Linux 內存變低會發生什么問題
作者 | cynrikluo
內存不是無限的,總有不夠用的時候,linux內核用三個機制來處理這種情況:內存回收、內存規整、oom-kill。
當發現內存不足時,內核會先嘗試內存回收,從一些進程手里拿回一些頁;如果這樣還是不能滿足申請需求,則觸發內存規整;再不行,則觸發oom主動kill掉一個不太重要的進程,釋放內存。

低內存情況下,內核的處理邏輯
內存申請的核心函數是__alloc_pages_nodemask:
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { }; __alloc_pages_nodemask會先嘗試調用get_page_from_freelist從伙伴系統的freelist里拿空閑頁,如果能拿到就直接返回:
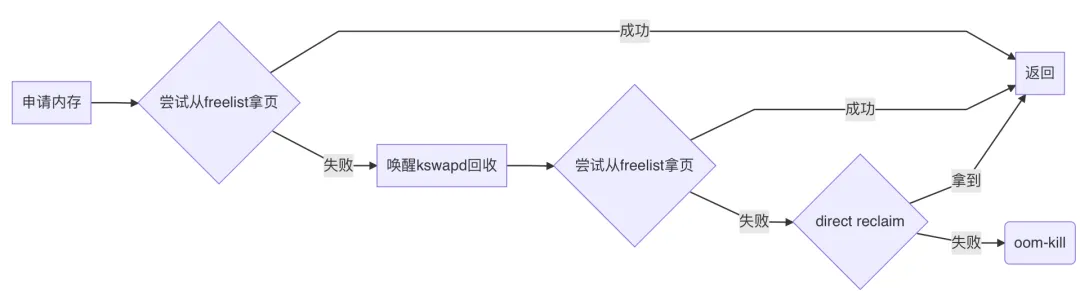
如果拿不到,則進入慢速路徑:
__alloc_pages_slowpath,慢速路徑,顧名思義,就是拿得慢一點,需要做一些操作以后再拿。
首先, __alloc_pages_slowpath會喚醒kswapd:
kswapd是一個守護進程,專門進行內存回收操作,執行路徑:

它被喚醒后,會立1刻開始進行回收,效率高的話,freelist上會立刻多出很多空閑頁。
所以 __alloc_pages_slowpath會馬上再次嘗試從freelist獲取頁面,獲取成功則直接返回了。
若還是失敗, __alloc_pages_slowpath則會進入direct_reclaim階段:
direct_reclaim,顧名思義,就是直接內存回收,回收到的頁不用放回freelist再get_page_from_freelist這么麻煩了,也不用喚醒某個進程幫忙回收,而是由當前進程(current)親自下場去回收,執行路徑:

如果direct_reclaim也回收不上來, __alloc_pages_slowpath還會垂死掙扎下,做一下內存規整,嘗試把零散的頁輾轉騰挪,拼成為大order頁(僅在申請order>0的頁時有用)。
如果還是無法滿足要求,則進入oom-kill了:
總結上面的邏輯:內存申請時,首先嘗試直接從freelist里拿;失敗了則先喚醒kswapd幫忙回收內存;若內存低到讓kswapd也愛莫能助,則進入direct reclaim直接回收內存;若direct reclaim也無能為力,則oom:
三條水線
實際上,從freelist上拿頁不是簡單地直接拿,而是先檢查下該zone是否滿足水線要求,不滿足那就直接失敗。
內核給內存管理劃了三條水線:MIN、LOW、HIGH。
三者大小關系從字面即可推斷,MIN < LOW < HIGH。
在首次嘗試從freelist拿頁時,門檻水線是LOW;喚醒kswapd后再次嘗試拿頁,門檻水線是MIN。
所以實際邏輯如下:
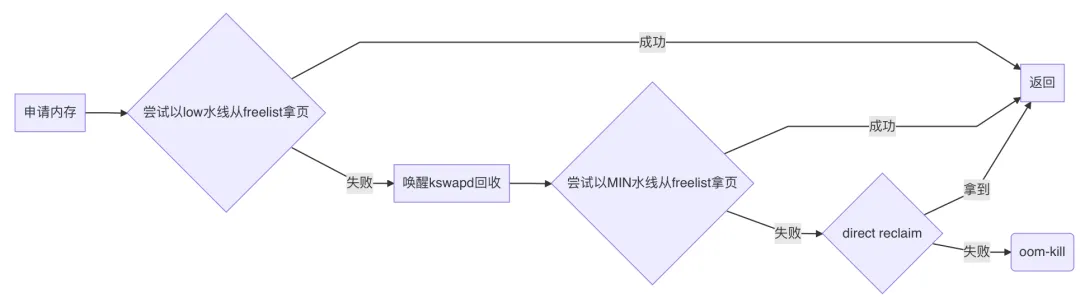
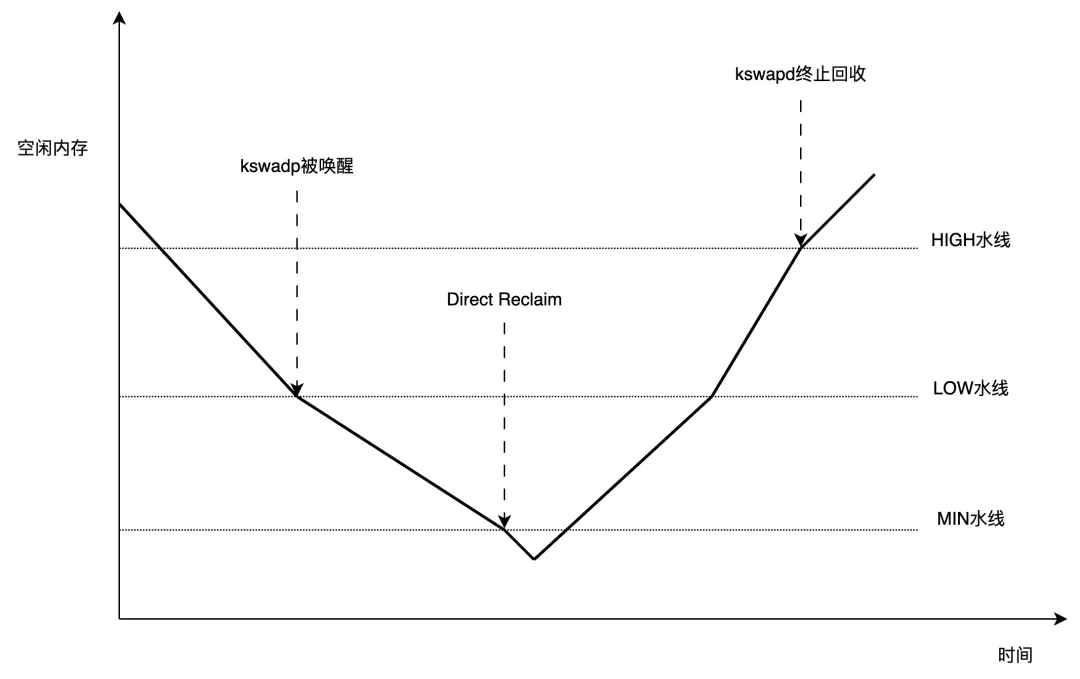
所以,可以簡單地認為,可用內存低于LOW水線時,喚醒kswapd;低于MIN水線時,進行direct reclaim;而HIGH水線,是kswapd的回收終止線:
為什么內存回收時,磁盤IO會被打滿?
可以看到,kswapd和direct_reclaim最終都是走到了shrink_node:

shrink_node是內存回收的核心函數,顧名思義,讓整個node進行一次“收縮”,把不要的數據清掉,空出空閑頁。

get_scan_count決定本次掃描多少個anon page和file page。
anon page就是Anonymous Page,匿名頁,是進程的堆棧、數據段等。內核回收匿名頁時,將這些數據進行壓縮(壓縮比大概為3),然后移動到內存中的一個小角落中(swap空間),這個過程并沒有與磁盤發生交互,因此不會產生IO,但需要壓縮數據,所以耗CPU。
file page就是文件頁,是進程的代碼段、映射的文件。內核回收文件頁時,先將“臟”數據回寫到磁盤,然后釋放掉這些緩存數據,干凈的數據則直接釋放掉。這個過程涉及到寫磁盤,因此會產生IO。
簡單總結一下get_scan_count的邏輯:
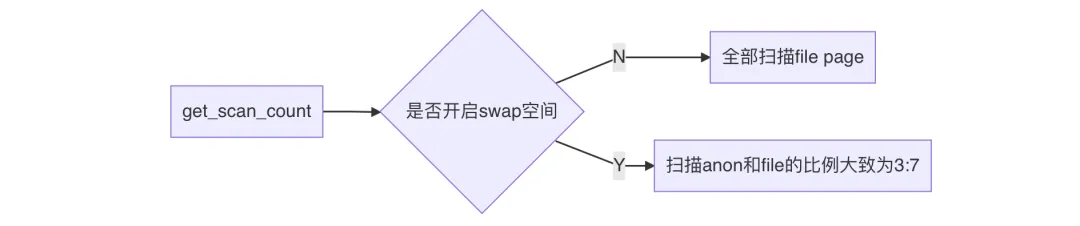
所以說,不論開沒開swap,內存回收都是傾向于回收file page。
如果file page中有臟頁,那內存回收大概率就會產生一些IO,無非是IO量多少罷了。
以下情況IO可能會打滿或者暴增:
- 當前內存不是特別緊張,但low、min水線設置得太低,之前一直沒怎么觸發過內存回收,以致于臟頁已經累積到大量,一觸發回收,立刻就是回寫大量臟頁,導致IO暴增。
- 內存極度緊張 (free 和available同時很低)。這種情況下,anon page遠比file page多,這意味著可回收的內存很少,內核會對活躍數據下手,一些進程上一秒還用著的數據,這一秒可能就被不幸回收了,但下一秒馬上又要被使用,會再次被讀入內存。如此,同一份數據,內核就進行了多次回收和讀入,IO就加倍了。
為什么低內存有時會引發hungtask?
低內存時,通常不是個別進程觸發了direct reclaim,而是大量進程都在direct reclaim。
大家都要回寫臟頁,于是IO被打滿了。
這時候,進程會頻繁地被IO阻塞,被阻塞的進程為了不占用CPU,會調用io_schedule_timeout或io_schedule來掛起自己,直到IO完成。
這種等待是D狀態的,一旦超過了120S,就會觸發hungtask。當然,這是非常極端的情況,IO已經完全沒救的情況。
大部分時候,IO雖然打滿了,但是總能周轉過來,所以這些進程并不會等太久。
然而,這些進程若是來自同一個業務,則大概率會訪問同一個數據,這就需要通過mutex、rwsem、semaphore等同步機制來控制訪問行為。
而這些同步機制的基本接口都是uninterruptible性質的,以semaphore為例:
extern void down(struct semaphore *sem); // 基本接口。獲取信號量,獲取不到則進入uninterruptible睡眠
extern int __must_check down_interruptible(struct semaphore *sem); // 其他接口
extern int __must_check down_killable(struct semaphore *sem); // 其他接口
extern int __must_check down_trylock(struct semaphore *sem); // 其他接口
extern int __must_check down_timeout(struct semaphore *sem, long jiffies); // 其他接口所謂uninterruptible性質,即當進程獲取不到同步資源時,直接進入D狀態等待其他進程釋放資源。
其他同步資源,rwsem、mutex等,都有這樣的uninterruptible性質接口。
正常情況下,只要持有同步資源的進程正常運行不卡頓,那么即使有上百個進程來爭搶這些同步資源,對于排序靠后的進程來說,時間也是夠的,一般不會等待超過120s。
但在低內存情況下,大家都在等IO,這些持有資源的進程也不能幸免,引發堵車連鎖反應。
如果此時同步資源的waiter們已累計了幾十個甚至上百個,那么就算只有一瞬間的io卡頓,排序靠后的waiter也容易等待超過120s,觸發hungtask。
一個非常典型的案例,一臺CVM在連續報了幾條hungtask warning后,徹底無響應了,通過魔術建觸發重啟。
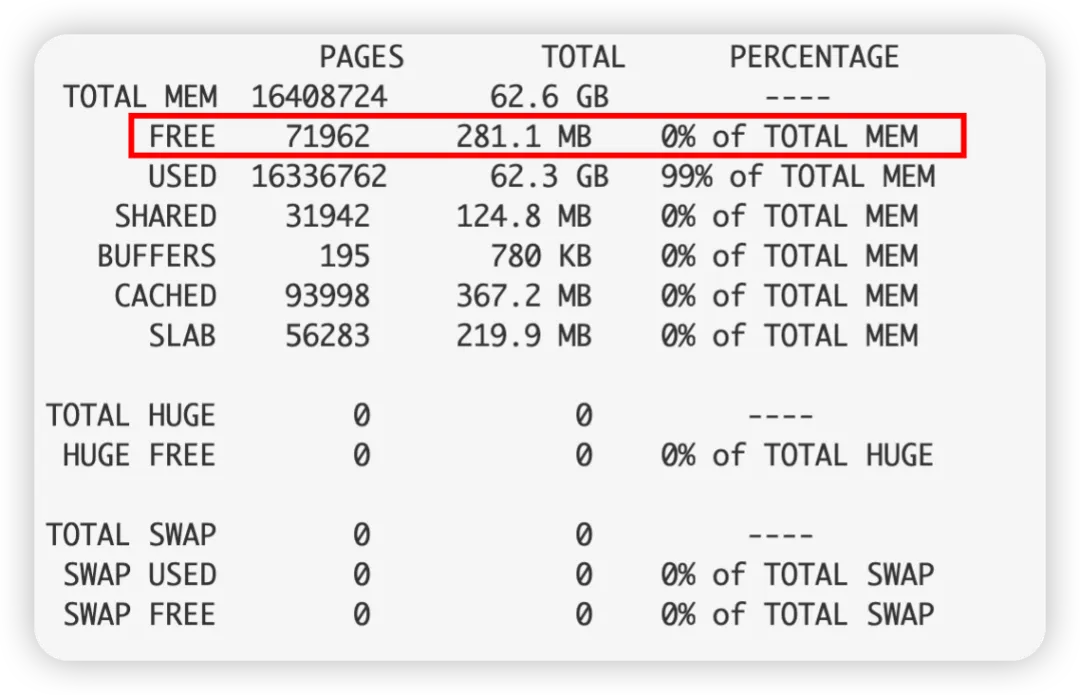
系統信息如下:

內存狀況不容樂觀,典型的低內存:
log上有很多hungtask warning,超時原因都是等rwsem太長,寫者waiter和讀者waiter都有:
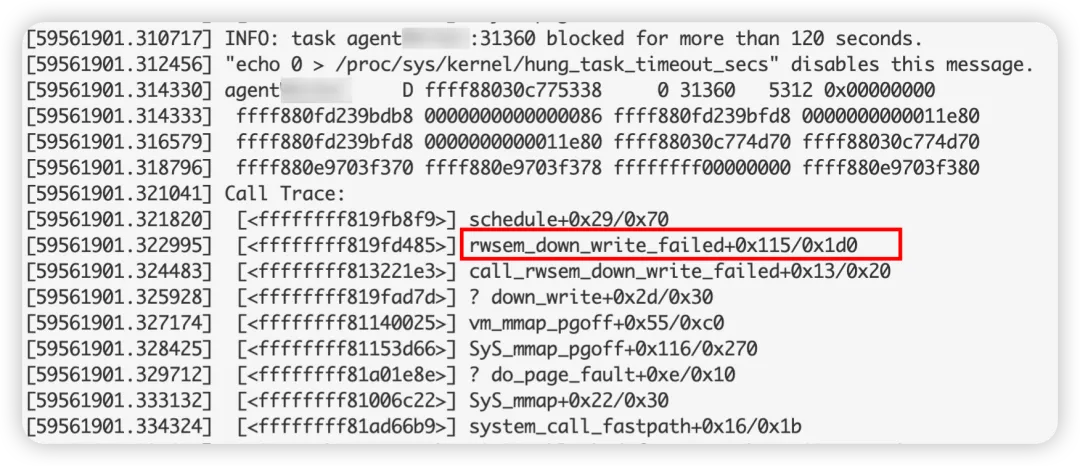
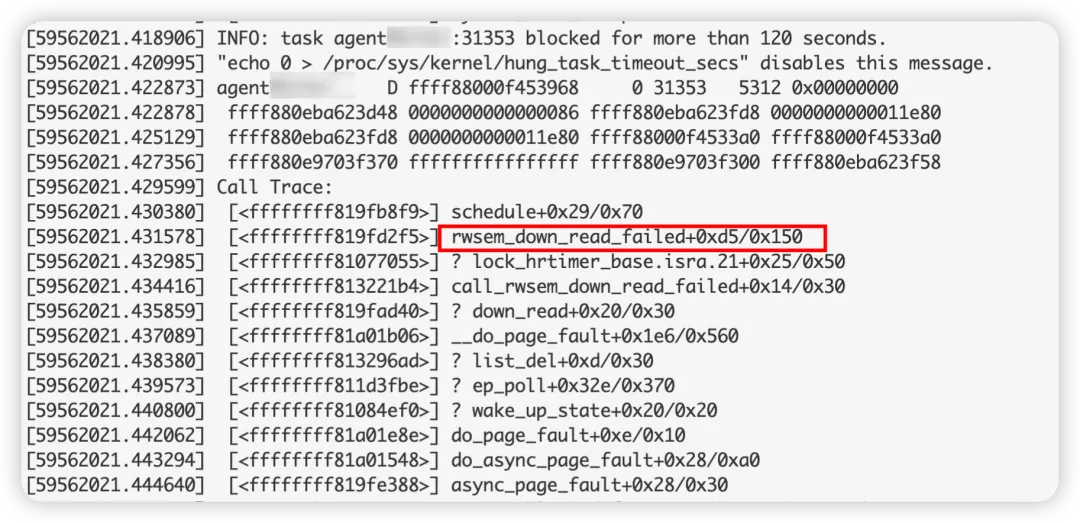
這些進程在等同一個rwsem,這個rwsem的地址為:ffff880e9703f370
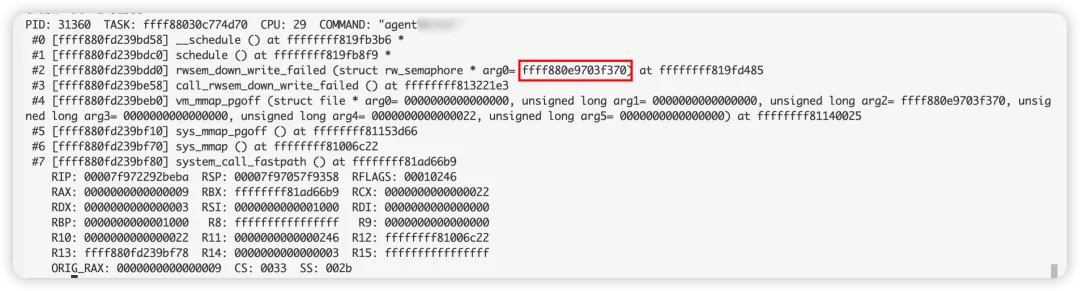
進一步探究,發現當前對ffff880e9703f370有引用的進程為19個,11個正在讀,8個排隊。
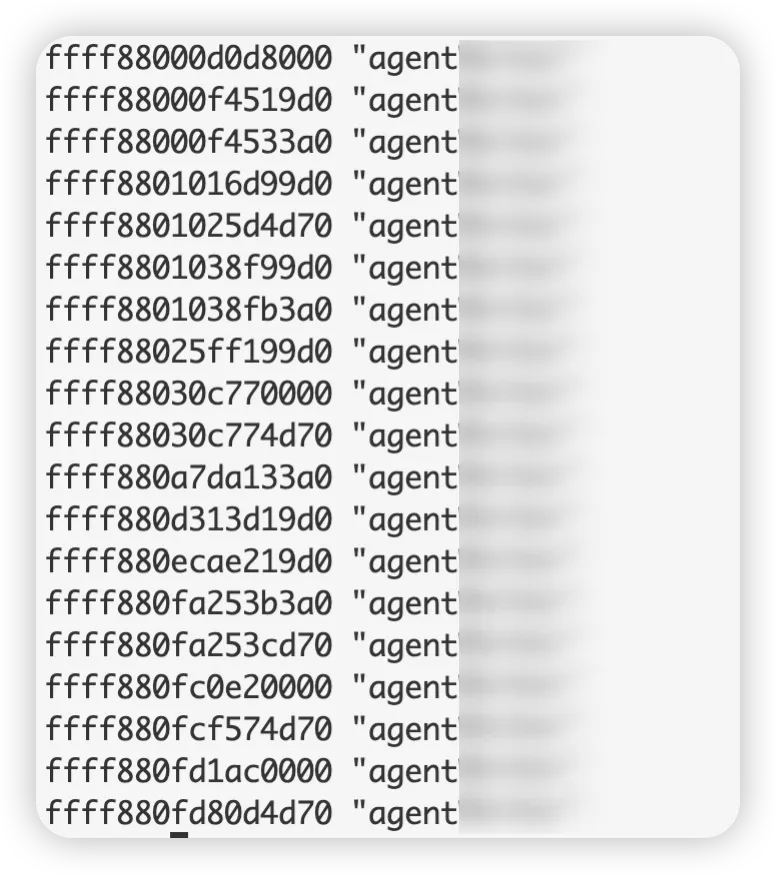
而這11個正在讀的進程,都在做同一件事——direct reclaim,并且都卡在IO等待:
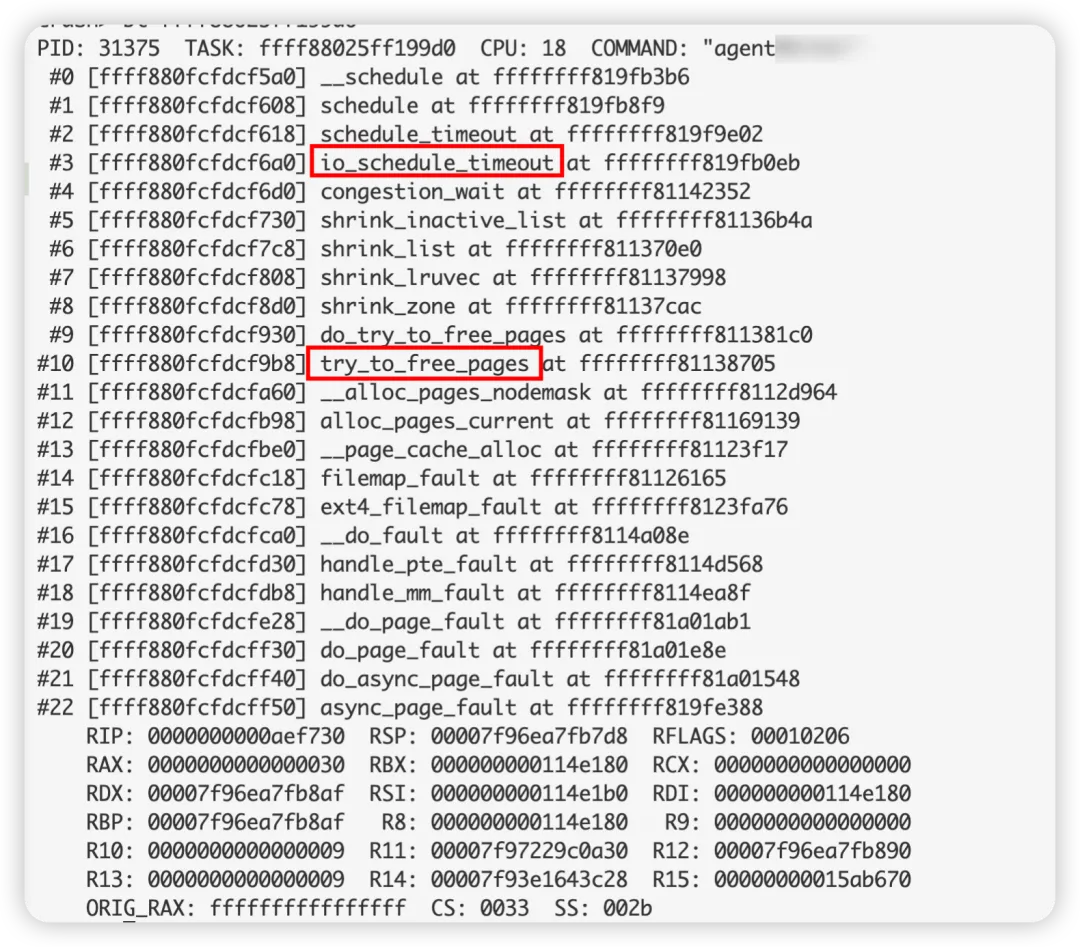
這11個進程,雖然也是D狀態,但由于時不時能調度到IO,相當于D狀態的持續時間不斷重置,所以本身并沒有觸發hungtask。
而這8個waiter進程就沒這個好運了,被前面11個進程你方唱罷我登場地阻塞,持續時間也沒有機會重置,最終超過120s,引發hungtask了。
優化低內存處理
我們已經知道了低內存會導致IO突增,甚至導致hungtask,那要如何避免呢?
可以從兩方面來避免。
(1) 調整臟頁回刷頻率
將平時的臟頁回刷頻率調高,這樣內存回收時,需要回收的臟頁就更少,降低IO的增量。
- 調低 /proc/sys/vm/dirty_writeback_centisecs
- 調低/proc/sys/vm/dirty_background_ratio
調高水線,可以更早地進入內存回收邏輯,這樣可以將free維持在一個較高水平,避免陷入極端場景。由于low和min同時受min_free_kbytes管控,所以可以直接調整min_free_kbytes值。
調高/proc/sys/vm/min_free_kbytes