高性能無鎖隊列 Disruptor 核心原理分析及其在i主題業務中的應用

一、i主題及 Disruptor 簡介
i主題是 vivo 旗下的一款主題商店 app,用戶可以通過下載主題、壁紙、字體等,實現對手機界面風格的一鍵更換和自定義。
Disruptor 是英國外匯交易公司 LMAX 開發的一個高性能的內存隊列(用于系統內部線程間傳遞消息,不同于 RocketMQ、Kafka 這種分布式消息隊列),基于 Disruptor 開發的系統單線程能支撐每秒600萬訂單。目前,包括 Apache Storm、Camel、Log4j 2在內的很多知名項目都應用了 Disruptor 以獲取高性能。在 vivo 內部它也有不少應用,比如自定義監控中使用 Disruptor 隊列來暫存通過監控 SDK 上報的監控數據,i主題中也使用它來統計本地內存指標數據。
接下來從 Disruptor 和 JDK 內置隊列的對比、Disruptor 核心概念、Disruptor 使用Demo、Disruptor 核心源碼、Disruptor 高性能原理、Disruptor 在 i主題業務中的應用幾個角度來介紹 Disruptor。
二、和 JDK 中內置的隊列對比
下面來看下 JDK 中內置的隊列和 Disruptor 的對比。隊列的底層實現一般分為三種:數組、鏈表和堆,其中堆一般是為了實現帶有優先級特性的隊列,暫不考慮。另外,像 ConcurrentLinkedQueue 、LinkedTransferQueue 屬于無界隊列,在穩定性要求特別高的系統中,為了防止生產者速度過快,導致內存溢出,只能選擇有界隊列。這樣 JDK 中剩下可選的線程安全的隊列還有ArrayBlockingQueue
和 LinkedBlockingQueue。
由于 LinkedBlockingQueue 是基于鏈表實現的,由于鏈表存儲的數據在內存里不連續,對于高速緩存并不友好,而且 LinkedBlockingQueue 是加鎖的,性能較差。ArrayBlockingQueue 有同樣的問題,它也需要加鎖,另外,ArrayBlockingQueue 存在偽共享問題,也會導致性能變差。而今天要介紹的 Disruptor 是基于數組的有界無鎖隊列,符合空間局部性原理,可以很好的利用 CPU 的高速緩存,同時它避免了偽共享,大大提升了性能。

三、Disruptor 核心概念
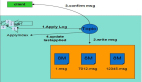
如下圖,從數據流轉的角度先對 Disruptor 有一個直觀的概念。Disruptor 支持單(多)生產者、單(多)消費者模式。消費時支持廣播消費(HandlerA 會消費處理所有消息,HandlerB 也會消費處理所有消息)、集群消費(HandlerA 和 HandlerB 各消費部分消息),HandlerA 和HandlerB 消費完成后會把消息交給 HandlerC 繼續處理。

下面結合 Disruptor 官方的架構圖介紹下 Disruptor 的核心概念:
- RingBuffer:前文說 Disruptor 是一個高性能內存內存隊列,而 RingBuffer 就是該內存隊列的數據結構,它是一個環形數組,是承載數據的載體。
- Producer:Disruptor 是典型的生產者消費者模型。因此生產者是 Disruptor 編程模型中的核心組成,可以是單生產者,也可以多生產者。
- Event:具體的數據實體,生產者生產 Event ,存入 RingBuffer,消費者從 RingBuffer 中消費它進行邏輯處理。
- Event Handler:開發者需要實現 EventHandler 接口定義消費者處理邏輯。
- Wait Strategy:等待策略,定義了當消費者無法從 RingBuffer 獲取數據時,如何等待。
- Event Processor:事件循環處理器,EventProcessor 繼承了 Runnable 接口,它的子類實現了 run 方法,內部有一個 while 循環,不斷嘗試從 RingBuffer 中獲取數據,交給 EventHandler 去處理。
- Sequence:RingBuffer 是一個數組,Sequence (序號)就是用來標記生產者數據生產到哪了,消費者數據消費到哪了。
- Sequencer:分為單生產者和多生產者兩種實現,生產者發布數據時需要先申請下可用序號,Sequencer 就是用來協調申請序號的。
- Sequence Barrier:見下文分析。

四、Disruptor使用Demo
4.1 定義 Event
Event 是具體的數據實體,生產者生產 Event ,存入 RingBuffer,消費者從 RingBuffer 中消費它進行邏輯處理。Event 就是一個普通的 Java 對象,無需實現 Disruptor 內定義的接口。
public class OrderEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}4.2 定義 EventFactory
用于創建 Event 對象。
public class OrderEventFactory implements EventFactory<OrderEvent> {
public OrderEvent newInstance() {
return new OrderEvent();
}
}4.3 定義生產者
可以看到,生成者主要是持有 RingBuffer 對象進行數據的發布。這里有幾個點需要注意:
- RingBuffer 內部維護了一個 Object 數組(也就是真正存儲數據的容器),在 RingBuffer 初始化時該 Object 數組就已經使用 EventFactory 初始化了一些空 Event,后續就不需要在運行時來創建了,提高性能。因此這里通過 RingBuffer 獲取指定序號得到的是一個空對象,需要對它進行賦值后,才能進行發布。
- 這里通過 RingBuffer 的 next 方法獲取可用序號,如果 RingBuffer 空間不足會阻塞。
- 通過 next 方法獲取序號后,需要確保接下來使用 publish 方法發布數據。
public class OrderEventProducer {
private RingBuffer<OrderEvent> ringBuffer;
public OrderEventProducer(RingBuffer<OrderEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void sendData(ByteBuffer data) {
// 1、在生產者發送消息的時候, 首先需要從我們的ringBuffer里面獲取一個可用的序號
long sequence = ringBuffer.next();
try {
//2、注意此時獲取的OrderEvent對象是一個沒有被賦值的空對象
OrderEvent event = ringBuffer.get(sequence);
//3、進行實際的賦值處理
event.setValue(data.getLong(0));
} finally {
//4、 提交發布操作
ringBuffer.publish(sequence);
}
}
}4.4 定義消費者
消費者可以實現 EventHandler 接口,定義自己的處理邏輯。
public class OrderEventHandler implements EventHandler<OrderEvent> {
public void onEvent(OrderEvent event,
long sequence,
boolean endOfBatch) throws Exception {
System.out.println("消費者: " + event.getValue());
}
}4.5 主流程
- 首先初始化一個 Disruptor 對象,Disruptor 有多個重載的構造函數。支持傳入 EventFactory 、ringBufferSize (需要是2的冪次方)、executor(用于執行EventHandler 的事件處理邏輯,一個 EventHandler 對應一個線程,一個線程只服務于一個 EventHandler )、生產者模式(支持單生產者、多生產者)、阻塞等待策略。在創建 Disruptor 對象時,內部會創建好指定 size 的 RingBuffer 對象。
- 定義 Disruptor 對象之后,可以通過該對象添加消費者 EventHandler。
- 啟動 Disruptor,會將第2步添加的 EventHandler 消費者封裝成 EventProcessor(實現了 Runnable 接口),提交到構建 Disruptor 時指定的 executor 對象中。由于 EventProcessor 的 run 方法是一個 while 循環,不斷嘗試從RingBuffer 中獲取數據。因此可以說一個 EventHandler 對應一個線程,一個線程只服務于一個EventHandler。
- 拿到 Disruptor 持有的 RingBuffer,然后就可以創建生產者,通過該RingBuffer就可以發布生產數據了,然后 EventProcessor 中啟動的任務就可以消費到數據,交給 EventHandler 去處理了。
public static void main(String[] args) {
OrderEventFactory orderEventFactory = new OrderEventFactory();
int ringBufferSize = 4;
ExecutorService executor = Executors.newFixedThreadPool(1);
/**
* 1. 實例化disruptor對象
1) eventFactory: 消息(event)工廠對象
2) ringBufferSize: 容器的長度
3) executor:
4) ProducerType: 單生產者還是多生產者
5) waitStrategy: 等待策略
*/
Disruptor<OrderEvent> disruptor = new Disruptor<OrderEvent>(orderEventFactory,
ringBufferSize,
executor,
ProducerType.SINGLE,
new BlockingWaitStrategy());
// 2. 添加消費者的監聽
disruptor.handleEventsWith(new OrderEventHandler());
// 3. 啟動disruptor
disruptor.start();
// 4. 獲取實際存儲數據的容器: RingBuffer
RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();
OrderEventProducer producer = new OrderEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long i = 0; i < 5; i++) {
bb.putLong(0, i);
producer.sendData(bb);
}
disruptor.shutdown();
executor.shutdown();
}五、Disruptor 源碼分析
本文分析時以單(多)生產者、單消費者為例進行分析。
5.1 創建 Disruptor
首先是通過傳入的參數創建 RingBuffer,將創建好的 RingBuffer 與傳入的 executor 交給 Disruptor 對象持有。
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final WaitStrategy waitStrategy){
this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
executor);
}接下來分析 RingBuffer 的創建過程,分為單生產者與多生產者。
public static <E> RingBuffer<E> create(
ProducerType producerType,
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy){
switch (producerType){
case SINGLE:
// 單生產者
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
// 多生產者
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}不論是單生產者還是多生產者,最終都會創建一個 RingBuffer 對象,只是傳給 RingBuffer 的 Sequencer 對象不同。可以看到,RingBuffer 內部最終創建了一個Object 數組來存儲 Event 數據。這里有幾點需要注意:
- RingBuffer 是用數組實現的,在創建該數組后緊接著調用 fill 方法調用 EventFactory 工廠方法為數組中的元素進行初始化,后續在使用這些元素時,直接通過下標獲取并給對應的屬性賦值,這樣就避免了 Event 對象的反復創建,避免頻繁 GC。
- RingBuffe 的數組中的元素是在初始化時一次性全部創建的,所以這些元素的內存地址大概率是連續的。消費者在消費時,是遵循空間局部性原理的。消費完第一個Event 時,很快就會消費第二個 Event,而在消費第一個 Event 時,CPU 會把內存中的第一個 Event 的后面的 Event 也加載進 Cache 中,這樣當消費第二個 Event時,它已經在 CPU Cache 中了,所以就不需要從內存中加載了,這樣可以大大提升性能。
public static <E> RingBuffer<E> createSingleProducer(
EventFactory<E> factory, int bufferSize, WaitStrategy waitStrategy){
SingleProducerSequencer sequencer = new SingleProducerSequencer(bufferSize,
waitStrategy);
return new RingBuffer<E>(factory, sequencer);
}RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer){
// 省略部分代碼...
// 額外創建2個填充空間的大小, 首尾填充, 避免數組的有效載荷和其它成員加載到同一緩存行
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory){
for (int i = 0; i < bufferSize; i++){
// BUFFER_PAD + i為真正的數組索引
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}5.2 添加消費者
添加消費者的核心代碼如下所示,核心就是為將一個 EventHandler 封裝成 BatchEventProcessor,
然后添加到 consumerRepository 中,后續啟動 Disruptor 時,會遍歷 consumerRepository 中的所有 BatchEventProcessor(實現了 Runnable 接口),將 BatchEventProcessor 任務提交到線程池中。
public final EventHandlerGroup<T> handleEventsWith(
final EventHandler<? super T>... handlers){
// 通過disruptor對象直接調用handleEventsWith方法時傳的是空的Sequence數組
return createEventProcessors(new Sequence[0], handlers);
}EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers) {
// 收集添加的消費者的序號
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
// 本批次消費由于添加在同一個節點之后, 因此共享該屏障
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
// 為每個EventHandler創建一個BatchEventProcessor
for (int i = 0, eventHandlersLength = eventHandlers.length;
i < eventHandlersLength; i++) {
final EventHandler<? super T> eventHandler = eventHandlers[i];
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null){
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
// 添加到消費者信息倉庫中
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 更新網關序列(生產者只需要關注所有的末端消費者節點的序列)
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}創建完 Disruptor 對象之后,可以通過 Disruptor 對象添加 EventHandler,這里有一需要注意:通過 Disruptor 對象直接調用 handleEventsWith 方法時傳的是空的 Sequence 數組,這是什么意思?可以看到 createEventProcessors 方法接收該空 Sequence 數組的字段名是 barrierSequences,翻譯成中文就是柵欄序號。怎么理解這個字段?
比如通過如下代碼給 Disruptor 添加了兩個handler,記為 handlerA 和 handlerB,這種是串行消費,對于一個 Event,handlerA 消費完后才能輪到 handlerB 去消費。對于 handlerA 來說,它沒有前置消費者(生成者生產到哪里,消費者就可以消費到哪里),因此它的 barrierSequences 是一個空數組。而對于 handlerB 來說,它的前置消費者是 handlerA,因此它的 barrierSequences 就是A的消費進度,也就是說 handlerB 的消費進度是要小于 handlerA 的消費進度的。

disruptor.handleEventsWith(handlerA).handleEventsWith(handlerB);如果是通過如下方式添加的 handler,則 handlerA 和handlerB 會消費所有 Event 數據,類似 MQ 消息中的廣播消費,而 handlerC 的 barrierSequences 數組就是包含了 handlerA 的消費進度和 handlerB 的消費進度,這也是為什么 barrierSequences 是一個數組,后續 handlerC 在消費數據時,會取A和B消費進度的較小值進行判斷,比如A消費到進度6,B消費到進度4,那么C只能去消費下標為3的數據,這也是 barrierSequences 的含義。
disruptor.handleEventsWith(handlerA, handlerB).handleEventsWith(handlerC);
5.3 啟動 Disruptor
Disruptor的啟動邏輯比較簡潔,就是遍歷consumerRepository 中收集的 EventProcessor(實現了Runnable接口),將它提交到創建 Disruptor 時指定的executor 中,EventProcessor 的 run 方法會啟動一個while 循環,不斷嘗試從 RingBuffer 中獲取數據進行消費。
disruptor.start();public RingBuffer<T> start() {
checkOnlyStartedOnce();
for (final ConsumerInfo consumerInfo : consumerRepository) {
consumerInfo.start(executor);
}
return ringBuffer;
}
public void start(final Executor executor) {
executor.execute(eventprocessor);
}5.4 發布數據
在分析 Disruptor 的發布數據的源碼前,先來回顧下發布數據的整體流程。
- 調用 next 方法獲取可用序號,該方法可能會阻塞。
- 通過上一步獲得的序號從 RingBuffer 中獲取對應的 Event,因為 RingBuffer 中所有的 Event 在初始化時已經創建好了,這里獲取的只是空對象。
- 因此接下來需要對該空對象進行業務賦值。
- 調用 next 方法需要在 finally 方法中進行最終的發布,標記該序號數據已實際生產完成。
public void sendData(ByteBuffer data) {
long sequence = ringBuffer.next();
try {
OrderEvent event = ringBuffer.get(sequence);
event.setValue(data.getLong(0));
} finally {
ringBuffer.publish(sequence);
}
}5.4.1 獲取序號
next 方法默認申請一個序號。nextValue 表示已分配的序號,nextSequence 表示在此基礎上再申請n個序號(此處n為1),cachedValue 表示緩存的消費者的最小消費進度。
假設有一個 size 為8的 RingBuffer,當前下標為6的數據已經發布好(nextValue為6),消費者一直未開啟消費(cachedValue 和
cachedGatingSequence 為-1),此時生產者想繼續發布數據,調用 next() 方法申請獲取序號為7的位置(nextSequence為7),計算得到的 wrapPoint 為7-8=-1,此時 wrapPoint 等于
cachedGatingSequence,可以繼續發布數據,如左圖。最后將 nextValue 賦值為7,表示序號7的位置已經被生產者占用了。
接著生產者繼續調用 next() 方法申請序號為0的數據,此時 nextValue為7,nextSequence 為8,wrapPoint 等于0,由于消費者遲遲未消費
(cachedGatingSequence為-1),此時 wrapPoint 大于了 cachedGatingSequence,因此 next 方法的if判斷成立,會調用 LockSupport.parkNanos 阻塞等待消費者進行消費。其中 getMinimumSequence 方法是獲取多個消費者的最小消費進度。

public long next() {
return next(1);
}public long next(int n) {
/**
* 已分配的序號的緩存(已分配到這里), 初始-1. 可以看該方法的返回值nextSequence,
* 接下來生產者就會該往該位置寫數據, 它賦值給了nextValue, 所以下一次調用next方
* 法時, nextValue位置就是表示已經生產好了數據, 接下來要申請nextSequece的數據
*/
long nextValue = this.nextValue;
// 本次申請分配的序號
long nextSequence = nextValue + n;
// 構成環路的點:環形緩沖區可能追尾的點 = 等于本次申請的序號-環形緩沖區大小
// 如果該序號大于最慢消費者的進度, 那么表示追尾了, 需要等待
long wrapPoint = nextSequence - bufferSize;
// 上次緩存的最小網關序號(消費最慢的消費者的進度)
long cachedGatingSequence = this.cachedValue;
// wrapPoint > cachedGatingSequence 表示生產者追上消費者產生環路(追尾), 即緩沖區已滿,
// 此時需要獲取消費者們最新的進度, 以確定是否隊列滿
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
// 插入StoreLoad內存屏障/柵欄, 保證可見性。
// 因為publish使用的是set()/putOrderedLong, 并不保證其他消費者能及時看見發布的數據
// 當我再次申請更多的空間時, 必須保證消費者能消費發布的數據
cursor.setVolatile(nextValue);
long minSequence;
// minSequence是多個消費者的最小序號, 要等所有消費者消費完了才能繼續生產
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences,
nextValue))) {
LockSupport.parkNanos(1L);
}
// 緩存生產者們最新的消費進度
this.cachedValue = minSequence;
}
// 這里只寫了緩存, 并未寫volatile變量, 因為只是預分配了空間但是并未被發布數據,
// 不需要讓其他消費者感知到。消費者只會感知到真正被發布的序號
this.nextValue = nextSequence;
return nextSequence;
}5.4.2 根據序號獲取 Event
直接通過 Unsafe 工具類獲取指定序號的 Event 對象,此時獲取的是空對象,因此接下來需要對該 Event 對象進行業務賦值,賦值完成后調用 publish 方法進行最終的數據發布。
OrderEvent event = ringBuffer.get(sequence);public E get(long sequence) {
return elementAt(sequence);
}protected final E elementAt(long sequence) {
return (E) UNSAFE.getObject(entries,
REF_ARRAY_BASE +
((sequence & indexMask) << REF_ELEMENT_SHIFT));
}5.4.3 發布數據
生產者獲取到可用序號后,首先對該序號處的空 Event 對象進行業務賦值,接著調用 RingBuffer 的 publish 方法發布數據,RingBuffer 會委托給其持有的 sequencer(單生產者和多生產者對應不同的 sequencer)對象進行真正發布。單生產者的發布邏輯比較簡單,更新下 cursor 進度(cursor 表示生產者的生產進度,該位置已實際發布數據,而 next 方法中的 nextSequence 表示生產者申請的最大序號,可能還未實際發布數據),接著喚醒等待的消費者。
waitStrategy 有不同的實現,因此喚醒邏輯也不盡相同,如采用 BusySpinWaitStrategy 策略時,消費者獲取不到數據時自旋等待,然后繼續判斷是否有新數據可以消費了,因此 BusySpinWaitStrategy 策略的 signalAllWhenBlocking 就是一個空實現,啥也不做。
ringBuffer.publish(sequence);public void publish(long sequence) {
sequencer.publish(sequence);
}public void publish(long sequence) {
// 更新生產者進度
cursor.set(sequence);
// 喚醒等待的消費者
waitStrategy.signalAllWhenBlocking();
}5.4.4 消費數據
前面提到,Disruptor 啟動時,會將封裝 EventHandler 的EventProcessor(此處以 BatchEventProcessor 為例)提交到線程池中運行,BatchEventProcessor 的 run 方法會調用 processEvents 方法不斷嘗試從 RingBuffer 中獲取數據進行消費,下面分析下 processEvents 的邏輯(代碼做了精簡)。它會開啟一個 while 循環,調用 sequenceBarrier.waitFor 方法獲取最大可用的序號,比如獲取序號一節所提的,生產者持續生產,消費者一直未消費,此時生產者已經將整個 RingBuffer 數據都生產滿了,生產者無法再繼續生產,生產者此時會阻塞。假設這時候消費者開始消費,因此 nextSequence 為0,而
availableSequence 為7,此時消費者可以批量消費,將這8條已生產者的數據全部消費完,消費完成后更新下消費進度。更新消費進度后,生產者通過 Util.getMinimumSequence 方法就可以感知到最新的消費進度,從而不再阻塞,繼續發布數據了。
private void processEvents() {
T event = null;
// sequence記錄消費者的消費進度, 初始為-1
long nextSequence = sequence.get() + 1L;
// 死循環,因此不會讓出線程,需要獨立的線程(每一個EventProcessor都需要獨立的線程)
while (true) {
// 通過屏障獲取到的最大可用序號
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
// 批量消費
while (nextSequence <= availableSequence) {
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
// 更新消費進度(批量消費, 每次消費只更新一次Sequence, 減少性能消耗)
sequence.set(availableSequence);
}
}下面分析下 SequenceBarrier 的 waitFor 方法。首先它會調用 waitStrategy 的 waitFor 方法獲取最大可用序號,以 BusySpinWaitStrategy 策略為例,它的 waitFor 方法的三個參數的含義分別是:
- sequence:消費者期望獲得的序號,也就是當前消費者已消費的進度+1
- cursor:當前生產者的生成進度
- dependentSequence:消費者依賴的前置消費者的消費進度。該字段是在添加 EventHandler,創建
BatchEventProcessor 時創建的。如果當前消費者沒有前置依賴的消費者,那么它只需要關心生產者的進度,生產者生產到哪里,它就可以消費到哪里,因此 dependentSequence 就是 cursor。而如果當前消費者有前置依賴的消費者,那么dependentSequence就是
FixedSequenceGroup(dependentSequences)。
因為 dependentSequence 分為兩種情況,所以 waitFor 的邏輯也可以分為兩種情況討論:
- 當前消費者無前置消費者:假設 cursor 為6,也就是序號為6的數據已經發布了數據,此時傳入的sequence為6,則waitFor方法可以直接返回availableSequence(6),可以正常消費。序號為6的數據消費完成后,消費者繼續調用 waitFor 獲取數據,傳入的 sequence為7,而此時 availableSequence 還是未6,因此消費者需要自旋等待。當生產者繼續發布數據后,因為 dependentSequence 持有的就是生產者的生成進度,因此消費者可以感知到,繼續消費。
- 當前消費者有前置消費者:假設 cursor 為6,當前消費者C有兩個前置依賴的消費者A(消費進度為5)、B(消費進度為4),那么此時 availableSequence
(FixedSequenceGroup實例,它的 get 方法是獲取A、B的最小值,也就是4)為4。如果當前消費者C期望消費下標為4的數據,則可以正常消費,但是消費下標為5的數據就不行了,它需要等待它的前置消費者B消費完進度為5的數據后才能繼續消費。
在 waitStrategy 的 waitFor 方法返回,得到最大可用的序號 availableSequence 后,最后需要再調用下 sequencer 的
getHighestPublishedSequence 獲取真正可用的最大序號,這和生產者模型有關系,如果是單生產者,因為數據是連續發布的,直接返回傳入的 availableSequence。而如果是多生產者,因為多生產者是有多個線程在生產數據,發布的數據是不連續的,因此需要通過
getHighestPublishedSequence 方法獲取已發布的且連續的最大序號,因為獲取序號進行消費時需要是順序的,不能跳躍。
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException {
/**
* sequence: 消費者期望獲取的序號
* cursorSequence: 生產者的序號
* dependentSequence: 消費者需要依賴的序號
*/
long availableSequence = waitStrategy.waitFor(sequence,
cursorSequence,
dependentSequence, this);
if (availableSequence < sequence) {
return availableSequence;
}
// 目標sequence已經發布了, 這里獲取真正的最大序號(和生產者模型有關)
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence,
final SequenceBarrier barrier) throws AlertException, InterruptedException {
long availableSequence;
// 確保該序號已經被我前面的消費者消費(協調與其他消費者的關系)
while ((availableSequence = dependentSequence.get()) < sequence) {
barrier.checkAlert();
// 自旋等待
ThreadHints.onSpinWait();
}
return availableSequence;
}六、Disruptor 高性能原理分析
6.1 空間預分配
前文分析源碼時介紹到,RingBuffer 內部維護了一個 Object 數組(也就是真正存儲數據的容器),在 RingBuffer 初始化時該 Object 數組就已經使用EventFactory 初始化了一些空 Event,后續就不需要在運行時來創建了,避免頻繁GC。
另外,RingBuffe 的數組中的元素是在初始化時一次性全部創建的,所以這些元素的內存地址大概率是連續的。消費者在消費時,是遵循空間局部性原理的。消費完第一個Event 時,很快就會消費第二個 Event,而在消費第一個 Event 時,CPU 會把內存中的第一個 Event 的后面的 Event 也加載進 Cache 中,這樣當消費第二個 Event 時,它已經在 CPU Cache 中了,所以就不需要從內存中加載了,這樣也可以大大提升性能。
6.2、避免偽共享
6.2.1 一個偽共享的例子
如下代碼所示,定義了一個 Pointer 類,它有2個 long 類型的成員變量x、y,然后在 main 方法中其中2個線程分別對同一個 Pointer 對象的x和y自增 100000000 次,最后統計下方法耗時,在我本機電腦上測試多次,平均約為3600ms。
public class Pointer {
volatile long x;
volatile long y;
@Override
public String toString() {
return new StringJoiner(", ", Pointer.class.getSimpleName() + "[", "]")
.add("x=" + x)
.add("y=" + y)
.toString();
}
}public static void main(String[] args) throws InterruptedException {
Pointer pointer = new Pointer();
int num = 100000000;
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i = 0; i < num; i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i = 0; i < num; i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}接著將 Pointer 類修改如下:在變量x和y之間插入7個 long 類型的變量,僅此而已,接著繼續通過上述的 main 方法統計耗時,平均約為500ms。可以看到,修改前的耗時是修改后(避免了偽共享)的7倍多。那么什么是偽共享,為什么避免了偽共享能有這么大的性能提升呢?
public class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
@Override
public String toString() {
return new StringJoiner(", ", Pointer.class.getSimpleName() + "[", "]")
.add("x=" + x)
.add("y=" + y)
.toString();
}
}6.2.2、避免偽共享為什么可以提升性能
內存的訪問速度是遠遠慢于 CPU 的,為了高效利用 CPU,在 CPU 和內存之間加了緩存,稱為 CPU Cache。為了提高性能,需要更多地從 CPU Cache 里獲取數據,而不是從內存中獲取數據。CPU Cache 加載內存里的數據,是以緩存行(通常為64字節)為單位加載的。Java 的 long 類型是8字節,因此一個緩存行可以存放8個 long 類型的變量。
但是,這種加載帶來了一個壞處,如上述例子所示,假設有一個 long 類型的變量x,另外還有一個 long 類型的變量y緊挨著它,那么當加載x時也會加載y。如果此時 CPU Core1 的線程在對x進行修改,另一個 CPU Core2 的線程卻在對y進行讀取。當前者修改x時,會把x和y同時加載到 CPU Core1 對應的 CPU Cache 中,更新完后x和其它所有包含x的緩存行都將失效。而當 CPU Core2 的線程讀取y時,發現這個緩存行已經失效了,需要從主內存中重新加載。
這就是偽共享,x和y不相干,但是卻因為x的更新導致需要重新從主內存讀取,拖慢了程序性能。解決辦法之一就是如上述示例中所做,在x和y之間填充7個 long 類型的變量,保證x和y不會被加載到同一個緩存行中去。Java8 中也增加了新的注解@Contended(JVM加上啟動參數-XX:-RestrictContended 才會生效),也可以避免偽共享。

6.2.3、Disruptor 中使用偽共享的場景
Disruptor 中使用 Sequence 類的 value 字段來表示生產/消費進度,可以看到在該字段前后各填充了7個 long 類型的變量,來避免偽共享。另外,向 RingBuffer 內部的數組、
SingleProducerSequencer 等也使用了該技術。
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}6.3、無鎖
生產者生產數據時,需要入隊。消費者消費數據時,需要出隊。入隊時,不能覆蓋沒有消費的元素。出隊時,不能讀取沒有寫入的元素。因此,Disruptor 中需要維護一個入隊索引(生產者數據生產到哪里,對應 AbstractSequencer 中的 cursor )和一個出隊索引(所有消費者中消費進度最小的序號)。
Disruptor 中最復雜的是入隊操作,下面以多生產者(MultiProducerSequencer)的 next(n) 方法(申請n個序號)為例分析下 Disruptor 是如何實現無鎖操作的。代碼如下所示,判斷下是否有足夠的序號(空余位置),如果沒有,就讓出 CPU 使用權,然后重新判斷。如果有,則使用 CAS 設置 cursor(入隊索引)。
public long next(int n) {
do {
// cursor類似于入隊索引, 指的是上次生產到這里
current = cursor.get();
// 目標是再生產n個
next = current + n;
// 前文分析過, 用于判斷消費者是否已經追上生產進度, 生產者能否申請到n個序號
long wrapPoint = next - bufferSize;
// 獲取緩存的上一次的消費進度
long cachedGatingSequence = gatingSequenceCache.get();
// 第一步:空間不足就繼續等待
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) {
// 重新計算下所有消費者里的最小消費進度
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
// 依然沒有足夠的空間, 讓出CPU使用權
if (wrapPoint > gatingSequence) {
LockSupport.parkNanos(1);
continue;
}
// 更新下最新的最小的消費進度
gatingSequenceCache.set(gatingSequence);
}
// 第二步:看見空間足夠時嘗試CAS競爭空間
else if (cursor.compareAndSet(current, next)) {
break;
}
} while (true);
return next;
}6.4、支持批量消費定義 Event
這個比較好理解,在前文分析消費數據的邏輯時介紹了,消費者會獲取下最大可用的序號,然后批量消費這些消息。
七、Disruptor 在i主題業務中的使用
很多開源項目都使用了 Disruptor,比如日志框架 Log4j2 使用它來實現異步日志。HBase、Storm 等項目中也使用了到了 Disruptor。vivo 的 i主題業務也使用了 Disruptor,下面簡單介紹下它的2個使用場景。
7.1、監控數據上報
業務監控系統對于企業來說非常重要,可以幫助企業及時發現和解決問題,可以方便的檢測業務指標數據,改進業務決策,從而保證業務的可持續發展。i主題使用 Disruptor(多生產者單消費者)來暫存待上報的業務指標數據,然后有定時任務不斷提取數據上報到監控平臺,如下圖所示。

7.2、本地緩存 key 統計分析
i主題業務中大量使用了本地緩存,為了統計本地緩存中key 的個數(去重)以及每種緩存模式 key 的數量,考慮使用 Disruptor 來暫存并消費處理數據。因為業務代碼里很多地方涉及到本地緩存的訪問,也就是說,生產者是多線程的。考慮到消費處理比較簡單,而如果使用多線程消費的話又涉及到加鎖同步,因此消費者采用單線程模式。
整體流程如下圖所示,首先在緩存訪問工具類中增加緩存訪問統計上報的調用,緩存訪問數據進入到 RingBuffer 后,單線程消費者使用 HyperLogLog 來去重統計不同 key的個數,使用正則匹配來統計每種模式key的數量。然后有異步任務定時獲取統計結果,進行展示。
需要注意的是,因為 RingBuffer 隊列大小是固定的,如果生產者生產過快而消費者消費不過來,如果使用 next 方法申請序號,如果剩余空間不夠會導致生產者阻塞,因此建議使用 tryPublishEvent 方法去發布數據,它內部是使用 tryNext 方法申請序號,該方法如果申請不到可用序號會拋出異常,這樣生產者感知到了就可以做兼容處理,而不是阻塞等待。

八、使用建議
- Disruptor 是基于生產者消費者模式,如果生產快消費慢,就會導致生產者無法寫入數據。因此,不建議在 Disruptor 消費線程中處理耗時較長的業務。
- 一個 EventHandler 對應一個線程,一個線程只服務于一個 EventHandler。Disruptor 需要為每一個
EventHandler(EventProcessor) 創建一個線程。因此在創建 Disruptor 時不推薦傳入指定的線程池,而是由 Disruptor 自身根據 EventHandler 數量去創建對應的線程。 - 生產者調用 next 方法申請序號時,如果獲取不到可用序號會阻塞,這一點需要注意。推薦使用 tryPublishEvent 方法,生產者在申請不到可用序號時會立即返回,不會阻塞業務線程。
- 如果使用 next 方法申請可用序號,需要確保在 finally 方法中調用 publish 真正發布數據。
- 合理設置等待策略。消費者在獲取不到數據時會根據設置的等待策略進行等待,BlockingWaitStrategry 是最低效的策略,但其對 CPU消耗最小。YieldingWaitStrategy 有著較低的延遲、較高的吞吐量,以及較高 CPU 占用率。當 CPU 數量足夠時,可以使用該策略。
九、總結
本文首先通過對比 JDK 中內置的線程安全的隊列和Disruptor 的特點,引入了高性能無鎖內存隊列 Disruptor。接著介紹了 Disruptor 的核心概念和基本使用,使讀者對 Disruptor 建立起初步的認識。接著從源碼和原理角度介紹了 Disruptor 的核心實現以及高性能原理(空間預分配、避免偽共享、無鎖、支持批量消費)。其次,結合i主題業務介紹了 Disruptor 在實踐中的應用。最后,基于上述原理分析及應用實戰,總結了一些 Disruptor 最佳實踐策略。
參考文章:
https://time.geekbang.org/column/article/132477
https://lmax-exchange.github.io/disruptor/