Facebook的有序隊列服務設計原理和高性能淺析
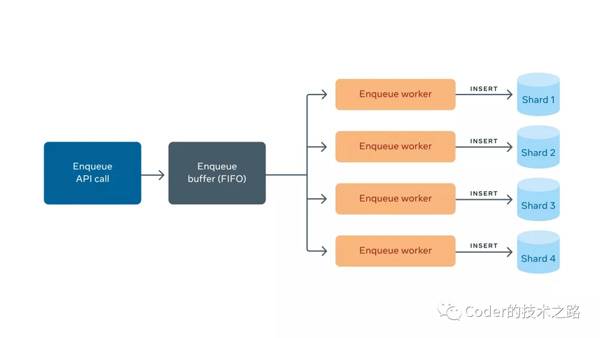
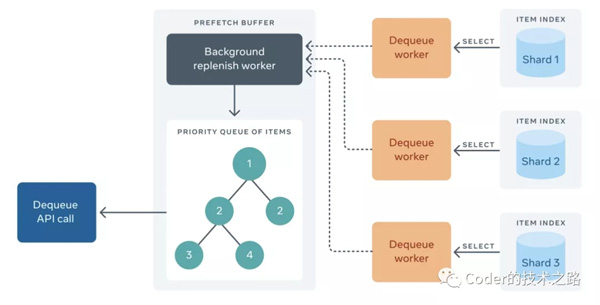
Facebook生態系統是由成千上萬的分布式系統和微服務驅動構成的,其中許多服務都得益于異步作業,特別是在在線流量的高峰時期。異步化提供了諸多好處:更有效地利用資源、提高系統可靠性、允許計劃執行,以及微服務彼此間可靠通信。實現這些優勢都需要一個隊列——一個存儲作業的地方,允許其異步發生,或者從一個服務傳遞到另一個服務。facebook有序隊列服務FOQS應運而生。 FOQS在Facebook上支持數百個服務,包括: facebook engineering[1] FOQS的主要能力是存儲位于namespace中的topic中的item。它公開了一個Thrift API,包含以下操作: FOQS通過內部服務Shard Manager來管理對主機的分片分配。每個分片分配給一臺主機。為了更容易地與其他后端服務通信,FOQS實現了Thrift接口。下面來分別介紹各部分的原理和設計: item是FOQS中優先隊列的消息,其中包含用戶指定的數據。一般來說,它由以下字段組成: 「FOQS中的每個Item對應于MySQL表中的一行。在進入隊列時,會給一個Item分配一個ID。」 一個topic就是一個邏輯優先隊列,一般是一個字符串,由用戶指定。它包含item,并按它們的優先級和deliver_after值對它們進行排序。主題是廉價且而且是動態變動的,只需將item排隊并指定topic標識就可以創建topic。 由于topic是動態的,FOQS為開發人員提供了一個API,通過查詢活動topic(至少包含一個item)來發現topic。當一個topic沒有更多的item時,它就不再存在。 一個namespace和一個隊列用例相匹配。它是FOQS的多租戶單位。每個namespace都有一定的容量保證,以每分鐘的隊列數量衡量。命名空間可以共享同一列(一列是FOQS主機和MySQL分片的集合,為一組命名空間提供服務),且不相互影響。命名空間只映射到一個列。 Enqueues是item進入FOQS的入口。如果成功進入隊列,則會執行持久化,最終出隊列。 當一個入隊請求到達FOQS主機時,請求被緩沖下來并返回一個promise。每個MySQL分片都有一個對應的worker,它從緩沖區中讀取item并將它們插入到MySQL中。一個數據庫行對應一個item。一旦插入完成(成功或失敗),promise就會完成實現,并將隊列響應發送回客戶機。如下圖所示: FOQS使用熔斷設計模式來標記不健康的分片。其健康狀況由慢查詢(滾動窗口上平均毫秒數大于 x ms)或錯誤率(滾動窗口上平均錯誤數大于x%)定義。如果分片被判定為不健康,worker將停止工作,直到分片健康。這樣,FOQS就不會繼續向已經不健康的分片添加新item了。 如果插入成功,enqueue API返回一個項目的唯一ID。該ID是一個字符串,包含分片 ID和分片中的64位主鍵。這種組合唯一地標識了FOQS中的每一項。 dequeue API的入參是(topic, count)的參數對的集合。對于每個topic,FOQS最多會返回對該topic的count個item。這些item是按優先級和deliver_after排序的,因此優先級較低的物品將首先被交付。如果多個item的優先級最低,較低的deliver_after(即較老的)item將首先交付。 隊列API允許指定項目的過期期限。當一個item出隊列時,它的過期判定也會開始。如果item沒有在期限內被ack或被nack,它可以被重投。這是為了避免下游消費者在ack或nack item之前崩潰時丟失item。FOQS支持至少一次和最多一次的投遞。如果一個item最多投遞一次,則在過期時間到期后將其刪除;如果至少一次,將嘗試重新投遞。 由于FOQS支持優先級,每臺主機需要在它關聯的分片上做一個reduce操作,以找到優先級最高的item。為了優化,FOQS維護了一個叫做預取緩沖區(Prefetch Buffer)的數據結構,它在后臺運行,從所有分片中取優先級最高的item,然后進行緩存,以便客戶端從隊列中取出。 每個分片維護一個按優先級排序的,準備投遞的item主鍵的 內存索引。該索引被所有可能標記一個item已經準備好投遞的操作(如enqueues)進行更新。并允許預取緩沖區通過k-way merge和select查詢來高效地找到優先級最高的主鍵。這些item的狀態在數據庫中也被更新為“已投遞”,避免重復投遞。 預取緩沖區(Prefetch Buffer)通過存儲每個topic的客戶端請求(出隊率)來補充自身。預取緩沖區(Prefetch Buffer)將以與客戶端請求成比例的速率請求item。快速出隊的topic將獲得更多的item放入預取緩沖區。 dequeue API只是從預取緩沖區讀取項目并將它們返回給客戶機: 前言
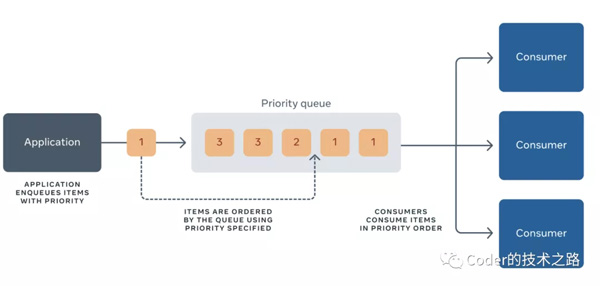
構建分布式優先隊列
Item
topic
namespace
Enqueue
Dequeue
ack表示該item已退出隊列并已成功處理,不需要再次發送。 nack表示一個item應該被重新投遞,因為客戶端需要再次處理。當一個項被NACK時,是可以延遲處理的,允許客戶端在處理失敗的item時利用指數后退。此外,客戶端可以在nack上更新該item的元數據,以便在該item中存儲部分結果。 因為每個MySQL分片最多屬于一個FOQS主機,一個ack/nack請求需要落在分片對應的主機上。由于shard ID編碼在每個item ID中,FOQS客戶端使用shard來定位主機。這個映射通過Shard Manager查找。 一旦ack/nack被路由到正確的主機,它就會被發送到特定分片的內存緩沖區。worker從ack緩沖區中取出item,然后從MySQL分片中刪除這些行; 類似地,worker從nack緩沖區中提取item。但不是刪除,而是使用新的deliver_after時間和元數據(如果客戶端更新了它)更新item。如果ack或nack操作因為任何原因丟失,例如MySQL不可用或FOQS節點崩潰,這些item將被考慮在租約到期后重新投遞。 Ack/Nack
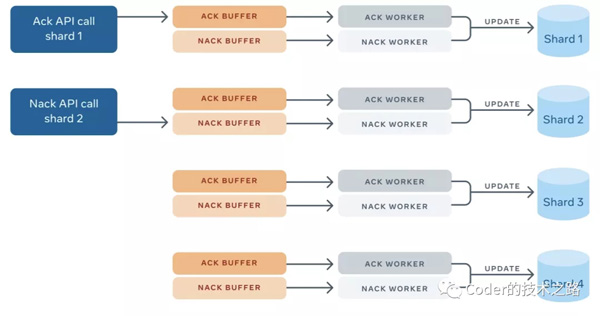
Push vs. Pull
FOQS提供了一個基于拉的接口,消費者使用dequeue API來獲取可用數據。為了理解在FOQS API中提供拉模型背后的動機,我們看看使用FOQS的作業的多樣性。它包括以下特征:
端到端延遲處理的需要:端到端處理延遲,是指item從準備好到被消費者從隊列中拉取消費所經歷的時間。快速消費和緩慢消費的作業混在一起。有的可以被毫秒級消費,而有的會延遲好幾天。 處理速率 : topic對于item的消費速率可能是不同的(每分鐘10個item到每分鐘1000多個item)。但是,根據下游資源在特定時間的可用性,可能有別于它們日常的處理速度。 優先級: topic級別或topic內單個item級別的處理優先級不同。 處理的位置 : 某些topic和item需要在特定的區域進行處理,以確保它們與正在處理的數據的關聯性。
FOQS的大規模實踐
FOQS在過去幾年中經歷了指數級的增長,現在每天處理近一萬億件產品。而處理的積壓訂單已經達到數千億項,反映了系統處理能力普遍欠缺。為了處理這種規模,我們必須實現一些優化。
檢查點 CheckPointing
FOQS專門設置有后臺線程,來運行比如延遲的item準備投遞、租約過期和清除過期的item,這些操作依賴于記錄行中的時間戳字段。
比如,如果我們想更新所有準備交付的item的狀態,來標識它們已經準備好投遞,則需要一個查詢:
- where timestamp_column <= UNIX_TIMESTAMP() for update
對所有行進行更新。
這種查詢的問題是MySQL需要用時間戳≲now 鎖定對所有行更新(不僅僅是符合條件的那些記錄)。、歷史越長,讀取查詢就越慢。
通過checkpoinging,FOQS在查詢上維護了一個下界(最后處理的已知時間戳),它限定了where子句。where子句變成:
- WHERE <checkpoint> <= timestamp_column AND timestamp_column <= UNIX_TIMESTAMP()
通過在兩邊綁定查詢,表示歷史記錄的行數就會更少,從而使讀取(和更新)的總體性能更好。
災備
Facebook的基礎設施需要能夠承受一整個數據中心發生異常。所以,每個FOQS MySQL分片被復制到兩個冗余的災備集群。跨區復制是異步的,但是MySQL binlog以同步的方式持久化到同一區域的另一個災備集群中。
如果數據中心需要被清空(或者MySQL數據庫正在進行維護),MySQL主數據庫將暫時處于只讀模式,直到副本能夠和主節點同步。
這通常需要幾毫秒。一旦副本和主節點數據達到一致,副本就被提升為主節點。
而這時會變成MySQL的主節點在另一個區域,而分區被分配給該區域的FOQS主機。這將最大限度地減少跨區域的網絡流量,但相對來說比較昂貴。推動MySQL副本成為主節點的事件會導致跨地區的流量不平衡(一般來說,FOQS不能假設哪里有多少流量)。為了處理這些場景,FOQS不得不改進它的路由,使入隊列路由到有足夠容量的主機,而出隊列路由到具有高優先級item的主機。
FOQS本身使用的一些災難可靠性優化:
入隊轉發: 如果入隊請求落在一個負載過重的主機上,FOQS將它轉發給另一個有處理能力的主機。 全局速率限制: 由于namespace是foqs的多租戶單元,所以每個namespace都有一個速率限制(計算為每分鐘排隊數)。FOQS在全局(所有地區)強制執行這個速率限制。在一個特定的區域內保證速率限制是不可能的,但是FOQS確實使用流量模式來嘗試將處理能力與流量配置在一起,以減少跨區域的流量。
Reference
facebook engineering: facebook工程師技術博客