大模型終端部署新趨勢:硬件直接支持混合矩陣乘法
在人工智能領域,模型參數的增多往往意味著性能的提升。但隨著模型規模的擴大,其對終端設備的算力與內存需求也日益增加。低比特量化技術,由于可以大幅降低存儲和計算成本并提升推理效率,已成為實現大模型在資源受限設備上高效運行的關鍵技術之一。然而,如果硬件設備不支持低比特量化后的數據模式,那么低比特量化的優勢將無法發揮。
為了解決這一問題,微軟亞洲研究院推出了全新的數據編譯器 Ladder 和算法 T-MAC,使當前只支持對稱精度計算的硬件能夠直接運行混合精度矩陣乘法。測試結果表明,Ladder 在支持 GPU 原本不支持的自定義數據類型方面,最高提速可達 14.6 倍;T-MAC 在搭載了最新高通 Snapdragon X Elite 芯片組的 Surface AI PC 上,使 CPU 上運行的大模型吞吐率比專用加速器 NPU 快兩倍。此外,研究員們還設計了 LUT Tensor Core 硬件架構,這種精簡設計使硬件能夠直接支持各種低比特混合精度計算,為人工智能硬件設計提供了新思路。
大模型已經越來越多地被部署在智能手機、筆記本電腦、機器人等端側設備上,以提供先進的智能及實時響應服務。但包含上億參數的大模型對終端設備的內存和計算能力提出了極高的要求,也因此限制了它們的廣泛應用。低比特量化技術因其能顯著壓縮模型規模,降低對計算資源的需求,成為了大模型在端側部署和實現高效推理的有效手段。
隨著低比特量化技術的發展,數據類型日益多樣化,如 int4、int2、int1 等低比特數據,使得大模型在推理中越來越多地采用低比特權重和高比特權重計算的混合精度矩陣乘法(mixed-precision matrix multiplication,mpGEMM)。然而,現有的 CPU、GPU 等硬件計算單元通常只支持對稱計算模式,并不兼容這種混合精度的矩陣乘法。
混合精度矩陣乘法與傳統的矩陣乘法有何不同?
在傳統的矩陣乘法中,參與運算的兩端數值是對稱的,例如 FP16*FP16、int8*int8。但大模型的低比特量化打破了這種對稱性,使乘法的一端是高比特,另一端是低比特,例如在 1-bit 的 BitNet 模型中實現的 int8*int1 或 int8*int2,以及浮點數與整數的混合乘法 FP16*int4。
為了充分發揮低比特量化的優勢,讓硬件設備能夠直接支持混合精度矩陣乘法,確保大模型在端側設備上的高速有效運行,微軟亞洲研究院的研究員們針對現有 CPU、GPU 計算算子和硬件架構進行創新:
- 推出了數據類型編譯器 Ladder,支持各種低精度數據類型的表達和相互轉換,將硬件不支持的數據類型無損轉換為硬件支持的數據類型指令,在傳統計算模式下,使得硬件能夠支持混合精度的 DNN(深度神經網絡) 計算;
- 研發了全新算法 T-MAC,基于查找表(Lookup Table,LUT)的方法,實現了硬件對混合精度矩陣乘法的直接支持,軟件層面,在 CPU 上的計算相比傳統計算模式取得了更好的加速;
- 提出了新的硬件架構 LUT Tensor Core,為下一代人工智能硬件設計打開了新思路。
Ladder:自定義數據類型無損轉換成硬件支持的數據類型
當前,前沿加速器正在將更低比特的計算單元,如 FP32、FP16,甚至 FP8 的運算集成到新一代的架構中。然而,受限于芯片面積和高昂的硬件成本,每個加速器只能為標準的數據類型提供有限類型的計算單元,比如 NVIDIA V100 TENSOR CORE GPU 僅支持 FP16,而 A100 雖然加入了對 int2、int4、int8 的支持,但并未涵蓋更新的 FP8 或 OCP-MXFP 等數據格式。此外,大模型的快速迭代與硬件升級的緩慢步伐之間存在差距,導致許多新數據類型無法得到硬件支持,進而影響大模型的加速和運行。
微軟亞洲研究院的研究員們發現,盡管硬件加速器缺乏針對自定義數據類型的計算指令,但其內存系統可以將它們轉換為固定位寬的不透明數據塊來存儲任意數據類型。同時,大多數自定義數據類型可以無損地轉換為現有硬件計算單元支持的更多位的標準數據類型。例如,NF4 張量可以轉換成 FP16 或 FP32 以執行浮點運算。
基于這些發現,研究員們提出了一種通過分離數據存儲和計算來支持所有自定義數據類型的方法,并研發了數據編譯器 Ladder,以彌合不斷出現的自定義數據類型與當前硬件支持的固有精度格式之間的差距。
Ladder 定義了一套數據類型系統,包括數據類型之間無損轉換的抽象,它能夠表示算法和硬件支持的各種數據類型,并定義了數據類型之間的轉換規則。當處理低比特算法應用時,Ladder 通過一系列優化,將低比特數據轉譯成當前硬件上最高效的執行格式,包括對計算和存儲的優化 —— 將算法映射到匹配的計算指令,并將不同格式的數據存儲到不同級別的存儲單元中,以實現最高效的運算。

圖 1:Ladder 的系統架構
在 NVIDIA A100、NVIDIA V100、NVIDIA RTX A6000、NVIDIA RTX 4090 和 AMD Instinct MI250 GPU 上運行的 DNN 推理性能評估顯示,Ladder 在原生支持數據類型上超越了現有最先進的 DNN 編譯器,并且在支持 GPU 原本不支持的自定義數據類型方面表現出色,最高提速可達 14.6 倍。
Ladder 是首個在現代硬件加速器上運行 DNN 時,可以系統性地支持以自定義數據類型表示低比特精度數據的系統。這為模型研究者提供了更靈活的數據類型優化方法,同時也讓硬件架構開發者在不改變硬件的情況下,支持更廣泛的數據類型。
T-MAC:無需乘法的通用低比特混合精度矩陣乘計算
為了讓現有硬件設備支持不同的數據模式和混合精度矩陣乘法,在端側部署大模型時,常見的做法是對低比特模型進行反量化。然而,這種方法存在兩大問題:首先,從性能角度來看,反量化過程中的轉換開銷可能會抵消低比特量化帶來的性能提升;其次,從開發角度來看,開發者需要針對不同的混合精度重新設計數據布局和計算內核。微軟亞洲研究院的研究員們認為,在設備上部署低比特量化的大模型,關鍵在于如何基于低比特的特點來突破傳統矩陣乘法的實現。
為此,研究員們從系統和算法層面提出了一種基于查找表(LUT,Look-Up Table)的方法 T-MAC,幫助低比特量化的大模型在 CPU 上實現高效推理。T-MAC 的核心思想在于利用混合精度矩陣乘法的一端為極低比特(如 1 比特或 2 比特)的特點。它們的輸出結果只有 2 的 1 次方和 2 的 2 次方種可能,這些較少的輸出結果完全可以提前計算并存儲在表中,在運算時,只需從表中讀取結果,避免了重復計算,大幅減少了乘法和加法的運算次數。
具體而言,T-MAC 將傳統的以數據類型為中心的乘法轉變為基于位的查找表操作,實現了一種統一且可擴展的混合精度矩陣乘法解決方案,減小了表的大小并使其停留在最快的內存單元中,降低了隨機訪問表的成本。這一創新為在資源受限的邊緣設備上部署低比特量化大模型鋪平了道路。

圖 2:T-MAC 示意圖
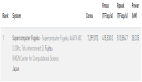
在針對低比特量化的 Llama 和 1 比特的 BitNet 大語言模型的測試中,T-MAC 展現出了顯著的性能優勢。在搭載了最新高通 Snapdragon X Elite 芯片組的 Surface Laptop 7 上,T-MAC 讓 3B BitNet-b1.58 模型的生成速率達到每秒 48 個 token,2bit 7B Llama 模型的生成速率達到每秒 30 個 token,4bit 7B Llama 模型的生成速率可達每秒 20 個 token,這些速率均遠超人類的平均閱讀速度。與原始的 Llama.cpp 框架相比,其提升了 4 至 5 倍,甚至比專用的 NPU 加速器還快兩倍。
即使是在性能較低的設備上,如 Raspberry Pi(樹莓派)5,T-MAC 也能使 3B BitNet-b1.58 模型達到每秒 11 個 token 的生成速率。T-MAC 還具有顯著的功耗優勢,在資源受限的設備上可以達到相同的生成速率,而它所需的核心數僅為原始 Llama.cpp 的 1/4 至 1/6。
這些結果表明,T-MAC 提供了一種實用的解決方案,使得在使用通用 CPU 的邊緣設備上部署大語言模型更為高效,且無需依賴 GPU,讓大模型在資源受限的設備上也能高效運行,從而推動大模型在更廣泛的場景中的應用。
LUT Tensor Core:推動下一代硬件加速器原生支持混合精度矩陣乘法
T-MAC 和 Ladder 都是在現有 CPU 和 GPU 架構上,實現對混合精度矩陣乘法的優化支持。盡管這些軟件層面的創新顯著提升了計算效率,但它們在效率上仍無法與能夠直接實現一個專門查找表的硬件加速器相比。研究員們認為,最理想的方法是重新設計硬件加速器,讓 CPU、GPU 等能夠原生支持混合精度矩陣乘法,但這一目標面臨三大挑戰:
- 效率:設計和實現方式必須具有成本效益,通過優化芯片的利用面積,最大限度地提高低比特數據的計算效益。
- 靈活性:由于不同的模型和場景需要不同的權重和激活精度,因此硬件中的混合精度矩陣乘法設計必須能夠處理各種權重精度 (如 int4/2/1) 和激活精度 (如 FP16/8、int8) 及其組合。
- 兼容性:新設計必須與現有的 GPU 架構和軟件生態系統無縫集成,以加速新技術的應用。
為了應對這些挑戰,微軟亞洲研究院的研究員們設計了 LUT Tensor Core,這是一種利用查找表直接執行混合精度矩陣乘法的 GPU Tensor Core 微架構。一方面,基于查找表的設計將乘法運算簡化為表預計算操作,可直接在表中查找結果,提高計算效率。另一方面,這種方法也簡化了對硬件的需求,它只需用于表存儲的寄存器和用于查找的多路選擇器,無需乘法器和加法器。同時,LUT Tensor Core 通過比特串行設計實現了權重精度的靈活性,并利用表量化實現了激活精度的靈活性。
此外,為了與現有 GPU 微架構和軟件堆棧集成,研究員們擴展了 GPU 中現有的 MMA 指令集,加入了一組 LMMA 指令,并設計了一個類似于 cuBLAS 的軟件堆棧,用于集成到現有的 DNN 框架中。研究員們還設計了一個編譯器,用于在具有 LUT Tensor Core 的 GPU 上進行端到端的執行計劃。這些創新方法可以讓 LUT Tensor Core 被無縫、快速地采用。

圖 3:LUT Tensor Core 微架構概述
在 Llama 和 BitNet 模型上的測試顯示,LUT Tensor Core 可以提供高達 6.93 倍的推理速度,且只占傳統 Tensor Core 面積的 38.7%。在幾乎相同的模型精度下,這相當于 20.7 倍的計算密度和 19.1 倍的能效提升。隨著人工智能大模型規模和復雜性的不斷增長,LUT Tensor Core 有助于進一步釋放低比特大語言模型的潛力,推動人工智能在新場景中的應用。
“查找表方法引領了計算范式的轉變。在過去,我們依賴于矩陣乘法和累加運算,而在大模型時代,得益于低比特量化技術,查找表方法將成為主流。相較于傳統的浮點運算或矩陣乘法,查找表方法在計算上更輕便高效,而且在硬件層面上更易于擴展,能夠實現更高的晶體管密度,在單位芯片面積上提供更大的吞吐量,從而推動硬件架構的革新。” 微軟亞洲研究院首席研究員曹婷表示。
低比特量化的長尾效應:為具身智能帶來新可能
低比特量化技術不僅優化了大模型在端側設備上的運行效率,還通過減少單個參數的 “體積”,為模型參數的擴展(Scale up)提供了新的空間。這種參數擴展能力,使模型擁有了更強的靈活性和表達能力,正如 BitNet 模型所展示的,從低比特模型出發,逐步擴展至更大規模的訓練。
微軟亞洲研究院的 T-MAC、Ladder 和 LUT Tensor Core 等創新技術,為各種低比特量化大模型提供了高效能的運行方案,使得這些模型能夠在各種設備上高效運行,并推動科研人員從低比特角度設計和優化大模型。其中部分技術已經在微軟必應(Bing)搜索及其廣告業務等搜索大模型中發揮作用。隨著對內存和計算資源的降低,低比特大模型在機器人等具身智能系統上的部署也將成為可能,可以使這些設備更好地實現與環境的動態感知和實時交互。
目前,T-MAC 和 Ladder 已經在 GitHub 上開源,歡迎相關研發人員測試應用,與微軟亞洲研究院共同探索人工智能技術的更多可能。