













集成大語言模型與產(chǎn)業(yè)數(shù)據(jù)智能,邁向“產(chǎn)業(yè)基礎模型”
編者按:隨著數(shù)據(jù)量和模型規(guī)模的增加,大語言模型在指令執(zhí)行、知識存儲、邏輯推理和編程技能等方面展現(xiàn)出了突破性的能力。然而,大語言模型在產(chǎn)業(yè)領(lǐng)域的潛能尚未得到充分挖掘,特別是在滿足產(chǎn)業(yè)數(shù)據(jù)分析、推理、預測、決策等數(shù)據(jù)智能需求方面。如何有效地變革各行業(yè)的數(shù)據(jù)模型及智能的構(gòu)建方法與應用范式,仍然面臨諸多挑戰(zhàn)。為應對這些挑戰(zhàn),微軟亞洲研究院提出了構(gòu)建產(chǎn)業(yè)基礎模型的倡議,其核心理念在于通過持續(xù)預訓練,將產(chǎn)業(yè)數(shù)據(jù)智能相關(guān)的知識與技能融入到大語言模型中。基于這一理念,微軟亞洲研究院開發(fā)了生成式表數(shù)據(jù)學習(Generative Tabular Learning,GTL)框架,展示了如何在表數(shù)據(jù)這一廣泛使用的數(shù)據(jù)表征上,構(gòu)建具有跨行業(yè)、跨數(shù)據(jù)模式、跨任務的產(chǎn)業(yè)基礎模型。
盡管大語言模在新聞撰寫、文檔總結(jié)、客服助理和虛擬助手等以語言為中心的任務上表現(xiàn)出色,但在深入理解和處理特定的行業(yè)數(shù)據(jù)時仍存在局限。為了應對大模型在產(chǎn)業(yè)界應用中所面臨的挑戰(zhàn),微軟亞洲研究院提出了構(gòu)建產(chǎn)業(yè)基礎模型(Industrial Foundation Models)的創(chuàng)新思路,并在表數(shù)據(jù)上成功驗證了實現(xiàn)跨領(lǐng)域通用數(shù)據(jù)智能的可行性及其巨大潛力。研究員們設計的生成式表數(shù)據(jù)學習(Generative Tabular Learning,GTL)框架,成功地將多行業(yè)數(shù)據(jù)智能相關(guān)的知識融入大語言模型中,使其具備在新領(lǐng)域、新數(shù)據(jù)及新任務上的直接遷移和泛化能力,更加敏捷地響應不同的產(chǎn)業(yè)需求。現(xiàn)在,微軟亞洲研究院正式開源這一技術(shù)范式,并希望通過此范式推動數(shù)據(jù)科學在各行業(yè)中的廣泛應用,促使復雜的數(shù)據(jù)智能技術(shù)變得人人可及。
項目鏈接:https://github.com/microsoft/Industrial-Foundation-Models
相關(guān)論文:From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models(已收錄于KDD 2024)
https://arxiv.org/abs/2310.07338
產(chǎn)業(yè)數(shù)據(jù)的巨大潛力亟待挖掘
微軟亞洲研究院的研究員們發(fā)現(xiàn),大語言模型在利用產(chǎn)業(yè)數(shù)據(jù)這一關(guān)鍵資源方面,尚未充分發(fā)揮其潛力。產(chǎn)業(yè)數(shù)據(jù)通常以特定結(jié)構(gòu)存儲在不同行業(yè)和部門的數(shù)據(jù)倉庫中,比如用于關(guān)系結(jié)構(gòu)的表數(shù)據(jù)、記錄時變信號的時間序列數(shù)據(jù),以及用于復雜相互關(guān)聯(lián)的圖數(shù)據(jù)。這些結(jié)構(gòu)中蘊含的豐富數(shù)據(jù)知識往往難以通過自然語言捕捉,因此當前以語義知識為核心的大語言模型在掌握數(shù)據(jù)智能相關(guān)的知識與能力方面存在不足。
更重要的是,產(chǎn)業(yè)數(shù)據(jù)及其蘊含的智能,為多個領(lǐng)域的重要應用奠定了基礎。這種智能不僅來源于數(shù)值和結(jié)構(gòu)化信息,還包括特定任務的需求和領(lǐng)域?qū)S兄R。例如,在醫(yī)療健康領(lǐng)域,來自患者的基本信息、生理信號和治療歷史的數(shù)據(jù),可用于輔助精確診斷和預后分析。在能源存儲領(lǐng)域,分析電池循環(huán)數(shù)據(jù)中的模式,可以加速材料篩選、優(yōu)化充放電協(xié)議、指導電池回收中的價值評估。在商業(yè)領(lǐng)域,歷史銷售和需求數(shù)據(jù)可以輔助預測未來的市場趨勢并制定定價策略。傳統(tǒng)的數(shù)據(jù)智能方法通常依賴于特定的數(shù)據(jù)模式與任務需求,具體表現(xiàn)為各個垂直領(lǐng)域中獨立開發(fā)及優(yōu)化的小模型。
為應對這些挑戰(zhàn)與機遇,微軟亞洲研究院提出構(gòu)建產(chǎn)業(yè)基礎模型的新思路。其核心策略是以統(tǒng)一的方式表征產(chǎn)業(yè)數(shù)據(jù),并在此基礎上對大語言模型進行持續(xù)預訓練,從而將通用的數(shù)據(jù)智能知識與能力整合到大語言模型中,創(chuàng)造出在新場景上可直接應用的產(chǎn)業(yè)基礎模型。這種模型不僅能夠在各行業(yè)部門中執(zhí)行以語言指令為中心的任務,還可以提取跨任務和跨部門的產(chǎn)業(yè)知識,并進行數(shù)據(jù)驅(qū)動的預測和邏輯推理。
此外,通過提供一個以語言為中心、無需參數(shù)調(diào)優(yōu)和編寫代碼的用戶界面,產(chǎn)業(yè)基礎模型還有潛力改變傳統(tǒng)的數(shù)據(jù)科學應用范式。這個用戶友好的界面將使各行業(yè)的領(lǐng)域?qū)<揖邆淙娴臄?shù)據(jù)科學技能,推動先進數(shù)據(jù)分析技術(shù)的普及。
同時,產(chǎn)業(yè)基礎模型強大的跨領(lǐng)域能力,也使其能夠有效地進行知識遷移與技能泛化。這對在數(shù)據(jù)有限的領(lǐng)域進行有效地少樣本上下文學習尤為關(guān)鍵。
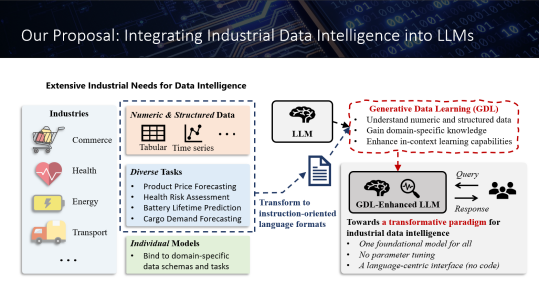
圖1 :產(chǎn)業(yè)基礎模型的架構(gòu)概覽
基于表數(shù)據(jù)開發(fā)產(chǎn)業(yè)基礎模型
表數(shù)據(jù)(Tabular Data)通常存儲于關(guān)系型數(shù)據(jù)庫中,是眾多產(chǎn)業(yè)領(lǐng)域中最普遍的數(shù)據(jù)格式之一,也是預測建模的基礎。因此,微軟亞洲研究院的研究員們從表數(shù)據(jù)著手,構(gòu)建能夠橫跨不同產(chǎn)業(yè)領(lǐng)域的基礎模型。
研究員們收集了來自不同產(chǎn)業(yè)領(lǐng)域的各種表數(shù)據(jù)集及其相應的預測任務,并將這些數(shù)據(jù)轉(zhuǎn)換為面向指令的語言格式。這種轉(zhuǎn)換使得大語言模型能夠適應多樣化的數(shù)據(jù)模式,例如不同特征的語義和數(shù)值含義,支持數(shù)值和類別特征的任意組合。此外,通過將大語言模型與數(shù)據(jù)樣本及可選的背景信息結(jié)合,模型不僅能夠處理回歸和分類任務,還能夠支持零樣本(Zero-Shot)學習和少樣本上下文學習(In-Context Learning)的場景。
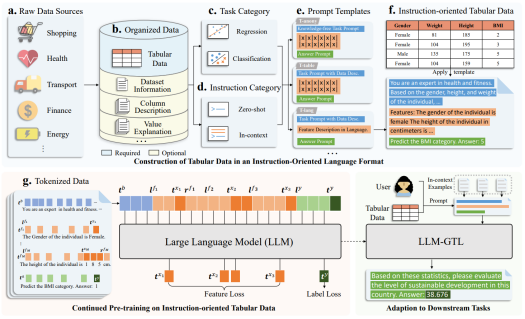
圖 2 :基于表數(shù)據(jù)的產(chǎn)業(yè)基礎模型開發(fā)流程
然而,將大語言模型的語言處理能力融入表數(shù)據(jù)的學習中仍面臨巨大的挑戰(zhàn)。最主要的問題在于,大語言模型通常在自然語言數(shù)據(jù)上進行預訓練,因此在處理格式化表數(shù)據(jù)的精細差別時顯得力不從心,并且缺乏對特定領(lǐng)域知識的深入理解,而這些知識對于有效的表數(shù)據(jù)學習至關(guān)重要。
為了解決這些挑戰(zhàn),研究員們引入了一個持續(xù)預訓練階段,即生成式表數(shù)據(jù)學習(Generative Tabular Learning,GTL)。通過對特征和標簽標記進行自回歸式生成建模,GTL框架可以將數(shù)據(jù)知識與統(tǒng)計學習能力有效整合到大語言模型中。經(jīng)過GTL框架增強的大語言模型,可以通過調(diào)整指令提示,直接應用于新的產(chǎn)業(yè)數(shù)據(jù)和任務需求。這意味著,模型能夠在無需復雜參數(shù)調(diào)優(yōu)的情況下,實現(xiàn)高效的數(shù)據(jù)處理,并且在不同領(lǐng)域知識、數(shù)據(jù)模式和任務之間進行廣泛遷移,從而推動大語言模型向產(chǎn)業(yè)模型的方向進化。
實驗結(jié)果:GTL顯著增強了LLaMA模型對表數(shù)據(jù)的理解能力
為了驗證GTL的有效性,研究員們收集了來自超過400個不同領(lǐng)域的表數(shù)據(jù)集,經(jīng)過嚴格的去重過濾和篩選,最終保留了384個獨立的數(shù)據(jù)集。其中,44個數(shù)據(jù)集被用于模型評估,其余的數(shù)據(jù)集用于構(gòu)建1000多個不同的預測任務,以支持GTL的持續(xù)預訓練。研究員們選擇LLaMA 2作為基礎大語言模型,并將其與開源和私有的大語言模型,以及傳統(tǒng)表數(shù)據(jù)機器學習算法進行了比較。
如圖3所示,實驗結(jié)果表明,GTL顯著增強了LLaMA模型對表數(shù)據(jù)的理解能力。這表明,表數(shù)據(jù)中所蘊含的行業(yè)知識尚未被開源的LLaMA模型充分掌握,而GTL則有效彌補了純語言數(shù)據(jù)訓練出的語言模型在產(chǎn)業(yè)數(shù)據(jù)智能上的不足。值得一提的是,盡管GTL增強的LLaMA模型參數(shù)規(guī)模較小,但其性能與GPT-4等更大規(guī)模的模型相比仍具有競爭力,甚至在某些情況下表現(xiàn)更為優(yōu)異。不過需要注意的是,與GPT-4在公開表數(shù)據(jù)上的對比結(jié)果可能因其私有訓練數(shù)據(jù)中潛在的“數(shù)據(jù)污染”問題而產(chǎn)生偏差。
此外,GTL增強的LLaMA模型不僅在少樣本學習場景中通過無須調(diào)參的上下文學習,超越了傳統(tǒng)表數(shù)據(jù)機器學習方法的統(tǒng)計學習能力,還具備了這些方法所缺乏的零樣本學習能力。
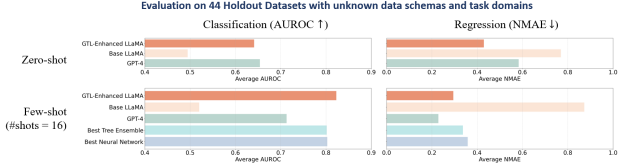
圖3: GTL增強的LLaMA-2-13B與其他基線模型的對比
研究員們還初步探究了GTL的規(guī)模定律。如圖4所示,數(shù)據(jù)的多樣性和模型參數(shù)規(guī)模都以冪律方式提升了新數(shù)據(jù)和新任務上的性能。這一發(fā)現(xiàn)表明了產(chǎn)業(yè)基礎模型在跨多樣任務和領(lǐng)域的廣泛泛化潛力,有望使復雜的數(shù)據(jù)智能技術(shù)變得更加普及,即便在數(shù)據(jù)可得性有限的行業(yè)中也能發(fā)揮重要作用。
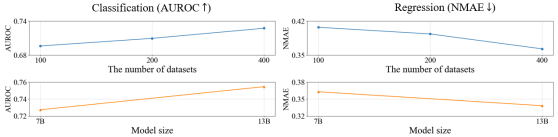
圖4:初探GTL的規(guī)模定律
多維度拓展產(chǎn)業(yè)基礎模型的潛力
生成式表數(shù)據(jù)學習(GTL)為會話式表數(shù)據(jù)深度學習打開了大門,使用戶能夠通過與模型對話來實現(xiàn)數(shù)據(jù)智能相關(guān)的分析、預測、推理和決策。通過將GTL與語言模型集成,模型不僅能夠生成預測結(jié)果,還可以提供對相應結(jié)果的解釋,從而為表數(shù)據(jù)學習的可解釋性帶來了新的機遇。基于這一范式所展現(xiàn)出的巨大潛力,微軟亞洲研究院從兩個角度展望了產(chǎn)業(yè)基礎模型未來的研究和應用前景。
首先,產(chǎn)業(yè)基礎模型本身的多維度擴展蘊含著巨大的潛力。這包括擴展數(shù)據(jù)集的種類和規(guī)模、增加模型規(guī)模、延長上下文長度,以及整合多樣化的數(shù)據(jù)格式,如時間序列和圖數(shù)據(jù)等。全面的擴展將使產(chǎn)業(yè)基礎模型能夠以更高的精度和更強的適應性,處理更多領(lǐng)域的更廣泛任務。同時,產(chǎn)業(yè)數(shù)據(jù)知識與大語言模型生態(tài)系統(tǒng)的前沿進展相結(jié)合,如工具使用、智能體和對話交互,將進一步拓展產(chǎn)業(yè)基礎模型的能力邊界。這種協(xié)同作用可以打造更魯棒和多功能的模型,將產(chǎn)業(yè)數(shù)據(jù)智能與大語言模型的復雜功能無縫融合。
其次,從用戶視角來看,產(chǎn)業(yè)基礎模型的發(fā)展將徹底革新產(chǎn)業(yè)數(shù)據(jù)智能的實現(xiàn)方式,重新定義數(shù)據(jù)科學的用戶界面和工具鏈,進而催生出創(chuàng)新性的產(chǎn)品和服務。例如,領(lǐng)域?qū)<覠o需掌握深厚的編程和數(shù)據(jù)科學知識,即可借助數(shù)據(jù)科學助手獲得先進的數(shù)據(jù)分析和預測能力,從而推動前沿數(shù)據(jù)科學工具的普及。另外,產(chǎn)業(yè)基礎模型可以作為決策支持工具,為行業(yè)領(lǐng)導者和從業(yè)者提供深刻的數(shù)據(jù)洞察和個性化分析,幫助企業(yè)做出更明智的戰(zhàn)略決策,優(yōu)化運營流程,并發(fā)掘新的增長機遇。
將大語言模型與產(chǎn)業(yè)數(shù)據(jù)智能相結(jié)合,是邁向產(chǎn)業(yè)基礎模型的關(guān)鍵一步。通過持續(xù)擴展和創(chuàng)新,創(chuàng)建以用戶為中心的工具,使前沿的數(shù)據(jù)智能技術(shù)更易于獲取,能夠釋放出產(chǎn)業(yè)基礎模型在各個行業(yè)中的更多潛能。微軟亞洲研究院將持續(xù)推動這一進程,不斷突破界限,讓前沿的數(shù)據(jù)智能技術(shù)惠及更多的行業(yè)領(lǐng)域。
相關(guān)鏈接:
論文:From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models(已收錄于KDD 2024)
https://arxiv.org/abs/2310.07338
項目:https://github.com/microsoft/Industrial-Foundation-Models

















