













同時操控手機和電腦,100項任務,跨系統智能體評測基準有了
跨平臺的多模態智能體基準測試 CRAB 由 CAMEL AI 社區主導,由來自牛津、斯坦福、哈佛、KAUST、Eigent AI 等機構的研究人員合作開發。CAMEL AI 社區開發的 CAMEL 框架是最早基于大語言模型的多智能體開源項目,因此社區成員多為在智能體領域有豐富科研和實踐經驗的研究者和工程師。
AI 智能體(Agent)是當下大型語言模型社區中最為吸引人的研究方向之一,用戶只需要提出自己的需求,智能體框架便可以調度多個 LLMs 并支持多智能體(Multi-agents)以協作或競爭的方式來完成用戶給定的任務。
目前智能體已越來越多地與大型多模態模型 (MLM) 相結合,支持在各種操作系統( 包括網頁、桌面電腦和智能手機) 的圖形用戶界面( GUI) 環境中執行任務。但是目前針對這種智能體性能評估的基準(benchmarks)仍然存在很多局限性,例如構建任務和測試環境的復雜性,評價指標的單一性等。
針對這些問題,本文提出了一個全新的跨環境智能體基準測試框架 CRAB。CRAB 采用了一種基于圖的細粒度評估方法,并提供了高效的任務和評估器構建工具。本文的研究團隊還基于 CRAB 框架開發了一個跨平臺的測試數據集 CRAB Benchmark-v0,其中涵蓋了可以在 PC 和智能手機環境中執行的 100 個任務,其中既包含傳統的單平臺任務,還包含了必須同時操作多個設備才能完成的復雜跨平臺任務。

- 論文題目:CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents
- 論文地址:https://arxiv.org/abs/2407.01511
- 代碼倉庫:https://github.com/camel-ai/crab
作者選取了當前較為流行的四個多模態模型進行了初步實驗,實驗結果表明,使用 GPT-4o 作為推理引擎的單智能體結構擁有最高的測試點完成率 35.26%。
引言
作為全新的智能體評估基準框架,CRAB(Cross-environment Agent Benchmark)主要用于評估基于多模態語言模型(MLMs)的智能體在跨環境任務中的表現。CRAB 可以模擬真實世界中人類用戶同時使用多個設備完成復雜任務的場景,如 Demo 所示,CRAB 可以用來評估智能體同時操縱一個 Ubuntu 桌面系統和一個 Android 手機系統完成發送信息的過程。

想象一下,如果智能體具備根據人類指令同時精確操作電腦和手機的能力,很多繁雜的軟件操作就可以由智能體來完成,從而提高整體的工作效率。為了達成這個目標,我們需要為智能體構建更加全面和真實的跨平臺測試環境,特別是需要支持同時操作多個設備并且能提供足夠的評估反饋機制。本文的 CRAB 框架嘗試解決以下幾個實際問題:
- 跨環境任務評估:現有的基準測試通常只關注單一環境(如網頁、Android 或桌面操作系統)[1][2][3][4],而忽視了真實世界中跨設備協作場景的復雜性。CRAB 框架支持將一個設備或應用的交互封裝為一個環境,通過對多環境任務的支持,提供給智能體更豐富的操作空間,也更貼近實際應用場景。
- 細粒度評估方法:傳統的評估方法要么只關注最終目標的完成情況(目標導向),要么嚴格比對操作軌跡(軌跡導向)[1][2][3]。這兩種方法都存在局限性,無法全面反映智能體的表現。CRAB 提出了基于圖的評估方法,既能提供細粒度的評估指標,又能適應多種有效的任務完成路徑。
- 任務構建復雜性:隨著任務復雜度的增加,手動構建任務和評估器變得越來越困難。CRAB 提出了一種基于子任務組合的方法,簡化了跨環境任務的構建過程。
- 智能體系統結構評估:本文還探討了不同智能體系統結構(單智能體、基于功能分工的多智能體、基于環境分工的多智能體)對任務完成效果的影響,為設計更高效的智能體系統提供了實證依據。

上表展示了本文提出的 CRAB 框架與現有其他智能體基準框架的對比,相比其他基準,CRAB 可以同時支持電腦和手機等跨平臺的操作環境,可以模擬更加真實的使用場景。
對于 CRAB,一眾網友給出了很高的評價。
有人表示,AGI 已經達成,因為有大語言模型(指 CRAB)已經學會了如何退出 Vim。

"Can you exit Vim?" 這個問題常常是一個編程或技術社區的玩笑,因為 Vim 對新手來說可能很難退出,尤其是當他們不熟悉 Vim 的操作模式時。(在此貢獻一張表情包)

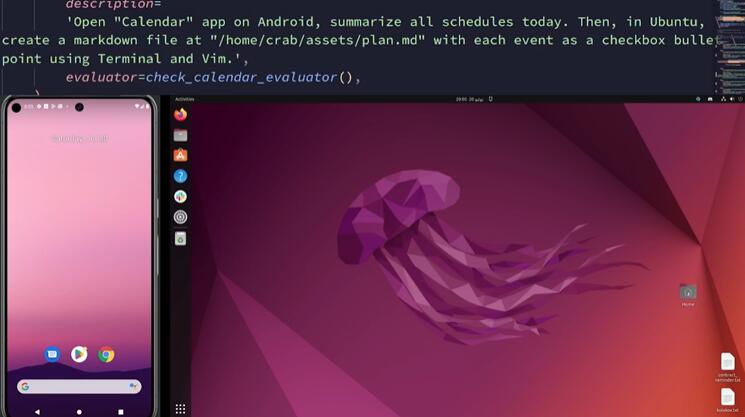
有人說很難相信一個智能體可以完成 “查看日歷,打開 Vim,進入插入模式,輸入事件列表,退出插入模式,并使用 :wq 保存” 這一系列任務。
也有網友總結說下個下一代機器人流程自動化(RPA)將更像是 “請幫我完成下列任務”,而不需要記錄每一個步驟,然后在幾天內運行時崩潰。


也有人提到了 CRAB 中的圖評估器(Graph Evaluator)用于處理智能體在環境中的狀態是一種非常智能的方式。

甚至有人夸贊道 CRAB 是 AI PC 的未來,認為這是 LLM 與 PC 和移動設備的完美結合,“它是一種類似 RabbitOS 的 AI,使現有的 PC 和移動設備具備 AI 功能。CRAB 的基準測試允許在現實世界中測試多模態語言模型代理的有效性和實用性。”

定義
任務定義
CRAB 框架將數字設備(如桌面電腦或智能手機)表示為一個具體的環境。每個環境被定義為一個無獎勵的部分可觀察馬爾可夫決策過程(POMDP),可以使用元組 表示,其中
表示,其中  為狀態空間,
為狀態空間, 為動作空間,
為動作空間, 是轉移函數,
是轉移函數, 是觀察空間。
是觀察空間。
而對于跨環境任務,可以定義一個環境集合 其中 n 是環境數量,每個環境又可以表示為
其中 n 是環境數量,每個環境又可以表示為 。
。
基于以上,作者將一個具體的跨環境任務表示為元組 ,其中 M 是環境集合,I 是以自然語言指令形式給出的任務目標,R 是任務的獎勵函數。參與任務的智能體系統可以被建模為一個策略
,其中 M 是環境集合,I 是以自然語言指令形式給出的任務目標,R 是任務的獎勵函數。參與任務的智能體系統可以被建模為一個策略  。
。
這表示智能體在接收到來自環境 的觀察
的觀察  和動作歷史 H 時,在環境 m 中采取動作 a 的概率。
和動作歷史 H 時,在環境 m 中采取動作 a 的概率。
圖任務分解(Graph of Decomposed Tasks, GDT)
將復雜任務分解為幾個更簡單的子任務是 LLMs 解決實際問題時非常有效的技巧 [5][6],本文將這一概念引入到了智能體基準測試中,具體來說,本文引入了一種分解任務圖(Graph of Decomposed Tasks,GDT),如下圖所示,它可以將一個復雜任務表示為一個有向無環圖(DAG)的結構。

GDT 中的每個節點可以代表一個子任務 (m,i,r),其中 m 為子任務執行的環境,i 為自然語言指令,r 是獎勵函數,用于評估環境 m 的狀態并輸出布爾值,判斷子任務是否完成。GDT 中的邊表示子任務之間的順序關系。
CRAB 框架
跨環境智能體交互
CRAB 首次引入了跨環境任務的概念,將多個環境(如智能手機和桌面電腦)組合成一個環境集合,使智能體能夠在多個設備之間協調操作完成復雜任務。

在 CRAB 框架中使用基于環境分工的多智能體系統的運行流程如上圖所示。工作流程通過一個循環進行,首先通過主智能體觀察環境,并對子智能體指定計劃,然后所有的子智能體在各自的環境中執行操作。隨后由一個圖評估器(Graph Evaluator)來監視環境中各個子任務的狀態,并在整個工作流程中不斷更新任務的完成情況。這種評估方式可以貼近真實場景,以考驗智能體的推理能力,這要求智能體能夠處理復雜的消息傳遞,并且需要深入理解現實世界的情況。
圖評估器(Graph Evaluator)
CRAB 內置的圖評估器同時兼顧了目標導向和軌跡導向評估的優點,其首先將復雜任務分解為多個子任務,形成一個有向無環圖結構。隨后定義了一種節點激活機制,即圖中的節點(子任務)需要根據前置任務的完成情況逐步激活,確保任務的順序執行。其中每個節點都關聯了一個驗證函數,用來檢查環境中的關鍵中間狀態。相比之前的評估基準,CRAB 圖評估器創新性地引入了一系列新的評價指標:
- 完成率(Completion Ratio, CR):完成的子任務節點數量與總節點數量的比率,CR = C / N。
- 執行效率(Execution Efficiency, EE):完成率與執行的動作數量的比值,EE = CR / A,A 為指定的動作數。
- 成本效率(Cost Efficiency, CE):完成率與使用的模型 token 數量的比值,CE = CR / T,T 為使用的模型 token 數量。
這些指標為智能體基準提供了更細粒度和更多維度的評估側重點。
CRAB Benchmark-v0
基準構建細節
基于提出的 CRAB 框架,本文構建了一個具體的基準測試集 CRAB Benchmark-v0 用于社區進一步開展研究。CRAB Benchmark-v0 同時支持 Android 手機和 Ubuntu Linux 桌面電腦兩個環境。并且為 Ubuntu 和 Android 定義了不同的動作集,用來模擬真實生活中的常見交互。其觀察空間由兩種環境的系統界面構成,并且使用屏幕截圖形式獲取環境狀態。為了方便智能體在 GUI 中操作,作者使用 GroundingDINO [7] 來定位可交互圖標,使用 EasyOCR 檢測和標注可交互文本,為每個檢測項分配一個 ID,方便后續在操作空間內引用。
我們以一個具體任務舉例,例如在 Ubuntu 系統上完成如下任務:創建一個新目錄 “/home/crab/assets_copy”,并將所有具有指定 “txt” 擴展名的文件從 “/home/crab/assets” 復制到目錄 “/home/crab/assets_copy”。
該任務需要執行多步操作才能完成,下圖展示了當使用 GPT-4 Turbo 作為推理模型并采用單智能體結構時的實驗細節。智能體首先使用 search_application 命令查找終端并打開。

然后使用 Linux 命令 “mkdir -p /home/crab/assets_copy” 創建新的目標目錄。

在創建好目標目錄后,智能體直接在終端中執行了拷貝命令 :
“cp /home/crab/assets/*.txt/home/crab/assets_copy” 來完成任務,整個流程行云流水,沒有任何失誤。

實驗效果
作者隨后在 CRAB Benchmark-v0 進行了 baseline 實驗,智能體的核心是后端的多模態語言模型,其用來提供自然語言和圖像理解、基本設備知識、任務規劃和邏輯推理能力,需要支持多模態混合輸入,可以同時處理多輪對話,因而作者選取了 GPT-4o (gpt-4o-2024-05-13)、GPT-4 Turbo (gpt-4-turbo-2024-04-09)、Gemini 1.5 Pro (2024 年 5 月版本) 和 Claude 3 Opus (claude-3-opus-20240229) 作為 baseline 模型。

實驗結果如上表所示,其中 GPT-4o 和 GPT-4 Turbo 模型在測試模型中實現了最高的平均測試點完成率(CR)。在執行效率(EE)和成本效率(CE)方面, GPT-4 系列也相比 Gemini 和 Claude 系列模型更加優秀。

總結
本文介紹了一種全新的跨環境多智能體評估基準 CRAB,CRAB 框架通過引入跨環境任務、圖評估器和基于子任務組合的任務構建方法,為自主智能體的評估提供了一個更加全面、靈活和貼近實際的基準測試平臺。相比先前的智能體基準,CRAB 減少了任務步驟中的手動工作量,大大提高了基準構建效率。基于 CRAB,本文提出了 Crab Benchmark-v0,同時支持智能體在 Ubuntu 和 Android 系統上執行多種復雜的跨環境任務,這一基準的提出,不僅可以推動自主智能體評價體系的發展,也為未來設計更加高效的智能體系統提供全新靈感。























