














譯者 | 布加迪
審校 | 重樓
ChatGPT和Bard等大語言模型(LLM)的興起已極大地改變了許多人的工作、交流和學習方式,這已不是什么秘密。但除了取代搜索引擎外,LLM還有其他應用。最近,數據科學家已重新改造LLM用于時間序列預測。
時間序列數據在從金融市場到氣候科學的各個領域無處不在。在人工智能進步的推動下,LLM 正在徹底改變我們處理和生成人類語言的方式。本文深入研究時間序列語言模型如何提供創新的預測和異常檢測模型。
什么是時間序列模型?
大體上說,時間序列語言模型被重新改造后用于處理時間序列數據,而不是處理文本、視頻或圖像數據。它們將傳統時間序列分析方法的優點與語言模型的高級預測功能相結合。當數據與預測或預期結果有明顯偏差時,可以使用強大的預測來檢測異常。時間序列語言模型和傳統LLM之間的一些顯著差異如下:
- 數據類型和訓練:ChatGPT 之類的傳統 LLM 用文本數據進行訓練,但時間序列語言模型用連續的數值數據進行訓練。具體來說,預訓練針對大型、多樣化的時間序列數據集(實際數據集和合成數據集)進行,這使模型能夠很好地適用于不同的領域和應用。
- 詞元化:時間序列語言模型將數據分解為塊而不是文本詞元(塊是指時間序列數據的連續段、塊或窗口)。
- 輸出生成:時間序列語言模型生成未來數據點的序列,而不是單詞或句子。
- 架構調整:時間序列語言模型結合特定的設計選擇來處理時間序列數據的時間特性,比如可變上下文和范圍長度。
與分析和預測時間序列數據的傳統方法相比,時間序列語言模型具有多個顯著優勢。不像ARIMA 等傳統方法通常需要廣泛的領域專業知識和手動調整,時間序列語言模型則利用先進的機器學習技術自動從數據中學習。這使得它們在傳統模型可能不盡如人意的眾多應用領域成為強大且多功能的工具。
- 零樣本性能:時間序列語言模型可以對未見過的新數據集進行準確預測,而無需額外的訓練或微調。這尤其適用于新數據頻繁出現的快速變化的環境。零樣本方法意味著用戶不必花費大量資源或時間來訓練模型。
- 復雜模式處理:時間序列語言模型可以捕獲數據中復雜的非線性關系和模式,ARIMA 或 GARCH等傳統的統計模型可能發現不了這些關系和模式,尤其是對于未見過或未預處理的數據。此外,調整統計模型可能很棘手,需要深厚的領域專業知識。
- 效率:時間序列語言模型并行處理數據。與通常按順序處理數據的傳統模型相比,這大大縮短了訓練和推理時間。此外,它們可以在單單一個步驟中預測更長序列的未來數據點,從而減少所需的迭代步驟數。
時間序列語言模型的實際運用
一些用于預測和預測分析的最流行的時間序列語言模型包括:谷歌的TimesFM、IBM的TinyTimeMixer和AutoLab的MOMENT。
谷歌的TimesFM可能最容易使用。使用pip安裝它,初始化模型,并加載檢查點。然后,你可以對輸入數組或Pandas DataFrames執行預測。比如:
<span style="font-weight: 400;">```python</span>
import pandas as pd
# e.g. input_df is
# unique_id ds y
# 0 T1 1975-12-31 697458.0
# 1 T1 1976-01-31 1187650.0
# 2 T1 1976-02-29 1069690.0
# 3 T1 1976-03-31 1078430.0
# 4 T1 1976-04-30 1059910.0
# ... ... ... ...
# 8175 T99 1986-01-31 602.0
# 8176 T99 1986-02-28 684.0
# 8177 T99 1986-03-31 818.0
# 8178 T99 1986-04-30 836.0
# 8179 T99 1986-05-31 878.0
forecast_df = tfm.forecast_on_df(
inputs=input_df,
freq="M", # monthly
value_name="y",
num_jobs=-1,
)谷歌的TimesFM還支持微調和協變量支持,這是指模型能夠結合和利用額外的解釋變量(協變量)以及主要時間序列數據,以提高預測的準確性和穩健性。你可以在此論文(https://arxiv.org/pdf/2310.10688)中詳細了解谷歌的TimesFM工作原理。
IBM的TinyTimeMixer包含用于對多變量時間序列數據執行各種預測的模型和示例。此筆記本(https://github.com/ibm-granite/granite-tsfm/blob/main/notebooks/hfdemo/ttm_getting_started.ipynb)重點介紹了如何使用TTM(TinyTimMixer)對數據執行零樣本預測和少樣本預測。下面的屏幕截圖顯示了TTM生成的一些估計值:
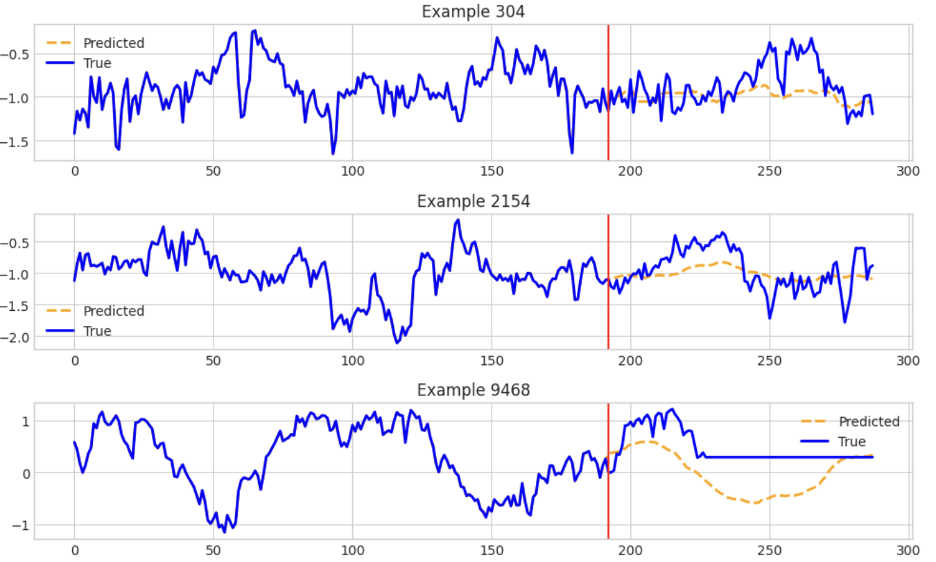
最后,AutoLab的MOMENT擁有預測和異常檢測方法,并附有一目了然的示例。它擅長長范圍預測。舉例來說,該筆記本表明了如何通過先導入模型來預測單變量時間序列數據:
```python
from momentum import MOMENTPipeline
model = MOMENTPipeline.from_pretrained(
"AutonLab/MOMENT-1-large",
model_kwargs={
'task_name': 'forecasting',
'forecast_horizon': 192,
'head_dropout': 0.1,
'weight_decay': 0,
'freeze_encoder': True, # Freeze the patch embedding layer
'freeze_embedder': True, # Freeze the transformer encoder
'freeze_head': False, # The linear forecasting head must be trained
},
)
```下一步是使用你的數據訓練模型進行正確的初始化。在每個訓練輪次之后,都會針對測試數據集評估模型。在評估循環中,模型使用output = model(timeseries, input_mask) 這一行進行預測。
```python
while cur_epoch < max_epoch:
losses = []
for timeseries, forecast, input_mask in tqdm(train_loader, total=len(train_loader)):
# Move the data to the GPU
timeseries = timeseries.float().to(device)
input_mask = input_mask.to(device)
forecast = forecast.float().to(device)
with torch.cuda.amp.autocast():
output = model(timeseries, input_mask)
```結語
時間序列語言模型是預測分析領域的重大進步,它們將深度學習的強大功能與時間序列預測的復雜需求結合在一起。它們能夠執行零樣本學習、整合協變量支持,并高效處理大量數據,這使它們成為各行各業的革命性工具。隨著我們見證這一領域的快速發展,時間序列 語言模型的潛在應用和優勢只會不斷擴大。
若要存儲時間序列數據,請查看領先的時間序列數據庫InfluxDB Cloud 3.0。你可以利用InfluxDB v3 Python客戶端庫和InfluxDB來存儲和查詢時間序列數據,并運用時間序列LLM進行預測和異常檢測。你可以查看下列資源開始上手:
- 客戶端庫深度探究:Python(第 1 部分):https://www.influxdata.com/blog/client-library-deep-dive-python-part-1/
- 客戶端庫深度探究:Python(第 2 部分):https://www.influxdata.com/blog/client-library-deep-dive-python-part-2/
原文標題:Transform Predictive Analytics With Time Series Language Models,作者:Anais Dotis-Georgiou
























