譯者 | 李睿
審校 | 重樓
實時流架構旨在連續地攝入、處理和分析數據,從而實現近乎實時的決策和見解。它們需要具有低延遲,處理高吞吐量數據量,并且在發生故障時具有容錯的能力。具備這些能力面臨的一些挑戰包括:
- 攝入——以高吞吐量從各種數據源、格式和結構中攝入數據,即使在大量數據流爆發期間也是如此。
- 處理——在確保有狀態計算、無序事件和數據延遲到達等復雜情況得到處理的同時,以可擴展和容錯的方式確保恰好一次(Exactly-once)的處理語義。
- 實時分析——在不影響數據完整性或一致性的情況下,對從數據流源頭不斷攝入和處理的新數據實現低延遲的查詢響應。
獨立的技術組件很難滿足所有的需求,這就是實時流架構由多個協同工作的專用工具組成的原因。
一、Apache的Kafka、Flink、Pinot介紹
以下深入了解實時流架構的核心技術——Apache Kafka、Apache Flink和Apache Pinot。
1.Apache Kafka
Apache Kafka是一個分布式流處理平臺,是實時數據管道的中樞神經系統。Apache Kafka的核心是圍繞發布-訂閱架構構建的,生產者將記錄發布到主題,消費者訂閱這些主題來處理記錄。
Apache Kafka架構的關鍵組件包括:
- 代理是存儲數據和服務客戶端的服務器。
- 主題是記錄發送到的類別。
- 分區是并行處理和負載平衡的主題劃分。
- 消費者群體使多個消費者能夠有效地協調和處理記錄。
Kafka是各行業實時數據處理和事件流的理想選擇,其主要功能包括:
- 高吞吐量
- 低延遲
- 容錯性
- 耐用性
- 橫向可擴展性
2.Apache Flink
Apache Flink是一個開源流處理框架,旨在對無界和有界數據流執行有狀態計算。它的架構圍繞分布式數據流引擎,確保應用程序的高效和容錯執行。
Apache Flink的主要功能包括:
- 支持流和批處理
- 通過狀態快照和恢復進行容錯
- 事件時間處理
- 高級窗口功能
Apache Flink集成了各種各樣數據的源和匯——源是Apache Flink處理的輸入數據流,而匯是Apache Flink輸出處理過的數據的目的地。支持的Apache Flink源包括消息代理(例如Apache Kafka)、分布式文件系統(例如HDFS和S3)、數據庫和其他流數據系統。類似地,Apache Flink可以將數據輸出到各種各樣的接收器,包括關系數據庫、NoSQL數據庫和數據湖。
3.Apache Pinot
Apache Pinot是一個實時分布式在線分析處理(OLAP)數據存儲,專為大規模數據流的低延遲分析而設計。Apache Pinot的架構旨在有效地處理批處理數據和流數據,提供即時查詢響應。Apache Pinot擅長對從Kafka等數據流來源獲取的快速變化的數據進行分析查詢。它支持多種數據格式,包括JSON、Avro和Parquet,并通過其分布式查詢引擎提供類似SQL的查詢功能。Pinot的星樹索引支持快速聚合、高效過濾、高維數據和壓縮。
二、Apache 的Kafka、Flink和Pinot集成
以下介紹Apache的Kafka、Flink和Pinot如何協同工作,對流數據進行實時洞察、復雜事件處理和低延遲分析查詢的概述:
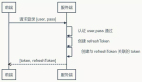
(1)Kafka作為一個分布式流媒體平臺,從各種來源實時攝取數據。它為流數據提供持久、容錯和可擴展的消息隊列。
(2)Flink從Kafka主題中消耗數據流。它對傳入的數據執行實時流處理、轉換和計算。Flink強大的流處理功能支持復雜的操作,例如窗口聚合、有狀態計算和基于事件時間的處理。然后將Flink的處理數據加載到Pinot中。
(3)Pinot攝入數據流,構建實時和離線數據集,并為低延遲分析查詢創建索引。它支持一個類似SQL的查詢接口,并且可以對實時和歷史數據提供高吞吐量和低延遲的查詢。
 圖1 Kafka、Flink和Pinot是實時流架構的組件
圖1 Kafka、Flink和Pinot是實時流架構的組件
以下深入了解各個組件:
1.Kafka攝入
Kafka提供了幾種攝入數據的方法,每種方法都有自己的優點。使用Kafka生產者客戶端是最基本的方法。它提供了一種簡單有效的方法,可以將記錄從各種數據源發布到Kafka主題。開發人員可以通過將生產者客戶端集成到Kafka客戶端庫支持的大多數編程語言(Java、Python等)的應用程序中來利用生產者客戶端。
生產者客戶端處理各種任務,包括通過跨分區分發消息來實現負載平衡。這通過等待Kafka代理的確認來確保消息的持久性,并管理失敗發送嘗試的重試。通過利用壓縮、批處理大小和逗留時間等配置,Kafka生產者客戶端可以針對高吞吐量和低延遲進行優化,使其成為Kafka實時數據攝取的高效可靠工具。
其他選擇包括:
- Kafka Connect是一個可擴展和可靠的數據流工具,具有內置功能,例如偏移管理、數據轉換和容錯。它可以通過源連接器將數據讀入Kafka,也可以通過連接器將數據從Kafka寫入外部系統。
- Debezium在將數據攝入Kafka方面非常受歡迎,它使用源連接器來捕獲數據庫變更(插入、更新、刪除)。它將這些變更發布到Kafka主題中,以實現數據庫的實時更新。
Kafka生態系統也有一套豐富的第三方數據攝取工具。
2.Kafka-Flink集成
Flink提供了一個Kafka連接器,允許它在Kafka主題之間消費和生成數據流。
連接器是Flink分布的一部分,它提供了容錯性和恰好一次的語義。
連接器由兩部分組成:
- KafkaSource允許Flink使用來自一個或多個Kafka主題的數據流。
- KafkaSink允許Flink為一個或多個Kafka主題生成數據流。
以下是一個如何在Flink的數據流API中創建KafkaSource的例子:
Java
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("ad-events-topic")
.setGroupId("ad-events-app")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");需要注意的是,FlinkKafkaConsumer基于遺留的SourceFunction API,已經標記為棄用并已刪除。新的基于數據源的API,包括KafkaSource,對水印生成、有界流(批處理)和動態Kafka主題分區的處理等方面提供了更大的控制。
3.Flink-Pinot集成
有幾個選項可以將Flink與Pinot集成,將處理后的數據寫入Pinot表。
選項1:從Flink到Kafka再到Pinot
這是一個兩個步驟的過程,首先使用Flink Kafka連接器的KafkaSink組件將數據從Flink寫入Kafka。以下是一個示例:
Java
DataStream<String> stream = <existing stream>;
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("ad-events-topic")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);作為第二個步驟的一部分,在Pinot端,需要為Kafka配置實時攝取支持,它將實時攝取數據到Pinot表中。
這種方法解耦了Flink和Pinot,允許獨立擴展它們,并潛在地利用架構中其他基于Kafka的系統或應用程序。
選項2:從Flink到Pinot(直接)
另一種選擇是使用作為Pinot發行版一部分的Flink SinkFunction。這種方法通過將流處理(或批處理)Flink應用程序直接寫入指定的Pinot數據庫來簡化集成。這種方法簡化了管道,因為它消除了中間步驟或額外組件的需要。它確保處理后的數據在Pinot中隨時可用,以實現低延遲查詢和分析。
三、優秀實踐和注意事項
雖然在使用Kafka、Flink和Pinot進行實時流解決方案時需要考慮很多因素,但這里有一些常見的因素。
1.恰好一次(Exactly-once)
恰好一次語義保證即使在出現故障或無序交付的情況下,每條記錄也只處理一次。實現這種行為需要流處理管道中涉及的組件之間的協調。
(1)使用Kafka的冪等設置來保證消息只傳遞一次。這包括在生產者上啟用enable.idempotence設置,并在消費者上使用適當的隔離級別。
(2)Flink的檢查點和偏移跟蹤確保只有處理過的數據被持久化,從而允許從故障中進行一致的恢復。
(3)最后,Pinot的追加功能和唯一的記錄標識符消除了攝入過程中的重復,保持了分析數據集中的數據完整性。
2.Kafka-Pinot直接集成vs.使用Flink
直接集成Kafka和Pinot還是使用Flink作為中間層取決于流處理需求。如果需求涉及最小的流處理、簡單的數據轉換或較低的操作復雜性,可以使用Kafka內置的支持將Kafka與Pinot直接集成,以從Kafka主題中消費數據并將其攝入實時表中。此外,可以在攝入過程中在Pinot中執行簡單的轉換或過濾,從而消除了對專用流處理引擎的需求。
如果用例需要復雜的流處理操作,例如窗口聚合、有狀態計算、基于事件時間的處理或從多個數據源攝取,則建議使用Flink作為中間層。Flink提供強大的流處理API和操作符來處理復雜的場景,提供跨應用程序的可重用處理邏輯,并且可以在將流數據攝取到Pinot之前對流數據執行復雜的提取-轉換-加載(ETL)操作。在具有復雜流需求的場景中,引入Flink作為中間流處理層可能是有益的,但它也增加了操作的復雜性。
3.可擴展性和性能
處理大量數據并確保實時響應需要仔細考慮整個管道的可擴展性和性能。討論最多的兩個方面包括:
(1)可以利用這三個組件固有的水平可擴展性。添加更多Kafka代理來處理數據攝取量,擁有多個Flink應用實例來并行處理任務,并擴展Pinot服務器節點來分配查詢執行。
(2)可以基于常用查詢過濾器對數據進行分區來有效地利用Kafka分區,從而提高Pinot中的查詢性能。通過在工作節點之間均勻分布數據,分區也有利于Flink的并行處理。
4.常用用例
可能正在使用構建在實時流架構之上的解決方案,有些人甚至沒有意識到這一點。以下將介紹幾個常用示例。
(1)實時廣告
現代廣告平臺需要做的不僅僅是提供廣告,還必須處理廣告拍賣、競價和實時決策等復雜流程。一個值得注意的例子是Uber公司的UberEats應用程序,廣告事件處理系統必須以最小的延遲發布結果,同時確保沒有數據丟失或重復。為了滿足這些需求,Uber公司使用Kafka、Flink和Pinot構建了一個系統來實時處理廣告事件流。
該系統依賴于Flink作業通過Kafka主題進行通信,最終用戶數據存儲在Pinot(Apache Hive)中。通過結合Kafka和Flink提供的恰好一次語義、Pinot中的追加功能以及用于重復數據刪除和冪等性的唯一記錄標識符的組合來保持準確性。
(2)面向用戶的分析
當涉及到延遲和吞吐量時,面向用戶的分析有非常嚴格的要求。LinkedIn已經廣泛采用Pinot來支持整個公司的各種實時分析用例。Pinot作為幾個面向用戶的產品特性的后端,包括“誰查看了我的個人資料”。Pinot支持對大量數據集的低延遲查詢,允許LinkedIn為其成員提供高度個性化和最新的體驗。除了面向用戶的應用程序,Pinot還被用于LinkedIn的內部分析,并為各種內部儀表板和監控工具提供支持,使團隊能夠實時了解平臺性能、用戶參與度和其他運營指標。
(3)欺詐檢測
對于欺詐檢測和風險管理場景,Kafka可以攝入與交易數據、用戶活動和設備信息相關的實時數據流。Flink的管道可以應用模式檢測、異常檢測、基于規則的欺詐檢測和數據豐富等技術。Flink的有狀態處理能力能夠在數據流經管道時維護和更新用戶或事務級狀態。處理后的數據,包括標記的欺詐活動或風險評分,然后轉發給Pinot。
風險管理團隊和欺詐分析師可以在Pinot實時數據的基礎上執行臨時查詢或構建交互式儀表板。這可以識別高風險用戶或交易,分析欺詐活動的模式和趨勢,監控實時欺詐指標和KPI,并調查標記為潛在欺詐的特定用戶或交易的歷史數據。
結論
Kafka的分布式流平臺支持高吞吐量的數據攝取,而Flink的流處理能力允許復雜的轉換和有狀態的計算。最后,Pinot的實時OLAP數據存儲促進了低延遲的分析查詢,使組合解決方案成為需要實時決策和見解的用例的理想選擇。
雖然Kafka、Flink和Pinot等單個組件非常強大,但在云計算和內部部署之間大規模管理它們在操作上可能很復雜。托管流媒體平臺減少了操作開銷,并抽象出許多低級集群配置、配置、監控和其他操作任務。它們允許根據不斷變化的工作負載需求彈性地增加或減少資源配置。這些平臺還為關鍵功能提供集成工具,例如跨所有組件監視、調試和測試流應用程序。
要了解更多信息,可以參閱Apache Kafka、Apache Flink和Apache Pinot的官方文檔和示例。圍繞這些項目的社區也有豐富的資源,包括書籍、教程和技術講座,涵蓋了現實世界的用例和最佳實踐。
額外的資源:
- Apache Kafka Patterns and Anti-Patterns by Abhishek Gupta, DZone Refcard
- Apache Kafka Essentials by Sudip Sengupta, DZone Refcard
原文標題:Real-Time Streaming Architectures: A Technical Deep Dive Into Kafka, Flink, and Pinot,作者:Abhishek Gupta