它的回答在深度、廣度和準確度方面都都秒了這兩款明星產品。
它甚至可以在不到 3 分鐘內收集并整合 300 多頁相關信息。這換成人類專家,需要大約 3 小時才能做完。

這款「國貨」就是多智能體框架 MindSearch(思?索),由來自中科大和上海人工智能實驗室的研究團隊聯合研發。正如其名,MindSearch 是一個會「思索」的系統,面對你輸入的問題,它將先調用負責充分「思」考問題的智能體,再啟用全面搜「索」的智能體,這些智能體分工合作,理解你的需求,并為你呈上從互聯網的五湖四海搜羅來的新鮮信息。

- 論文鏈接:https://arxiv.org/abs/2407.20183
- 項目主頁:https://mindsearch.netlify.app/

MindSearch 演示 demo
那么,MindSearch 是憑什么打敗 ChatGPT 和 Perplexity.ai 的呢?和別的 AI 搜索引擎相比,MindSearch 有什么獨到之處嗎?
答案還得從它的名字說起。MindSearch 的核心競爭力在于采用了多智能體框架模擬人的思維過程。
如果向 Perplexity.ai 提問「王者榮耀當前賽季哪個射手最強?」它會直接搜索這個問題,并總結網上已有的回復。把這個問題交給 MindSearch,它會把這個問題拆解成一個邏輯鏈:「當前賽季是哪個賽季?」,「從哪些指標可以衡量王者榮耀的射手的強度?」,再匯總所能查詢到的答案。

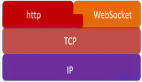
技術實現
WebPlanner:基于圖結構進行規劃
僅依靠向大型語言模型輸入提示詞的方式并不能勝任智能搜索引擎。首先,LLM 不能充分理解復雜問題中的拓撲關系,比如前一段掛在熱搜上的大模型無法理解 9.9 和 9.11 誰大的問題,就是這個問題的生動注腳。字與字之間的關系,LLM 都很難在簡單對話中理解,那么「這個季節種哪個品種的番茄最合適?」這種需要深入思考,分解成多個角度來回答的問題,對于 LLM 就更難了。換句話說,LLM 很難將用戶的意圖逐步轉化為搜索任務,并提供準確的響應,因此它總是提供一些模版式的知識和套話。
基于此,研究團隊設計了高級規劃器 WebPlanner,它通過構建有向無環圖(DAG)來捕捉從提問到解答之間的最優執行路徑。對于用戶提出的每個問題 Q,WebPlanner 將其解決方案的軌跡表示為 G (Q) = ?V, E?。在這個圖中,V 代表節點的集合,每個節點 v 代表一個獨立的網頁搜索任務,包括一個輔助的起始節點(代表初始問題)和一個結束節點(代表最終答案)。E 代表有向邊,指示節點之間的邏輯和推理關系。
研究團隊進一步利用 LLM 優越的代碼能力,引導模型編寫代碼與 DAG 圖交互。為了實現這一點,研究團隊預定義了原子代碼函數,讓模型可以在圖中添加節點或邊。在解答用戶問題的過程中,LLM 先閱讀整個對話,還有它在網上搜索到的信息。閱讀完這些信息后,LLM 會根據這些信息產生一些思考和新的代碼,這些代碼將通過 Python 解釋器添加在用于推理的圖結構中。
一旦有新節點加入圖中,WebPlanner 將啟動 WebSearcher 來執行搜索任務,并整理搜索到的信息。由于新節點只依賴于之前步驟中生成的節點,所以這些節點可以并行處理,大大提高了信息收集的速度。當所有的信息收集完畢,WebPlanner 將添加結束節點,輸出最終答案。

WebSearcher:分層檢索網頁
由于互聯網上的信息實在太多,就算是 LLM 也不能一下子處理完所有的頁面。針對這個問題,研究團隊選擇了先廣泛搜索再精確選擇的策略,設計了一個 RAG 智能體 ——WebSearcher。
首先,LLM 將根據 WebPlanner 分配的問題,生成幾個類似的搜索問題,擴大搜索的范圍。接下來,系統將調用不同搜索引擎的 API 查詢問題,例如分別在 Google、Bing 和 DuckDuckGo 查一下,得到網頁的鏈接、標題和摘要等關鍵信息。接著,LLM 將從這些搜索結果中選出最重要的網頁來仔細閱讀,匯總得出最終答案。

MindSearch 中,LLM 如何管理上下文
作為一個多智能體框架,MindSearch 為如何管理長上下文提供了全新嘗試。當需要快速閱讀大量網頁時,由于最終答案只依賴 WebSearcher 的搜索結果,WebPlanner 將專注于分析用戶提出的問題,不會被過長的網頁信息分心。
這種明確的分工也大大減少了上下文計算量。如何在多個智能體之間高效共享信息和上下文并非易事,研究團隊在實證中發現,如果只依靠 WebPlanner 的分析,有可能會在信息收集階段由于 WebSearcher 內部的局部感知場丟失有用的信息。為了解決這個問題,他們利用有向圖邊構建的拓撲關系來簡化上下文如何在不同智能體間傳遞。
具體來說,在 WebSearcher 執行搜索任務時,它的父節點以及根節點的回答將作為前綴添加在其回答中。因此,每個 WebSearcher 可以有效地專注于其子任務,同時不會丟失之前的相關上下文或者忘記最終的查詢目標。
本地部署
7 月初,上海人工智能實驗室已經開源了搭載 MindSearch 架構的 InternLM2.5-7B-Chat 模型。
除了直接點擊鏈接,跳轉到體驗 Demo 試玩。研究團隊還公開了 MindSearch 的完整前后端實現,基于智能體框架 Lagent,感興趣的朋友可以在本地部署模型。
- 在線 Demo:https://mindsearch.openxlab.org.cn/
- 開源代碼:https://github.com/InternLM/mindsearch
在 GitHub 下載 MindSearch 倉庫后,輸入如下命令就可以打造屬于自己的 MindSearch 了:
# 啟動服務
python -m mindsearch.app --lang en --model_format internlm_server
## 一鍵啟動多種前端
# Install Node.js and npm
# for Ubuntu
sudo apt install nodejs npm
# for windows
# download from https://nodejs.org/zh-cn/download/prebuilt-installer
# Install dependencies
cd frontend/React
npm install
npm start