多場景多任務統一建模在網易云音樂的算法實踐

一、背景介紹
多場景建模是一項與業務緊密結合的算法優化工作,其核心在于思考如何處理多個業務場景之間的差異性和共性。
1. 云音樂推薦場景介紹
云音樂的核心場景包括每日推薦,每天更新 30 首歌曲,以列表形式呈現;還有流式推薦、實時更新,和每日推薦一樣都是直接為用戶推薦歌曲;此外還有歌單推薦,包括首頁推薦歌單以及 MGC 歌單。

2. 主推薦場景差異化
這些場景特點各異,旨在滿足用戶不同的個性化推薦需求。可以看到,在過去一段時間,這些場景一直由專人專項持續優化。這樣做的優點是能使模型更貼合業務場景和特點,充分發揮模型效果,提升場景忠實用戶的體驗。
這種做法也存在弊端。其一,長期專人專項優化可能導致技術棧出現較大差異;其二,技術共享和共建節奏會被拖慢。

3. 新增場景愈多
我們面臨的挑戰不僅是要承接越來越多新的場景,滿足更多用戶個性化音樂訴求并帶來增量,同時還要思考如何更好地承接和持續優化這些新場景。

4. 建模目標
開展多場景工作的目標主要有兩個:一是用一個模型服務所有推薦場景,取得更好的效果,聯合建模用戶在任意場景消費后產生的數據,精準建模用戶真正感興趣的底層興趣表征;二是用一個模型服務所有場景,有效降低機器成本和人力成本,提升研發效率,促進技術共建達到更高水平。

5. 建模難點
第一個難點是雙蹺蹺板問題,由多任務蹺蹺板和多場景蹺蹺板構成,兩者耦合時平衡難度加大。另一個難點,可用西方故事“格力婭如何戰勝大衛”來描述,即如何用一個通用的大模型打敗每個場景專有的小模型,其中難點眾多,將在后續介紹中詳細闡述。

二、整體框架
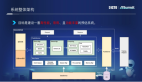
1. 系統框架
此次雖主要談及算法層面的多場景建模,但更重要的是,在算法層面之外,我們對從數據層到場景層再到頂層任務的整個系統框架進行了統一構建,摒棄了原先零散、不統一、不規范的技術及相應數據等,在此基礎上構建了統一的模型架構。

2. 模型架構
此架構與業界現有的多場景建模整體架構差異不大,但其中融入了音樂場景特有的業務特點以及我們的思考。例如,針對音樂推薦中老歌持續被消費這一強業務特點,我們做了很多長期多興趣的表征,并與即時性交叉且進行動態更新。同時,我們希望將業務背后沉淀的音樂、公寓知識傳遞到更頂層,服務于水面之上的多個業務場景。

3. 整體概述
整體架構可以概述為三個關鍵詞:自底向上、求同存異和去偽存真。求同存異是此次分享中最想強調的點,因為多場景工作更多是如何以最小代價固化沉淀真正有價值的共性部分,同時以快速敏捷的方式保留差異部分,兩者有機結合才能完成多場景統一大模型的建設。

三、關鍵模塊
1. 統一模型建模
在參考了業界眾多已有的多場景建模工作后,我們完成了整體架構的設計。對重要區域進行了分色塊標記,方便理解。例如,底層有藍色和黃色色塊,總體遵循公私域分離設計結構。在公域部分,抽取多個場景共享的特征和表達,黃色部分則更多是場景特有的東西。可以看到圖中有多個紫塔并聯,每個紫塔代表一個場景特有的知識。在其之上是常見的 MMOE 架構,用于多個場景不同目標的多任務學習輔助。

2. 公域網絡設計
公域更多表達的是業務場景共有的特性、用戶公共的興趣或其長短期興趣中不變的部分。那么求同如何實現?這更多考驗算法工程師面對零散業務特性和不同邏輯時,如何提取公約數。這里分享四個要點:一是通用的輸入結構;二是特征的最大公約數;三是共享共建;四是輕量高效。共享共建和輕量高效可能基于團隊文化,強制要求做到更好以服務大模型。在算法層面,更強調保留公共核心特征。這里也列舉了一些核心點,比如通過消融實驗找出并保留必要核心特征,能砍則砍,盡量減輕構建大模型前的負擔。

3. 多場景效果分析
基于此思考,我們進行了多次迭代,并及時基于 AB 測試分析以驗證公域架構設計的有效性。將用戶按活躍等級分為 0 - 10 級共 11 個檔次,0 級用戶最不活躍,10 級最活躍。從圖中可以看出,橫軸是各人群對應的提升幅度,0 - 3 級提升幅度明顯最大。此數據旨在論證,通過良好的公域結構設計,能有效表達并沉淀用戶特征,使低活用戶受益更多。

4. 私域網絡設計
公域工作相對基礎,而私域則較為復雜。私域的核心點在于保留每個場景最特殊、最有價值的部分特征,強調參數隔離、梯度隔離,每個塔相互不干擾,輸入特征完全不同。這些特征來源于每個場景特有的特性挖掘,例如某業務場景的封面特征或流式場景基于用戶實時反饋產生的信號等。

5. 場景私有網絡 SEN
為應對私有場景差異大的問題,設計了 SEN 場景私有網絡這一通用邏輯,便于接入新場景和合并老場景時提高復用率和整體迭代效率。求同存異中的求同主要是針對公域網絡設計,而存異則是針對私域網絡設計,主要體現在:一是私有場景的私有特征是不對齊的;二是某些私有特征很重要但易過擬合;三是存在分布漂移問題。我們參考了 Transformer 類的一些設計,進行組合,來解決這些問題。

6. 跨域多任務模型
接著是雙蹺蹺板問題中的多任務蹺蹺板,下圖中列舉了幾個核心場景及其面臨的任務。

基于場景特有任務,我們設計了 task master 邏輯。對于有任務的場景保留梯度,對于無任務的場景通過 subgradient 方式停止梯度,避免影響對應 SEN 網絡的學習。這保證了多場景、多梯度之間,場景與場景、任務與任務以及場景對應特有任務之間盡可能隔離。

7. 模型輕量化設計
在音樂推薦場景中,用戶行為序列特別是長期行為序列非常重要,引入 LSTM 加 session 切分提取用戶長期興趣特征曾帶來顯著提升,但此特征和對應的網絡結構對模型消耗大。在迭代多場景、多任務統一大模型時,我們找到了一個相對更輕量化的方式,即層次 attention 網絡。

從數據對比來看,雖然層次 attention 在某個核心指標上有輕微負向,但從全局來看是一種權衡,犧牲局部小收益換取未來全局更大的收益,提升了整體的迭代效率。

四、應用效果
模型上線后效果顯著,核心推薦場景紅心率提升 10% 以上,眾多小場景核心指標提升 15% 以上,直接帶動次留相對提升 1%。模型還落地到網易集團其他業務,新客絕對值提升 0.2%,次留絕對值提升 0.2%。同時,模型上線后替換了原有的零散和不統一的技術棧,整體效率也有所提升,并節省了資源消耗。

五、展望
在現有整體模型統一的基礎上,我們希望將模型進一步復雜化,服務于網易云音樂更多業務線,不僅限于音樂推薦,還包括播客、直播等,以各種合作的形式發揮模型最大效果。

六、問答環節
Q1:新模型可以加入新的域和任務嗎?
A1:可以,場景的私域網絡 SEN 中,一個網絡對應一個場景,新增場景只需在私有網絡增加對應的塔,較為靈活。
Q2:里面迭代 5 次是指一周推選 5 次嗎?
A2:并非如此,是指離線完整訓練模型嘗試新方向,離線訓練效率提升使得迭代速度加快。
Q3:統一模型較大,多人在模型上迭代是否會有沖突或效率降低?
A3:目前的做法是預先區分好迭代方向,不同同學負責重疊度最低的方向,且因同學負責業務不同,重疊性進一步降低。雖干擾減少,但也存在問題,如因他人工作提升加入新點,個人收益可能不如單獨 AB 時多。此時強調增量 AB,大量 DIFF 比較。這是當前實踐,仍在思考提升合作效率的方法。
Q4:拆分私域特征的必要性如何看待?
A4:私域特征復用度低,多為場景特有且重要,建議不混用到公域側,實踐中混用效果不理想。
Q5:多場景樣本是否復用?
A5:是的,所有場景樣本合在一起訓練,若不優化離線訓練效率,訓練耗時會大幅增加。
Q6:層次 attention 是將長短序融合再和短序融合嗎?
A6:是的,先對長序做 attention,再和短序做 attention。
Q7:公域特征為何對不活躍用戶提升大?
A7:音樂場景眾多,但用戶通常只用一兩個功能,多場景建模能覆蓋全推薦域樣本,改變用戶底層表達,對類似用戶冷啟更好,不再只適配單點場景特性。
Q8:新場景私域增量,私域訓練后公域那塊的場景綜合所有的,如果新場景上來是直接全量訓練還是增量訓練?
A8:新場景上來直接全量訓練,因補充新樣本存在差異性,直接增量訓練可能不穩定。
Q9:全量樣本更新是全冷啟還是熱啟?
A9:做全量更新。
Q10:上了一個私域塔,公域塔上層模型都得微調,如何影響對其他任務的評估?
A10:上了新私域塔通常直接做 AB,當前推薦域用一個實驗評估,新增私域塔未觀測到對其他場景的負向影響,因新增多為小場景,核心場景通常非新增量帶來。
Q11:對于私域特征混用不好的效果如何看待?
A11:因差異性大,如同豬飼料給牛吃會生病。
Q12:不同場景正負樣本的定義是否有差異?
A12:有差異,樣本分布差異大,做實驗時觀測到部分場景樣本量大會對其他場景產生負向影響,通過離線多次采樣迭代找出較好混合比例以表征全場景用戶。
Q13:不同場景量級差異大嗎?
A13:較大,做采樣會有信息丟失,但會保留能共同建模且對整體有收益的部分。
Q14:Loss 上有什么考慮?
A14:多任務層因 task master 設計影響較小,多場景層通過獨立每個場景的子塔設計保證樣本隔離。
Q15:對于 list、wise、pointwise 這些不同樣本的 loss 設計,這種框架怎么設計?
A15:目前主要是 pointwise 框架,listwise 邏輯更傾向于在 pointwise 基礎上做二次偏序校正,用于多任務層的偏序表達。
Q16:跨場景建模后,各場景的推薦會趨同嗎?
A16:目前未出現此現象,底層召回有差異,且不同場景激活的子塔參數分布差異大。
Q17:不同場景的樣本反饋延遲會不同嗎?
A17:會,實時場景較快,日更場景較慢,統一做統一時間的批量處理。
Q18:上層和輸出塔有分場景設計的必要嗎?
A18:視業務而定,若業務中某場景某任務非常重要且對其他場景影響可控,可單獨設計輸出塔,目前無統一方法論。
Q19:有歌曲和視頻,能做多長期建模嗎?
A19:目前主要在歌曲域做多場景建模,歌曲和視頻差異大,跨域建模方案更復雜。
Q20:長層次 attention 只是處理短序列嗎?
A20:不是,長短序列一起處理,短序列可視為 target,長序列視為序列。
Q21:提到統一實驗,如果兩個體量相當的私域一個漲一個跌,如何評估?
A21:先看總量,再看私域場景漲跌情況,總量最重要。
Q22:Task mask 如何解決場景和任務之間的耦合?
A22:A 場景有 A 任務,B 場景無 A 任務,構建樣本時混合 A、B 場景樣本,訓練 B 場景時 mask 掉 A 任務的梯度。
Q23:長序列和短序列多長?
A23:長序列有上萬的長期序列和幾百的中長期興趣序列。
Q24:層次 attention 可以再講解一下嗎?
A24:短序列做 target attention 的 target,長序列做序列。
Q25:如果場景量級不同,采樣大場景會丟失信息嗎?如何平衡?
A25:會丟失部分信息,取決于丟失部分對整體的影響,保留能共同建模且有益的部分。
Q26:上層網絡的分場景設計的思路
A26:受前輩 star 工作影響,設計理念相同,分公域和私域專家,私域為場景私有網絡 SEN,每個場景有獨有網絡,公域設計基于用戶層面的共同興趣表達,而非場景層面。
Q27:關于任務在不同場景中轉化率分布不同,用同一輸出塔可能導致問題,是否有必要為每個場景的任務分別拆出輸出。
A27:通過私域場景獨立塔保持信息偏置,保證小場景 COPC 穩定,且梯度隔離可保證 COPC 準確,公域梯度回傳基于用戶公共興趣不受場景轉化率影響。