













大模型 LLM.int8() 量化技術原理與代碼實現
大語言模型LLM因其龐大的參數規模,往往難以在消費級硬件上直接運行。這些模型的參數量可能達到數十億級別(主要是權重),這些參數不僅存儲成本高,推理階段的計算量也很大。通常需要顯存較大的GPU來加速推理過程。
因此,越來越多的研究開始關注如何縮小模型,比如改進訓練方法或引入適配器模塊。其中一項關鍵技術便是量化(quantization)。
本文將深入探討量化的基本原理,介紹LLM.int8()大模型量化方法,并通過具體的代碼實戰來展示如何實現模型的量化,以便在各種設備上高效運行這些模型。

基礎知識
1.數值表示
模型推理過程中,激活值是輸入和權重之積,因此權重數量越多,激活值也會越大。

因此,我們需要盡可能高效表示數十億個值,從而盡可能減少存儲參數所需的空間。
大語言模型中參數數值,通常被表示為浮點數。浮點數(floating-point numbers,簡稱 floats)是一種用于表示帶有小數點的正數或負數的數據類型。
在計算機科學中,浮點數通常遵循IEEE-754標準進行存儲。這一標準定義了浮點數的結構,包括符號位、指數位和尾數位三個組成部分。其中,
- 符號位(Sign Bit):決定了浮點數的正負。
- 指數位(Exponent Bits):表示浮點數的指數部分。
- 尾數位(Fraction Bits):表示小數點后的數值部分。

三部分結合起來,即可根據一組bit值計算出所表示的數值。使用的位數越多,表示的數值值通常越精確。
- 半精度浮點數(Half-Precision Floats, FP16):使用16位來表示一個浮點數,其中包括1位符號位、5位指數位和10位尾數位。
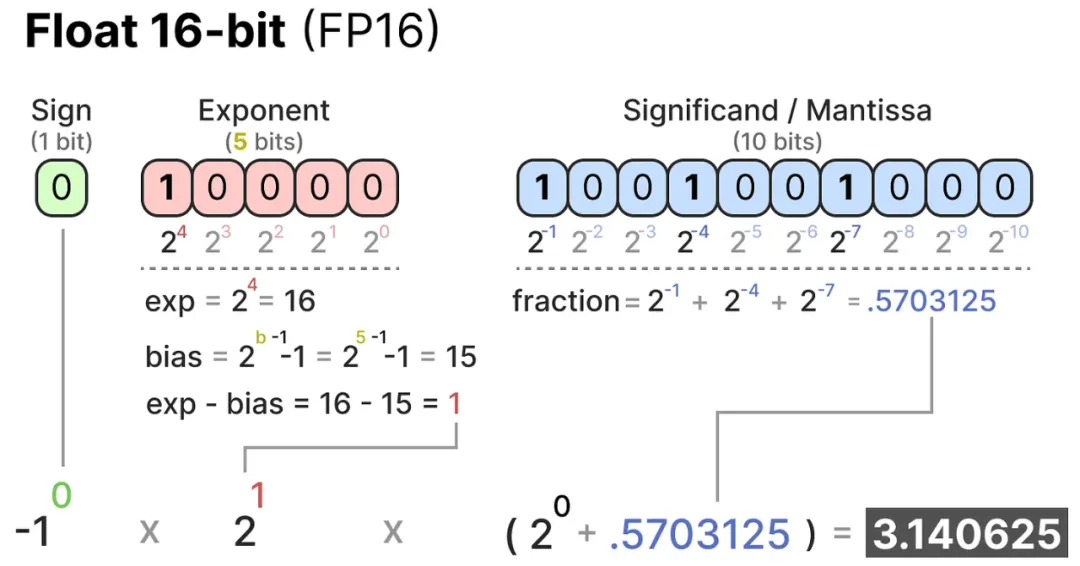
- 單精度浮點數(Single-Precision Floats, FP32):使用32位來表示一個浮點數,其中包括1位符號位、8位指數位和23位尾數位。

2.動態范圍與精度
動態范圍(Dynamic Range):指的是可表示的最大值與最小值之間的范圍。可用的位數越多,動態范圍也就越廣。
精度(Precision):指兩個相鄰可表示值之間的差距。可用的位數越多,精度也就越高。

對于給定的浮點數表示形式,我們可以計算出存儲特定數值所需的內存大小。例如,對于32位浮點數(FP32),每個數值占用4字節(8位/字節),而對于16位浮點數(FP16),每個數值占用2字節。
假設模型有N個參數,每個參數使用B位表示,則模型的內存需求(以字節為單位)可以用以下公式計算:
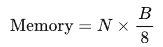
在實際應用中,除了模型本身的參數外,推理過程中的內存/顯存需求還受到其他因素的影響,例如:
- 上下文大小:對于序列模型而言,處理的序列長度會影響內存需求。
- 模型架構:不同的模型架構可能會有不同的內存使用模式。
對于一個包含700億參數的模型,如果使用32位浮點數表示,所需的內存為:
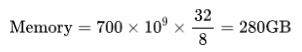
如果改為使用16位浮點數表示,所需的內存將減少一半:

由此可見,將模型參數的表示位數最小化,即量化(不僅是推理,還有訓練過程)能夠顯著減少內存需求,但這也意味著精度的降低,可能會對模型的準確性產生負面影響。
「因此,量化技術的目標是在保持模型準確性的同時盡可能減少表示數值所需的位數。」
二、什么是模型量化?
所謂模型量化,其實就是將模型參數的精度從較高位寬(如FP16、FP32、BF16,一般是浮點運算)轉換為較低位寬(如Int8、Int4,一般是整數運算),從而降低模型存儲大小及顯存占用、提升推理性能。

三、量化分類
模型量化可從以下幾方面分類:
(1) 根據量化時機
- 訓練時量化(Quantization-Aware Training, QAT),需要模型重新訓練。
- 訓練后量化(Post Training Quantization,PTQ),可以量化預訓練好的模型。不需要重新訓練。
(2) 根據映射函數是否為線性
- 線性量化
- 非線性量化
(3) 根據量化的粒度(共享量化參數的范圍)
- Tensor粒度(per-tensor):整個矩陣一起量化。
- Token粒度(per-token)和Channel粒度(per-channel):每行/每列單獨量化,X的每一行代表一個Token,W的每一列代表一個Channel。
- Group粒度(per-group):兩者的折衷,多行/多列分為一組,每組分別量化。
(4) 根據量化范圍
- 只量化權重(Weight Only):只量化模型權重,推理時是INT乘FLOAT。
- 權重與激活同時量化(Weight and Activation):這里的激活實際是就是每一層的輸入,對于矩陣乘法Y = WX,同時量化W和X,推理時是INT乘INT。
目前Weight and Activation可以做到Int8(或者叫W8A8,Weight 8bit Activition 8bit)與FP16水平相當,而Weight Only方向INT4(W4A16)已經可以做到與FP16相差無幾,INT3(W3A16)也很接近了。實際上,這兩個方向并不是互斥的,我們完全可以同時應用兩種方式,只是工程比較復雜,暫時還沒有成熟的框架。
?
(5) 根據存儲一個權重元素所需的位數
- 8bit量化
- 4bit量化
- 2bit量化
- 1bit量化
四、量化方案
1.LLM.int8()
(1) LLM.int8()量化算法
INT8量化的基本思想是將浮點數 通過縮放因子scale映射到范圍在[-128, 127]內的8位整數表示
通過縮放因子scale映射到范圍在[-128, 127]內的8位整數表示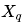 。
。
量化公式如下:

其中:
- Xq表示量化后的整數。
- Xf表示量化前的浮點數。
- scale表示縮放因子。
- Round 表示四舍五入為整數。
- Clip表示將結果截斷到[-128, 127]范圍內。
縮放因子scale的計算公式:
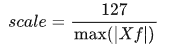
其中, 表示浮點數最大絕對值。
表示浮點數最大絕對值。
反量化的過程為:

如下圖所示為通過該方式實現量化-反量化的示例。假設使用absmax quantization技術對向量[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]進行量化。首先找到絕對值最大值5.4。Int8的取值范圍是[-127, 127],所以量化因子為127/5.4=23.5。因此向量會被量化成[28, -12, -101, 28, -73, 19, 56, 127]。

為了還原原始值,可以使用全精度的int8數值除以量化因子23.5。但是它們在量化過程中是四舍五入取整過的,會損失一些精度。
為了不區分int8格式的正負符號,我們需要減去最小值,然后再使用最大值作為量化因子。具體實現如下:
對于給定的向量或矩陣,首先找到最小值 ,并減去最小值:
,并減去最小值:

找到X'的絕對最大值 ,使用絕對最大值作為量化因子:
,使用絕對最大值作為量化因子:

這類似于zero-point量化,但不同之處在于,zero-point量化會確保全精度數值0仍然轉換為整數0,從而在數值0處保證不會有量化損失。
LLM.int8()算法的具體步驟:
- 從矩陣隱藏層中,以列為單位,抽取值大于確定閾值的異常值(outliers)。
- 分別通過FP16精度對outliers的部分做矩陣乘法,通過量化int8精度對其他的做矩陣乘法。
- 將量化的部分恢復成FP16,然后將兩部分合在一起。

「為什么要單獨抽出異常值(outliers)?」
在大規模模型中,數值超出全局閾值范圍的被稱為outliers。8位精度的數據是壓縮的,因此量化一個含有幾個大數值的向量會導致大量錯誤的結果。例如,如果一個向量中有幾個數值遠大于其他數值,那么量化這些數值會導致其他數值被壓縮到零,從而產生較大的誤差。
Transformer 架構的模型會將所有的內置特征連接組合在一起。因此,這些量化錯誤會在多層網絡的傳播中逐步混合在一起,導致整體性能的下降。
為了解決這些問題,混合精度量化技術應運而生。這種技術將大數值的特征拆分出來,進行更有效的量化和混合精度計算。
(2) LLM.int8()量化實現
如下是在Transformers庫中集成nuances庫,利用bitsandbytes庫提供的8位量化功能,將模型轉換為int8精度。
第一步:導入庫
import torch
import torch.nn as nn
import bitsandbytes as bnb
from bnb.nn import Linear8bitLt在自己的數據集和任務上訓練模型了,最后保存模型定義自己的模型。可以從任何精度(FP16,BF16,FP32)轉換至int8。但模型的輸入需要是FP16精度。所以下面為FP16精度的模型。
fp16_model = nn.Sequential(
nn.Linear(64, 64),
nn.Linear(64, 64)
)第三步:在自己的數據集和任務上訓練模型,最后保存模型
# 訓練模型
[... train the model ...]
# 保存模型
torch.save(fp16_model.state_dict(), "model.pt")第四步:定義一個int8精度的模型。
int8_model = nn.Sequential(
Linear8bitLt(64, 64, has_fp16_weights=False),
Linear8bitLt(64, 64, has_fp16_weights=False)
)這里加入has_fp16_weights的參數是很重要的。因為它默認會被設置為True,這意味著它會被作為Int8/FP16混合精度訓練。然而,我們關心的是use has_fp16_weights=False時的計算內存占用。
第五步:加載模型并量化至int8精度。
int8_model.load_state_dict(torch.load("model.pt"))
int8_model = int8_model.to(0) # 量化int8_model = int8_model.to(0) 將模型存入顯卡,會執行量化。
如果在其之前打印int8_model[0]的權重,可得到FP16的精度值。
print("Before quantization:")
print(int8_model[0].weight)
Parameter containing:
tensor([[ 0.0031, -0.0438, 0.0494, ..., -0.0046, -0.0410, 0.0436],
[-0.1013, 0.0394, 0.0787, ..., 0.0986, 0.0595, 0.0162],
[-0.0859, -0.1227, -0.1209, ..., 0.1158, 0.0186, -0.0530],
...,
[ 0.0804, 0.0725, 0.0638, ..., -0.0487, -0.0524, -0.1076],
[-0.0200, -0.0406, 0.0663, ..., 0.0123, 0.0551, -0.0121],
[-0.0041, 0.0865, -0.0013, ..., -0.0427, -0.0764, 0.1189]],
dtype=torch.float16)如果在其之后打印int8_model[0]的權重,可得到INT8的精度值。
print("After quantization:")
print(int8_model[0].weight)
Parameter containing:
tensor([[ 3, -47, 54, ..., -5, -44, 47],
[-104, 40, 81, ..., 101, 61, 17],
[ -89, -127, -125, ..., 120, 19, -55],
...,
[ 82, 74, 65, ..., -49, -53, -109],
[ -21, -42, 68, ..., 13, 57, -12],
[ -4, 88, -1, ..., -43, -78, 121]],
device='cuda:0', dtype=torch.int8, requires_grad=True)由此可見,權重值被壓縮了,分布在[-127,127]之間。
如需恢復FP16精度,則:
print("Restored FP16 precision:")
print((int8_model[0].weight.CB * int8_model[0].weight.SCB) / 127)然后得到:
tensor([[ 0.0028, -0.0459, 0.0522, ..., -0.0049, -0.0428, 0.0462],
[-0.0960, 0.0391, 0.0782, ..., 0.0994, 0.0593, 0.0167],
[-0.0822, -0.1240, -0.1207, ..., 0.1181, 0.0185, -0.0541],
...,
[ 0.0757, 0.0723, 0.0628, ..., -0.0482, -0.0516, -0.1072],
[-0.0194, -0.0410, 0.0657, ..., 0.0128, 0.0554, -0.0118],
[-0.0037, 0.0859, -0.0010, ..., -0.0423, -0.0759, 0.1190]],
device='cuda:0')這和原始的FP16精度權重非常接近。
第六步:在同一個顯卡上用FP16精度計算模型。
input_ = torch.randn(64, dtype=torch.float16)
hidden_states = int8_model(input_.to(torch.device('cuda', 0)))第七步:集成到Transformer庫。
使用accelerate庫初始化模型。當處理大型模型時,accelerate庫提供了很多便利,特別是在內存管理和模型初始化方面。init_empty_weights方法可以幫助任何模型在初始化時不占用任何內存。
import torch.nn as nn
from accelerate import init_empty_weights
with init_empty_weights():
model = nn.Sequential([nn.Linear(100000, 100000) for _ in range(1000)]) # This will take ~0 RAM!修改.from_pretrained。當調用函數.from_pretrained時,會內置將所有參數調用torch.nn.Parameter,這不符合功能模塊Linear8bitLt。因此,將Actor生成的
module._parameters[name] = nn.Parameter(module._parameters[name].to(torch.device("meta")))修改為:
param_cls = type(module._parameters[name])
kwargs = module._parameters[name].__dict__
module._parameters[name] = param_cls(module._parameters[name].to(torch.device("meta")), **kwargs)替換 nn.Linear 層為 Linear8bitLt 層
def replace_8bit_linear(model, threshold=6.0, module_to_not_convert="lm_head"):
for name, module in model.named_children():
if len(list(module.children())) > 0:
replace_8bit_linear(module, threshold, module_to_not_convert)
if isinstance(module, nn.Linear) and name != module_to_not_convert:
with init_empty_weights():
model._modules[name] = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
# 參數has_fp16_weights需要被設置為False,從而直接加載模型權重為int8精度。
has_fp16_weights=False,
threshold=threshold
)
return modelmodel = replace_8bit_linear(model, threshold=6.0)




























